Agent memory is rapidly becoming a defining feature of AI systems, fundamentally shifting the nature of system personalization. Longer context windows and embedded memory allow AI systems to perform longer and more complex tasks, with more detailed system and user context, a real benefit for users and a goal of developers.
But where traditional systems reflected model training data and crowd-sourced user preferences, persistent AI memory moves closer to an identity model, with systems learning user preferences and identities. Because identity is harder to audit, harder to change, and harder to contain, it raises design challenges that conventional personalization was never built to address: how legible should an agent's memory be to the user? How easily can it be corrected or erased? Where does context from one domain bleed inappropriately into another? As these memories accumulate value, how do they become targets for exploitation?
The design patterns borrowed from recommendation engines may not transfer directly to a world in which AI systems hold persistent, nuanced models of individual people. With the shift in longer AI memories come new frameworks that treat memory not just as a feature to be optimized, but as a relationship to be governed in the context of autonomy, trust, and privacy.
Context & Traditional UX Paradigm
For over a decade, mainstream consumer software has relied heavily on personalization. Recommender systems, search ranking, and feed optimization have long been used to construct probabilistic user representations from behavioral data. However, persistent AI memory shifts personalization directly into the interaction loop. To understand why this shift matters, it is helpful to first examine the interaction principles that have historically guided interface design.
Interaction Design Paradigm
Core human-computer interface (HCI) theories emphasize that systems should be legible and controllable, allowing users to form an accurate mental model of how the system is behaving and how to correct it when it is wrong. In The Design of Everyday Things (2013), Norman formalizes interaction as a cycle between user intention and system response between forming an intention, specifying and executing actions, and evaluating the system state. Notably, Norman introduces the “Gulf of Evaluation” as the gap between what a system does and whether a user can understand it, arguing that good design reduces this gap by making system state clear and interpretable.
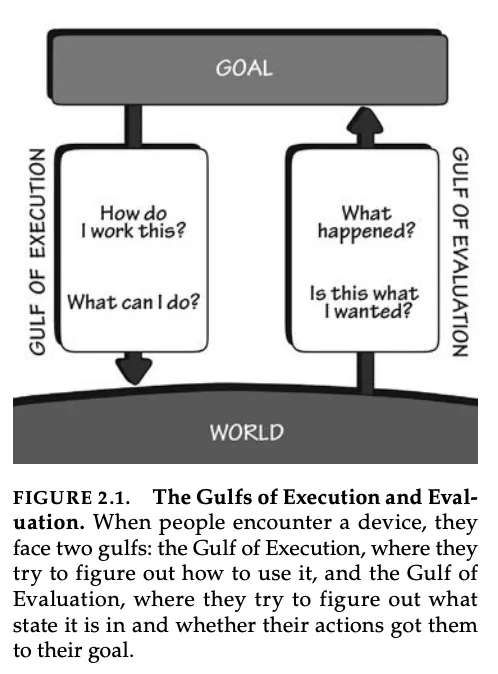
Source: The Design of Everyday Things
Research on interface agents also highlights the significance of direct manipulation, which emphasizes continuous visibility of system state, reversibility, and predictability. Even when systems stored data such as browser history or saved documents, the state was often surfaced through concrete UI artifacts, such as history logs, settings panels, and editable preferences.
These surfaces provide immediate feedback that helps form and refine a mental model of the system, making the relationship between their actions and system behavior more transparent and predictable. Designers communicate system causality through visible feedback to support accurate mental models and predictable interactions. For example, browsers visually distinguish visited from unvisited links, giving users passive feedback about their own navigation history without requiring them to explicitly recall it. These surfaces made the relationship between user action and system behavior legible.
Source: Contrary Research
These interaction design principles shaped how personalization systems were traditionally implemented. Personalization remained a background process, shaping what appeared on screen without directly reasoning about the user within the interaction itself.
Personalization in Mainstream Models
Historically, early conversational systems were limited in scope at the interaction layer. Early conversational systems like MIT’s ELIZA relied on in-session pattern matching and did not maintain persistent user representations across interactions. Later voice assistants, such as Siri and Alexa, did store preferences and interaction histories in the cloud, but the dominant framing of interaction remained transactional, with one-off commands directed at a system.
Over the past decade, modern personalization systems operated primarily through ranking and recommendation layers that ran largely beneath the interaction surface. Systems like recommendations, ranking, and targeting construct probabilistic ranking models by aggregating behavioral signals such as views, clicks, watch time, and purchases. While these systems maintain user vectors and segmentations, these representations are optimized for a specific purpose: predicting what a user will engage with next, not reasoning about who they are. As a result, they are rarely surface as editable profiles or explicit identity models that users can read, contest, or correct. Consumer-facing features like Spotify Wrapped surface aspects of behavioral data, but are designed for marketing and shareability rather than transparency.

