
Actionable Summary
Data is the new oil: In 2006 people started saying data is the new oil. The future of every digital business will be defined by its ability to effectively capture the value from data. From devices to the cloud, data is exploding. This proliferation represents a massive opportunity for organizations to build a data advantage.
The infrastructure behind the data: As a result of this explosion of data and the exponential benefits that AI presents for businesses in 2022, the next question is “What are the core infrastructure building blocks to drive that value?
Snowflake’s journey: Snowflake is a cloud data platform founded in 2012 by disgruntled ex-Oracle architects. The company started their journey as a cloud data warehouse for storing data and running analytical compute workloads. However, Snowflake has transformed into a “data cloud” that provides a wide variety of cloud services across data sharing, application development, cybersecurity, and most recently transactional database functions.
Databricks’ journey: Databricks was founded the following year in 2013 by a group of computer science researchers at Berkeley. Their journey started as a data lake supporting open-source Apache Spark. Today, it has expanded into a broader platform that includes a Databricks marketplace incorporating data storage and positioning itself as a data lakehouse.
Clash of the titans: The similarities between their products and data focus has kicked off a clash between these data titans, which will ultimately determine who wins the data infrastructure for the modern enterprise. From public blog clashes to indirect attacks at conferences, both companies are battling it out.
Differentiation: The distinction between both companies has become increasingly blurry due to their rapid product velocity. In our view, the winner will be defined less by the technology and more by the go-to-market strategy, depth of product penetration, and execution of the leadership teams.
The market opportunity is enormous: According to IDC, worldwide spending for big data and analytics solutions is worth over $215 billion. Both companies will benefit from this TAM because they provide the core infrastructure for driving value from big data. And we’re just getting started. Gartner estimates only 30% of new workloads are on cloud native platforms today. We believe the market is large enough to create two established companies similar to the dynamics with hyperscalers like AWS and Azure.
This report: This deep-dive explores the intricacies of these companies as they battle it out.
The Birth of the Titans
In 2012 a veteran group of Oracle data architects were frustrated with the company’s on-prem data solutions. Benoit Dageville and Thierry Cruanes complained to Oracle’s management and even tried to build a solution internally, but were denied. They believed there was a much better way to store data, especially at a time when the cloud was gradually growing in popularity. This was an audacious statement to make at the time. Hadoop was the most transformative product the industry had seen, and Cloudera raised a major round two years later in 2014 signaling strong momentum. Trusting the trend Benoit and Thierry quit their jobs to build their better way.
Benoit and Thierry went on to create a cloud-native data warehouse in 2012 riding the wave of cloud adoption. The first product was publicly launched in 2014 after it operated in stealth for a few years. Snowflake’s founders were not only data obsessed, but also avid skiers; naming their company after the “snowflake schema.” As of August 2022, Snowflake has grown to more than $50 billion in market cap. From January 31, 2019, to July 31st, 2022, the company grew revenue by over >100% CAGR to over $1.64 billion. It now generates over $172 million in free-cash flow and net dollar retention of nearly 170%, one of the highest within the software industry. Snowflake set the stage for modernized data platforms.
Databricks followed soon after in 2013. It emerged from a university research project out of the AMPLab project at the University of California, Berkeley. Ali Ghodsi and his co-researchers developed Apache Spark as a much faster alternative to Hadoop, an outdated alternative. When the original team realized that so many of their users had difficulty setting up Spark themselves, they quit their university jobs and set out to build a company dedicated to supporting the open source version of Spark. As of August 2021 Databricks was valued in a private venture round at $38 billion. The company has over $1 billion in annual recurring revenue at a growth rate of over 80% year-over-year with net retention of more than 150%.
Today, both companies have become giants within the industry. Their products represent the massive shift towards enterprises making use of their growing mountains of data. Traditionally, companies used an on-prem data warehouse to store the data and run after-the-fact analysis with BI dashboards.. The rise of the cloud along with tools like Databricks and Snowflake have made it possible for this growing pool of data to help companies identify insights, improve products, and make smarter decisions in near real-time.
The emerging clash between both companies is moving beyond data storage and into the heart of owning the cloud data stack within the modern enterprise. Snowflake positions itself as wanting to be the “data cloud” for companies while Databricks positions itself as a “data lakehouse.” These new terminologies are meant to capture user’s attention with each company vying for each other’s audience. Snowflake has traditionally been known as a data warehouse for business analysts and data engineers. Databricks has traditionally been known as the data lake for data scientists and ML engineers. But those lines are beginning to blur. Snowflake has developed new offerings such as Snowpark for Data Science, support for Python, Snowflake for Apache Iceberg and transactional databases to win the hearts of open-source developers and data scientists. Meanwhile, Databricks has launched recent offerings such as Databricks SQL in 2021, Delta Lake features and Unity catalog which caters towards the data storage and security conscious customers; Snowflake’s bread and butter.

What do Snowflake and Databricks do?
Already have a handle on what these products do? Skip to where the story begins.
To understand the contrast between Snowflake and Databricks you have to understand the promise of AI. The biggest misconception among executives is that you can easily “use AI on your data” and see value overnight. Building an artificial intelligence model that effectively delivers value for a business is much more involved. This meticulous process involves data gathering, cleaning, and preparation in order to build a model around that data. After multiple iterations a model is ready to be operationalized.
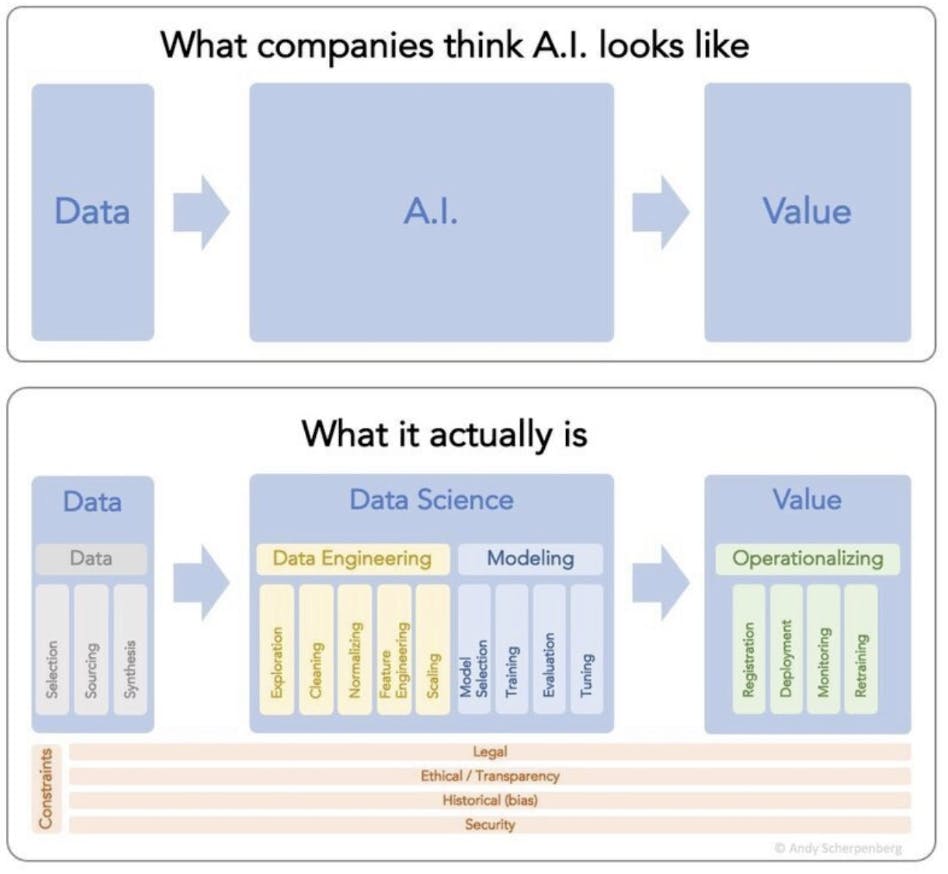
Source: Andy Scherpenberg
Snowflake and Databricks have created value in different layers of this stack. Snowflake focuses on the left, all the way from data storage to data engineering, including most of the components at the bottom such as implementing strict security and legal policies on data. Databricks historically has focused more on the steps from data modeling to operationalizing data models.
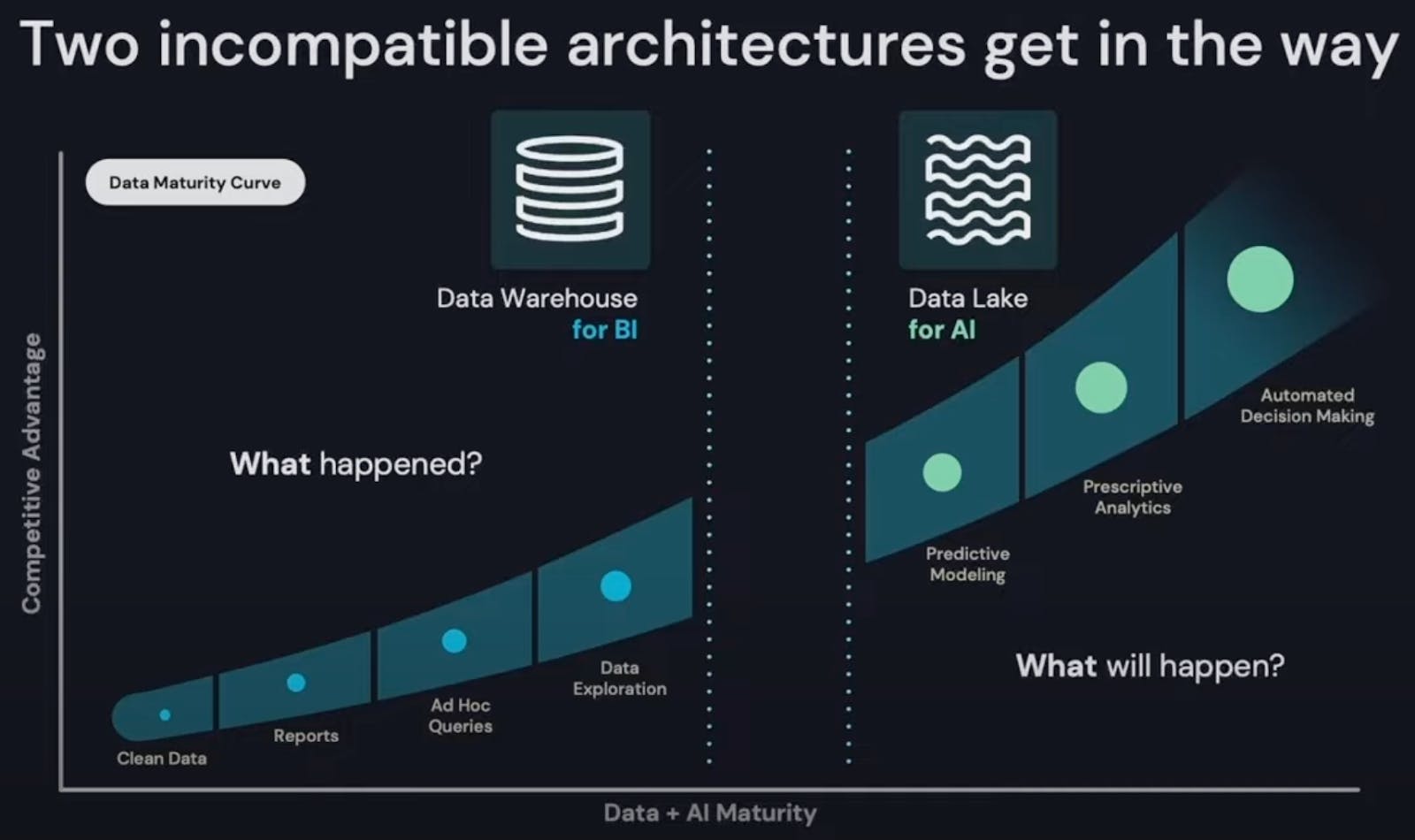
The process of implementing analytics and big data for every company begins with understanding “what happened?” versus “what will happen?” Data warehouses store the data required to answer the question of "what happened”.Data lakes manage the data required for building models to answer the question of “what will happen?”
Snowflake
Snowflake is a cloud data platform built on the foundation of a data warehouse that enables customers to consolidate data into a single source of truth and drive meaningful business insights, build data-driven applications, and share data.
Databricks
Databricks is similarly a cloud data platform but built on the foundation of a data lake. That data lake is used for data storage but its purpose is focused on enabling data scientists to leverage machine learning applications to analyze the data. The platform is primarily geared towards data science and machine learning applications.
Setting the Stage: A Summary of Our Findings
Databricks and Snowflake have empowered thousands of companies to access, explore, share, and unlock the value of their data. Their platforms have leveraged the elasticity and performance of the cloud to solve data silos. Both platforms enable customers to unify and query data to support a wide variety of use cases. The battle between Snowflake and Databricks comes from the following themes:
Similarities in Vision
One data platform to rule them all
Both companies are chasing the same vision of becoming the single “big data'' platform for the modern enterprise. Snowflake positions itself as the Data Cloud and Databricks positions their platform as the Data Lakehouse. The goal of each company is to enable every customer to store and utilize as much data as possible within one platform.
Snowflake added support for transactional data workloads to reduce the need for customers to copy data out to other databases. They also enable application development within the Snowflake environment through their acquisition of Streamlit. The Snowflake marketplace takes this one step further by incentivizing developers to build new applications within the data cloud.
Databricks is implementing a similar strategy by marketing itself as a Data Lakehouse; a new architecture that combines all the benefits of a data lake and a data warehouse into one platform. This means an enterprise can cover all their data requirements with a single platform rather than implementing multiple solutions.
Many companies today use a variety of software platforms within their data stack. But most companies would love to reduce the need for multiple vendors by buying one platform that covers the majority of their data needs. Snowflake and Databricks recent product innovations are all geared towards achieving this goal for customers as we will explore in this report.
Cost Savings and seamless data transfer without ETL
Consistent innovation in the space has driven down the cost for compute and storage. Snowflake’s biggest innovation since its inception was the launch of Unistore and hybrid tables. Unistore is a transactional database that will make it easy for customers to easily move data between the data warehouse and operational databases seamlessly. That move threatens the Extract, Transform, and Load ( ETL) market as some companies no longer have to worry about writing python scripts to transform data from their transactional databases into Snowflake or Databricks. Customers will likely save costs by avoiding the need to purchase extra software such as Fivetran or DBT Labs.
