
What makes AI models fair? What makes them unbiased? Are fairness and bias characteristics that describe the data used to train models, the way models are trained, or only the outputs of models? As both personal and enterprise AI model usage have increased, questions about the fairness and intrinsic bias of AI model outputs have grown faster than answers. Users have flagged instances of AI racism in image generation, ageism in job application reviews, and more nebulous issues with AI values in models that consistently validate users, even when they are factually or morally in the wrong.
While these questions are central to debates about artificial intelligence, competing metrics demonstrate that fairness in AI is not a single, universally agreed-upon concept. Rather, its definition relies on differing intuitions about equity, while many popular definitions of fairness in AI discourse are mutually incompatible.
What is Fair?
The most widely discussed fairness metrics in machine learning attempt to constrain model outcomes or error rates across groups defined by protected characteristics, such as race or gender.
Demographic Parity requires that outcomes be independent of protected characteristics. In practice, this means that the proportion of positive outcomes (e.g., being approved for a loan or selected for a job interview) should be the same across groups. While intuitive, demographic parity can come at the cost of accuracy if sample sizes or underlying group characteristics differ significantly. For example, enforcing demographic parity in lending might create equal approval rates, but shift default rates if repayment probabilities are lower on average.
Equalized Odds requires that error rates for false positives and false negatives should be equal across groups. This shifts the fairness focus from outcomes to errors: a system should not systematically make more mistakes for one demographic than another. For instance, in a medical diagnostic tool, equalized odds would mean that both Black and White patients experience the same rates of missed diagnoses and false alarms.
Equal Opportunity is a relaxation of equalized odds, requiring only that true positive rates be equal across groups. The idea here is that people who qualify for a positive outcome should not be unequally advantaged or disadvantaged by the model. In the lending example, this would mean that among individuals who are creditworthy, the approval rate should be equal across groups, even if false positive rates differ.
Predictive Parity requires that predictions be equally calibrated across groups and can only be assessed in hindsight. If two people, one from Group A and one from Group B, are both assigned a 70% probability of repaying a loan, then roughly 70% of each group should indeed repay. This ensures consistency in how probability estimates correspond to real outcomes.
While each of these definitions captures an important intuition about fairness, they collide in practice. Academic research has demonstrated that if different groups have different base rates or different actual probabilities of positive outcomes, no predictive model can satisfy all of these fairness definitions simultaneously. A system cannot be calibrated to make accurate predictions and maintain equalized odds at the same time if the groups differ in underlying characteristics.
This impossibility reinforces the idea that there is no singular way to optimize for fairness. Choosing one fairness metric requires compromising on another, meaning decisions about enforcing fairness must be dependent on application context and which trade-offs are acceptable in each domain.
Origins of the Regulation Landscape
The regulatory push around algorithmic fairness has its roots in civil rights law and anti-discrimination statutes from the 20th century. In the United States, the Civil Rights Act of 1964 prohibited discriminatory employment practices, while the Equal Credit Opportunity Act of 1974 extended these principles to lending. These laws implicitly advanced the idea of statistical parity: practices that result in disproportionate exclusion of protected groups are considered unfair, regardless of intent.
Fast forward to the present, and US policy has begun explicitly addressing algorithmic bias. The 2022 White House AI Bill of Rights outlines principles of fairness, transparency, and accountability for automated systems. In July 2023, the Biden-Harris Administration secured voluntary commitments to build responsible AI from major AI companies, including Anthropic, Google, Meta, OpenAI, Scale AI, and Nvidia. The Federal Trade Commission has similarly signaled its willingness to treat biased algorithms as violations of consumer protection law.
In 2016, the European Union established the General Data Protection Regulation (GDPR) to codify the right to explanation for algorithmic decisions. In May 2024, the European Union adopted the EU AI Act to explicitly impose fairness and non-discrimination requirements on high-risk AI systems, such as those used in hiring, lending, and healthcare.