Source: Dive Into Deep Learning
In these paradigms, user-facing controls in these systems reflect this architecture. They are typically coarse-grained and reactive, such as marking content as “Not interested,” hiding items from a feed, or excluding songs from a taste profile. These actions adjust ranking inputs at the margins but do not expose or modify the underlying user representation itself. As a result, even pervasive personalization has historically been experienced as feed optimization or content filtering rather than as an explicit, evolving representation of the user that shapes interaction in real time. However, persistent AI memory represents a structural departure from this paradigm.
The Rise of Persistent AI Memory
In recent years, persistent AI memory has become a major focus of research, product development, and venture investment across the AI industry. Industry reports project rapid growth in AI memory hardware required to support these advancements, which require separate componentry from the logic chips that carry out AI computations. The AI memory hardware market is projected to exhibit a CAGR of 63.5% from 2025 to 2033, due in part to surging capital expenditure associated with a global memory component shortage.
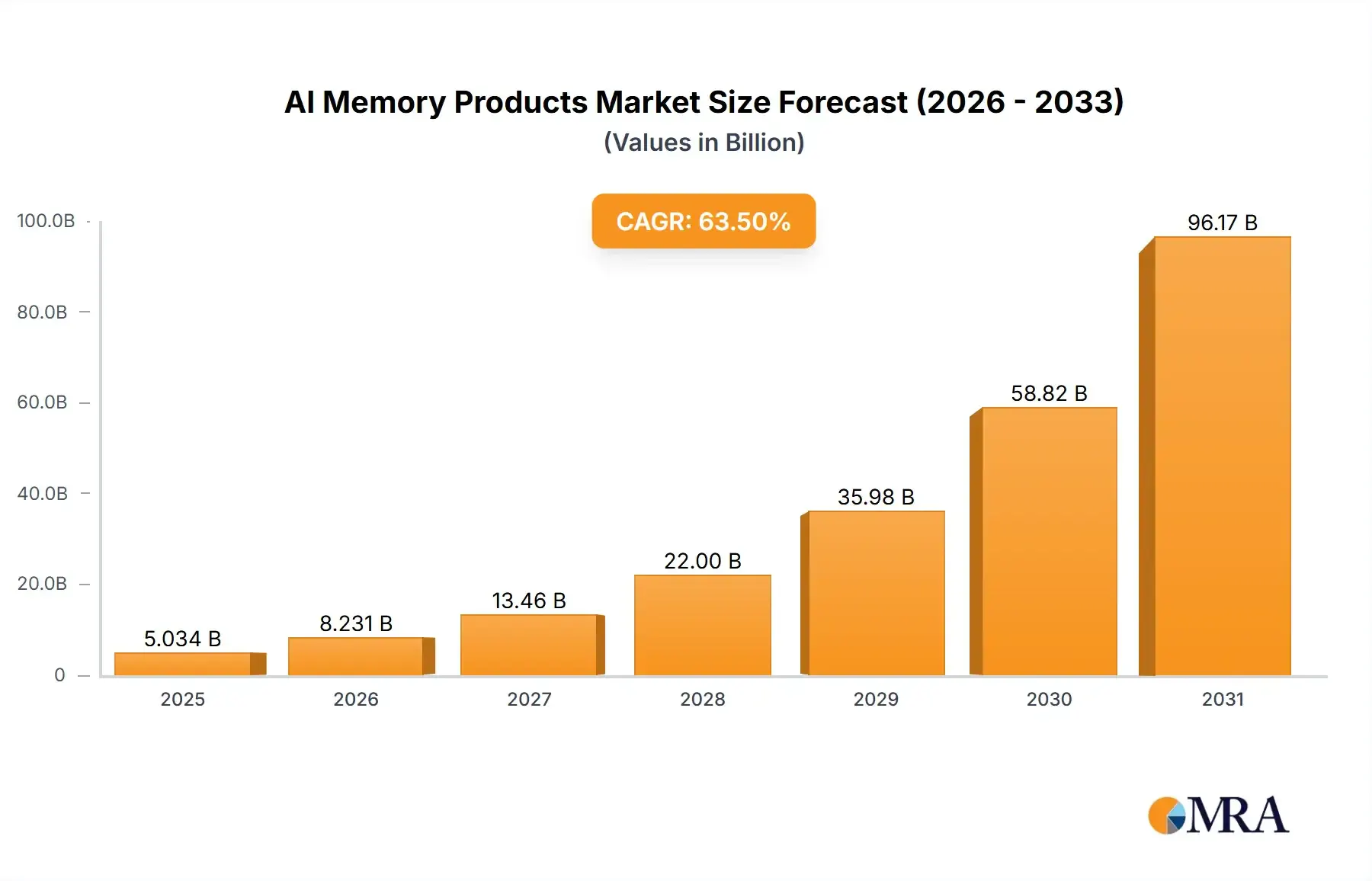
Source: Market Report Analytics
Current Landscape
Over recent years, major AI labs have moved from session-based chat toward persistent, cross-session memory architectures. In February 2024, OpenAI announced long-term memory for ChatGPT, allowing the system to “remember things across conversations.” ChatGPT references past conversations to deliver responses that feel more relevant and tailored to individual users. Memory operates through two primary mechanisms: “saved memories,” which users explicitly ask the system to retain, and “chat history,” which allows the model to draw insights from previous chats to improve future responses.