Multi-cloud benefits
The move from on-prem to the cloud has been the single most important catalyst for both companies. Databicks and Snowflake benefit from being multi-cloud. This enables customers to adopt multiple clouds on their platform like Amazon AWS, Microsoft Azure and Google Cloud Platform (GCP). At their recent Data + AI Summit Databricks claimed that over 80% of their enterprise customers today use more than one cloud. Both Snowflake and Databricks built their businesses on the success of the hyperscalers and effectively pay a “tax” to do so.
Differences in Approach
Data Science vs. Data Analytics
Databricks originated as a data lake built around open-source Spark for data science and ML use-cases. Meanwhile, Snowflake built a cloud data warehouse that could be used for business intelligence analytics. Most customers will use both Databricks and Snowflake for their respective areas of expertise. But that dynamic is rapidly changing as Snowflake and Databricks continue to position their product portfolios to more closely compete with each other.
Open vs. Closed Ecosystem
One key difference between these platforms is where the data lives and who is responsible for it. Snowflake is widely regarded as a closed platform because they control their entire storage and compute platforms in a closed ecosystem. Meanwhile, Databricks is open source. All their key product lines from Delta Lake to Delta Sharing can be implemented for free. Customers can then turn to Databricks’ enterprise offerings for more advanced features and support.
Pre-Packaged vs. Configurable
Snowflake provides a packaged, off-the-shelf solution that allows companies to get basic analytics off the ground in minutes. Databricks offers much greater customization and configuration offering customers full control over their set-up. More on this information can be found in this report.
Narrowing the gap
Each solution continues to converge from a different direction addressing a newer part of the data landscape than they previously served.
Snowflake has gradually moved into enabling more advanced AI/ML use cases by incorporating data lake features that support unstructured data. Snowflake now supports more data science libraries like Anaconda, languages like Python, and now have features like Snowpark runtime.
Databricks is evolving beyond advanced data processing for data scientists. Over the past three years they’ve started building towards their Data Lakehouse vision by launching products like Delta Lake, Unity Catalog and Databricks SQL. These products enable more robust data storage and incorporate secure governance policies around the data.
If you want to go deeper in comparing and contrasting Databricks’ and Snowflakes products take a look at the Product Differences in the Appendix
The Bottom Line
Building the universal data stack will require a platform that extends from simple data storage all the way to complex machine learning functionality. Both companies are positioned to capitalize on the explosion of data. They both offer cheap and performant storage and analytics. They also both have large ecosystem partners. They have rapid product velocity and significantly higher ratings from customers and peers which allows them to compete with the likes of Azure and AWS.
The clash of the data titans goes beyond simply building a good business in a large market. Both Snowflake and Databricks have aspirations to become the universal data platform and clearly see each other as an obstacle in their path.
We’re about to get into the history of the data revolution, which can involve a broad swath of technical terms. To brush up on concepts like databases, data warehouses, data lakes, and ETL see “Talking the Talk” in our Appendix.
The Past: How Hadoop got Duped
While Databricks and Snowflake are some of the most well-positioned companies to take advantage of the data revolution they were only founded in the early 2010s. For the foundations of that revolution we have to go back further in time.
One technology that stands out around the birth of the modern data stack: Hadoop. Starting out first as a successful open-source project and then increasingly becoming one of the most promising companies to tackle data insights. Several companies were built around Hadoop (Hortonworks, Cloudera), but Hadoop itself was always an Apache project.
Understanding the rise of Hadoop, Cloudera and their eventual downfall sets the stage for Snowflake and Databricks. Learning from their mistakes will also be a necessary step for any data platform to stand the test of time.
The Founding Fathers of The Data Revolution
Believe it or not, Hadoop is actually an acronym. It stands for High Availability Distributed Object Oriented Platform. Quite a mouthful! Hadoop is an open source, Java-based software platform used to manage data processing and data storage for big data applications across structured and unstructured data. Hadoop scales up from a single server to thousands of machines. It isn’t a standalone solution for data storage or relational databases. Instead, its an open-source framework for processing large amounts of data in real-time. Hadoop works by distributing data rapidly across computing clusters, either on-premises or in the cloud, sidestepping the failure rate limitations of even the most powerful individual machines.
During 2006, IT teams were unable to process and run complex analysis on large amounts of data in an efficient way. Hadoop changed this entire dynamic and gave birth to the rise of the Hadoop Distributed File System (HDFS). That system provided data storage at the time, and Apache Hive (launched in 2010) was a first generation data warehouse. In addition to the file system, MapReduce provided the programming framework to break up complex data processing jobs on large data sets into discrete operations that could be distributed across hundreds of individual compute nodes.
In 2008 engineers from Facebook, Google, Oracle, and Yahoo came together to create Cloudera. The idea arose from the need to harness the power of Hadoop. Cloudera uses Hadoop-based support and services for processing data. For years, Hadoop helped businesses store, sort, and analyze large volumes of data. Cloudera was created to help users deploy and manage Hadoop.
Before the era of the cloud you had data warehouses built on-premise and had to run on a single system that had to be incredibly powerful (lots of cores, memory and storage). Because the hardware resources were fixed users had to pay more for more analysis with less compute and memory. During the initial ETL stage analysts had to refine the raw data into a specialized format that restructured the data for extracting insights they cared about.
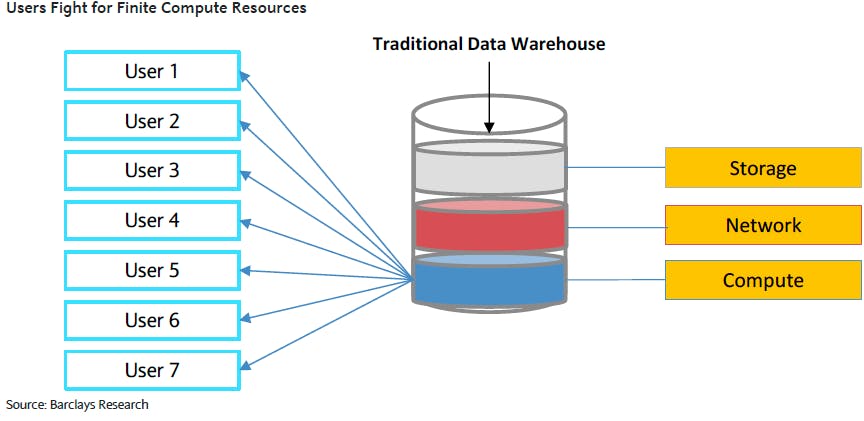
Source: Barclay’s Research; “Snowflake Computing Initiation Report"
Codependence of compute and storage: Hadoop never had an efficient separation of compute from storage. Hadoop enabled companies to have a data lake (storage) with querying and analytics on top of data (compute), but it required running extremely complicated software clusters and became a massive headache for IT and data scientists to use.
Complexity: Hadoop can be difficult for end-users to work with. Hadoop architectures can also require significant expertise and resources to set up, maintain, and upgrade. As cloud adoption grew and new tools became more sophisticated people moved away from Hadoop.
On-premise architecture doesn’t scale: Legacy database architecture wasn’t originally designed for cloud-based workloads. These shortcomings have resulted in data silos, governance challenges, and limited business insights. Big data architecture has attempted to solve the problem of data silos with large pools of cost-effective storage, but in doing so have often created data integrity and governance challenges.
Operating system shifts: In 2020 a leading Hadoop provider shifted its product set away from being Hadoop-centric, as Hadoop is now thought of as “more of a philosophy than a technology.” 2021 has been a year of interesting changes. In April 2021, the Apache Software Foundation announced the retirement of ten projects from the Hadoop ecosystem.
The Evolution of Hadoop
Over time on-prem Hadoop saw a large decline in users giving way to a cloud-based open source analytics tool. Out of the ashes of Hadoop rose a new project: Apache Spark. This module eventually emerged as an independent distributed analytics platform that makes the compute side of Hadoop much faster.
Data is first loaded into memory across the distributed nodes in a cluster so that all analytical tasks performed on it could be done entirely in-memory, instead of working over a storage layer. This can make certain operations 100x faster over Hadoop, and suddenly answers could come in seconds or minutes instead of hours or days. Databricks was created around the open-source Spark engine in order to enhance and support it. Apache Spark has become one of the primary data science and machine learning tools in use today.
Limitations of the Past Set The Stage For The Future
Hadoop wasn’t alone in failing to scale during the explosion of big data. Companies like IBM and Teradata were all hailed as dominant big data players in previous decades. Underlying architectural weakness caused these solutions to suffer the same limitations as Hadoop. Those failures helped to set the stage for Snowflake and Databricks.
Struggling with multiple data types: Legacy database architectures typically fail to capture, and classify semi-structured data adequately. Data on these platforms are generally stored in inconsistent formats or have duplicates.
Struggling with large data volumes: Legacy on-prem databases suffered from storage capacity constraints, redundant data storage, and insufficient compute resources to ingest large volumes of data. Big data architectures often took hours or days to query large data sets.
Inability to create data sharing: Many of these legacy database platforms lacked the ability to share read/write data with multiple parties. It always resulted in data copies, data security concerns, and poor governance.
Difficult to operate: Legacy databases required the user to have to maintain the underlying infrastructure and there was a significant amount of effort required to configure it (often requiring a new programming language).
Worse delivery models: Legacy platforms lacked the advanced optimizations to efficiently access only the data required to deliver the desired results. These platforms were slower and required constant tuning for manually organizing data prior to use. Real-time products like Snowflake and Databricks have enabled consumption-based or pay-as-you-go business models for infrastructure tools.
The Present: Rise of the Super Cloud
The move from on-prem to the cloud has redefined modern data infrastructure. All these inadequacies among legacy tools were the exact kind of limitations that drove the likes of Benoit Dageville, Thierry Cruanes, and Ali Ghodsi to reimagine data infrastructure.
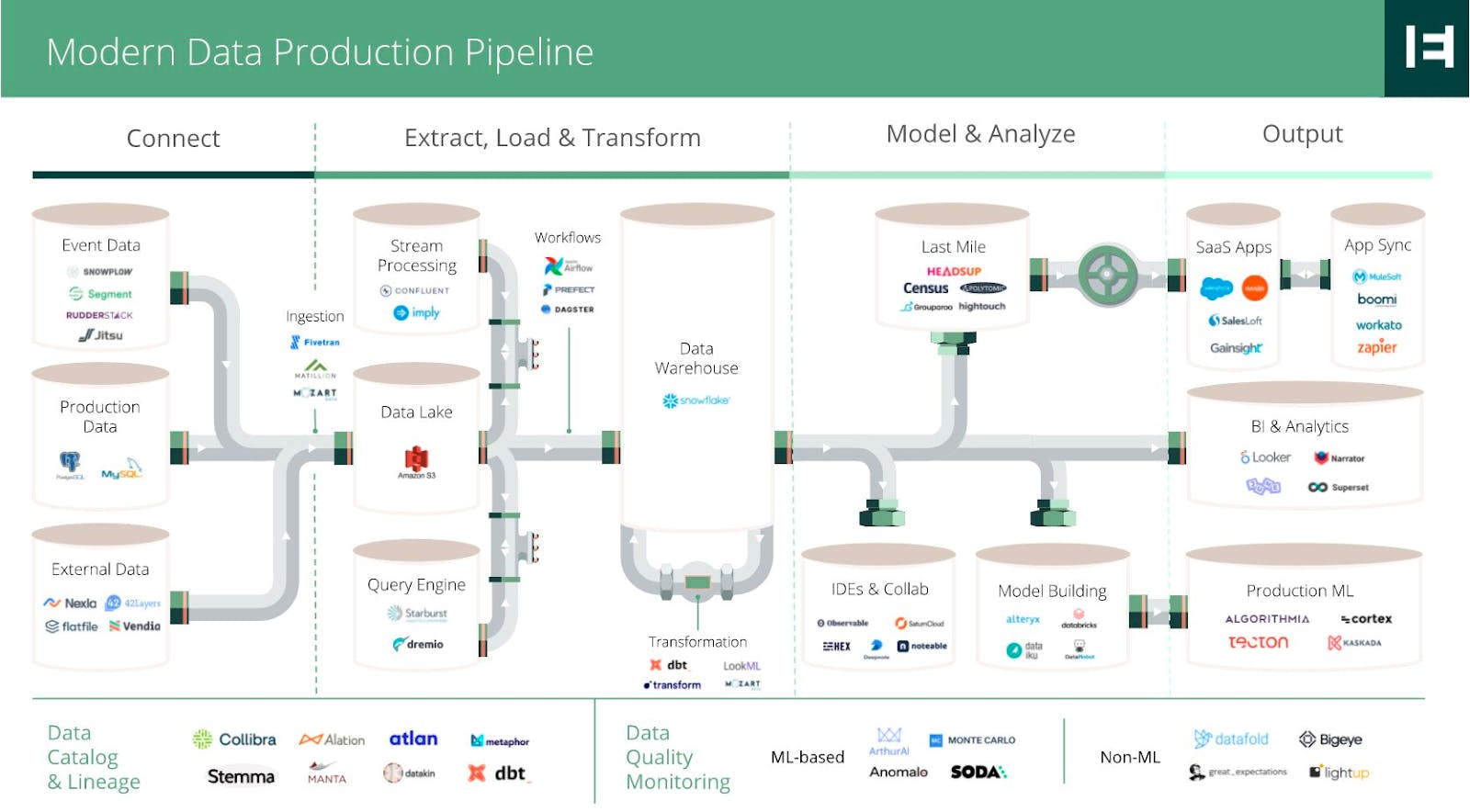
Source: Emergence
Building The Snowflake Platform
The Data Cloud
Snowflake is a data cloud platform that was publicly launched in 2014. Snowflake started its journey as a "Data Warehouse-as-a-Service.”, but it has evolved to become a much broader platform by extending into security, data sharing, and marketplace capabilities. At the latest Snowflake Summit the company said their new platform encompasses every service Snowflake provides for its customers.