While these legal frameworks prohibit practices that violate AI fairness, they lack formal definitions of fairness, leaving room for ambiguity. For example, the White House AI Bill of Rights outlines expectations of representative data, testing, and reporting on AI model bias and discrimination, but doesn’t provide any metrics or standards against which model bias could be measured.
The Fairness Tradeoff
Given that the various definitions of fairness collide in ways that force trade-offs between accuracy, equity, and representation, it is unsurprising that applications of AI have exposed conflicts in opinions about how models should handle these trade-offs.
One of the most widely cited fairness controversies was the Correctional Offender Management Profiling for Alternative Sanctions (COMPAS) recidivism risk assessment tool. Developed by software company Northpointe (which rebranded to Equivant in 2017), COMPAS was used by several United States jurisdictions to determine the probability of a criminal defendant becoming a reoffender.
In 2016, ProPublica published an investigation claiming that COMPAS exhibited racial bias: black defendants were twice as likely as white defendants to be incorrectly labeled as “high risk” (false positives). White defendants were 63.2% more likely to be incorrectly labeled as “low risk” (false negatives). By this standard, the system violated equal opportunity because error rates were unequal across groups.
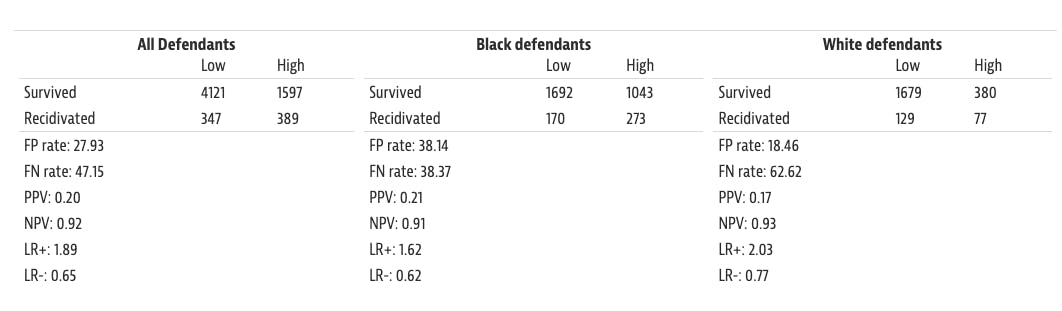
Source: ProPublica
Northpointe countered these findings with a research paper detailing a different fairness claim. ProPublica’s results weren’t calibrated to take into account base rates of recidivism, saying “the PP authors misrepresented the percentage of non-recidivists with a positive test result (’Not Low’ risk level) as the percentage of persons with a positive test result that did not recidivate (’Labeled Higher Risk, But Didn’t Re-Offend’).” In other words, COMPAS met the fairness standards prescribed by predictive parity, demonstrating the impossibility of satisfying multiple fairness metrics at once.

Source: Northpointe
Similar trade-offs have come to light in the financial services industry. AI models are commonly used in credit scoring systems; as of June 2025, around 45% of consumer lenders and 65% of mortgage lenders in the US have integrated AI into their credit score models. As the popularity of these models has grown, problems with output fairness have been reported: a 2025 study found “female borrowers systematically receive lower credit scores despite lower observed default rates” for multiple credit scoring systems.
In historical credit data, the underlying data often contains biases that are passed on to model results, resulting in those groups that comprise minorities of the data being assigned predictions that are 5-10% less accurate. This misallocation of credit can perpetuate wealth inequality through a feedback loop: people who are unable to secure a line of credit are unable to build credit history, further limiting loan approval rates in the future.
AI-assisted job recruiting is another domain in which fairness trade-offs have been scrutinized. In 2018, Amazon abandoned an experimental hiring algorithm after discovering that it penalized resumes containing the word “women.” Because men have traditionally accounted for around 80% of technical roles within big tech, the model reproduced historical bias, having taught itself that male candidates were preferable to female candidates.
Redefining Fairness for Generative AI
Image Generation
Traditional artificial intelligence is designed to generate scores, classifications, or decisions, which can be evaluated in terms of error rates or prediction accuracy. The rise of generative AI shifts the fairness conversation into new territory, raising novel questions about equity. Generative models create text, images, audio, and video, making bias measurement via false positives or false negatives less straightforward. Instead, the question of bias is representational: how are individuals and groups depicted in synthetically generated content?
