
Thesis
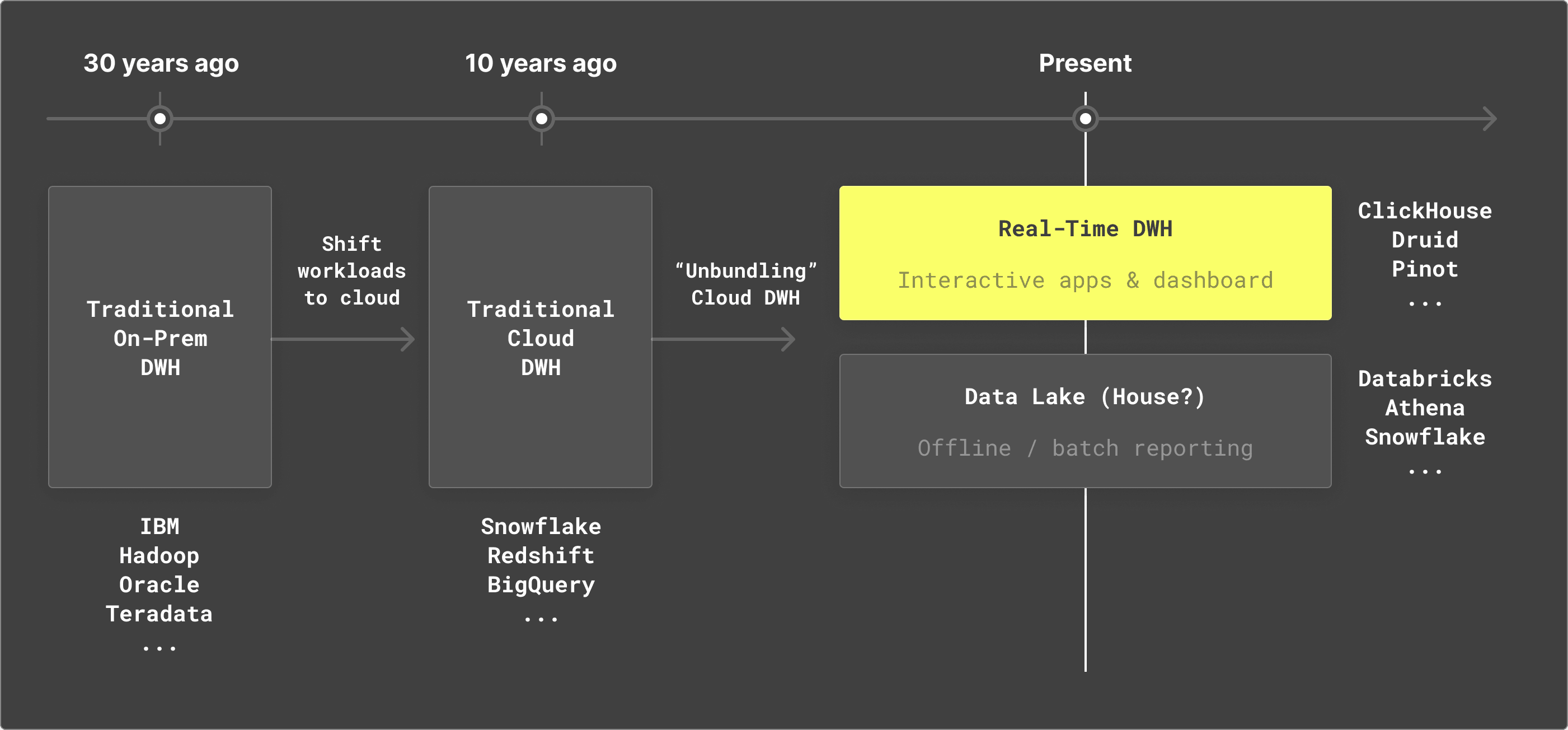
From 2010 to 2023, global data generation has surged by an estimated 60x, from 2 zettabytes in 2010 to 120 zettabytes in 2023. This has spurred an evolution in the enterprise data management systems responsible for standardizing and storing the growing volumes of data. Unlike traditional data warehouses subject to inflexible architectures and difficulty managing resources, cloud warehouses like Snowflake and Databricks modernized the industry, allowing organizations to store and query petabytes (PBs) of data through managed cloud services. While fundamentally sound for storing enterprise-scale volumes of data, such platforms still lacked capabilities to enable teams to interact with the data in real time.