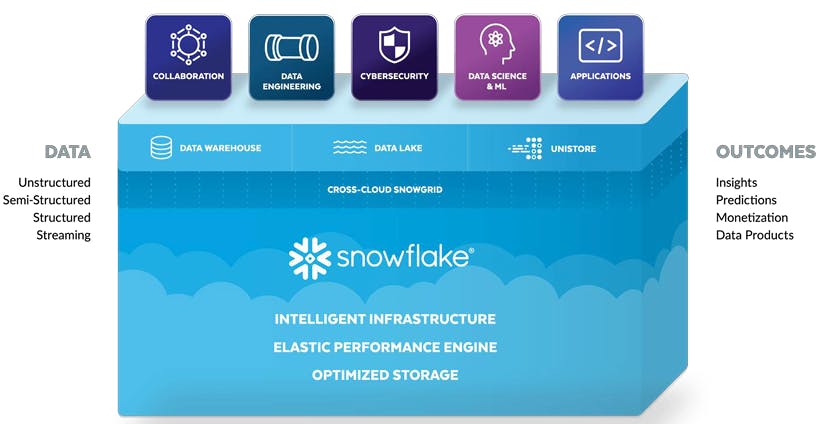
Building The Snowflake Platform
Snowflake’s vision? The Data Cloud. The underlying platform that provides everything needed to operate and run a data-driven company. Snowflake’s database combines the benefits of a data lake and a data warehouse into one platform that allows for running analytical tooling within the platform. Snowflake is able to provide as much compute and storage as the customer needs by scaling resources up or down. The distributed architecture and scalable compute engine creates a massive cost and performance advantage in compute-heavy tasks like querying and analytics.
How Snowflake Works
Customers can spin up new virtual warehouses (private virtual clusters) which are all powered by the number of nodes needed by a customer. Larger enterprise customers can set up multiple instances or multi-clusters. When customers spin up a new virtual warehouse they can specify the cloud provider and region they would like to utilize, and select a size (from XS to 4XL) of the computer cluster. This internally controls the number of distributed compute nodes within that cluster. Snowflake both manages and scales its own platform's infrastructure on cloud providers like AWS and Azure, but also helps to scale customer instances that run within Snowflake.
The Core Components of Snowflake’s Platform
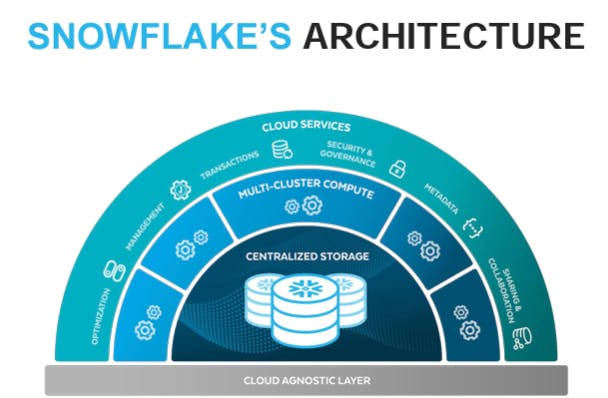
Snowflake’s architecture consists of three independently scalable components: storage, compute, and cloud services. Snowflake’s original moat was its ability to separate compute from storage, but that competitive advantage has been eroded as most modern data platforms provide similar capabilities in their infrastructure.
Storage
Snowflake’s storage layer ingests massive amounts and varieties of structured, semi-structured, and unstructured data to create a unified data record. Snowflake’s storage layer is built on AWS S3, Azure Blob, and Google Cloud Storage (GCS). The customer can choose the cloud provider it wants to utilize.
Compute
Snowflake customers can spin up a dedicated compute cluster called a virtual warehouse for analytics. The architecture behind it is called massively parallel processing (MPP), where the compute cluster is breaking up queries into separate sub-queries across the individual compute nodes, each handling a portion of the distributed data. Snowflake stores data in small blocks of data called micro-partitions. This allows it to be able to process huge amounts of data quickly, and can scale to work over incredibly large multi-petabyte datasets.
Cloud Services
Some of the services provided include an API for the management of the data, security roles, data sharing, data marketplace, data transactions, and metadata partitioning (e.g. how data fields are broken down).
Unistore
The newest addition to Snowflake’s platform was launched as recently as June 2022: Unitsore. Unistore application workload represents the fact that Snowflake is positioning itself as a suitable data store for high-traffic data applications to query. This will enable application developers to connect directly to Snowflake as the database-of-record for their applications. Querying data with Unistore can be done in as little as 10ms (response times), suitable for data-rich applications with a responsive UI. Unistore is also transactional, providing some support for data capture use cases. The Unistore storage engine is organized around data rows, which is foundational to a relational transactional data model. Hybrid tables operate like standard SQL tables. As of early September 2022, this product is still in private preview which means it is not publicly available for all Snowflake customers.
Competitive Advantages and Capabilities
ANSI SQL Platform
Snowflake’s platform is built around SQL. It allows for SQL querying capabilities over its Data Warehouse. Customers can throw in a variety of data into the warehouse and use SQL to query both structured and semi-structured data. SQL is an advantage because it is the de facto database querying language for technical and non-technical users.
Application Development
Snowflake has started to position their platform for building applications. The acquisition of Streamlit enables developers to build an application on Snowflake datasets. Streamlit + Unistore enable the connection between applications and a data warehouse. There are two keys pieces of this strategy:
Developer Tooling: Snowflake is rapidly becoming a platform for developers to build serverless platforms and connected applications. Snowflake has positioned itself as a development tool providing managed data storage. At their last conference, the company discussed “bringing data to applications” rather than “bringing applications to the data.” Developers are starting to build cloud-native in the serverless paradigm, and Snowflake fits right into that trend. Developers will always want flexibility to use both relational and NoSQL data to build data applications on Snowflake. Across the proverbial battle field Databricks’ platform doesn't cater to software developers who want to build applications directly on their platform. This will come up again as the plot thickens.
Native Application Framework: This new launch delivers the tools and environment for developers to build, deploy, and even monetize data-intensive applications in the cloud. Developers can build applications on top of their customer’s Snowflake environment without having to worry about distributing and monetizings applications on the platform. This eliminates any need for data to be copied out of the application developers hosting environment. This goes beyond the future of managing data and takes a crack at disrupting the traditional SaaS model itself.

Source: Snowflake Investor Presentation
Cybersecurity
Snowflake’s platform has always been inherently security conscious. From its early days, Snowflake provided data masking, recovery, data security certifications, and governance services. This is one aspect where Snowflake has had to be aware since day one, given its central position housing data.
At their recent Summit Snowflake officially announced a new Cybersecurity workload that provides a unified, and scalable data platform for helping security teams manage and capture security log data. Snowflake has also built partnerships with many of its ecosystem partners to further build up its security offering. One example is Snowflake’s partnership with Panther Labs where customers can perform security analytics right in their Snowflake instance versus shipping logs off to another security vendor’s data platform for analysis.
Databricks has shown security performant use-cases in partnership with Crowdstrike. But its early focus on analytics over storage means its security efforts aren’t as mature as Snowflake’s.
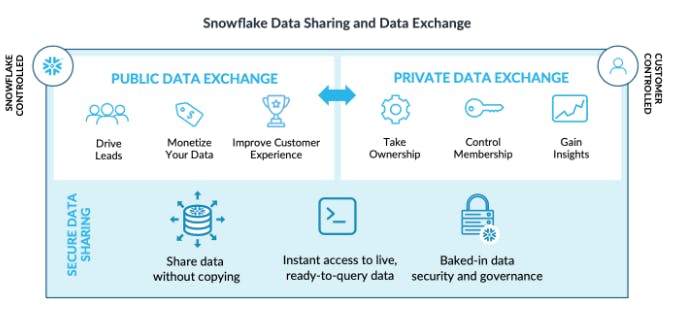
Data Sharing Ecosystem
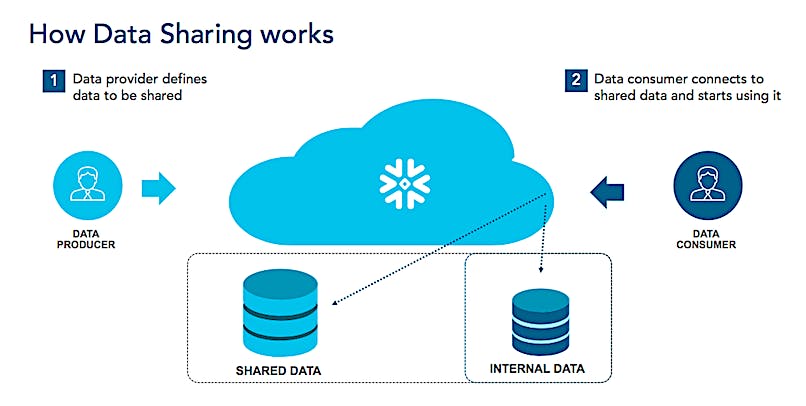
Source: Snowflake Data Sharing
Snowflake’s platform enables data sharing internally and externally within the enterprise. While groundbreaking at the time of launch this feature has since been replicated by platforms like Google BigQuery. Snowflake’s data sharing enables governed data access so users can securely share data with external users. All the computation from querying done on the shared data is covered by the owner of the data.
An active data share is defined as a stable edge, in which two parties consume actual Snowflake credits to maintain a data sharing relationship for a period of time. Snowflake calls the networks created by these shared data graphs the Data Cloud.
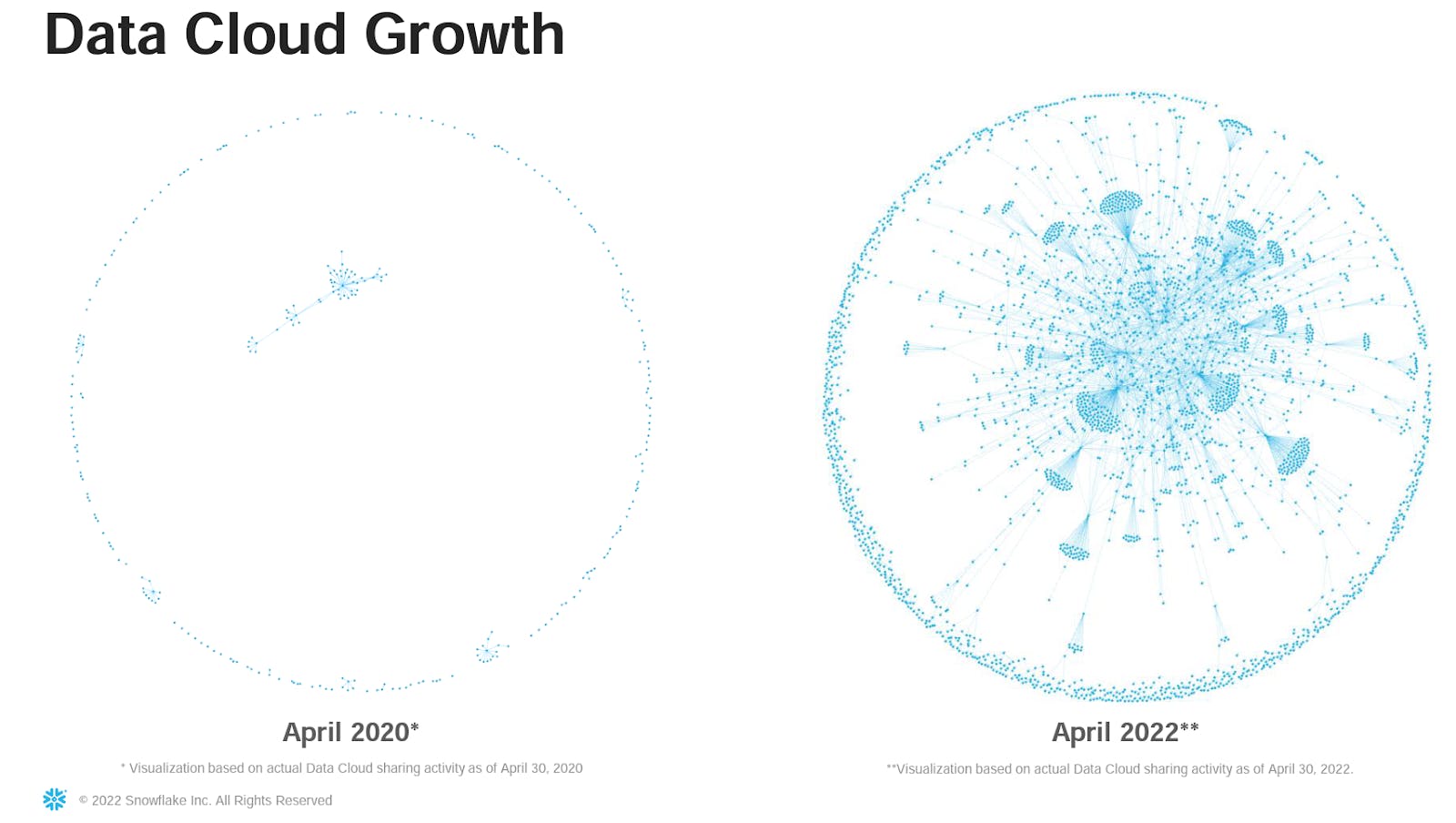
The number of stable edges grew by 122% from Q1 2021 to Q1 2022. Over the course of the last few quarters Snowflake has seen the percentage of customers with at least one stable edge grow from 15% in Q3 2021 to 20% in Q1 2022.
At the financial presentation during Snowflake’s 2022 summit their CFO revealed that 63% of $1M+ customers have a data sharing relationship in place. This is over 3x the 20% of total customers with at least one stable edge across customers of all sizes. They also saw an 86% increase in customers using stable edges. Over 1,264 Snowflake customers have started using the platform after they fully began tracking it during 2020. Data sharing gets even easier when two clients are already Snowflake customers.
Source: Snowflake / Hypergrowth
Data Exchange is a process that allows companies to create collaborative shared databases between partners using Snowflake’s own virtual warehouses. Joint ventures can be built around shared pools of data. If all parties are separate Snowflake customers, they can each share the storage and compute costs.
Data Marketplace
Snowflake’s Data Marketplace allows companies to share and monetize their data more publicly with external partners. All forms of data can be exposed for public consumption. For example, hospitals or governments can share COVID-19 data or research facilities can open survey results. Companies can choose whether they want to monetize these exposed datasets. The network effects created by the Data Marketplace represent a significant opportunity for Snowflake.