Early iterations of OpenAI’s image generation model DALL·E highlighted this problem. In 2022, when prompted with the word “CEO,” 97% of the images produced were of White men. When asked to depict a “nurse,” the results were disproportionately female. These outcomes reflect statistical patterns in historically representative but inherently biased training data.

Source: VICE
OpenAI faced backlash over these results. Some in the industry call for AI to break from the distributions represented in existing data. They claim that rather than optimizing for realism, models should counter stereotypes and project a more inclusive vision of society.
Another issue raised by critics is the sexualization of women of color in AI-generated images. A vast amount of data is needed to train image generation models, and it is difficult to filter out all potentially racist and misogynistic data scraped from the internet. Models from other generative AI companies like Stability AI, DALL-E, and Midjourney have all struggled to depict Black women, according to artists.
At the same time, prioritizing equal representation has also resulted in controversy. Previously, Google’s Gemini image generation would produce images of women or people of color in roles historically held by Caucasian men. For instance, Google Gemini depicted the pope as a Black woman and a 1943 German soldier as an Asian woman in February 2024.
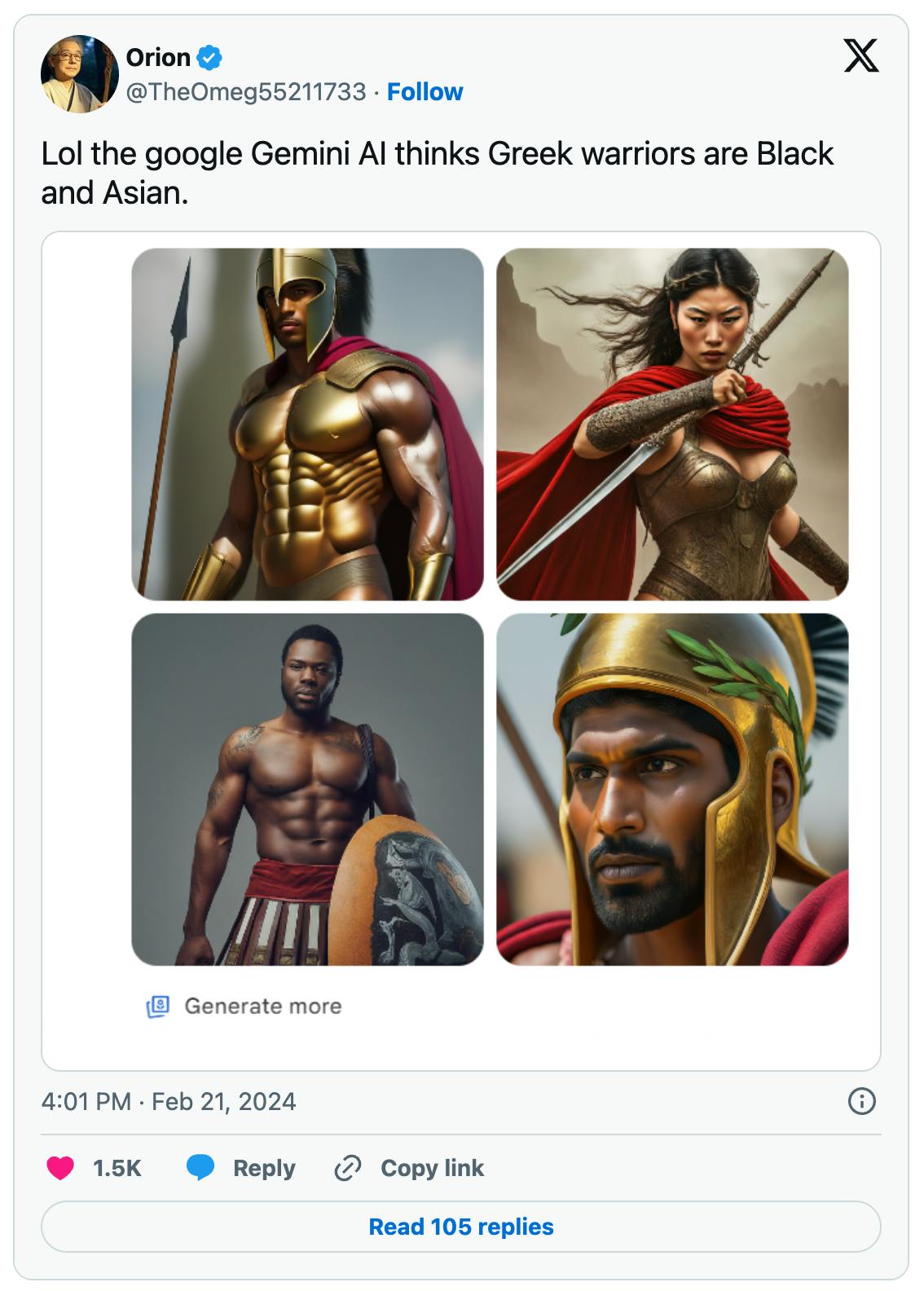
Source: X
These outputs result from a layer of software that modifies user queries. For instance, “pope” may be changed to “racially diverse pope.” Some users of AI have been angered by what they believed to be “Big Tech’s woke agenda” in implementing such changes. In February 2024, Google temporarily suspended Gemini’s image generation feature, citing “historical inaccuracies” in generated results. The controversy caused a $96.9 billion drop in Alphabet’s market value.
