
Thesis
The evolution of computer user interfaces began with pioneering systems like the Sketchpad in 1963, and was subsequently refined through the 1970s and 80s with graphical user interfaces (GUIs) like Apple’s Lisa and Microsoft’s Windows 1.0. The 2000s witnessed the extension of GUIs to mobile devices, most notably with Apple's iPhone in 2007, which replaced stylus-driven screens with multitouch finger gestures, making graphical interfaces always-on and pocket-accessible. Despite aesthetic refinements like flat design and gesture navigation in the 2010s and 2020s, the fundamental interaction model has remained largely unchanged.
GUIs on computer and phone screens still dominate how users spend their time online, but contribute to various dependency issues. As of 2025, over 60% of the world’s internet traffic comes from smartphones. In the U.S., 98% of adults own a smartphone, spend 4.5 hours each day on it, and check it 144 times per day on average. This widespread ownership has led to dependency on their phones. 57% of adults self-describe as “mobile phone addicts”, checking their phones 144 times per day on average. 75% of Americans also admit to feeling uncomfortable without their phones, with nearly half saying that they panic when their battery drops below 20%.
As an alternative option, voice user interfaces offer natural, hands-free interaction modalities that address many GUI limitations, but significant limitations still limit their utility beyond basic commands. With over 8 billion digital voice assistants currently in active use worldwide as of 2025, 90% of consumers find voice search more convenient than text queries as of 2023, while speaking proves faster than typing for many tasks.
However, users of mainstream voice assistants like Amazon Alexa and Google Assistant consistently report that both assistants excel at simple tasks (such as timers and music playback) but struggle with multi-step or contextual interactions, leading to poor usability for anything beyond simple queries. In efforts to upgrade its assistant, Google Assistant users have noted dropped features, slower response times, and confusion following the Gemini transition. Internal documents from Amazon also reveal that the generative AI upgrade to Alexa suffered from unacceptable latency and achieved customer satisfaction scores of only around 4.6 out of 7.
Another reason voice assistants fail to achieve meaningful user engagement is due to a lack of emotional expressivity, contextual memory, and authentic personalities. This causes neutral, utility-driven voices to have diminishing returns on users’ psychosocial measures, whereas human-like voices achieved higher levels of trust and sustained engagement with users.
Sesame AI is a conversational AI company that builds voice companions capable of natural and emotionally resonant conversations. It has built emotionally intelligent voice assistants called Maya and Miles that can interrupt, laugh, change tone mid-sentence, and respond to emotional cues in real-time conversations. Unlike traditional voice assistants that follow a rigid speech-to-text-to-speech pipeline, Sesame's Conversational Speech Model (CSM) processes both text and audio tokens simultaneously, enabling natural conversational flow with 200-300 millisecond response times. Sesame’s goal is to build lifelike computers that act as useful companions for daily life.
Founding Story
Sesame AI was founded in June 2023 by Brendan Iribe (CEO), Ankit Kumar (CTO), and Ryan Brown (founding engineer). The founding team drew on their backgrounds in AI, speech technology, and consumer hardware to address key problems with existing voice assistants.
Iribe and Kumar's partnership predates Sesame AI and was built on mutual respect and complementary strengths. After co-founding Oculus VR (the company behind the virtual reality headset Oculus Rift) in 2012 and selling it to Meta (formerly known as Facebook) for $2 billion in 2014, Iribe looked to angel invest in startups. He had been an angel investor in Kumar’s earlier startup, Ubiquity6, which Kumar had been building from 2017 to 2021. Kumar, who later led engineering for Discord’s Clyde AI from 2021 to 2023 after Discord acquired Ubiquity6 in 2021, impressed Iribe with his deep expertise in language and speech AI. Their connection grew through months of working together, during which they explored the idea of a voice-first AI system that felt emotionally expressive and interruptible.
In February 2025, Sesame released a research demo of its voice technology (named “Maya” and “Miles”) and announced its vision of an AI voice companion paired with smart glasses. After releasing it to the public, the demo received significant viral attention, allowing Sesame to capture both media spotlight and investor interest. For instance, in February 2025, Verge headlined the demo with “Sesame is the first voice assistant I’ve ever wanted to talk to more than once”, praising its uncanny realism; elsewhere on Reddit and Hacker News, users called the demo “crossing the uncanny valley”, used to describe the voice’s human-like realism. Within weeks of unveiling the demo, Sesame closed a $47.5 million Series A led by a16z on February 27th, 2025. By April 2025, reports claim the company was raising more than $200 million at a $1 billion valuation, citing strong continued momentum for its product and vision.