Powered By Program
Snowflake’s Powered By program allows other companies to build their own data-driven product or service on top of Snowflake’s platform. Those customers can then sell that product to their own customers. This approach allows these providers to skip the development and maintenance of their own data processing engine and “rent” it from Snowflake. In Snowflake's fiscal Q2 2023, Snowflake had 590 of these Powered By program participants (up 35% q/q) and revealed that as at Q1 FY 2023 9% of their $1M+ customers came from this program.
Snowflake: In Summary
Snowflake has built an extensive Data Cloud that has demonstrated success at scale with its core functions around storage and compute. Their extensions have driven new use cases around application development and more robust analytics. Snowflake’s cybersecurity and data sharing ecosystem present significant network effects.
The obvious next question? How is Databricks positioning themselves against the Snowflake war machine?
Building The Databricks Platform
A lot of airtime is dedicated to Snowflake with its $100B IPO but make no mistake; Databricks is a formidable monster of a business not content to ignore Snowflake’s market position. Databricks provides a data science and analytics platform; a data lake that was built on top of open-source Apache Spark. The core product is a compute engine used for running advanced queries on data. They provide notebooks for data exploration and the ability to manage data pipeline jobs. Databricks has evolved over the past 9 years from a simple data lake to their much more wide-reaching vision today.
The Data Lakehouse
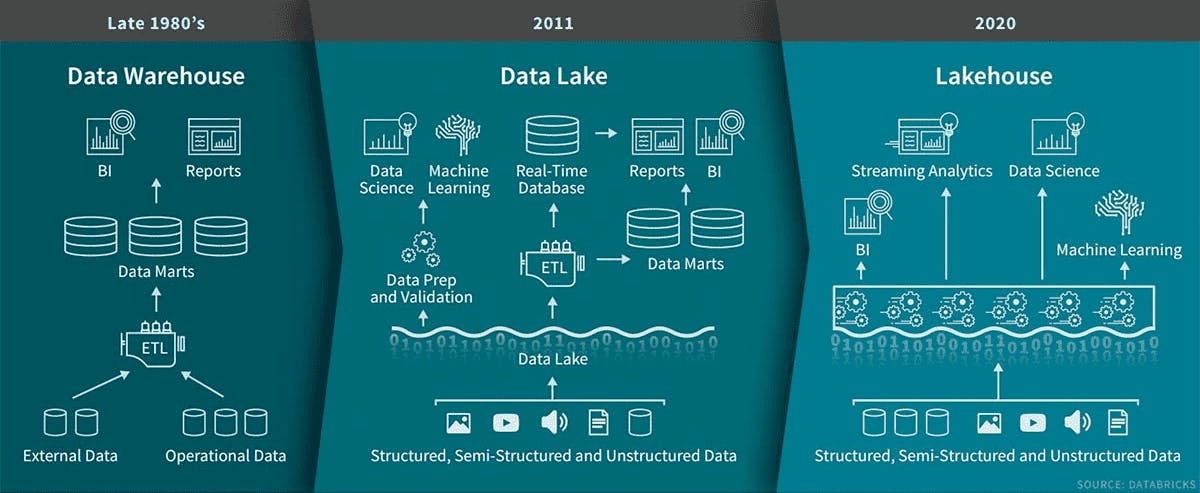
Databricks' vision is The Data Lakehouse. At their recent Data + AI Summit, the company emphasized the importance of the Data Lakehouse as being a superior infrastructure for the next-generation of companies. The Data Lakehouse combines elements of a data warehouse with a data lake in one centralized platform. It is able to provide the benefits of streaming analytics, BI, and machine learning all within one platform.
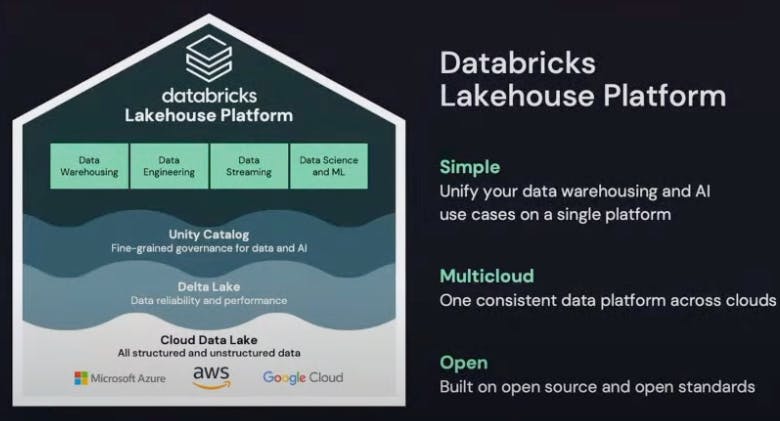
Source: Databricks Product Website
Databricks' Lakehouse is based on the open source Apache Spark framework that allows analytical queries against semi-structured data without a traditional database schema. Databricks believes the processing speed of the Lakehouse is a key differentiator for them against Snowflake.
The benefits of having a data lake and warehouse in one platform means that data teams can move faster as they are able to use data without needing to access multiple systems. Teams no longer have to worry about stitching together data lakes and data warehouses. This helps teams avoid issues around data duplication, extra operational costs, and multiple ETL processes.
There are certain key features of a data lakehouse. Storage is decoupled from compute. Lakehouses also support transactional data use cases and support diverse data types from unstructured to structured data. Additionally, the Data Lakehouse supports SQL programming language for querying the data.
You can start to see how clearly Databricks is positioning their Data Lakehouse against Snowflake’s Data Cloud. But before we explore the evolution of Databricks’ platform we have to start from its beginnings.
What is Apache Spark?
Apache Spark is a cloud based, open-source compute engine for running advanced analytics, querying, and processing large volumes of data. Apache Spark started in 2009 as a research project at the UC Berkeley AMP Lab based on a research paper called Spark: Cluster Computing with Working Sets.
Spark is not a storage engine but rather a system for querying and analyzing data already stored in a place like Amazon’s AWS S3 or in a data warehouse. The distributed nature of the platform makes Spark difficult to implement on your own which led to the creation of Databricks as a company in order to offer Spark as an enterprise managed service.
The main components of the Databricks platform are the Data Lake (storage engine), Delta Lake (processing engine) and Unity Catalog (governance and security engine over the data). Everything is built on the foundation of cloud platforms like AWS or Azure.
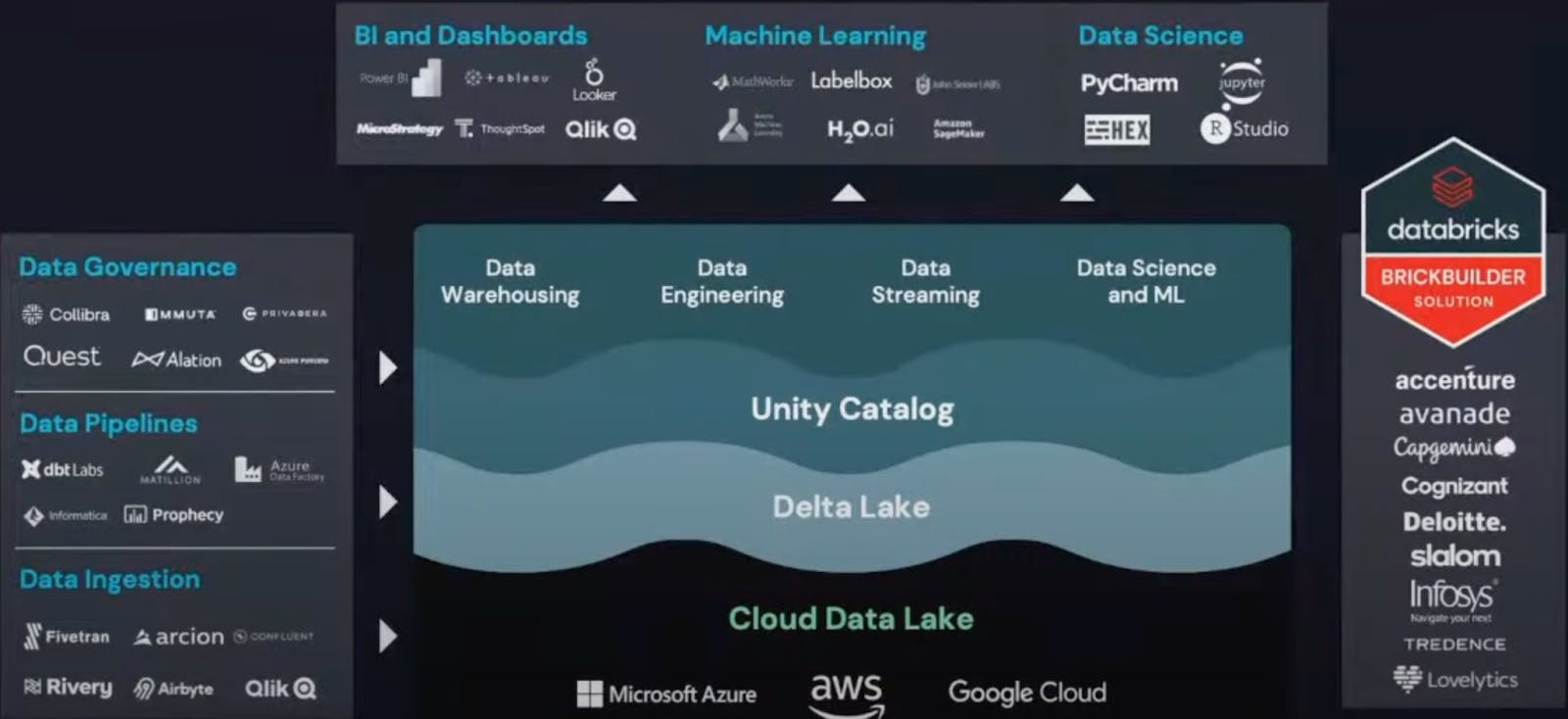
Source: Databricks AI Summit
The Core Components of Databricks’ Platform
Before we dive into the fundamentals of Databricks, there’s one important thing to unpack. You’ll notice that a simple data lake is not a core component of Databricks’ offering. A data lake is a storage engine for all kinds of structured and unstructured data. But many leaders in the data world, like Fivetran’s CEO George Fraser, will say “data lakes are not part of the modern data stack.” Because of the separation of storage and compute the justification for a simple data lake being cheaper has become a weaker argument. Modern enterprises want more from their core infrastructure.
Databricks has positioned themselves at the cutting edge of how data can be organized. The evolution of the Delta Lake, and subsequently the Data Lakehouse, create the best of both worlds offering the “query performance usually associated with data warehouses, but with the cost and scalability associated with data lakes.” Many companies still leverage a data lake. But the evolution of the data stack is pushing towards the vision that Databricks’ Data Lakehouse lays out.

Apache Spark
The foundation of Databricks is Apache Spark and the foundation of Apache Spark is analytics. A company can store their data in a data lake like AWS S3 or Azure’s Data Lake Storage that are then pulled into analytics jobs. The core layer of Apache Spark is called the Spark Cluster. This cluster is a group of servers for setting up data pipeline jobs. Databricks’ platform provides users the ability to access data and use Spark’s distributed file-system (DBFS) without needing to spin up several internal instances. Databricks has become a Spark-as-a-Service provider and simplified the process of allowing users to develop ML via a no-code UI, instead of scripting.
Delta Lake
Delta Lake is a major iteration from a standard data lake. This solution lets a customer query their data lake like a data warehouse. Combining the scalability of a data lake and the accessibility of a data warehouse is one of the biggest shots Databricks is taking at Snowflake’s position. Delta Lake helps to organize and structure data by creating a database layer over existing data lakes. Delta Lake is also the core foundation of the Data Lakehouse along with other catalog, ETL, and data scheme features.
MLflow
Databricks built and maintains an open source package called MLflow. It was released in 2018 and offers a full platform for the machine learning lifecycle. While the package is open source, Databricks offers a paid service called MLflow that manages the infrastructure for customers. MLflow helps in model registry, deployment, and operationalizing machine learning jobs. Databricks recently launched the latest MLflow 2.0. Getting a machine learning pipeline into production requires setting up infrastructure that can be tedious for data teams to scale. MLflow Pipelines, included in MLflow 2.0, will handle the operational details for users. Instead of having to orchestrate notebooks users can simply define the elements of their pipeline in a configuration file. MLflow Pipelines manages the execution automatically and offers data scientists pre-defined, production-ready templates based on the model type they’re building to allow them to bootstrap model development without requiring intervention from production engineers.
Delta Engine
In June 2020 Databricks launched its new Delta Engine as a new query engine that layers on top of Delta Lake to boost query performance using SQL queries. This feature optimizes the underlying file structure within the data lake and improves performance of querying over files. Adjacent features like Databricks Photon enable fast query performance at low cost. It can be applied to multiple functions from data ingestion and ETL to streaming and data science or queries. Databricks claims that Photon can achieve cost savings up to 80% over comparable systems and accelerate data analytics workloads by up to 12x
Unity Catalog
Data governance and security has been a challenge in the past for data lakes, as there is no common control layer across the different data types. Additionally, users of data lakes often struggle to catalog and locate data, wasting time combing through different data stores for the appropriate data to feed their models. Unity Catalog provides a central governance solution for all data and AI assets. Unity Catalog also includes built-in search and discovery of data assets so that users can quickly find, understand, and reference relevant data across data sources.
Competitive Advantages and Capabilities
Open Source Platform
Databricks is often touted by developers as a much more open system than Snowflake because of its open-source origins. Databricks is built on three core open-source systems (Apache Spark, Delta Lake, and MLflow). They also support many different programming languages beyond just SQL. As an OS technology, it means the product is available for any company to implement the platform. Each piece of technology has a strong and loyal community of engineers supporting it. Companies can adopt Databricks and pay for a managed service without feeling locked in to the platform.
Snowflake is much more of a closed ecosystem and has clearly recognized the advantage Databricks have within its OS roots. Snowflake has made several attempts to engage with the open source community like offering support for Apache Iceberg, a popular open table format for analytics. For use cases requiring open standards, Apache Iceberg Tables give customers more options of storage patterns with Snowflake’s performance, security and governance. But in general developers see Snowflake as mostly a closed ecosystem and Databricks as mostly an open ecosystem.
Having an open system isn’t automatically “better” than a closed system. Like with any technology choice, it brings trade-offs that may cater to certain user audiences. An open system offers transparency and configurability, as the source code is available and can be manipulated. A closed system, on the other hand, obfuscates the inner workings of the system. While lacking transparency, the product is usually thoughtfully pre-configured for operators to be immediately usable without the overhead of infrastructure management or configuration choices. Additionally, the developers of a closed system often have more flexibility to make changes to the internal system workings, as they don’t need to contend with compatibility to open interfaces or community management.