A 2018 Gartner study showed that organizations failed to use over 97% of their data, primarily due to the lack of accessibility and query speed. While warehouses enabled storage and compute, most lacked real-time access. As one former VP at VMWare put it, “businesses [are] competing on how well they use data, not how well they use software.” Regardless of function, teams increasingly rely on methods to quickly aggregate large volumes of data. Marketers require real-time insights across channels and campaigns, financial analysts track large transactions over time, and DevOps teams ingest logs and events across devices to create alerting and observability.
Cloud data warehouses were not suited to address real-time requirements, resulting in data propagation delays across large data set pulls, slow query performance for multiple joins, and increasing costs due to high compute requirements from frequent data pulls. The traditional data warehouse solved the need for storing and batching large data but unveiled a gap in a data solution for real-time interaction and analytics.
Source: ClickHouse
ClickHouse was built to address such concerns, offering a real-time processing warehouse to enable interactive data visualizations and real-time analytics. To complement traditional warehouses' offline capabilities, ClickHouse optimizes around low latency and high interactivity across complex joins and large data aggregations. In what ClickHouse CPO Tanya Bragin deems the “unbundling of the cloud data warehouse,” ClickHouse has aimed to address a growing gap between the needs of consumers and the capabilities of existing analytic tooling.
Founding Story

Source: ClickHouse
ClickHouse (short for Clickstream Data Warehouse) was founded in 2021 by Alexey Milovidov (CTO), Yuri Izrailevsky (President of Product & Technology), and Aaron Katz (CEO).
According to a 2021 blog post by Milovidov, the idea for ClickHouse originated when he was working at Russian search engine Yandex, where he had been working to develop a real-time web analytics system. As Milovidov put it:
“In 2009 we started ClickHouse as an experimental project to check the hypothesis if it's viable to generate analytical reports in real-time from non-aggregated data that is also constantly added in real-time”.
Milovidov’s team began experimenting with analytical processing tools to power Yandex Metrica, Russia’s second-largest web analytics platform. After three years of development, they launched the initial prototype in 2012 internally as the primary database management system behind Metrica’s analytics engine. They quickly saw organic adoption across internal teams at Yandex, prompting Milovidov to consider moving ClickHouse from an internal tool to a publicly available platform. The team continued iterating on the product for the next four years before deciding to open-source it in 2016.
The decision proved pivotal, significantly broadening the exposure beyond Yandex and finding success with early adopters like Lyft and Comcast. While adoption continued to grow and community contributions sped development cycles, the core team of 15 couldn’t keep up with the growing demand without investment and proper organizational structure.
In 2021, Milovidov incorporated ClickHouse as a separate entity. He brought on co-founders Aaron Katz as CEO and Yury Izrailevsky as President of Product & Technology. The same year, the company received its initial investment, a $50 million Series A led by Index Ventures and Benchmark. After the company’s launch, Milovidov stated:
“We want to make ClickHouse suitable for all kinds of companies and enterprises, not just tech-savvy internet companies who are fine with managing their clusters. We want to lower the learning curve, make ClickHouse compliant with enterprise standards, make ClickHouse service instantly available in the cloud in a serverless way, make auto-scaling easy, and much more.”
The team has kept the product open source since the company was launched, and has scaled the team internationally across 10 countries as of April 2024.
Product
ClickHouse is a database management system optimized for real-time data analysis and reporting. Its architecture is built for analytical processing and is intended to handle a larger volume, velocity, and variety of data relative to its peers and legacy systems.