As a result of its momentum, Sesame attracted talent for critical hires. For example, in June 2025, they brought on Oculus co-founder Nate Mitchell as Chief Product Officer to lead hardware design. Johan Schalkwyk, currently the Voice Lead at Meta’s Super Intelligence Lab, was Sesame’s ML lead from 2024 to 2025. Ryan Brown, Sesame’s founding engineer, worked at Oculus from 2013 to 2019, and then at Meta from 2019 to 2023 as the director of Reality Labs Research Engineering, before joining Sesame in June 2023.
Product
Sesame AI’s core products are its voice companions, Maya and Miles, and the Conversational Speech Model (CSM). It has plans to release companion hardware in the form of wearables in the future.
Voice Companions
Sesame AI’s voice-based digital companion is an AI assistant that converses nearly like a human. The assistant is powered from Sesame’s cloud and is embodied by two voice personas, “Maya” (female voice) and “Miles” (male voice). Through the voice preview on its website, users can speak with Maya and Miles in extended, free-form conversations.

Source: Sesame
Unlike Alexa or Siri, which only handle brief commands, Sesame’s companions are designed for ongoing dialogues, such as interactive entertainment or emotional support. For instance, you can play a Dungeons & Dragons-style adventure with the AI or get coaching through your day. The companions maintain context over long conversations, remember user preferences, and can proactively bring up relevant topics that span up to two minutes of dialogue history. To convey emotional depth in user conversations, companions’ voices laugh, pause, say “um,” and even interrupt appropriately, exhibiting human-like timing and intonation. As of April 2025, Sesame focuses primarily on English with some multilingual capability, with plans to expand to over 20 languages.
Conversational Speech Model (CSM)
The underlying technology powering Sesame’s voice companions is the Conversational Speech Model (CSM). This system employs a transformer architecture and is trained on over a million hours of filtered audio data. It explicitly models emotional and prosodic elements, such as pitch, rhythm, and energy. Running the model requires minimal setup, with model sizes ranging from a billion to eight billion parameters. This makes it feasible for on-device deployment in the company’s planned smart glasses hardware.
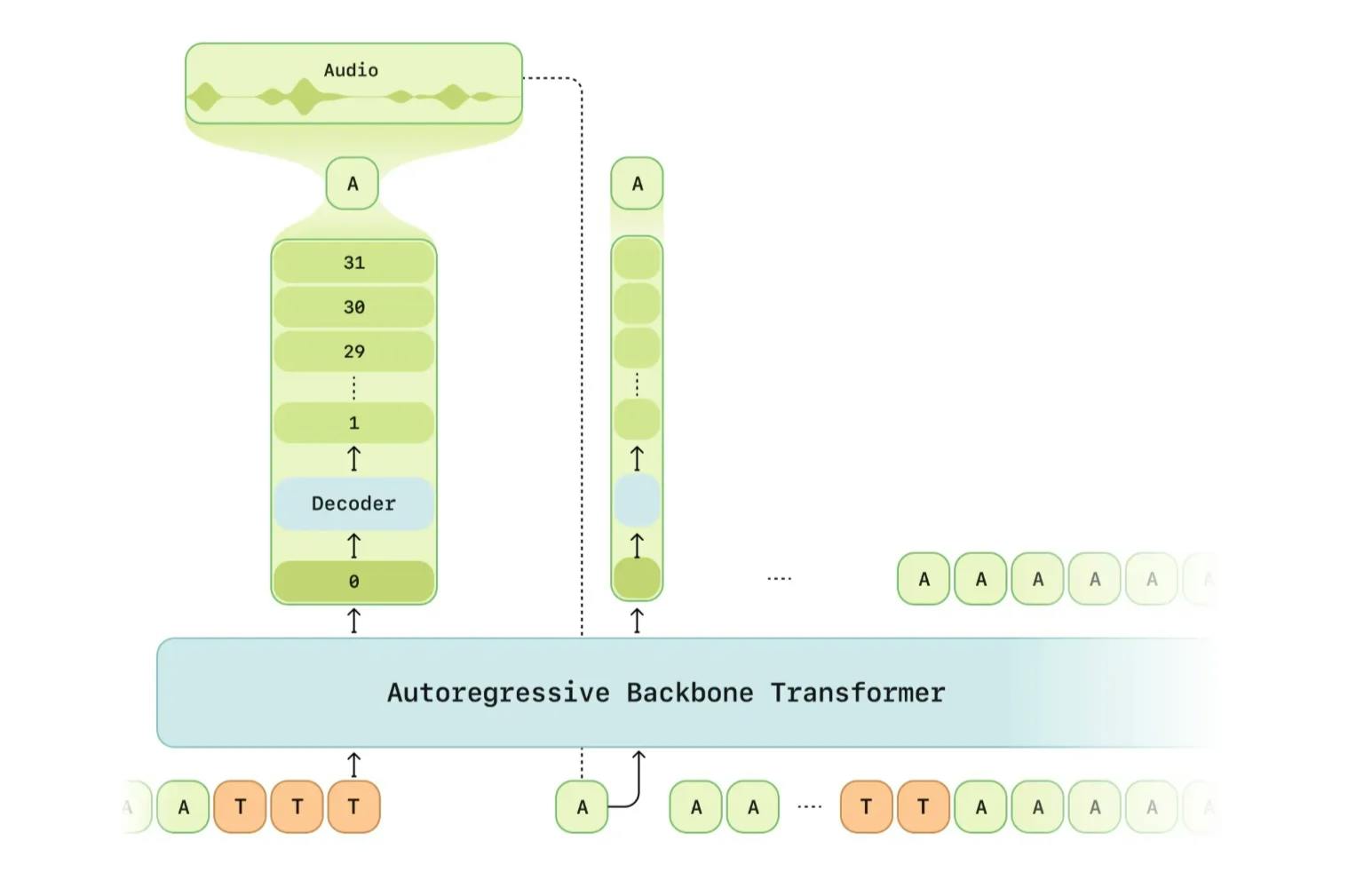
Source: Sesame