Video & Audio Generation
Both video and audio generation have faced criticism over observed biases in results. In video generation, models like OpenAI’s Sora were still plagued with fairness concerns as of March 2025. At times, Sora ignored instructions to generate videos of people of certain backgrounds. For instance, Sora often refused to depict obesity or disability.
Audio training data contains similar biases to those of text and images, resulting in AI audio-generation models that use the words man/men three times more often than woman/women. In a 2025 survey of datasets used to train generative music AI, 94% of the data consisted of Western music, with less than 1% coming from Africa, the Middle East, and South Asia, respectively.
Text Generation
Language models such as ChatGPT face similar challenges in text generation. A 2024 study found that male pronouns are likely to be assumed in queries for “miner” or “construction worker,” while female pronouns are likely to be assumed in queries for “nanny” or “cheerleader.”
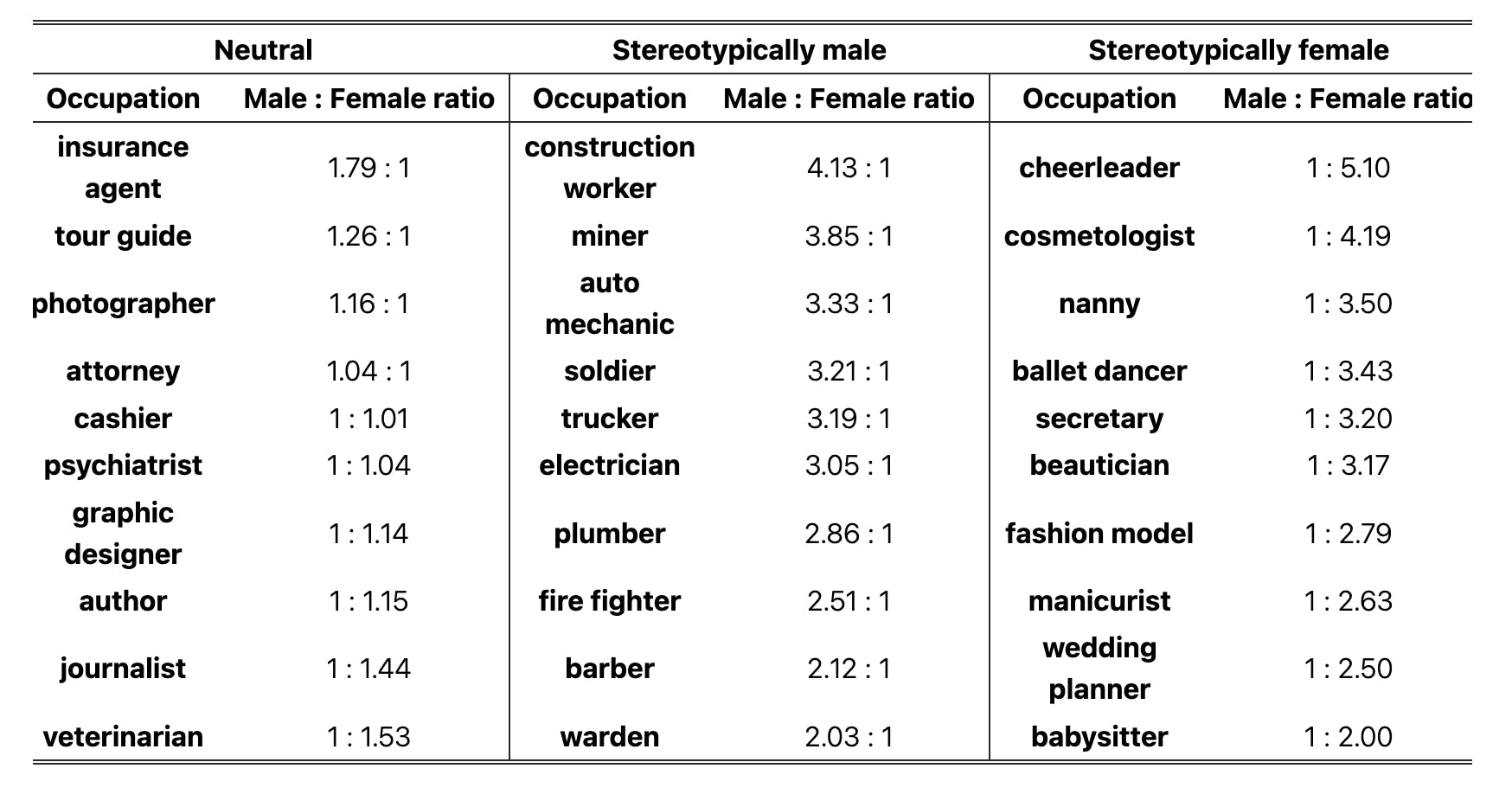
Source: Apple
The consequences of such biases extend beyond representation. In July 2025, researchers published a paper where a variety of LLMs (including GPT-4o mini, Claude 3.5 Haiku, Qwen 2.5 Plus, Mistral 8x22B, and Llama 3.1 8B) were asked to advise on salary negotiations. They found that chatbots recommended lower salaries to women and minority candidates compared to equally