Traditional database management systems (DBMS) are built off the concept of transactions (OLTP) — they are optimized for processing many small, individual operations like managing orders and updating records. ClickHouse complements this by focusing on complex analytics and reporting on larger volume loads (OLAP).
Architecture and Approach
ClickHouse’s execution speed and real-time analytic capabilities result from attention to detail on the technical architecture of the core platform. The product was first built to do one task well: filter and aggregate data as quickly as possible.
Most programming languages provide an out-of-the-box implementation for most common algorithms and data structures but tend to be generic for high-volume transactions. For a standard “Group By” operation, ClickHouse has implemented over 30 algorithm variations for optimal performance contextual to the query.
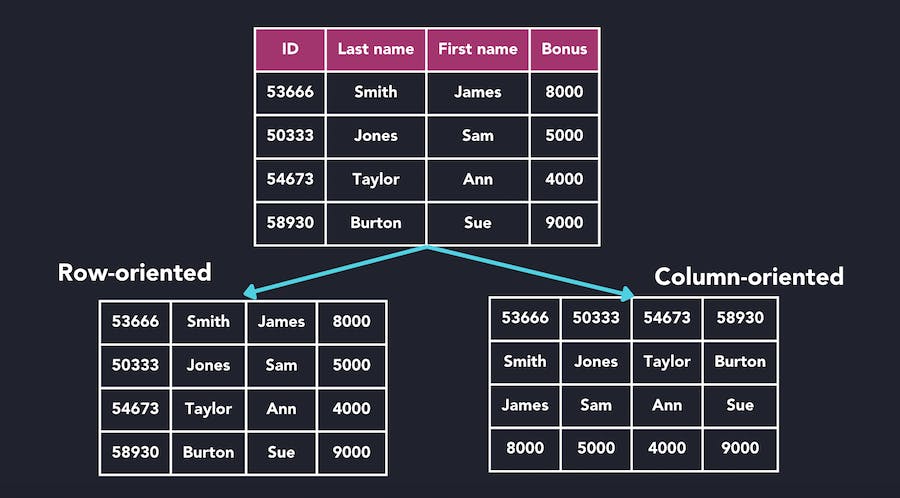
Unlike traditional Database Management Systems built on a row-based schema, ClickHouse relies on columnar storage, making it more efficient for read-intensive operations. With each column stored separately, aggregation queries (like SUM, MIN, MAX) only need to read data from relevant columns, significantly reducing the amount of data that needs to be read from disk. This reduces the cost of unused data on read queries and more quickly indexes the relevant data points.
For example, a company that stores employee information may need to calculate average bonuses paid across specific teams. With the direction of storage scans from left to right, the column-oriented structure allows direct access to requisite columns without the overhead of non-needed data.
Source: QuestDB
While ClickHouse has optimized for speed, it has not claimed to be a silver bullet for all workloads. The product was built specifically to optimize real-time aggregations and reporting. Having to service use cases like Metrica (processing over 100 PBs of data with more than 100 billion records) and the needs of early adopters like Cloudflare (processing a large portion of all HTTP traffic on the internet, over 10 million records/second), the tool was specifically built for scale. That said, it is not best suited for transactional processing and row-level writes, which require full disk scans for even single record updates.
Product Features
ClickHouse is a database management system at its core, meaning its primary job is to store and serve large volumes of data. It specializes in high volume, online analytic workloads, and has claimed a 100-1000x faster processing speed than traditional row-oriented systems with the same available I/O throughput and CPU capacity. The speed and flexibility are derived from a series of product capabilities and technical features:
Continuous Data Ingestion: Continuous data pipelines more seamlessly move data from source to destination, often involving real-time processing. While most data sources must be loaded into ClickHouse in batches, ClickPipes was released to quickly set up a real-time ingestion pipeline, integrate with common streaming data sources, and flexibly scale and handle increasing data volumes. With over 80% of Fortune 100 companies using Apache Kafka as of April 2024, it’s a valuable addition for plugging such streaming sources into a real-time database.