Sesame’s CSM represents a major architectural departure from traditional two-stage text-to-speech (TTS) systems. Instead of first generating a semantic representation of speech and then passing it to a separate acoustic model, CSM uses a unified, end-to-end transformer-based architecture. At its core is a large autoregressive transformer (based on LLaMA) that ingests interleaved audio and text tokens—capturing both what is said and how it sounds. These audio tokens are derived from Mimi, Sesame’s internal audio tokenizer, which uses residual vector quantization (RVQ) to efficiently encode prosody, rhythm, and voice timbre. The model’s output predicts the semantic base layer of speech, which is then refined through a smaller acoustic decoder that fills in the remaining codebooks to reconstruct full-resolution audio. This architectural separation allows for a large context-aware model to drive the conversation, while offloading detailed sound reconstruction to a lightweight decoder, enabling fast response generation without sacrificing audio quality.
One of the standout innovations of CSM is its low latency. Traditional RVQ-based voice synthesis approaches suffer from delays since each quantization layer must be predicted in sequence, often requiring multiple forward passes. CSM solves this by predicting all semantic tokens first in a single pass and then decoding all acoustic layers in parallel, allowing playback to begin almost immediately. This structure makes the system highly responsive in live settings, offering a real-time feel that’s essential for natural conversations. Importantly, this speed does not come at the cost of expressivity. Because the model is trained on text-and-audio pairs and optimized to preserve temporal dynamics, it learns to naturally include pauses, breaths, stutters, and changes in tone, giving the generated voice a much more human cadence.
CSM’s ability to include emotionally nuanced features like breathing and hesitation is not hardcoded. Since the model is conditioned on full conversational context, it can infer when a breath, sigh, or pause is appropriate, much like a human would during speech. For example, a thoughtful pause before a reflective answer or a subtle exhale at the end of a sentence are modeled implicitly. This expressiveness is further enhanced by training CSM on real conversational turns rather than isolated phrases, enabling it to understand and replicate the flow of human dialogue. The system not only generates word tokens, but it also mimics the rhythm, timing, and sonic texture of real speech, crossing into what Sesame calls the “uncanny valley of voice” with remarkable precision. In blind tests conducted in March 2025, participants initially couldn't distinguish between CSM and actual humans during brief conversations, though longer interactions revealed some limitations.