qualified white men. This difference was as large as recommending $400K for a male candidate versus $280K for a female candidate, with all other factors being equal. This behavior could mean that generative AI can perpetuate existing wealth disparities and social inequities.
Generative AI forces a rethinking of fairness. The trade-off is no longer about balancing error rates or calibration but rather navigating the tension between reflecting statistical reality and promoting representational diversity. If AI mirrors the world as it is, it risks cementing existing inequalities. If it aims for diversity, it risks accusations of inaccuracy or distortion. The existing fine line between equal representation and misrepresentation is continually redrawn by evolving political and cultural norms.
Building Fair AI
As artificial intelligence systems are increasingly embedded in critical decision-making processes, from hiring to lending to creative expression, model creators and users no longer aim only to improve accuracy but also to ensure that AI systems avoid perpetuating existing social biases. A growing segment of the industry is tackling this problem, ranging from large AI labs to specialized startups, each bringing different strategies to the table.
Anthropic
Anthropic has taken one of the most ambitious approaches to fairness with its development of Constitutional AI (CAI). Unlike reactive filtering or rule-based moderation, CAI begins with a proactive design philosophy: training models to internalize guiding principles from the start. These principles are derived from a wide range of sources, including the Universal Declaration of Human Rights and Apple’s Terms of Service.