ChatGPT, for example, exposes a visible memory state through a settings panel, where stored information can be viewed, edited, or deleted. In this sense, memory is treated similarly to browser history or document drafts, an artifact that users can inspect and modify. Design patterns such as progressive disclosure and manual deletion controls reflect attempts to make persistent AI memory legible and controllable.
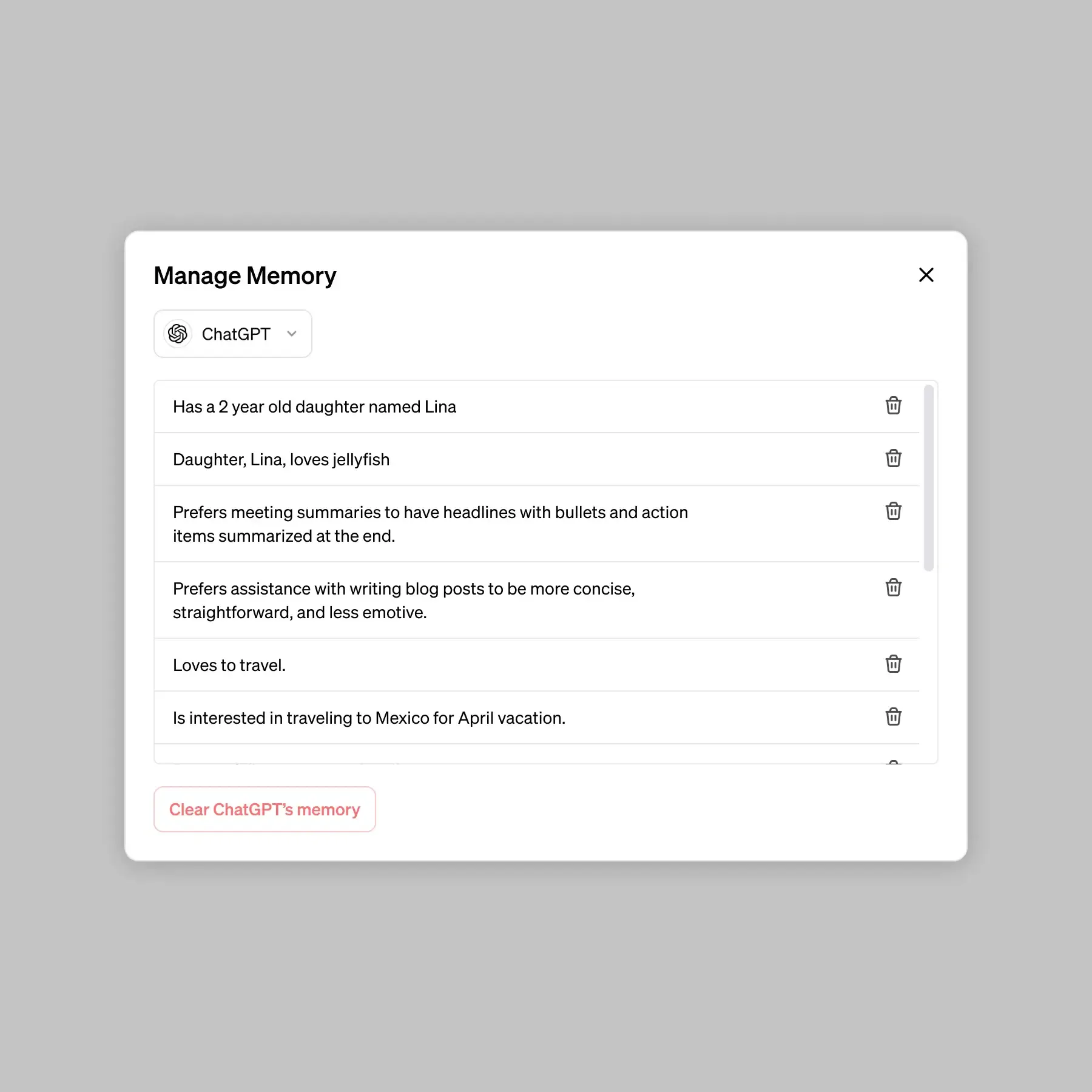
Source: Open AI
Anthropic has introduced a similar approach, but a somewhat different interface, for persistent memory through Claude Projects and Claude Code. In this model, memory persists across sessions via explicit CLAUDE.md markdown files, which allow users to define rules, preferences, and project-specific instructions that guide the system’s behavior. Claude also maintains auto memory, which captures contextual signals like project patterns, hotkey commands, and user preferences. Each project maintains its own memory directory, effectively creating scoped memory environments that help define contextual boundaries between different workflows.