Sesame open-sourced its CSM-1b model in March 2025 under an Apache 2.0 license, making it available on GitHub and Hugging Face for developers to build upon. As of July 2025, it has 13.8K stars on GitHub, and the model has 95K downloads on Hugging Face. A hosted HuggingFace space is available for testing audio generation. By making its underlying CSM-1b model available as open source, Sesame has also positioned itself within the developer ecosystem, allowing third parties to build upon its technology while generating community interest in its approach to voice AI.
Source: Hugging Face
Wearables
Sesame is also building lightweight eyeglass wearables designed for all-day use, giving users access to their AI companion who can observe the world alongside them. As of July 2025, there is no release date, with only images of the prototype shared on its website. This hardware component represents Sesame's vision for integrated AI assistance that seamlessly blends into daily life.

Source: Sesame
Market
Customer
Sesame AI targets both consumers and businesses with its voice technology, but with an initial emphasis on a direct-to-consumer companion. The ideal consumer is a tech-forward individual who is an early adopter of new devices and values productivity or personal improvement. These are likely professionals or creatives (e.g., busy founders, developers, or knowledge workers) who would adopt an AI assistant to manage information overload and multitask. Sesame’s offering could also appeal to visually impaired users or seniors who benefit from hands-free assistance.
On the B2B side, Sesame’s technology also has potential appeal to enterprise users. As of 2025, approximately 32% of daily users express frustration that devices misunderstand their requests, while 13% feel existing solutions do not meet intelligence expectations. And as of 2024, 73% of consumers prefer voice assistants for interacting with businesses. To reduce customer complaints, an ideal business customer might be a large bank or healthcare provider upgrading their IVR system with a lifelike voice.
Market Size
Sesame AI operates in the conversational AI and augmented-reality (AR) wearable markets. In the US, around 154 million Americans use voice assistants as of July 2025, and this figure is expected to grow to 170 million by 2028. The global AI virtual assistant market (including enterprise and consumer software) was valued at $7.2 billion in 2022 and is projected to reach nearly $33.4 billion by 2030, growing at a CAGR of 21%.
The integration of hardware into Sesame AI’s offering significantly expands its total addressable market beyond software licensing. As of July 2025, the global wearable computing market could reach $238 billion by 2030, growing at a CAGR of nearly 20%. North America alone accounts for over one-third of this market, with the U.S. wearables sector valued at $24 billion in 2024 and growing at around 15% CAGR .
Importantly, audio-first wearables like Sesame’s smart glasses avoid privacy backlash associated with camera-based AR devices, making them potentially more socially acceptable and easier to deploy. By controlling both hardware and AI software, Sesame can benefit from higher-margin device sales and lock-in through a vertically integrated platform, making its positioning more defensible.
In the enterprise voice solutions segment, there’s a substantial opportunity in call center automation, customer service, in-game NPCs, and branded voice experiences. The conversational AI market is projected to grow from $17 billion in 2025 to nearly $50 billion by 2031, representing a 24% CAGR.
Sesame’s CSM‑1B model stands out by offering emotionally expressive, interruptible, and context-aware speech, addressing critical shortcomings of traditional TTS systems and unlocking higher value in enterprise deployments. For instance, the automotive industry alone presents a $5 billion opportunity by 2028 as car manufacturers strive to develop more natural in-vehicle assistants capable of managing intricate, multi-turn conversations while drivers are on the road.
Finally, expanding to global audiences through multilingual support dramatically increases Sesame’s TAM. With approximately 3.4 billion non-English speakers worldwide, supporting 20+ languages could meaningfully scale its reach. Enterprises in sectors like Asia-Pacific and Latin America are particularly eager for voice-first solutions due to regional preferences for spoken interfaces and lower smartphone penetration. Multilingual voice AI naturally aligns with business process outsourcing growth and enables quicker deployment than screen-based software, thanks to fewer localization hurdles.