Source: BusinessWire
Merge Tree Engine: The core of ClickHouse’s performance lies in the family of storage engines that power most of the database functionality and insert large amounts of data to the table (by writing to the table part by part, then merging parts in the background). The base Merge Tree is the default engine for single-node ClickHouse instances and is the most use case agnostic. The ReplicatedMergeTree is best suited for production loads, adding high availability, automatic data duplication, and auto retries in case of networking failure. Other engines in the family address specific use cases and may require manipulation of background data.
Data Compression: ClickHouse’s performance can be attributed to its efficient data compression techniques. Compression is critical in database systems as it reduces the size of files or data streams to use less storage space or transmission bandwidth. ClickHouse offers general-purpose compression algorithms for common operations but has also built specialized codecs (algorithms) for specific kinds of data and competes with more niche databases.
Vectorized Query Execution: ClickHouse stores and processes data in columns. Vectorized query execution streamlines operations by processing blocks in bulk, storing each column as a vector, and interacting through the vector. The technique utilizes modern CPU architectures and instruction sets to process multiple elements simultaneously, significantly improving performance.
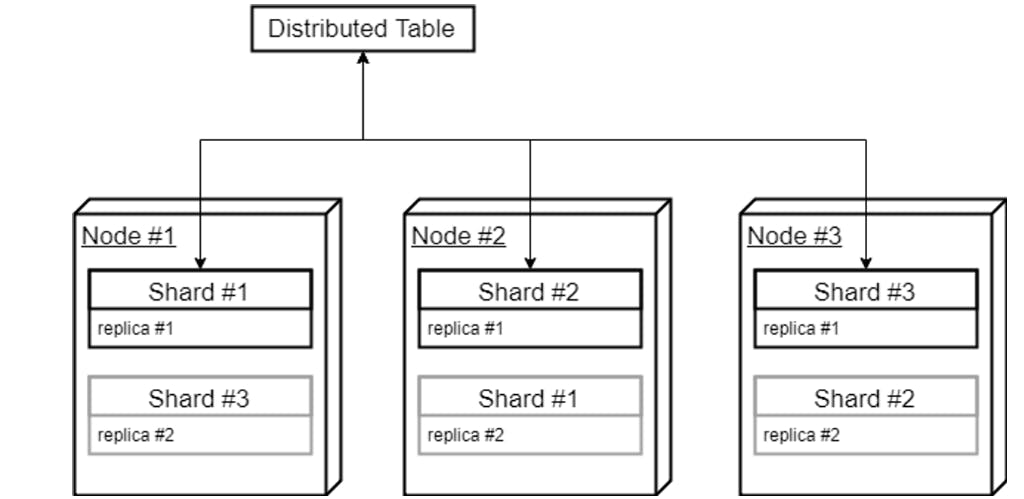
Distributed Processing: Data distribution splits datasets into shards stored on different servers. ClickHouse offers a Distributed Table Engine that doesn’t store data but allows distributed query processing across multiple servers. Once the results are received from relevant servers, the coordinator node aggregates results and returns the answer.
Materialized views: A materialized view in ClickHouse is a database object that stores the result of a query. Unlike a standard view, which is just a saved query executed on demand, a materialized view saves the query's result to disk, similar to a table. Materialized views automatically on changes to the underlying source table change. This is most often used for more common queries within a larger data set. Rather than process queries each time a data set is used, materialized views save the query information to allow for easy access, reducing time and money.
Built-in functions and aggregators: ClickHouse supports many functions tailored toward analytics and handling large datasets. These include aggregate functions, table functions, and window functions. They also allow the creation of custom aggregate functions through a specialized AggregateFunction data type. While most common functions are available in general SQL syntax, most ClickHouse functions are optimized for performance on large data sets to take advantage of columnar storage and in-memory processing capabilities. ClickHouse also allows users to define their own functions for specific analytical tasks.
Scalability and High Availability (HA): Scalability and HA are critical concepts in efficient databases. ClickHouse allows for simple auto-scaling to accommodate larger volumes of data and provides replication to ensure data availability and fault tolerance. Based on a multi-master replication scheme, redundancy exists in case of server failures. ClickHouse has invested in optimizing low-level implementation and execution details to accrue performance gains. It lists and maintains its set of features in its docs.