Advanced Data Science Capabilities
Databricks has an edge when it comes to implementing advanced machine learning and artificial intelligence algorithms at scale. From their data science playbooks, to the complexity of the Data Lakehouse, they have specialized and strengthened their capabilities within the data science market.
Databricks provides a notebook workspace for exploration and visualization of data. They also offer a production pipeline scheduler for running large data pipelines on a regular schedule. All the tools a data scientist or ML engineer need to successfully run and operate models at scale. Databricks also supports a variety of open-source collaboration tools and ML Libraries such as Koalas, TensorFlow, dmlc XG Boost, PyTorch, Jupyter, and RStudio.
Real-Time Data Streaming
Databricks has an edge when it comes to data streaming given the inherent architecture of the data lake. For every data pipeline exercise (i.e. transforming raw data into insights), a customer needs to store their data in a database and then send it into a data warehouse or data lake. To make this possible the data has to go through an ETL process or real-time streaming.
A data lake can take data in without enforcing a schema (i.e. schema on read). Databricks Spark Streaming is designed to absorb structured and unstructured data easily. A data lake is able to absorb real-time data more quickly and efficiently than a data warehouse which would require additional ETL around it. Databricks streaming makes it much easier to aggregate data, manage issues when data flows are delayed, and manage ACID compliance. Databricks launched this product in 2017 and further doubled down on it at their Data + AI Summit with a newer version called Project Lightspeed.
Delta Sharing
Databricks launched their data sharing product in 2021 as an open protocol for real-time collaboration. The product is based on an open-source project by Databricks. Organizations can easily collaborate with customers and partners on any cloud and provide them the flexibility to run complex computations and workloads using both SQL and data science-based tools like Python, R, and Scala with consistent data privacy controls. Databricks provides the core infrastructure on top of a cloud provider. In the upcoming months, they will be launching Data Cleanrooms as a way to share and join data across organizations. A key observation is that Databricks doesn't require a delta sharing user to be a customer of its platform, whereas Snowflake requires you to be a customer to use their data sharing and marketplace features.
Databricks Marketplace
The Databricks marketplace launched in June 2022. This came after Snowflake launched their data marketplace in June 2021. The Databricks Marketplace enables data providers to securely package and monetize digital assets like data tables, files, machine learning models, notebooks, and analytics dashboards. Data consumers can discover new data and AI assets, potentially accelerating their own discovery and analysis.
Databricks SQL
In November 2020, Databricks introduced Databricks SQL (previously known as SQL Analytics) for running business intelligence and analytics reporting on top of data lakes. Customers are able to run SQL queries against their Data Lakehouse, just as they would any data warehouse by adding SQL on the storage layer. They can also use product connectors to integrate directly with business intelligence tools like Tableau, Qlik, Looker, and ThoughtSpot. This is a focus for appealing to a broader user base outside of data science, many of whom are heavy SQL users.
At the Databricks summit they announced the availability of serverless compute; a platform on Databricks SQL that helps customers avoid having to provision servers themselves. Databricks manages all the necessary servers and customers benefit from having a lower cost overhead. They launched a number of open-source connectors to make it easier for developers to access Databricks SQL from any application.
Databricks: In Summary
Databricks has progressed beyond simple data analytics and positioned itself as a formidable challenger to Snowflake, and they continue to be the de facto option for advanced AI and ML workloads. Today, Spark is used for data ingestion and analysis. Delta Lake is a high-performance database query engine focused on the refinement, security, and governance of data. Finally, the launch of Delta Sharing and their data marketplace will act as a catalyst for the company in building their own data network. The combination of open source (Delta Lake, Spark) and proprietary enhancements (Delta Engine, Enterprise Spark, SQL Analytics) have all culminated in the Data Lakehouse. The Titans taking on the data stack now come down to the Snowflake Data Cloud and the Databricks Data Lakehouse.
The Present: Building The Engine
The $200 billion+ data market has enabled both Snowflake and Databricks to build massive businesses with exceptional SaaS metrics.
Snowflake’s Traction
Snowflake has grown its revenue from $96 million in 2018 to over $1 billion in 2021, expecting to cross the $2 billion mark this year (growing 60%+ year-over-year). That growth has been incredibly consistent, having previously grown 100%+ for the 11 quarters after they reached $100 million in revenue.
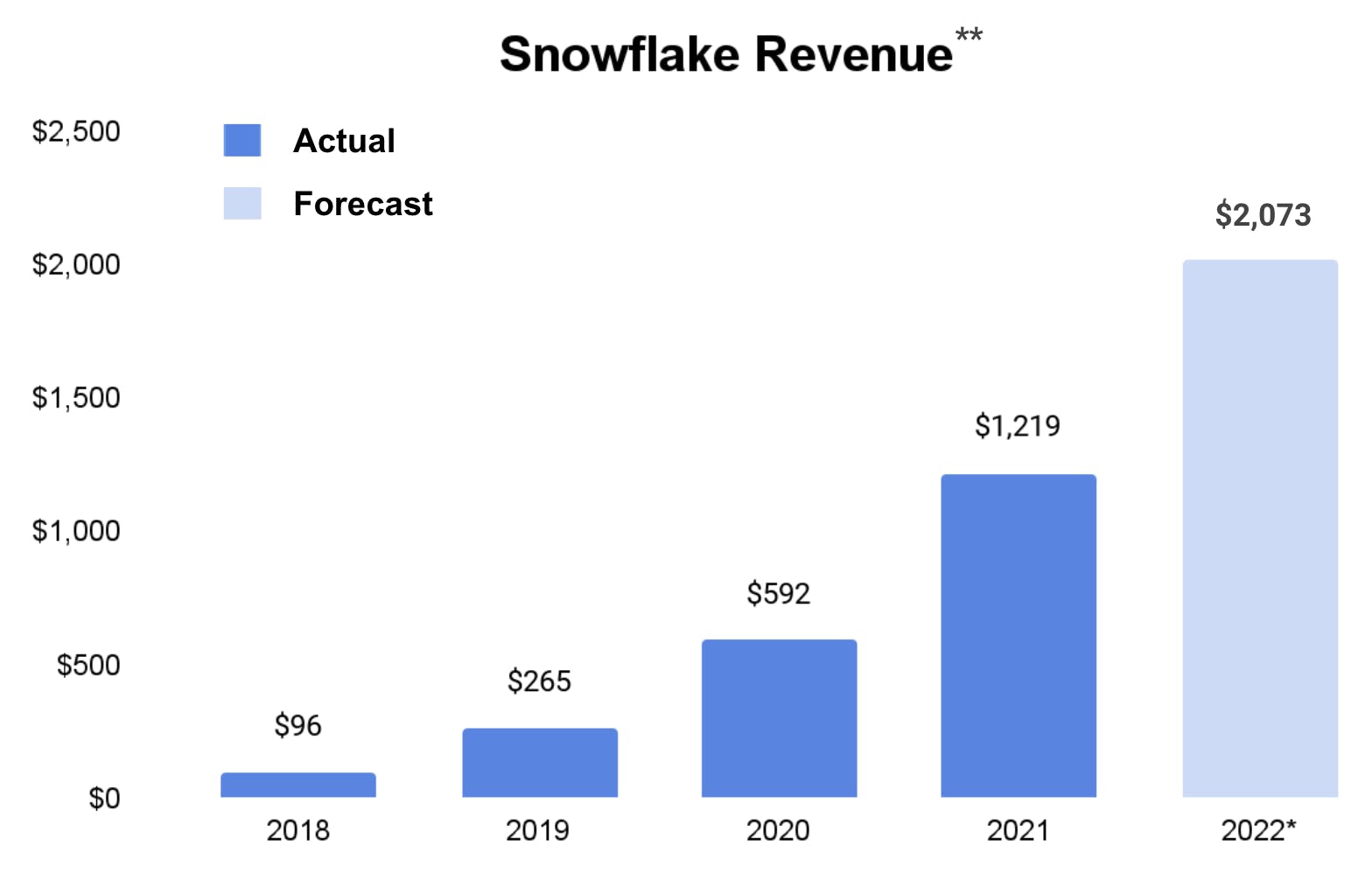
Source: Koyfin (**Differences between calendar year and $SNOW fiscal year; *2022 based on company guidance as of September 2022)
Among public software companies Snowflake has consistently been one of the fastest growing companies even while being at a larger revenue scale than most of them.
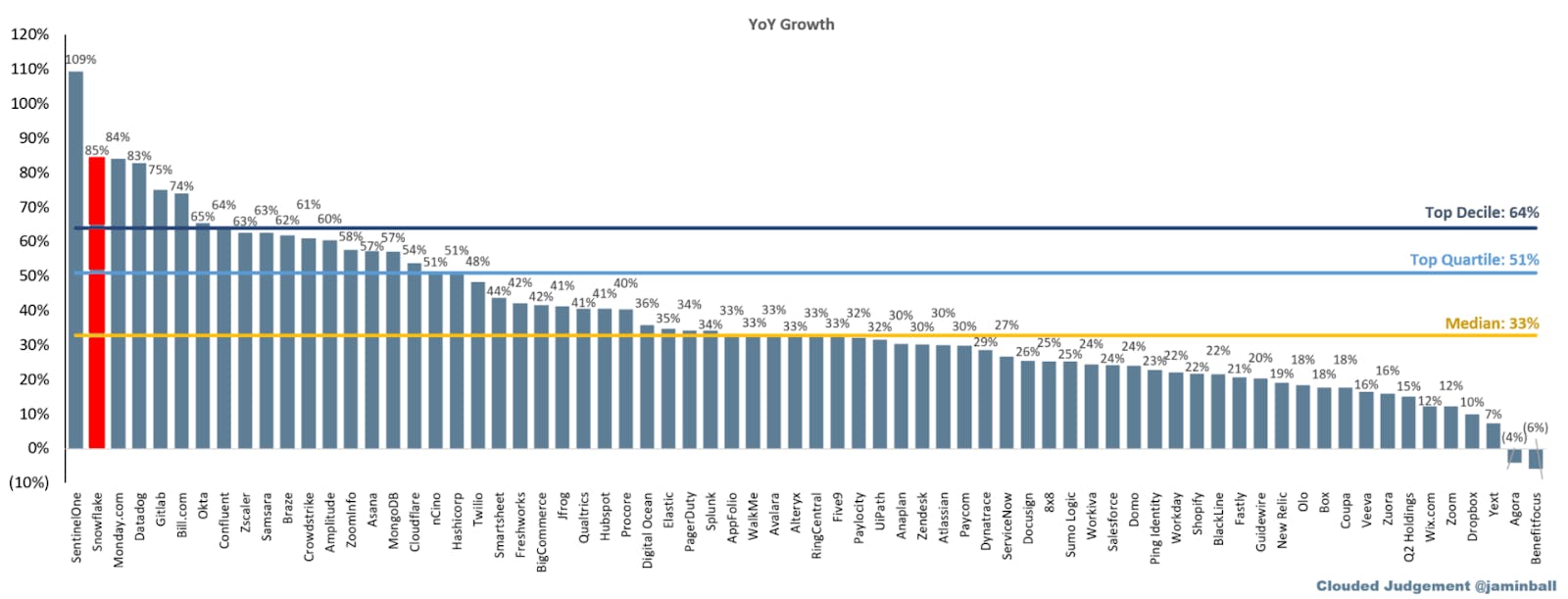
Source: Clouded Judgment
Databricks Traction
Based on the numbers that Databricks has shared across its various funding rounds we know they’ve recently crossed $1 billion in ARR. As a private company we only have sporadic data updates from Databricks, but they grew revenue by ~80% last year and if they maintain that growth rate they’ll end this year at nearly $1.5 billion of ARR.
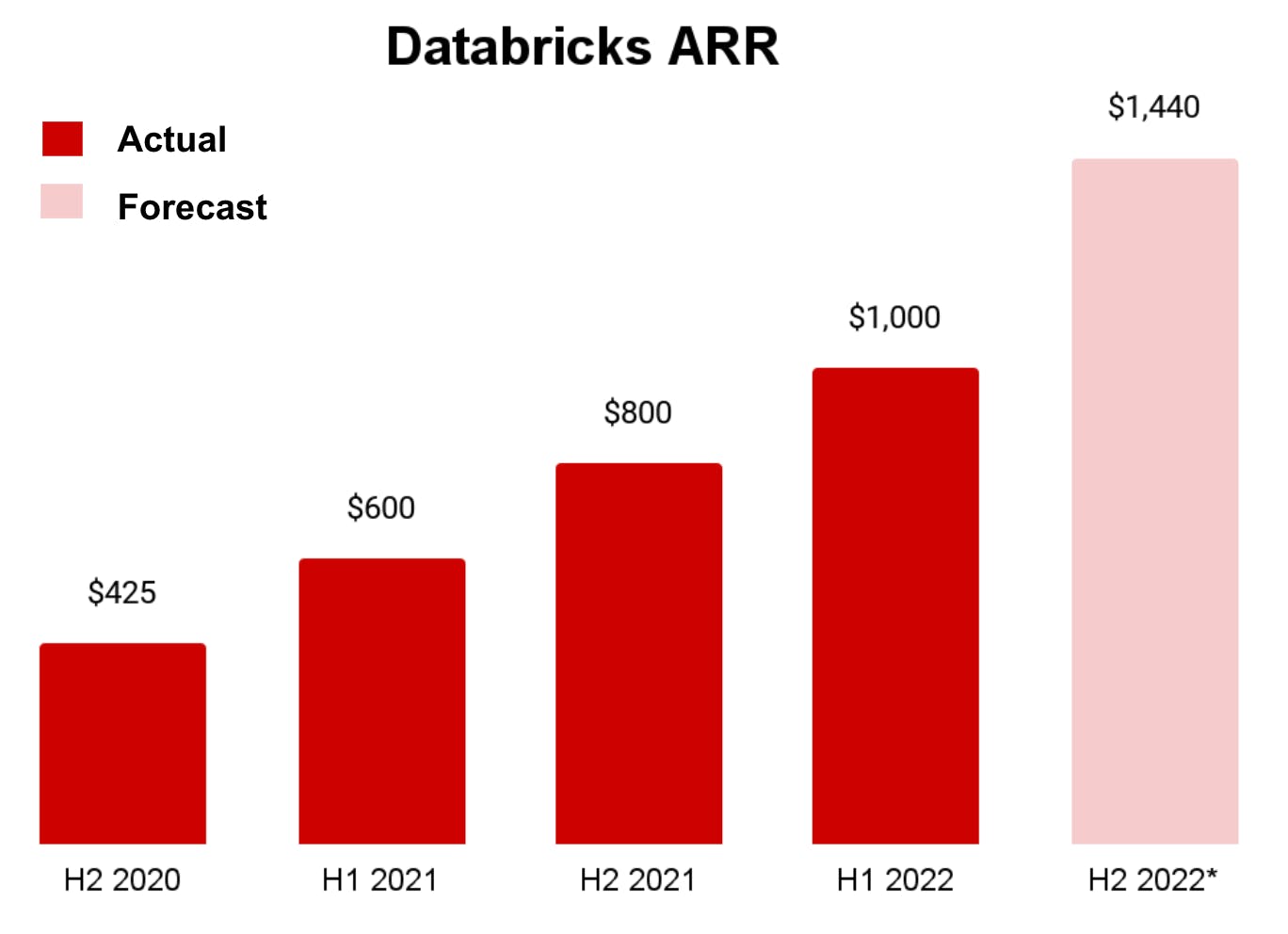
Source: Databricks Press Release (Feb 2022, Aug 2022) (Forecast is based on consistent growth rate; not a Databricks forecast)
One critical difference in the ARR for both companies is that Snowflake collects services revenue (compute and storage) and passes it on to cloud providers like AWS or Azure. Databricks customers pay for data storage directly to the cloud providers so Databricks doesn’t collect services revenue. As a result, Snowflake has a higher total revenue mix coming from services but lower gross margins (75%) than Databricks (80%). Because of this dynamic, Databricks has a more balanced relationship with all the major cloud providers because the hyperscalers benefit when one of their customers uses databricks. Snowflake also revealed on their recent earnings call that 80% of their customers use Amazon AWS Cloud workloads with about 18% on Azure and 2% on GCP.