Other companies offering AI products are expanding persistent memory beyond conversational interfaces to broader product ecosystems. In January 2026, Google integrated persistent personalization into Gemini across Workspace and Android. Gemini can now reference your Gmail, Calendar, Drive, Photos, Search, Maps/Shopping, and YouTube history to personalize answers and perform multi‑step tasks. By aggregating signals across services, Gemini can construct and reuse a richer profile of each user, including their interests, relationships, and typical locations to tailor responses and execute multi-step tasks.
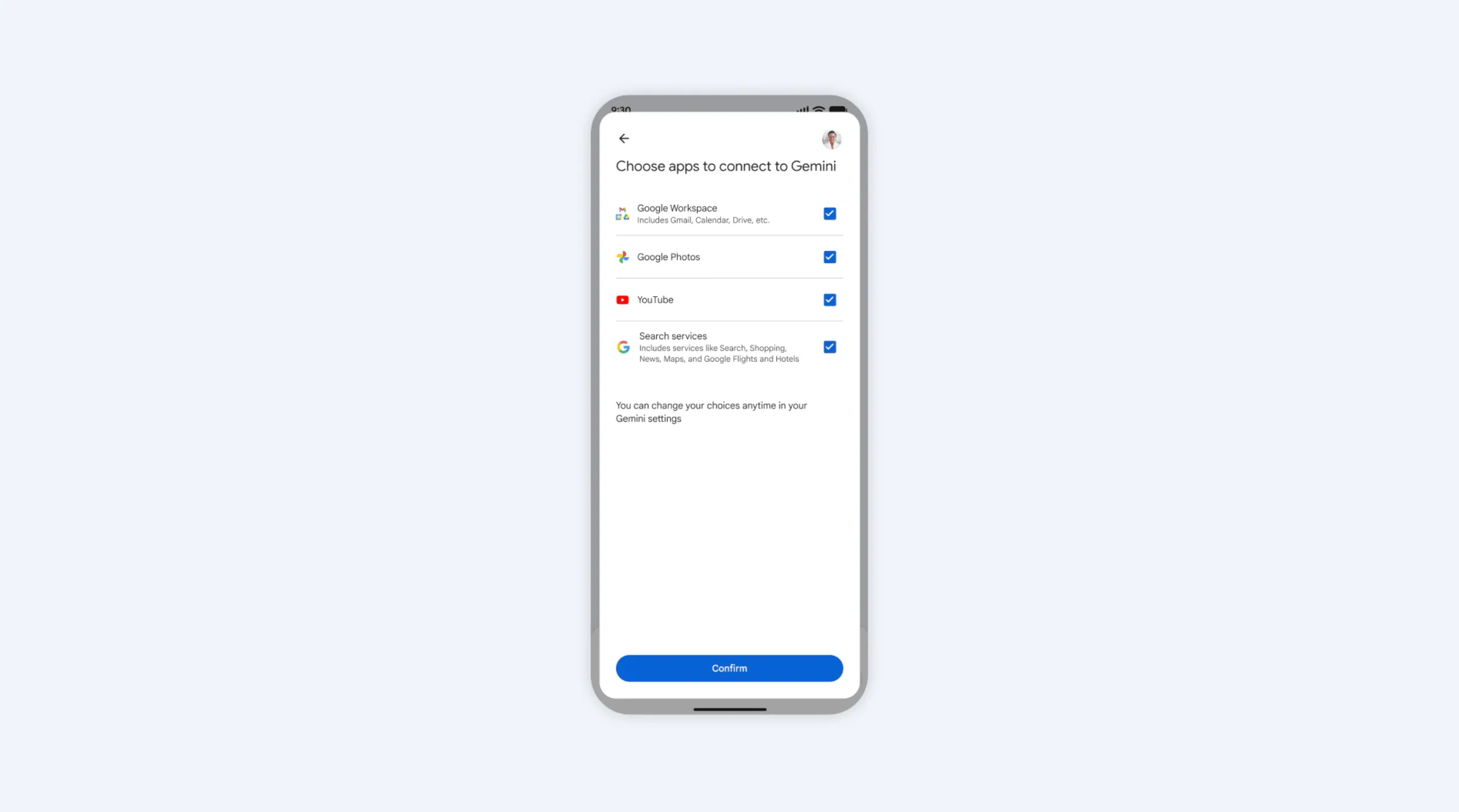
Source: Google
Alongside foundation models, a new class of AI-native startups is building systems designed to “remember everything.” Limitless AI, for example, markets itself as a “personalized AI powered by what you’ve seen, said, and heard” as a way to augment human memory so users can recall past conversations and experiences without manual note‑taking. Similarly, Bee is developing a wearable “life logging” device that captures continuous audio and environmental signals to generate daily narrative summaries of a user’s life. Meanwhile, Memori, an open-source library developed by GibsonAI, gives any LLM app “persistent memory across sessions,” including facts, preferences, and context to integrate with agent frameworks.