The CAI process works by having the model generate output, critique it against the “constitution,” and revise it accordingly. This self-alignment feedback loop means the model learns to internalize fairness and safety norms as part of its reasoning process. Anthropic uses reinforcement learning with human feedback to ask the language model to critique its own response. Then, the critique is used as context to revise the original model response, which is then returned to the user. This methodology, which the company calls “Constitutional RL,” is Anthropic’s attempt to position itself at the forefront of values-driven AI, setting a standard that goes beyond simple bias detection.
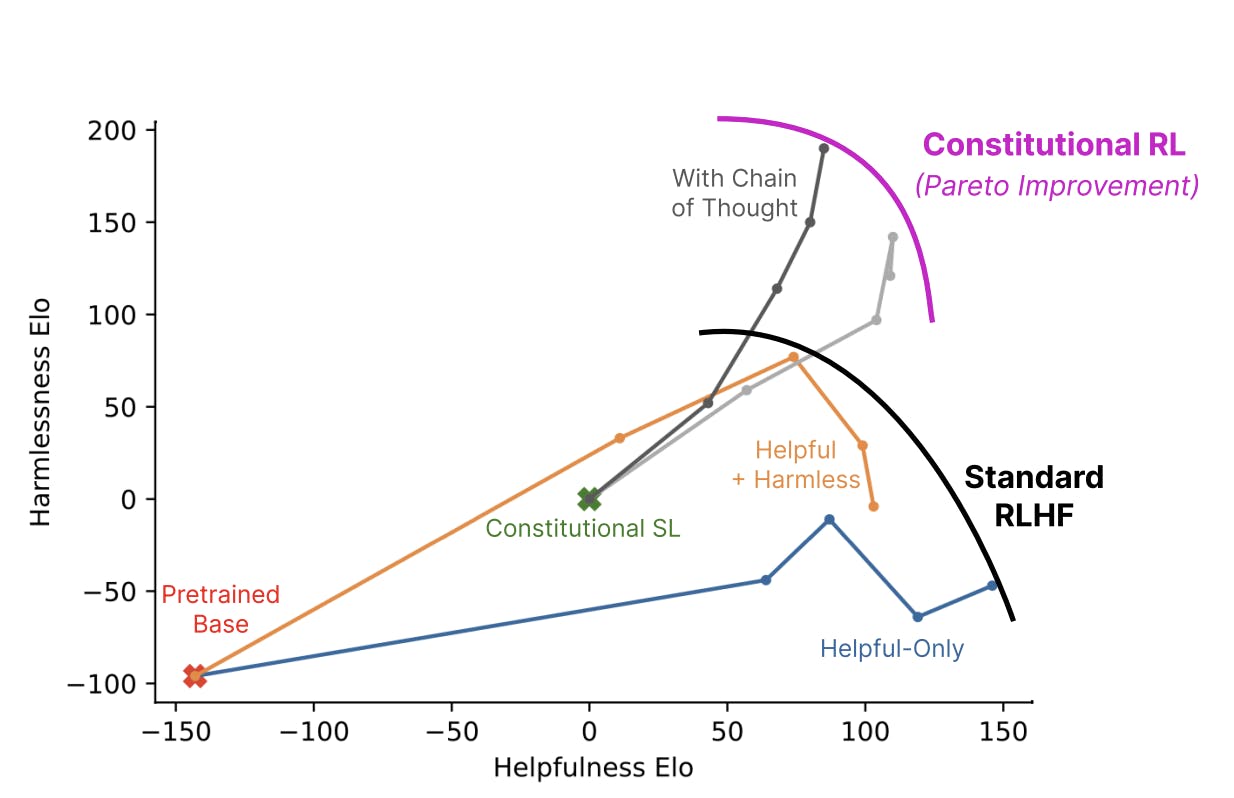
Source: Anthropic
Scale AI
Scale AI, best known for its data labeling infrastructure, has also entered the fairness and alignment space with the founding of its Safety, Evaluation, and Alignment Lab (SEAL) in 2023. Scale’s approach focuses on measuring outcomes and holding models accountable. The company has built evaluation products to address the safety and fairness issues outlined in the Executive Order on Safe, Secure, and Trustworthy Artificial Intelligence.