Competition
Incumbents
Amazon (Alexa): First launched in November 2014, Amazon’s Alexa had over 77 million U.S. users in 2025. Embedded in Echo smart speakers and many appliances. In February 2025, Amazon announced Alexa+, a new AI-enhanced version with improved conversational abilities and generative AI features, offered at $19.99/month. Alexa has rich smart home integration and Amazon’s ecosystem behind it. However, Alexa’s voice remains relatively robotic and its interactions are largely one-shot commands, not long dialogues. Amazon’s model is to monetize through e-commerce and device sales (Alexa often acts as a gateway to shopping or services).
While Alexa is a household utility, Sesame positions itself as a personal companion with emotional intelligence. Amazon’s scale at over 100 million Echo devices is a significant distribution advantage, but Alexa’s emotional intelligence is limited, creating an opportunity for Sesame to differentiate on realism and proactivity.
Google (Assistant): First launched in May 2016, Google Assistant had over 92 million US users as of 2025 and leads in market share on smartphone-based smart assistants. In March 2025, Google overhauled Assistant with generative AI, integrating its advanced Chirp 3 speech model and PaLM language model. Chirp 3 supports expressive tone, custom voice cloning, and 31 languages. Google’s Assistant benefits from tight integration with Android/Pixel phones and a significant knowledge graph via Google search. It is positioned for tasks like search, phone control, and even customer service via its Dialogflow service for enterprise voicebots.
Google’s voice tech is state-of-the-art in multilingual support and speed, but Google is focused on broad utility (like voice typing, queries) rather than a persistent personality. Sesame’s edge is in emotional presence and a dedicated device. Google’s strategy of bundling Assistant for free on billions of devices could commoditize basic voice interactions, but Sesame seems to predict that an emotionally attuned experience can command a premium despite Google’s free offering.
Apple (Siri): First launched in October 2011, Apple’s Siri assistant, with 86.5 million US users as of July 2025, is another competitor, especially with Apple’s push into wearables (AirPods, Apple Watch, and Vision Pro AR headset). Siri in 2025 is considered less advanced in AI dialogue. However, Apple is reportedly working on a major AI overhaul as of March 2025, but progress has been delayed and is unlikely to be released before 2027. Apple’s competitive advantage is hardware integration and privacy – Siri on devices like Vision Pro or AirPods could provide voice assistance in a seamless, on-device manner with strong user trust.
Siri is a general assistant with a focus on quick commands and device control. If Apple pivots Siri to be more conversational and perhaps integrates it deeply into its lineup of wearable devices, it could compete directly with Sesame’s glasses. However, Apple’s AI conservatism (its emphasis on privacy and avoiding risky behavior) means Siri might remain less dynamic than Sesame’s AI. For now, Siri is an indirect competitor in that it habituates users to basic voice interaction; Sesame must demonstrate vastly superior capabilities to persuade users to adopt a new device over just using Siri on an iPhone or AirPods.
OpenAI: Founded in 2015, OpenAI introduced voice conversation in September 2023, giving millions access to a conversational voice AI via the ChatGPT mobile app. This system uses advanced text-to-speech (with distinct voices) and GPT-4’s language understanding. OpenAI’s voice can hold dialogues and answer complex queries, but it runs on a phone and, while natural, still lacks the subtle interjections and real-time turn-taking that Sesame emphasizes.
When compared to Sesame, ChatGPT can be considered a direct competitor on the software side since it is Sesame’s closest rival in terms of AI conversation quality and is often compared side by side by media outlets and consumers. However, OpenAI’s merger with io, the product development firm founded by Apple’s former Chief Design Officer Jony Ive, in May 2025, marks OpenAI’s expansion into AI hardware that can potentially rival Sesame’s AR glasses product.
Meta (Ray-Ban Stories): Founded in 2004, Meta partnered with EssilorLuxottica to launch Ray-Ban Stories, smart glasses that integrate with Meta's ecosystem. Unlike Sesame AI's planned glasses focused on advanced voice interaction, Ray-Ban Stories primarily emphasize photo/video capture and basic audio features. Meta's advantage lies in its existing market presence, while Sesame focuses on conversational capabilities.