These products create an independent memory layer that records rich streams of activity, including screen interactions, microphone input, calendar events, and messaging data. Products like Jenova.ai expose persistent memory with explicit toggles and per‑item controls, distinguishing between temporary context windows and “Global Memory” that stores preferences and past conversations across sessions.
These design patterns represent early attempts to reconcile continuous memory capture with user expectations of control and transparency, but introduce new design challenges and governance questions around memory scope, user agency, and audibility. To address this, Gemini, for example, surfaces “Personalization from Google services” controls that allow users to see which connected services are informing responses and toggle them on or off. In some cases, Gemini also provides inline indicators that a response was generated using information from connected services, offering a lightweight form of provenance for cross-product memory usage.
How AI Memory is Technically Enabled
While there have been efforts in making persistent memory legible, addressing challenges around control requires examining how persistent memory actually operates. Multiple architectures enable persistent memory at different layers of the system. One important distinction is between context windows and persistent memory.
Context Windows
A context window refers to the temporary token buffer available during a single model inference, which determines how much information a model can process at once. Increasing context length allows more information to be processed within a single session. Recent work on “in-memory prompting” shows that longer context windows can improve reasoning depth and short-term recall within a single interaction. However, large context windows alone do not create cross-session identity memory. Once a session ends, the context window is cleared, and the model does not retain knowledge of the user unless that information is stored externally.
Persistent Memory
Persistent memory, in contrast, requires additional storage representations outside the model, indexing and retrieving them in future sessions, and binding them to a specific user identity. From a UX and governance perspective, the key shift is not solely increased context length but the introduction of persistence, marking the transition from remembering what a user said to remembering who a user is.
In practice, long-term AI memory is most commonly implemented via retrieval‑augmented generation (RAG). In this architecture, past content like messages, facts, or summaries is embedded into high-dimensional semantic representations and stored in an external database. At inference time, relevant vectors are retrieved based on similarity to the current query and injected into the prompt. Because retrieval operates through semantic similarity rather than deterministic rules, relevant memories are probabilistically selected and incorporated into the model’s reasoning process. Over time, retrieved memories are recursively synthesized into higher‑level “reflections” and longer‑term plans. These reflections are then written back into the memory stream, creating a persistent, evolving representation over time.