Driving Tailwinds
Just to appreciate that scale, only a few hundred companies have ever achieved more than $1 billion of revenue out of the hundreds of thousands of tech companies in the world. For both of these companies to be at $1 billion+ of revenue growing >50% in less than 8 years is exceptional.
Looking at the path of these two titans converging, we see they’re simultaneously riding two massive tailwinds that are starting to converge – as we’ve seen from the data suites from both companies.
Tailwind #1: The Prevalence of the Cloud
Over the last few years, we’ve seen the cloud move from the cutting edge to the mainstream. While only 30% of new workloads are deployed on cloud-native platforms, we’ve seen the overall share of corporate data stored in the cloud increase to ~60%, especially with a pull-forward during Covid.
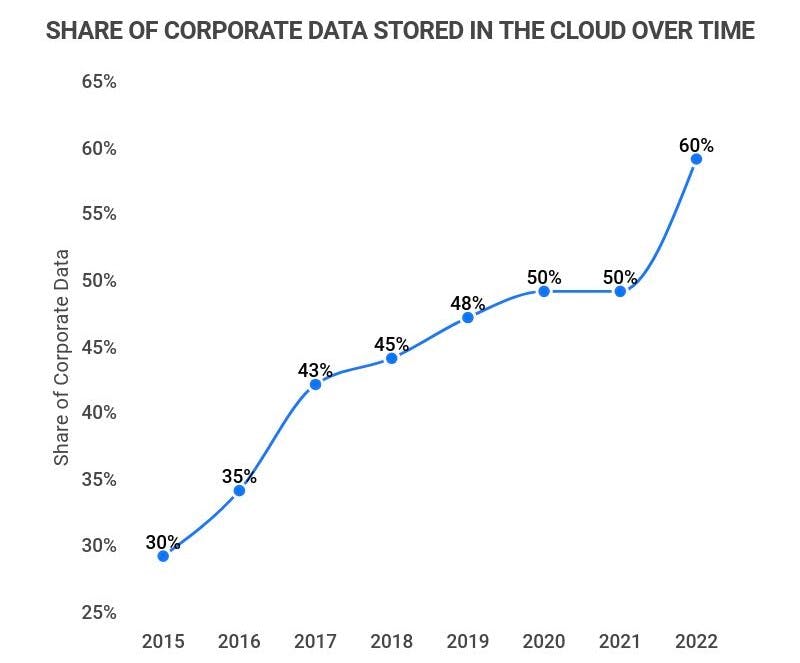
Source: Zippia
Tailwind #2: The Rise of Data Science & Machine Learning
As every company starts to embrace their role as a data company they find themselves in need of a particular set of skills. Machine learning engineer is the 4th fastest growing role in the US as part of a market that is growing 40%+ and represents over $40B spent on machine learning applications and platforms. Machine learning budgets are increasing each year by almost 25% driven by the many use-cases within organizations.
Secret Sauce: Driving Net Retention
These companies are riding the data revolution and have been able to execute on product velocity in order to expand their platforms. One of the clearest indicators of that execution is in net retention. When a customer starts out as a $100K contract and over the course of 12-months expands to a $150K contract they have 150% net retention.
Snowflake has ~170% net retention while Databricks has ~150%+. While the concept of net retention can seem simple (i.e. help customers spend more) it’s incredibly difficult to have high net retention. When you look across the majority of SaaS companies you see that Snowflake and Databricks are best in class.
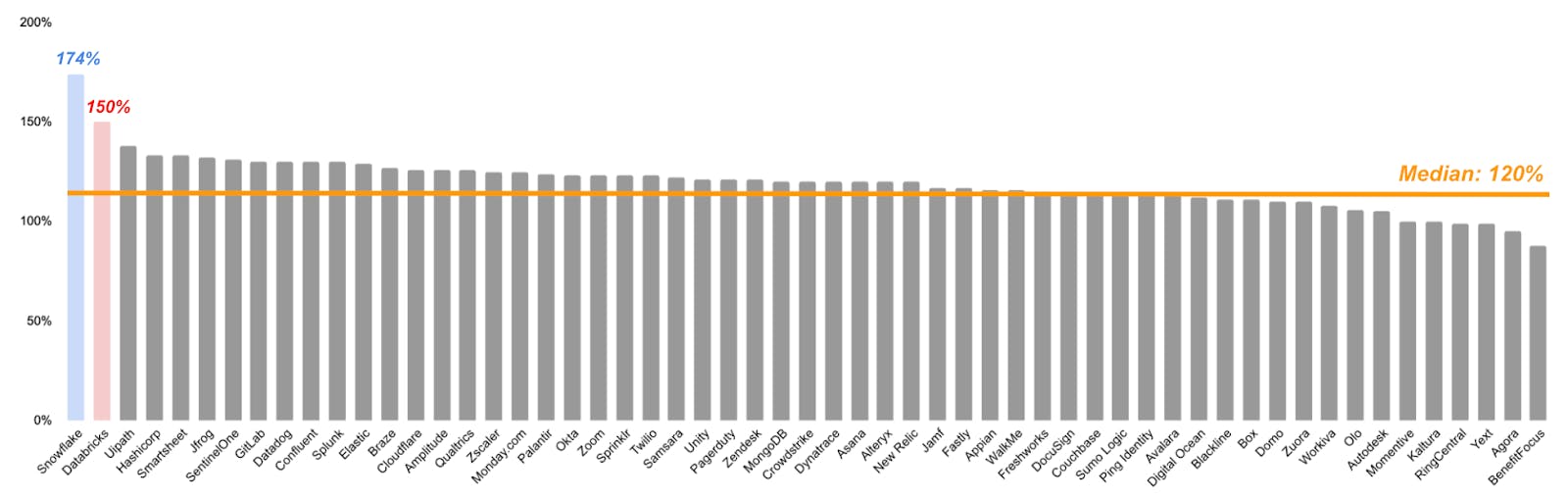
Source: Clouded Judgment (Aug 2022) and TechCrunch
Net retention is a function of a few fundamental pieces: (1) initial size of the land, (2) subsequent size of the expansion, and (3) keeping churn low. As key data infrastructure churn isn’t an existential risk to Snowflake or Databricks. The bigger risk comes from downsell driven by fluctuations in customer usage. So we’ll focus on the land and expand.
The Land
Unfortunately, most companies don’t disclose very much information about the size of their initial contracts. But we have a few data points. One clear example is Snowflake’s initial contract size with customers that eventually become $1 million customers.
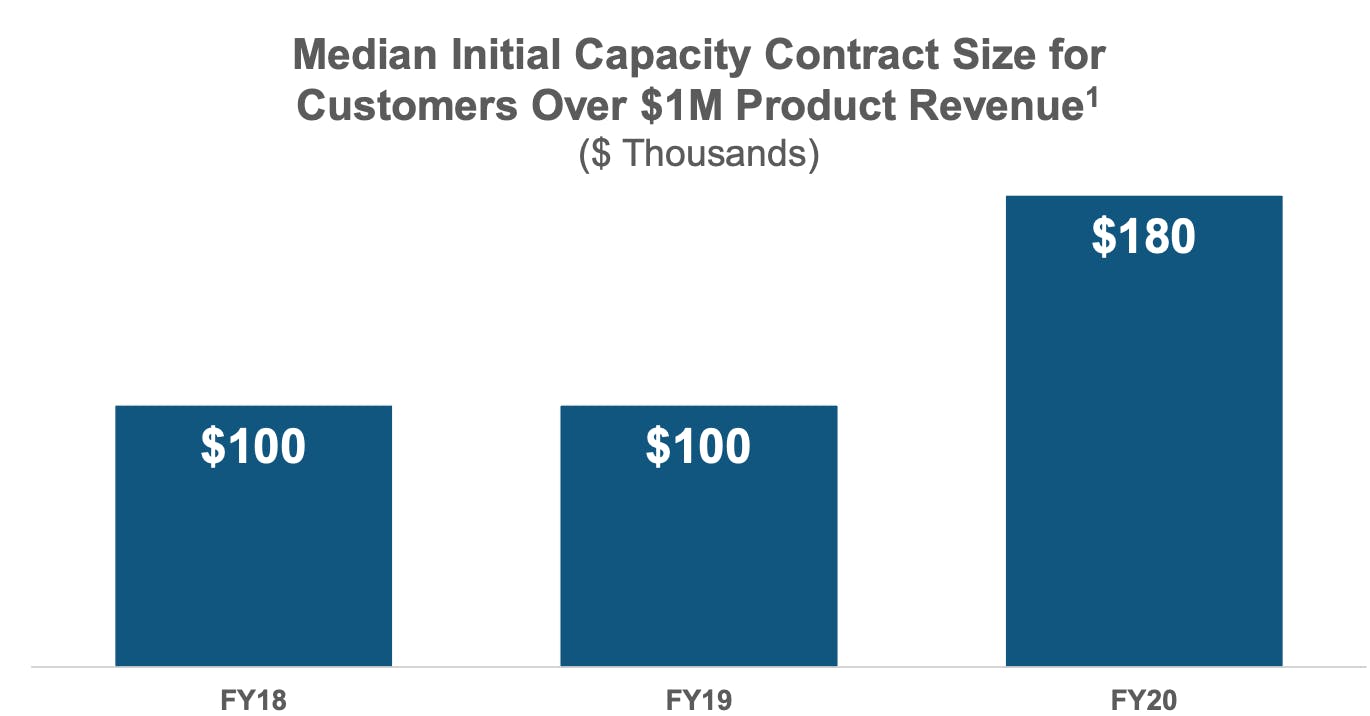
Source: Snowflake Investor Presentation
Those customers start as ~$100K customers and that initial land has continued to increase in size. As companies embrace more use cases around data management and bring more of their data into the cloud they start to spend more with Snowflake right off the bat. Snowflake recently announced in their recent conference that they’ll start to focus on working with the Global 2000 which will lead to even larger initial contract sizes.
Another data point we have is a company’s average contract value (ACV). The larger those ACVs, the larger their initial land likely is – though not always.) Take Databricks as an example. We can cobble together a few data points to get a directional perspective on their ACVs. We know that around February 2021 it had ~5,000 customers and ended 2020 at $425 million of ARR. By the end of Q2 2022 it had $1 billion in ARR and over 7,000 customers. Based on those rough numbers we get the sense that their ACV has increased from ~$85K to ~$143K over the course of two years or so.
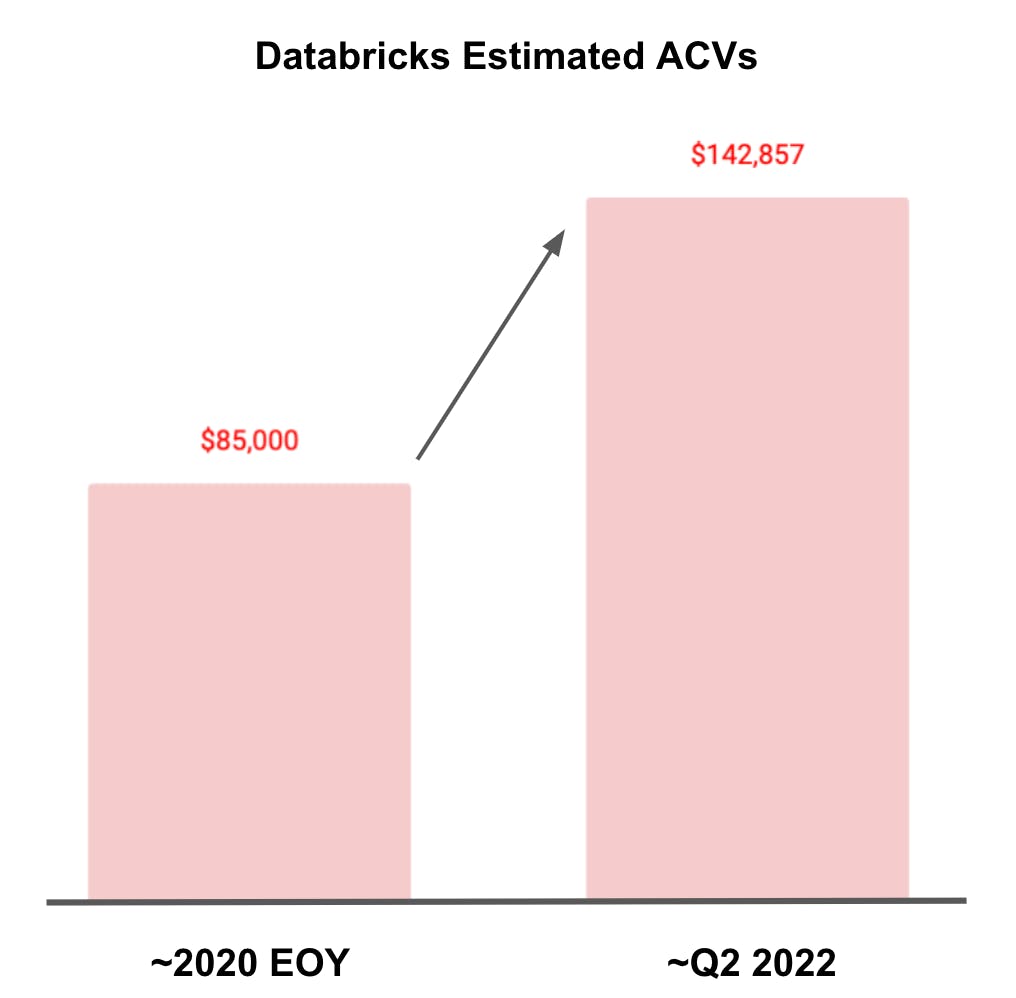
Source: Databricks, Techcrunch, WSJ
Those smaller lands allow for lower customer friction. Customers can spend whatever is right for them, allowing Snowflake and Databricks to get involved with the customer and then create even more value over time from new use cases and additional products.