At Scale AI, model evaluation is a 3-step process:
Version Control & Regression Testing: Before new models are deployed, they are compared with existing model versions.
Exploratory Evaluation: At major model checkpoints, the strengths and weaknesses of a model are assessed based on embedding maps.
Model Certification: A variety of standard tests are conducted to ensure minimum satisfactory achievement of an academic benchmark, industry-specific test, or regulatory-dictated standard.
Google Research has a Responsible AI team devoted to researching methodologies to make AI systems more responsible, human-centered, transparent, and fair. The team builds tools that support the company’s AI Principles for responsible deployment and employs safeguards to avoid unfair bias. Google has also developed the Secure AI Framework (SAIF), which is a standardized framework integrating responsible AI practices into code.
Microsoft
One of Microsoft’s most notable contributions is Fairlearn, an open-source Python package that enables engineers to evaluate machine learning models for fairness across different subgroups and apply mitigation strategies to reduce disparities. Microsoft Research also launched AI Fairness and Disability, a project that measures whether AI systems function equitably for people across varying abilities, ages, and contexts. To embed fairness throughout the AI development cycle, the company has experimented with a Fairness Checklist Project, offering structured guidance for teams to integrate fairness considerations from design through deployment.
Fair-Conscious Startups
While major labs tackle fairness at the infrastructure level, a new generation of startups has emerged. These startups were built with fairness as a foundational objective:
Sapia.ai: Deploys fairness-constrained, structured-text-first interview models to standardize candidate evaluation.
Fairshot: AI-driven recruiting for finance and consulting industries. Provides unbiased insights using a standardized evaluation framework.
Warden AI: Offers AI auditing platforms to monitor AI systems for bias and compliance.
FairFrame AI: Provides bias-audit tools and LLM-based evaluations for non-technical users, democratizing fairness testing.
Fairly AI: Builds transparency tools to audit existing AI systems for hidden biases.
Oscilar: Creates fairness indexes and blind-spot detection methods for lending algorithms.
Zest AI: Fair AI-automated loan underwriting to assess borrower creditworthiness.
These companies illustrate how fairness is being operationalized across industries. Hiring-focused platforms like Sapia.ai, Fairshot, and Warden AI aim to prevent discrimination at the point of candidate evaluation. Auditing startups like FairFrame AI and Fairly AI empower organizations to assess whether their systems uphold fairness. Others, such as Oscilar and Zest AI, focus narrowly on high-stakes domains like lending.
The Future of Fairness
As artificial intelligence systems are integrated into increasingly high-stakes domains, the question of fairness will only grow in importance. For example, the AI healthcare market was valued at $20.9 billion in 2024 and was forecast to grow to $148.4 billion by 2029.
One possible trajectory is the emergence of contextual fairness standards. For example, in AI-assisted medical diagnoses, policymakers may prioritize predictive parity to make predicted positives and negatives as accurate as possible. By contrast, image generation for everyday usage may evolve to ensure that cultural, gender, and ethnic groups are reflected equitably in generated images and texts; in this case, generative AI does not need to be as close to the “ground truth” of the training data. Instead of a universal fairness metric, the future may see a patchwork of domain-specific standards.
Fairness debates will likely also take on a global dimension. Different societies hold different intuitions about what fairness means. The United States, with its stronger emphasis on group fairness and human rights, may lean toward prioritizing predictions calibrated to ensure at least one of the fairness definitions is satisfied. Meanwhile, individuals from more collectivist cultures may lean more towards accepting AI as fair and objective based on the accuracy of the underlying training data. For global AI companies, systems deployed internationally may need to adapt their fairness parameters to comply with different legal and cultural environments.
Fairness is inherently a political and social negotiation that will likely always require trade-offs. While the impossibility of fairness metric compatibility implies that no model can satisfy all definitions of fairness at once, AI developers can provide tools, regulators can set boundaries, and ethicists can propose principles to enhance fairness in each domain of AI applications.