Vertical AI Companions
Inflection AI: Founded in 2022 by Mustafa Suleyman, Karen Simonyan, and Reid Hoffman, Inflection AI is a conversational AI startup building Pi, a personal AI companion. Pi is primarily chat-based (text and voice via an app and website) with voice capabilities, and is designed to be supportive and emotionally intelligent. Inflection’s team, led by DeepMind co-founder Mustafa Suleyman, has created a custom large language model called Inflection-1 that is aimed at personal advice and casual conversation. Inflection’s latest funding round was in June 2023, with $1.3 billion raised at a $4 billion post-money valuation, backed by Microsoft, Nvidia, and others.
Inflection and Sesame share a vision of AI as a conversational friend. However, Inflection does not make hardware – it relies on users using phones or computers. Strategically, Inflection seems more focused on being an AI service or API, perhaps to integrate into various platforms, whereas Sesame is tightly coupling software with a flagship device. However, Inflection’s $1.5 billion in total funding makes it the second-best funded AI startup after OpenAI, and it is reportedly working with its investors, Nvidia and Coreweave, to build one of the world’s largest AI clusters with 22K Nvidia H100 GPUs. Sesame will need to maintain its technical edge in voice realism to stay ahead of Pi’s evolution. It might also differentiate by target use-cases: Inflection’s Pi might lean toward life coaching and Q&A, while Sesame is aiming for a broader personal assistant role integrated with real-world tasks.
Character.AI: Founded in November 2021 by Noam Shazeer and Daniel De Freitas (both former Google engineers behind LaMDA), Character.AI is a platform that offers real and fictional AI personalities with a broad range of uses in entertainment, instruction, general question-answering, and other areas. By March 2023, Character.AI reached a $1 billion valuation following a $150 million Series A led by Andreessen Horowitz, with tens of millions of monthly active users as of June 2025 and millions of characters created by users as of January 2024. While Character.AI provides a broad platform for chat-based interactions and entertainment, Sesame is targeting deeper personal companionship and ambient voice assistants.
Voice Infrastructure
ElevenLabs: Founded in 2022 by Piotr Dąbkowski and Mati Staniszewski, ElevenLabs specializes in developing natural-sounding speech synthesis software using deep learning. The company raised $180 million in a Series C funding round in January 2025, co-led by Andreessen Horowitz and ICONIQ Growth. ElevenLabs has raised $281 million in total funding from investors, including Sequoia Capital, Andreessen Horowitz, and Nat Friedman, with a valuation of $3.3 billion as of January 2025. Unlike Sesame AI's focus on conversational companions with emotional intelligence, ElevenLabs primarily targets content creation, dubbing, and voice cloning applications across multiple languages for retail and consumer clients such as Epic Games and Twilio as of July 2025.
Deepgram: Founded in 2015 by Scott Stephenson and Adam Sypniewski, Deepgram specializes in developing voice AI platforms with a focus on speech-to-text (STT), text-to-speech (TTS), and speech-to-speech (STS) capabilities. The company has raised approximately $86 million in total funding as of July 2025, with its most recent round being a $72 million Series B completed in November 2022. While Sesame focuses on creating human-like voice companions for direct consumer interaction, Deepgram provides the underlying infrastructure that enables businesses to build their own voice applications. This positions Deepgram more as a technology provider than an end-user product creator, targeting developers and enterprises that need customizable voice AI capabilities for their specific use cases.
Hume AI: Founded in March 2021 by Alan Cowen (a former Google researcher), Hume AI is a research-first company focused on building emotional intelligence into AI systems. In March 2024, the company raised $50 million in a Series B funding round led by EQT Ventures, bringing its total funding to nearly $73 million as of July 2025. Unlike Sesame's focus on creating emotionally intelligent voice companions primarily for consumer applications, Hume specializes in detecting emotional signals across four modalities (voice, facial expressions, language) with hundreds of dimensions of emotional expression. Hume AI's approach centers on its Vocal Emotion API, which can identify over 24 distinct emotional expressions in speech using research validated across 12 countries.
Business Model
Sesame AI operates a dual revenue model: a consumer subscription business centered around its AI companions, Maya and Miles, alongside enterprise licensing, hosted APIs, and model customization. The company's go-to-market strategy centers on an audio-first computing platform that moves beyond screens to enable always-available voice companions through natural-sounding dialogue and presence.