The Expand
For both Snowflake and Databricks there is significant opportunity in driving meaningful expansion from existing customers. A key piece of that expansion to date has come from one of the most discussed aspects of Snowflake and Databricks’ business models: usage-based pricing.
Usage-Based Pricing
Companies like Datadog, MongoDB, and Confluent have become some of the most successful companies in part by leveraging usage-based pricing to tap into the value they’re creating for their customers. Based on a survey of 350+ tech executives ~25% preferred usage-based pricing up from 20% just 2 years before. As of May 2022 the median revenue growth rate for public SaaS companies was 27% compared to the median growth rate for usage-based companies at 56%+. That growth potential sets the stage for why usage-based pricing can be a secret sauce.
Usage-based pricing is where a customer makes an upfront commitment for a minimum amount of product usage (typically 1-2 years). The vendor generally then recognises revenue based on the amount of usage in a given quarter, or year. The more standard approach is a subscription SaaS model. Customers pay for access to the product and the vendor recognizes revenue each month of the contract, whether the customer uses the product a lot or not at all.
Snowflake and Databricks’ business models are built on usage-based pricing. Both companies enable customer consumption based on the amount of compute capacity needed to process data or by the volume of data ingested, analyzed, or stored. The long-term implications for usage-based business models is the impact on a company’s ability to penetrate their TAM. A company can further penetrate their TAM as they are not limited by finite metrics like the number of users or seats, but by the growth of the inherent data and addressable use cases.
Frequency of usage can be broken down into two categories: “always on” vs. “episodic.” Episodic means a company utilizes software for specific occasions. “Always on” means the platform is important for day-to-day operations.

Source: Morgan Stanley/The Rise of the Consumption Model
The core use cases for Snowflake and Databricks revolve around business intelligence and machine learning which makes them more susceptible to customer slowdowns in usage. By executing on visions like Snowflake’s application development use case or Databricks’ Data Lakehouse they’re able to better position themselves to continue expanding with their existing customers. Over the long-term, usage-based pricing offers customers flexibility, predictability, and control over cost thereby making it inherently preferable for customers.
The caveat is that pricing power per unit of data falls over time with a usage-based pricing approach. Both Databricks and Snowflake have worked to make their platforms even faster and more efficient. As their technology improves the relative cost goes down meaning Databricks and Snowflake generate more value for customers at a lower overall price point. However, over time we believe that usage-based pricing aligns product performance with customer value. This creates an opportunity for these platforms to monetize on other aspects of value creation.
Verticalized Use Cases
Snowflake and Databricks are also continuing to lean into expansion by increasing the number of use cases a customer might leverage. One example of that is how Snowflake is doubling-down on verticalized GTM efforts. Snowflake segments their efforts into (1) large vertical-specific customers, (2) large enterprises regardless of vertical, and (3) mid-sized corporations with <500 employees.
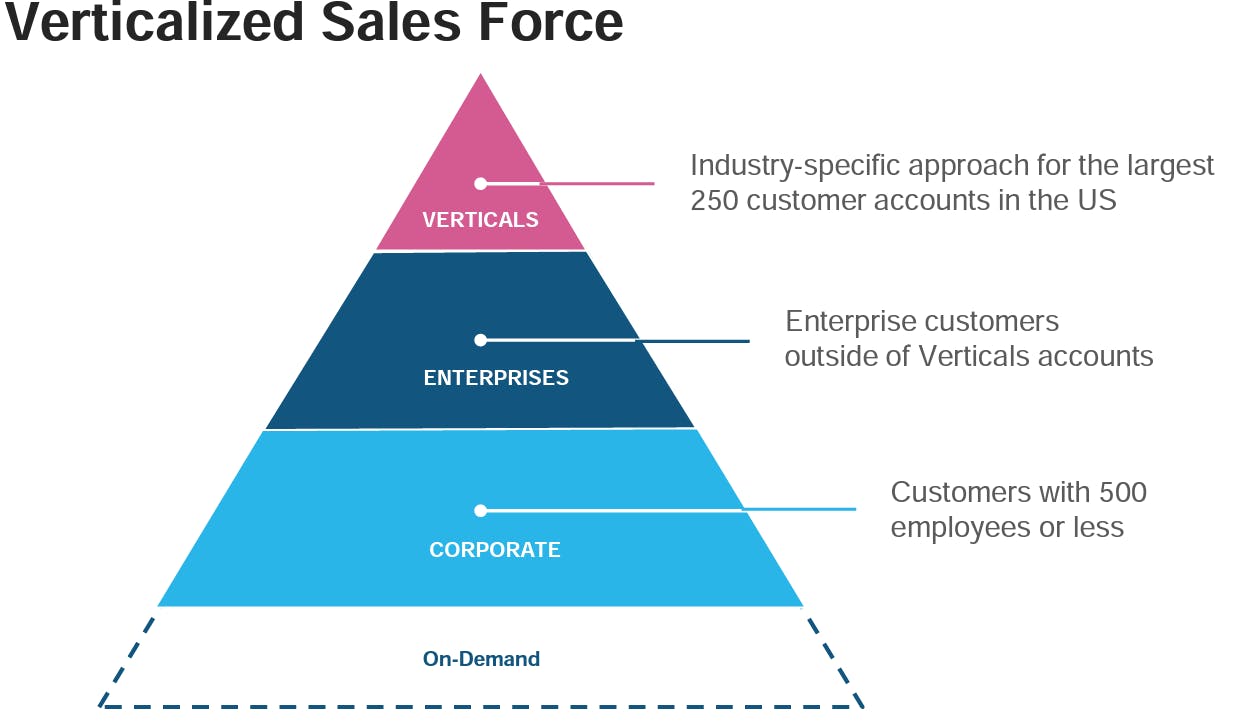
Source: Snowflake Investor Presentation
Their revenue mix exposes where their focus has been historically. 57% of their $1 million+ customers are within their enterprise segment.
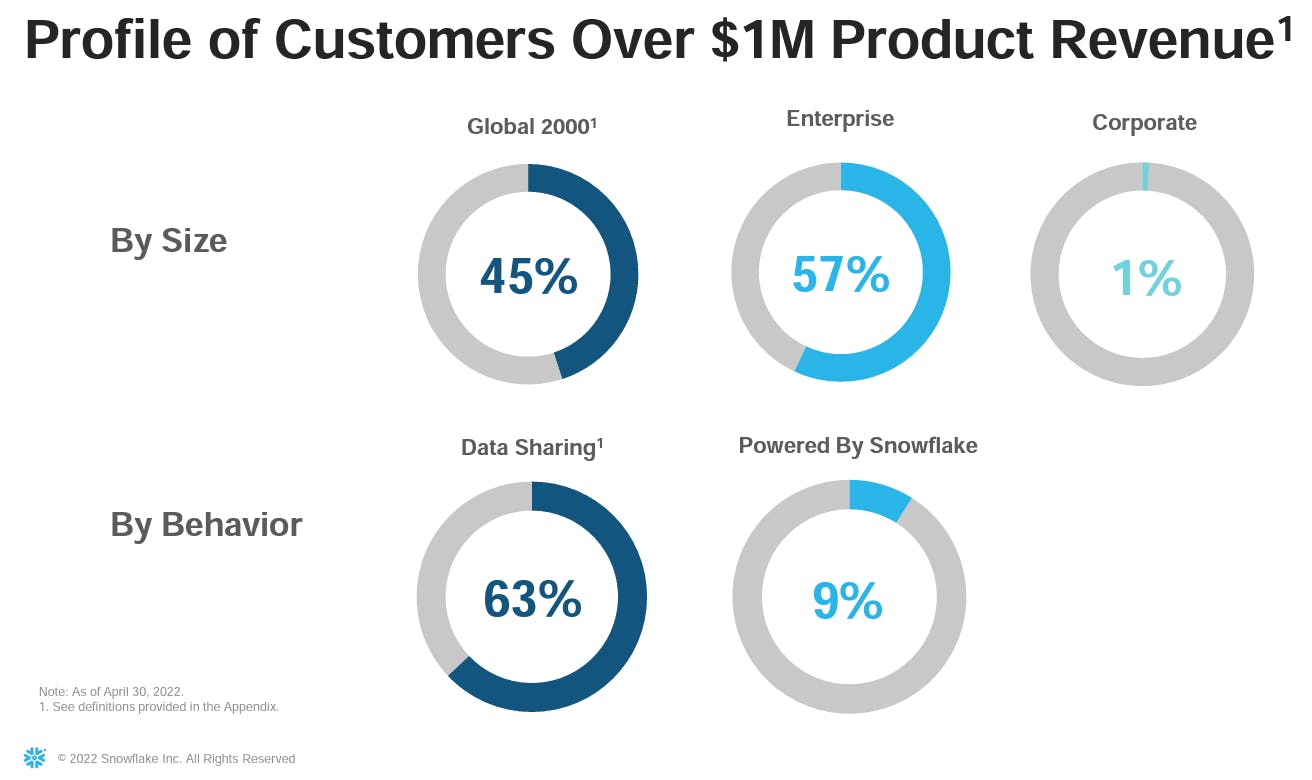
Source: Snowflake Investor Presentation
Going forward Snowflake has laid out their plan to focus on specific verticals like financial services or media and telecom. That emphasis on specific verticals helps to build marquee customers, understand the demands of their unique business problems, and better cater the sales muscle to that use case. The better they understand their verticalized customers the more effectively they can drive expansion across the rest of the customer base within that vertical.
The ability to align cost with value for customers by focusing on usage-based pricing and vertical-specific product requirements allows for more trust between companies like Databricks or Snowflake and their customers. Customers don’t have to worry about adopting a platform where they may find themselves paying for something that no longer provides value (also known as shelfware in software). As a result, customers are less likely to churn off the platform.
Management Teams: The Builders of the Engine
In 2018 Frank Slootman was already retired. He had a stellar record, first transforming Data Domain from a 20 person company into an 800 person team doing $1 billion in sales, and then taking the reins at ServiceNow. Starting in 2011, Slootman supercharged the business, increasing revenue from $75M to $1.5B over his six-year stint. During retirement Slootman got a call from Mike Speiser, the first CEO of Snowflake and founder of Sutter Hill Ventures. Mike wanted Slootman to take the lead at Snowflake. According to Slootman, he didn't consider any other roles, and if the opportunity had come a year earlier, he would have turned it down. But the timing was perfect and the rest was history.
Across the battlefront? Databricks grew out of academia. The company was founded by Ali Ghodsi, Andy Konwinski, Arsalan Tavakoli-Shiraji, Ion Stoica, Matei Zaharia, Patrick Wendell, and Reynold Xin. After building a widely successful open-source project, the team realized that so many users wanted more out of Apache Spark. So they set out to build a company to realize the massive potential they saw for the underlying open-source projects.
Frank Slootman talks about the culture at Snowflake as primarily focused on execution and innovating with new products. Ali Ghodsi focuses more on how they prioritize a culture of being close to the open-source developer community. Getting to this point required both companies to build high-quality products and an effective go-to-market engine. Going forward you’ll start to see these two cultures play out even more. Snowflake is increasingly focused on execution. Databricks is prioritizing innovation outside their core product aspects, leveraging the army of PhDs they have, and leaning into the innovation within their open source community. Neither company will be satisfied with being one of many data tools. The vision? Creating the universal data stack.
The Future: Building the Universal Data Stack
Every business is looking for ways to transform their businesses by capturing and analyzing data to build up their own competitive advantage. The migration to the cloud continues to push forward. According to IDC, 49% of data will be stored in public cloud environments by 2025. Similarly, 90% of Global 1000 Organizations will have a multi-cloud management strategy by 2024.
Understanding the TAM
Snowflake and Databricks are positioned to capture each of these tailwinds. They provide the underlying infrastructure for capturing value from data. Organizations continue to invest billions of dollars in cloud and data infrastructure to capitalize on these opportunities. While either company could be limited to their existing TAM (data warehousing or data analytics) the future is much brighter than that. Snowflake recently articulated their opportunity based on the workloads they can address
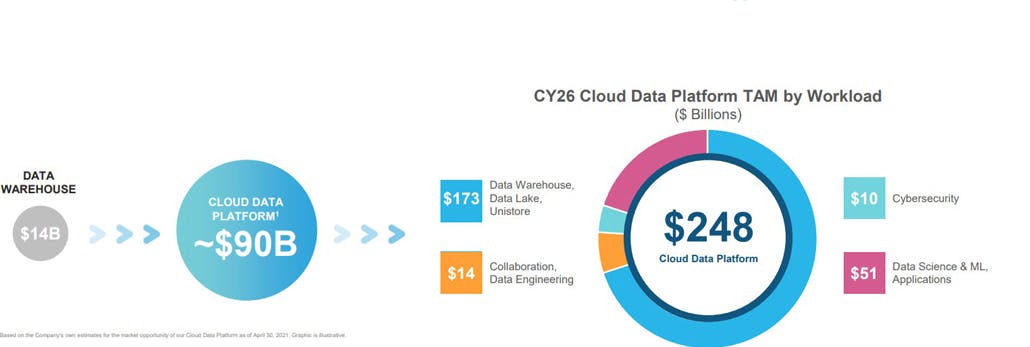
Source: Octahedron Capita/Snowflake
By extending across data lakes, storage, collaboration, cybersecurity, and data science Snowflake believes they can address the entire $200 billion+ data market. At IPO Snowflake pegged their market opportunity simply as the $90 billion for cloud data. In the same way Databricks is largely pegged to the ~$51 billion TAM within data science and ML applications. But each company is focusing on the advantage they can build out of the core data warehouse or data lake. If you think back to all the product innovation we’ve seen from Databricks and Snowflake you’ll see them play out in each of these segments.