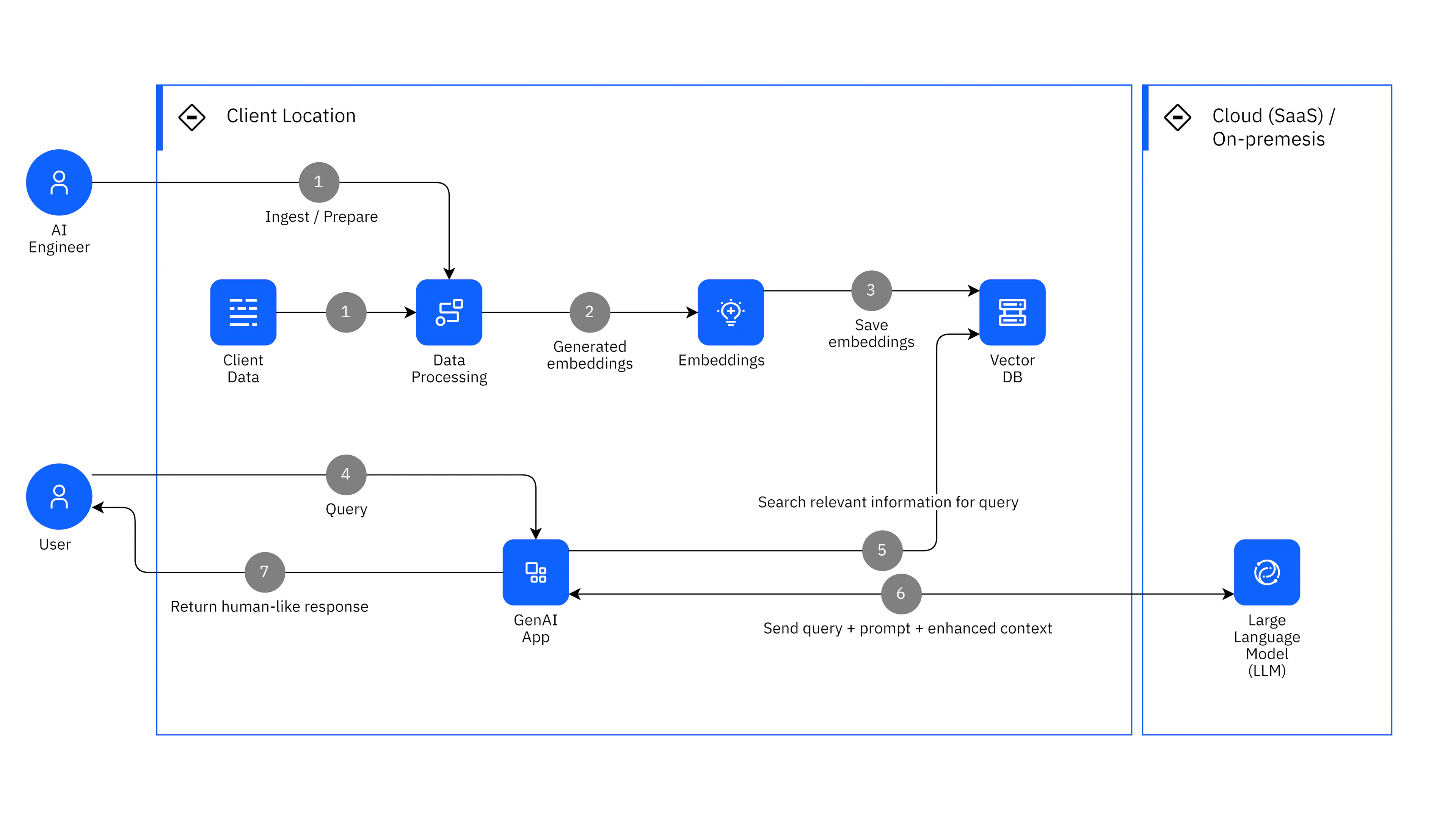
Source: IBM
This retrieval layer is also often supplemented by behavioral logs such as clicks, corrections, tool usage, and lightweight user models that update inferred preferences over time. However, because retrieval is similarity-based, rather than rule-bound, contextual boundaries may blur: what is retrieved depends on semantic proximity rather than the original context in which the information was provided.
Furthermore, certain architectures extend beyond simple episodic retrieval and synthesize higher-level abstractions from accumulated interactions. For example, Stanford University researchers introduced an explicit memory stream in their Generative Agents study, demonstrating how episodic memories can be converted into “reflections.” In the study, 25 generative agents exhibited complex social behaviors as reflections, which were then written back into memory and influenced future planning and dialogue. This experiment demonstrates how LLMs can function as long-term memory-enabled reasoning engines by recursively summarizing, abstracting, and re-coding experiences. Over time, such reflection mechanisms allow systems to construct evolving representations that influence future interactions.