On the consumer side, Sesame plans to monetize through subscription access to its voice companions. While a basic version of Maya and Miles may be available freely, advanced tiers, such as longer conversations, priority access, or new emotional behaviors, are likely to be offered under a paid model. Over time, Sesame intends to bundle these companions with proprietary smart glasses hardware, enabling vertical integration reminiscent of models followed by Apple or Peloton. This strategy lets Sesame retain control of the full ecosystem from device through software, capturing both software subscription revenue and higher-margin hardware sales.
On the enterprise side, Sesame is building out monetization avenues via hosted inference services, premium fine-tuning, and SLA-backed tiers, including enterprise-grade support. The company’s decision to open-source its CSM‑1B model under Apache 2.0 on Hugging Face means that developers can freely experiment, and enterprises can upgrade to hosted or custom voice solutions when integrating expressive speech into their products.
The model may benefit from emergent network effects. As more users and enterprises interact with the voice AI, the underlying Conversational Speech Model can improve in emotional accuracy, timing, and personalization. Moreover, the embedded form factor (AI-powered glasses or always-on audio interfaces) builds switching costs. Once users rely on the companion integrated into daily life, migrating to another platform becomes more disruptive. Sesame’s combination of hardware and software ownership also creates defensibility against pure-software competitors by offering a seamless and personal user experience that is difficult to replicate without control over both layers.
Traction
Sesame AI has released its first AI model and two voice companions, "Maya" and "Miles," with abilities to express emotional fluctuations, tonal variations, and contextual understanding via its CSM model that significantly differentiates them from traditional voice assistants. Performance metrics show the system achieves CMOS scores matching human recordings and delivers a 37% improvement in context understanding compared to existing solutions. Beyond technical performance, public reactions to the demo release suggest high user satisfaction in testing. For instance, some early testers described their conversations as an “AGI moment” for voice AI, noting they felt more natural than anything prior (even compared to OpenAI’s voice). The Verge’s review titled “Sesame Is the First Voice Assistant I’ve Ever Wanted to Talk to More Than Once” suggests equally high user satisfaction. This kind of organic virality, with people sharing shock that the AI felt human-like, is a strong initial signal of product-market fit on the user experience side.
Valuation
As of July 2025, Sesame AI has raised a total of approximately $57 million in funding across two rounds at undisclosed valuations. It first raised $10.1 million in a seed financing round in September 2023, and it raised another $47.5 million in a Series A round led by Andreessen Horowitz in November 2023, along with Spark Capital, Matrix Partners, and BIG Ventures. According to Bloomberg, Sesame AI is in talks to raise approximately $200 million in a new funding round as of April 2025, implying a valuation above $1 billion. The round is reportedly being co-led by Sequoia Capital and Spark Capital.
Key Opportunities
Prioritizing Delightful Personality
Sesame AI has an opportunity to lead the industry in building a companion interface layer that mediates interactions between users and backend AI services with a focus on personality, expressiveness, and emotional resonance — not merely response accuracy. According to CTO Ankit Kumar, Sesame’s goal is to achieve what they term “voice presence”, characterized by emotional intelligence, conversational timing (pauses, interruptions, tone shifts), and contextual adaptation, which elevates dialogue from transactional commands to engaging companionship over time.
By prioritizing personality and emotional coherence, Sesame can differentiate in a field where competing voice AIs increasingly match each other in basic technical performance. This friendly, adaptive UX fosters user loyalty and habitual use, making the companion feel like an integral part of daily routine. That emotional bond introduces stronger engagement, stickiness, and switching costs as users become less inclined to migrate to voice platforms lacking the same persona-driven experience. Over time, this strategy could become a core differentiator as voice agents become commoditized based on capability.
Multimodal Companion Interface
By integrating visual inputs from glasses alongside speech, Sesame could interpret what users look at, enabling the AI to comment on or assist with their surroundings. This is akin to systems like GazeGPT that enhance pointing and attention grounded in LMM-powered visual understanding. Similarly, research on vision-based multimodal interfaces demonstrates that combining visual, audio, and tactile inputs dramatically improves context awareness and communication naturalness. In practice, this means Sesame’s AI could reference objects in view, track user gaze or gestures, and respond proactively with richer dialogue that aligns with what the user is doing. This creates a more intuitive and immersive experience.