Deployment
ClickHouse offers multiple deployment options based on needs and preferences: it shares recommendations on the choice of hardware to run on, including the number of cores, CPU architecture, RAM, and storage.
ClickHouse Cloud: ClickHouse Cloud was released as a managed service by ClickHouse that allows users to focus on development rather than sizing and scaling the underlying infrastructure.
Single Node Deployment: The single-node deployment is the simplest option for deploying ClickHouse on-premise and is commonly used for smaller-scale development environments. While not optimized for productionized loads, the single server option can still process billions of records while helping to keep the cost down.
Cluster Deployment: Clustering requires setting up a ClickHouse across servers and setting up proper cluster parameters to enable the servers to work together. This includes defining the cluster topology, shards and replicas, and node communication. ClickHouse also allows for automatic cluster discovery, allowing nodes to discover and register themselves with the manual definition of each. Once tables are created on each instance, a distributed table is created as a master “view” into each local table in the cluster.
Source: Altinity
Data Stack Embedding and Integrations
ClickHouse is an OLAP data warehouse and fits into a broader data ecosystem and modern data stack. With that, it relies on several integrations that allow for seamless reading and writing from data sources and emitting returned query results to data visualization platforms.

Source: Renta
ClickHouse splits its integration by type and support level, including core integrations, partner integrations, and community integrations. The integration types are categorized by language clients, data ingestion, data visualization, and SQL client categories:
Data Ingestion: Data ingestion is collecting and importing raw data from sources into ClickHouse for centralized analysis. Some ingestion integrations include Apache Kafka and PostgreSQL.
Data Visualization: With ClickHouse primarily used for large, analytic workloads, data visualization is a common use case. ClickHouse provides many native integrations with visualization platforms, including Tableau and Looker.
Source: Redash
Programming Language Interfaces: With many of its target customers data engineers, ClickHouse also provides programming language interfaces, allowing users to write custom functions and scripts to interact with its data.
SQL Client: ClickHouse provides a native command-line client for interacting with data, but it also integrates with other clients built for visualizing and writing queries against data sets.
Market
Customer

Source: ClickHouse
Milovidov built ClickHouse to report on and aggregate search metrics for Yandex, and many early adopters began leveraging the tool for similarly high-volume use cases in adjacent functions (DNS queries, operational logs, security/fraud). With the initial release being open-source, there was no formal marketing or sales motion, meaning adoption was driven by word of mouth and in-person events. The product found success with some high customers early on, including Cloudflare for handling DNS analytics and Uber for internal logging.
The product sits at the infrastructure layer and is horizontal by nature. Any use case that requires aggregation of large data loads could benefit from ClickHouse, and since its inception, the customer base has spanned size and function. Since its release, ClickHouse has maintained a list of customers and adopters as well as relevant blogs, links, and reference material. The list emphasizes its horizontal appeal, serving use cases and teams across security, travel, ecommerce, fintech, and many more.
As of April 2024, notable customers of ClickHouse include IBM, Microsoft, Cisco, Spotify, Sony, Lyft, Gitlab, Deutsche Bank, HubSpot, Checkout.com, Cloudflare, eBay, Twilio, and ServiceNow. As of April 2024, ClickHouse is used by over 100K developers.
Market Size
The market for database management systems was estimated at $63.4 billion in 2022 and was projected to grow at a CAGR of 11.8% until 2030 to reach a size of $154.6 billion. The data warehouse market, meanwhile, was valued at $5.6 billion in 2022 and was projected to reach $28.6 billion by 2030.
Competition
Traditional Database Management Systems
Oracle Database: Oracle released its Oracle Database in 1977. It later released an Oracle Warehouse Builder as an integrated ETL tool for designing, deploying, and managing data integration processes. In 2018, Oracle released its Autonomous Data Warehouse, optimized for analytic workloads. While built to support analytic workloads, the product indexes security and automated actions rather than the speed of real-time analytic reporting.