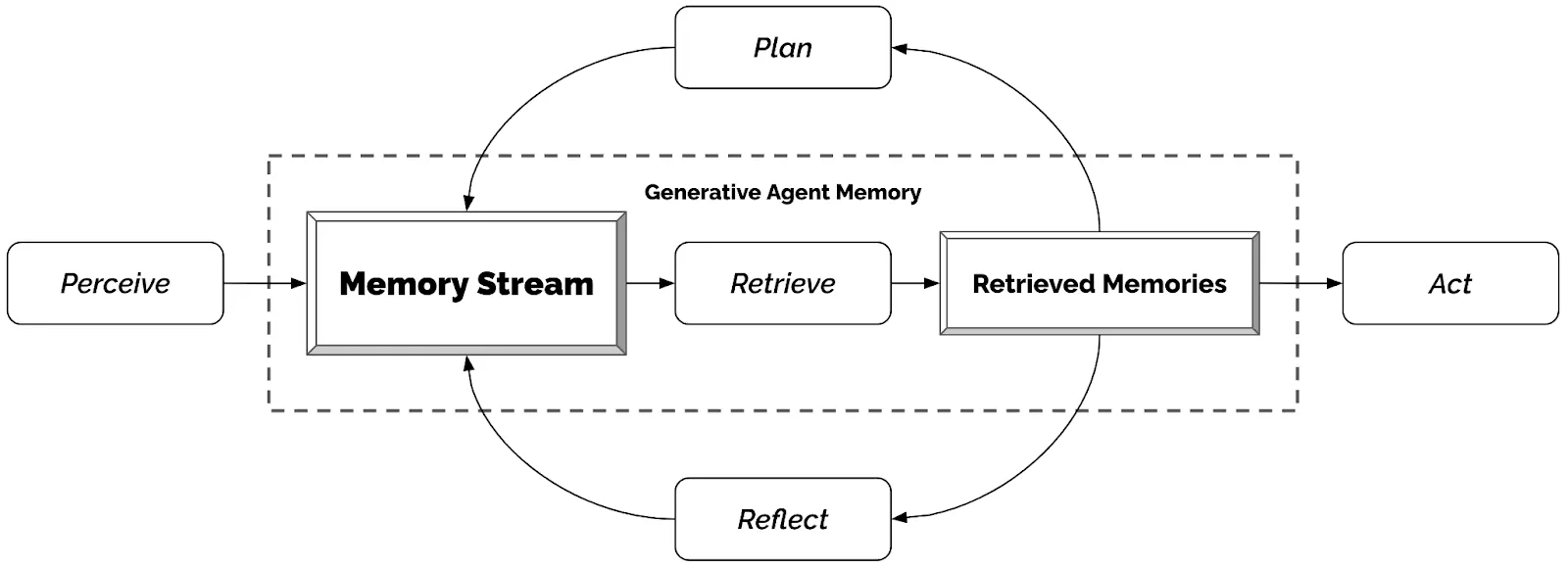
Source: Stanford HAI
As these architectures are increasingly deployed in consumer products, they also raise new questions about how persistent memory systems fit within existing privacy and data governance frameworks.
Privacy Laws Surrounding AI Software
These reflection mechanisms, in which inputs are embedded, abstracted, and recursively rewritten, sit in tension with existing privacy laws, which were built around discrete, traceable data collection events. In existing legal frameworks, there is an emphasis on transparency, purpose limitation, and contestability across the full lifecycle of personal data processing. The GDPR, for example, establishes core principles governing how personal data may be handled, including purpose limitation, which requires that data be collected for specified, explicit, and legitimate purposes and not further processed in incompatible ways. It also grants individuals the right to erasure under certain conditions, as well as rights to data accuracy and rectification, where users have the right to correct inaccurate data. Complementing these principles, FTC guidance emphasizes notice and consent tied to specific data collection events, reinforcing the expectation that users can understand when and how their data is being used.
More recent regulations extend these ideas to automated and AI-driven systems. The EU AI Act introduces logging, traceability, and data governance duties for high‑risk AI, requiring automatic record-keeping over the system’s lifecycle so that decisions and outputs can be reconstructed and audited. These logs must capture periods of use and reference datasets so authorities can reconstruct how particular outputs or decisions were produced. Similarly, emerging CPRA and CPPA rules in California focus on automated decision-making and profiling, granting consumers greater rights to access information used in automated decisions and, in some cases, to opt out of certain forms of profiling.
Together, these frameworks assume that personal data processing can be meaningfully described in terms of specific purposes, traceable processing steps, and contestable outcomes. Persistent AI memory complicates these assumptions. Conversational inputs may be embedded into high-dimensional semantic representations, aggregated across time, and abstracted into derived reflections that no longer map cleanly to a single input or collection event. This raises new compliance questions surrounding persistent AI memory, especially when identity abstractions are recursively generated and reused across contexts.
Core Risks of Persistent Memory
Legibility and Reversibility
The introduction of persistent memory significantly alters the nature of human-computer interaction, introducing new risks around legibility, agency, and reversibility. Regulatory authorities have also begun to identify these concerns; Spain’s data protection authority (AEPD) identifies four key risk dimensions in agentic systems with persistent memory:
Relevance (controlling what information is stored)
Consistency (ensuring stored data remains accurate)
Retention (limiting how long data is kept)
Integrity (preventing manipulation or poisoning of stored information).
One major challenge is the erosion of system legibility. Traditional HCI principles assume that users should be able to understand what a system knows and how it behaves. However, persistent AI memory introduces layers of latent representations such as embeddings, inferred summaries, and weighted retrievals that influence outputs, but remain largely invisible to the user. This opacity creates what Norman describes as the widening “Gulf of Evaluation,” where users struggle to interpret the system’s internal state.