Additionally, Sesame is exploring the opportunity of additional sensory modalities such as haptic or tactile feedback, echoing recent prototypes like GPT‑4o-powered glasses for visually impaired users that deliver directional cues via temple-mounted actuators. Research into vision-language-haptic systems like HapticVLM shows how combining tactile feedback with visual and auditory signals enables deeper interaction and sensory immersion. For Sesame, the integration of subtle haptic cues, such as confirming user queries, signaling notifications, or supplementing visual/verbal interaction, could reinforce the perception of a responsive, emotionally intelligent companion.
Transforming Customer Experiences Across Industries
Sesame's emotionally intelligent voice technology has applications across multiple industries, from customer service to healthcare and education. The ability to detect user emotions through vocal tone, speech pacing, and word choice patterns allows for more empathetic and effective interactions.
Enterprise-grade deployments, such as in banking, healthcare, and automotive, stand to benefit significantly from this emotional realism. When Sesame’s voice AI is embedded into contact centers, in-vehicle assistants, or in-store customer-facing kiosks, the CSM system can adapt tone and personality based on conversational history, enabling brands to create consistent, emotionally resonant interactions across touchpoints.
Key Risks
Model Commoditization
Sesame’s edge lies in its emotionally expressive and low-latency voice model, but that advantage is under threat from rapidly evolving competitors. OpenAI, Google, and other well-capitalized players are aggressively advancing voice AI, making lifelike speech capabilities increasingly standardized. Analysts warn that as latency drops and emotional modeling becomes the industry norm, the uniqueness of Sesame’s Conversational Speech Model may diminish unless it continually innovates beyond basic voice realism.
Hardware Execution
Transitioning from research demo to mass-produced consumer hardware brings substantial complexity. Sesame’s planned smart glasses must navigate supply chain logistics, component sourcing, manufacturing, and regulatory compliance — headwinds where numerous better-known companies have faltered. Google Glass, Humane’s Ai Pin, and even Apple Vision Pro stumbled over design, overheating, cost, or consumer confusion, and were subsequently labeled major hardware flops despite strong funding.
Moreover, wearables (especially smart glasses) face reliability constraints like limited battery life, form-factor engineering challenges, and durability concerns. Sesame must demonstrate execution leadership in hardware production to avoid repeating these failures.
Privacy & Regulatory Risks
Smart glasses that are always listening or observing have a well-documented history of triggering public and regulatory backlash. Google Glass’s rapid unpopularity stemmed from concerns over covert recording and infringement on reasonable privacy expectations, leading to bans in public venues and its eventual withdrawal from consumer channels. Modern AI wearables with microphones or sensors raise similar fears around unintended surveillance, particularly if coupled with facial recognition, environmental sensing, or cloud processing without user control. Furthermore, academic reviews emphasize ethical concerns tied to voice assistants, such as data misuse, emotional profiling, and erosion of user trust over time. Finally, regulatory regimes like GDPR and emerging AI governance frameworks could impose compliance obligations, data localization, or opt-in mandates—potentially undermining Sesame’s seamless, always-on UX and increasing operating costs.
Summary
Sesame AI is building a vertically integrated audio‑first AI platform that combines emotionally intelligent voice companions (Maya and Miles) with proprietary smart glasses hardware, underpinned by its transformer‑based Conversational Speech Model (CSM) that delivers sub‑300 ms, context‑aware dialogue with human‑like expressivity. The product suite includes the open‑source CSM‑1B for developers, hosted inference APIs, and forthcoming AI‑powered wearables designed for always‑on use. As of July 2025, Sesame has generated virality among demo users and media reporters and has over 2K stars on Hugging Face. It has raised $47.5 million in Series A and is looking to raise $200 million in Series B at a $1 billion valuation.
Key growth opportunities include expanding enterprise licensing in customer service and automotive, broadening hardware distribution channels, and launching multilingual support to access the 3.4 billion non‑English speaker market. However, Sesame must navigate risks from voice‑model commoditization by Big Tech, the complexity of hardware manufacturing, and emerging privacy and AI governance regulations that could impact its always‑listening wearables strategy.