$173 billion from data warehousing, data lake: This is the core market today where both companies play, whether the focus is on analytics or intelligence.
$51 billion from data science, ML, and applications: This is the core market for Databricks, and is growing 40%+ year-over-year.
$14 billion from collaboration and data engineering: Both Databricks and Snowflake are leveraging data share and their own data marketplaces to get more exposure to the collaborative benefits of data.
$10 billion from cybersecurity: Because Snowflake has sat at a more central place in a company’s data ecosystem they’ve been more focused on security and therefore have more advanced functionality. But as each company seeks to become more of a center of gravity cybersecurity will become more central to the conversation.
Competitive Moats
Some of the advantages that Snowflake and Databricks have are high switching costs and network effects.
Switching costs arise from the fact that once a company transitions all their data and begins running multiple workloads in a data warehouse or data lake it becomes increasingly difficult to switch platforms. Multi-cloud can make the switch even more complex.
Network effects come from data sharing and collaborative marketplaces. The more customers adopt these platforms the more they can share and receive data from others, such as customers, partners, and data providers. Over time, there is potential for businesses and multiple applications to be built on these marketplaces. We believe the marketplace has tremendous potential to increase the value of both companies over the long run.
This doesn’t mean that Snowflake and Databricks aren’t without their own competitive threats from other companies. For more on some of those threats see our competitive landscape in the Appendix.

Source: Annika Lewis
Both companies will continue to build their product and go-to-market motion around the vision of becoming the universal data stack. Is Databricks better positioned to use its edge within open-source and data science? Will Snowflake’s position within the data warehouse win the day?
If you take one thing away from this report it’s this: the battle is far from over.
Snowflake began as a cloud-native data warehouse with strong capabilities in data storage. Meanwhile, Databricks began its journey as a cloud-native data lake built upon open-source Apache Spark with robust data compute. Some people believe Snowflake has an unfair advantage as a public company with a well-established multi-product platform in their Data Cloud. Databricks has only recently launched their Data Lakehouse vision and is catching up in terms of becoming a more central piece of the data stack. While the visions that Snowflake and Databricks are laying out puts them in direct contention with each other, the reality is they rarely overlap day to day.

Source: Wolfe Research/Databricks+Snowflake Research
Instead the opportunity is to understand the vision each company is laying out and what that means for the data stack of the future. Each company is setting out to build one universal data stack that incorporates aspects from storage and compute to analytics and data science. They are even extending into building data-rich real-time applications and transactional workloads.
Every organization wants to answer the question of “What will happen?” for their own business. The more efficient data management gets and the more robust machine learning becomes, the more effectively people will be able to answer that question.
In the battle of the data titans the winner will likely come down to some key things that will play out over the next few years:
Product Penetration: The longer it takes each company to penetrate into the broader market segments in that $200 billion+ TAM the more difficult it will be to achieve ubiquity. If Databricks takes too long to expand their use cases further outside data science then they’ll be competing with a much more entrenched Snowflake. If Snowflake fails to build a more robust data science product they’ll fall behind given Databricks’ superior resources within their open source community
Go-To-Market Strategy: We’ve laid out the different approaches Databricks and Snowflake have taken to their relative end-markets. The big question now will be (1) how quickly can each company continue to push up-market? The larger, more established customers can set the tone for future generations of customers. The same is even more true in specific verticals. The company serving the largest players in a given vertical will have an unfair advantage towards massive expansion (e.g. as Snowflake establishes themselves in banking it may be easier for them to start selling their data science modules vs. those same banking customers talking with Databricks)
Leadership Execution: While both teams represent tenured software executives there is a clear difference between the “tried-and-true” professional C-Suite that Snowflake has put together and the “born in the trenches” open-source team that is leading the charge at Databricks. Each can dramatically dictate the future ability to execute
Appendix
Product Differences
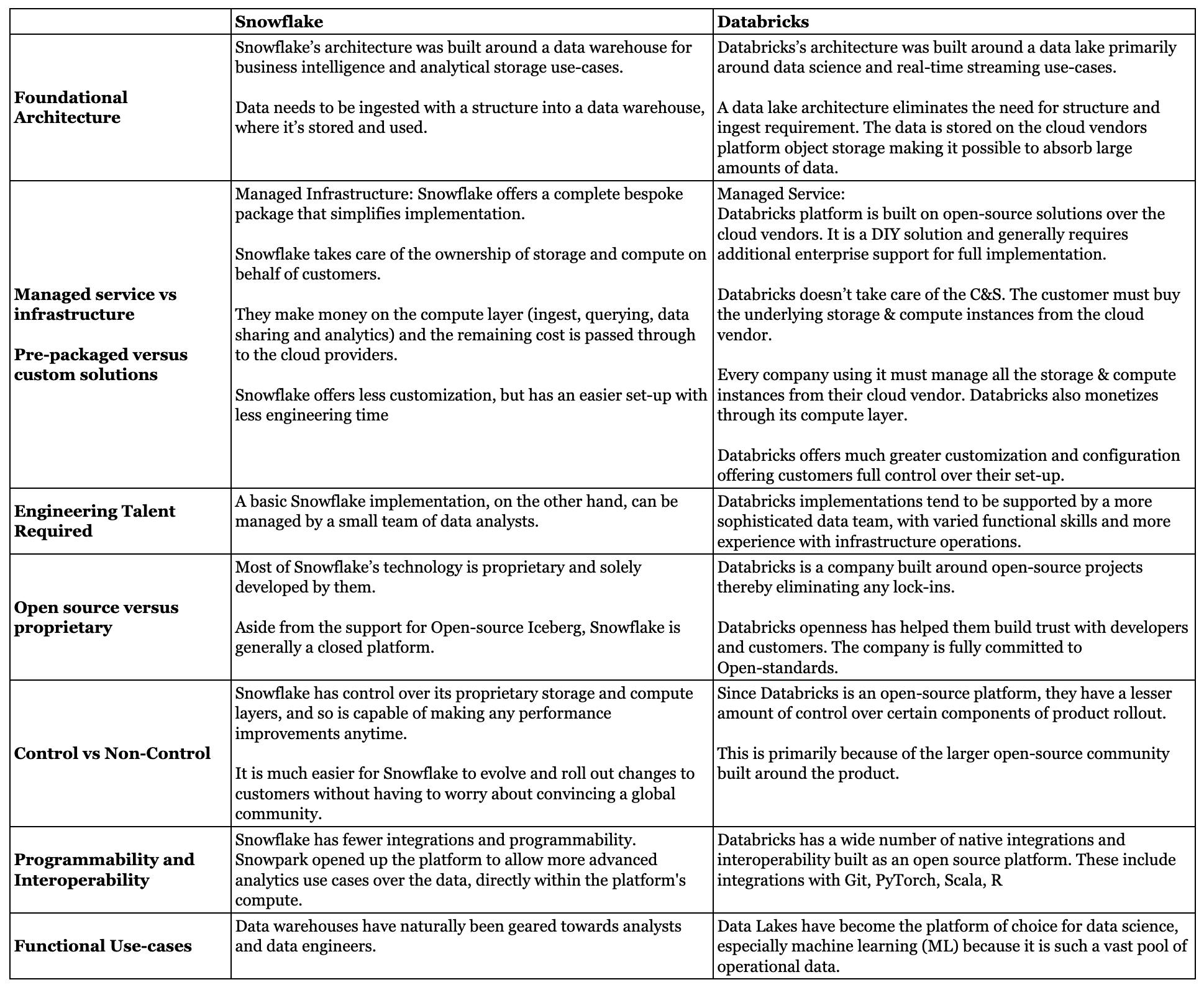
Source: Contrary Research
Talking The Talk
To better understand Databricks and Snowflake there is some key terminology to get down. These include databases, data lakes, data warehouse and the ETL (Extract, Transform and Load) process.
Databases
The best way to think of a database is to look at it as an organized collection of structured information, or data. There are two types of Databases:
Transactional databases (OLTP)
Online Transaction Processing (OLTP) is a system for capturing and maintaining transactional data in a database. Transactional data in the context of day-to-day information that is needed to run the operations of a business. OLTP databases are commonly used in applications like online banking, ERP systems, or inventory management, enabling quick updates to row-level data that are processed almost in real time.
Analytical databases (OLAP)
An Online Analytical Processing (OLAP) system applies complex queries to large amounts of historical data, aggregated from OLTP databases and other sources, for data mining, analytics, and business intelligence projects. Snowflake and Databricks are primarily built as OLAP systems. Data warehouses are OLAP systems that give analysts and decision-makers the ability to use custom reporting tools to turn data into insights.
Data Warehouse
A data management system that stores a company’s processed, current, and historical data from multiple sources for easy consumption and reporting. Data warehouses absorb information in a very structured and hierarchical format that is difficult to obtain directly from transactional databases. The data warehouse is used to store processed and structured data that can be used for machine learning and business intelligence purposes.
Data Lake
This is a centralized system that is able to hold a large amount of raw data in any format. A data lake can absorb structured, unstructured and semi-structured data. A data lake uses flat architecture and object storage to store the data. The data lake is used to automatically pull in data real-time. The near limitless scale of the cloud enables the near limitless scale of the data lake. The platform can absorb a massive amount of data as information flows in. A data lake also allows data to be stored very cheaply since it does not require tables or structure associated with a regular database platform. It uses a low-cost object storage for the storing of raw data. It is important to note that a Data Lake does not replace a Data Warehouse.
Key difference between data lake and data warehouse
A data lake can be used to store structured, semi-structured and unstructured data. Meanwhile, a data warehouse only stores structured data that has been processed for operational use. A data warehouse is a data management system that stores current and historical data from multiple sources in a business friendly manner for easier insights and reporting. Data warehouses are typically used for business intelligence (BI), reporting and data analysis. Meanwhile, data lakes are used for data science and machine learning use-cases.
ETL
This is the process of transforming data from a database into a data warehouse (like Snowflake) or data lake (like Databricks). ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are two different ways of transforming data. Data engineers often use ETL to extract data from different data sources and move it into the data warehouse, where they can easily cleanse and structure it. ELT, on the other hand, loads data into the warehouse in its original format first, and cleanses and structures it as it is processed.
The raw data from transactional databases and other sources is processed in advance around predefined business objectives. The refining process would typically involve taking the raw data from multiple sources, merging it into a single dataset (blending), then cleaning, enriching, filtering for duplication, and removing personal info (scrubbing). This data processing is typically done in a separate staging area (likely a separate database), then imported into the Data Warehouse once refinement is complete using python scripts.
Data Lakehouse
This is a new open data management architecture that combines the strengths of a data warehouse with a data lake into one centralized platform. A lakehouse brings together the flexibility, cost-efficiency, and scale of data lakes with the data management and transactional layer of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data.
Competitive Landscape
Amazon AWS RedShift
Due to AWS’ early success with the cloud, Redshift has been one of the most logical alternatives to Databricks and Snowflake. Around 2017, Redshift was able to decouple storage from compute. Amazon was only able to solve through a license to the source code for ParAccel, a legacy relational database that was later acquired by Actian. As a result, Redshift isn’t able to separate compute from storage at as granular a level as Snowflake can.
Redshift lacks the ability to provide time-travel (ability to restore lost data), cross-cloud replication and zero-copy cloning. Redshift only recently added support for semi-structured data. Snowflake is a managed solution whereas Redshift is a Platform-as-a-Service (PaaS). Redshift also lacks the ability to do data sharing for cross regions and multi-cloud.
Since Redshift wasn’t built from the ground up to be a cloud-native data warehouse, they don't have the same level of speed and scalability as perhaps Snowflake and Databricks.
The most popular data lakes are just the native object storage products that each major cloud provider offers. AWS’s object storage solution – S3 (Simple Storage Service) – is probably the most widely used data lake right now. S3 is a general purpose product – your favorite apps probably use it to store profile pictures – but AWS has some ancillary products and services that format it for use as a data lake, e.g. LakeFormation lets you set data access policies for your data in S3.
Google’s Big Query
Google internally developed BigQuery in 2011 and over time, successfully separated compute and storage. While BigQuery lacks some enterprise features, it has differentiated features such as tight integration with Looker (ETL/Visualization tool) and the ability to analyze data sitting in other cloud vendors such as AWS and Azure. GCP generally lacks the comprehensive suite of features to match Snowflake and Databricks.
Azure SQL Data Lake + Synapse
Synapse (formerly SQL Data Warehouse) also has the ability to independently scale storage and compute so that customers only have to pay for the query performance they need. Azure built their platform using Massive Parallel Processing (MPP) engines. Data is stored in Azure Blob storage and compute nodes are spun up when needed. Microsoft’s data warehouse has the ability to query structured and unstructured data, but it is mainly used for structured datasets. Another benefit for Azure is a cloud extension of its SQL server family of products which existing customers can utilize.
Legacy & DIY Solutions
There are other legacy competitors such as Oracle Autonomous Data Warehouse, IBM Db2 Data Warehouse and IBM Cloud Pak for Data System, Yellowbrick Data Warehouse (pure SaaS) and Teradata Vantage data warehouse.
There are many other do-it-yourself solutions on the market. These are platforms for companies who want to implement data warehouse solutions without implementing a snowflake or databricks platform.
MongoDB Atlas for data analytics
Presto (open-source distributed SQL engine)
Apache Pinot (open-source distributed OLAP database)
Apache Druid (open-source distributed columnar analytical database)
ClickHouse (open-source distributed columnar analytical database)