While some AI systems attempt to address this, such as ChatGPT’s “saved memories” dashboard, temporary chats, and disable toggles, the system’s deeper representations remain difficult to inspect. A user may see a high-level summary such as “prefers X over Y,” but cannot easily trace which past interactions produced that inference, how strongly it influences retrieval, or whether additional behavioral signals contributed to the conclusion. As a result, users may struggle to verify or contest how the system models them internally. This gap is observable in practice. When users query ChatGPT's memory settings panel, they see a curated list of discrete saved facts. However, some users have reported ChatGPT referencing deleted data when asking the model what they know about them directly in chat.
Deleting a chat might not fully remove embeddings or derived reflections, and “forget” commands often fail to trace all downstream effects. In systems that act autonomously, the stored representation of the user can influence future decisions and recommendations in ways that are resistant to direct edits or resets. This means there is rarely a clear “undo” function for how the system carries forward past interactions, a fundamental breakdown of the direct manipulation principle.
Contextual Integrity
A useful framework for understanding another category of risk comes from HCI researcher Helen Nissenbaum’s theory of contextual integrity. She argues that privacy norms are not absolute, but instead depend on whether information flows are appropriate within a given social context. Under this framework, privacy violations occur when data is used in ways that deviate from contextual expectations, even if the data itself is not inherently sensitive. Historically, users generally understood when they were providing information, and disclosure often felt associated with visible product surfaces. This could include typing a query, submitting a form, or granting a permission, regardless of whether backend systems retained logs or analytics.
Persistent memory undermines this expectation. When information is stored within a shared semantic repository, data is prone to crossing contexts in ways that are deeply undesirable for the user. Research suggests that conversational models can exhibit contextual integrity violations in up to 69% of benchmark scenarios.
In practice, this can manifest as “memory seepage,” where data meant for one purpose could blend into other agentic actions or shared pools. For instance, a casual chat about dietary preferences to build a grocery list might later influence health-related recommendations or insurance options. Similarly, a search for restaurants offering accessible entrances could inadvertently affect how the system frames seemingly unrelated topics, such as salary negotiations, all without a user’s awareness. Cross-product memory architectures further amplify this risk by aggregating signals across multiple platforms, such as email, calendar, messaging, and search history, collapsing informational boundaries and appropriate flow norms.
Security and Societal Risks
Beyond interaction design challenges, persistent AI memory also introduces broader security and societal risks. Because these systems centralize large volumes of conversational data, behavioral logs, and cross-product data, they create rich identity representations that can become attractive targets for attackers. These vector stores and agent memory layers expand the attack surface. Unlike discrete logs, persistent embeddings enable attackers to reconstruct sensitive inferences, such as health conditions inferred from dietary chats, even from partial database leaks.
These risks are compounded by retention practices. Many AI systems currently store large volumes of interaction data indefinitely, which conflicts with data minimization principles in privacy regulation. Over time, persistent memory systems accumulate increasingly detailed behavioral histories, meaning that the longer a user interacts with a system, the richer and more sensitive this representation becomes. As a result, data breaches involving persistent memory infrastructure could expose years of cross-context activity rather than isolated events.
Related concerns have emerged around “shadow memory,” in which autonomous agents generate operational logs or intermediate records that remain largely invisible to users. Although these logs can support auditability and traceability, they may also introduce new privacy risks. If detailed behavioral traces are captured or reused in training pipelines without appropriate safeguards, they could enable forms of hyper-surveillance or unauthorized data reuse. Reporting on guidance from Spain’s data protection authority highlights the scale of potential exposure: more than 200 million personal data breaches were submitted to the regulator, illustrating how large-scale data retention systems can amplify the consequences of security failures.
Persistent memory systems may also introduce longer-term societal risks related to bias reinforcement. Architectures that periodically summarize interactions into higher-level “reflections” can abstract traits, preferences, or behavioral patterns from accumulated conversations. When recursive memory and feedback loops create higher-level traits from interactions, the system may converge on a version of the user that becomes increasingly difficult to dislodge.
This dynamic can be particularly problematic when early inferences are biased or incomplete. Misinterpretations may be repeatedly retrieved during future interactions, shaping recommendations, tone, or assumptions about the user. Marginalized groups may face compounded risks and misrepresentations over time, especially when training data underrepresents certain populations or encodes historical biases. In these cases, persistent personalization can reinforce misrepresentations rather than correct them, requiring users to expend disproportionate effort to reshape how the system models them.