Microsoft’s Azure SQL Database: Microsoft provides various analytics products, from streaming to general enterprise analytics. Its flagship product is Microsoft SQL Server, a relational database management system. The product is more suited for transactional workloads based on a row-based storage model. It supports traditional SQL language with additional extensions, unlike ClickHouse’s proprietary ClickHouse SQL language. Microsoft SQL server has been around much longer (first released in 1989) and maintains a mature ecosystem of integrations and libraries.
Specialized Analytical Databases
Amazon Redshift: Launched in 2012, Amazon Redshift is a cloud-based, petabyte-scale data warehouse service provided by Amazon Web Services (AWS). It's designed for large-scale data storage and analysis, making it ideal for businesses with extensive data warehousing needs. As a service under AWS, Redshift's development and expansion are supported by Amazon's significant resources.
Its integration with other AWS services makes it a compelling choice for businesses already within the AWS ecosystem. Redshift compiles code for each query execution plan, which adds significant overhead to first-time query execution. When working with interactive applications with variable queries, this does add considerable overhead. ClickHouse also provides a much higher limit on concurrent queries.
Google BigQuery: BigQuery was first introduced in 2010, and stands out as a fully managed, serverless data warehouse that enables scalable analysis over petabytes of data. Part of Google Cloud benefits from Google's advanced infrastructure. BigQuery’s unique serverless approach allows for consistent performance on a diverse range of query sets and access patterns, though it still lacks sub-second analytical queries for more predictable query patterns. It also touts a user-friendly interface with a GUI wrapper and the ability to save progress.
Like ClickHouse, BigQuery is built off a columnar storage schema but lacks some granular optimizations unique to ClickHouse (including materialized views, vectorized query execution, and specialized engines). While the tools can address similar use cases, they’ve been used as complements due to BigQuery’s easy integration with existing Google products and ClickHouse’s performant aggregations.
Snowflake: Founded in 2012, Snowflake is a cloud-based data platform known for its distinct architecture that separates computing and storage, allowing for scalable and flexible data processing. It went public in 2020 with a market cap of over $70 billion, and its market cap as of April 2024 is $52.9 billion.
Snowflake’s unique offering lies in providing a data warehouse-as-a-service that supports structured and semi-structured data, appealing to a wide range of data-driven businesses. Based on a benchmark analysis from 2023, ClickHouse outperformed Snowflake for real-time analytics in a few areas: query latency (~2x compute to achieve equivalent performance on filtered queries) and cost (Snowflake charging only for execution time, optimized for workloads that often sit idle).
Open Source OLAP Databases
Apache Druid: Apache Druid, which was released in 2011, is an open-source project designed for real-time analytics and handling high-concurrency queries. As an Apache Software Foundation project, it's supported by community contributions and companies that utilize it. Druid's real-time data ingestion and rapid query capabilities suit it for time-sensitive analytics scenarios. While similar in structure, customers like Lyft have shared drawbacks and issues faced with Druid including a high upfront cost of onboarding new teams and a high cost in general.
PostgreSQL: PostgreSQL, which launched in 1986, is an open-source relational database that can become an analytical tool when enhanced with extensions like Citus or TimescaleDB. Its main strengths are PostgreSQL’s extensibility and robust community support, though it is not natively optimized for analytical workloads. The two solutions address very different use cases and oftentimes can work in conjunction (for OLTP use cases and complementary OLAP needs).
Business Model
ClickHouse's pricing model is based on usage and offers different tiers to cater to various needs. For instance, the Development tier costs between $1 and $193 per month, with up to 1 TB of storage and features like automatic scaling and AWS Private Link. The Production tier, designed for larger workloads, has a usage-based pricing model with unlimited storage, starting at $47.10 per TB per month for storage and $0.6888 per unit per hour for computing. Additionally, ClickHouse provides a Dedicated tier for the most demanding workloads, offering custom compute options and advanced security features.
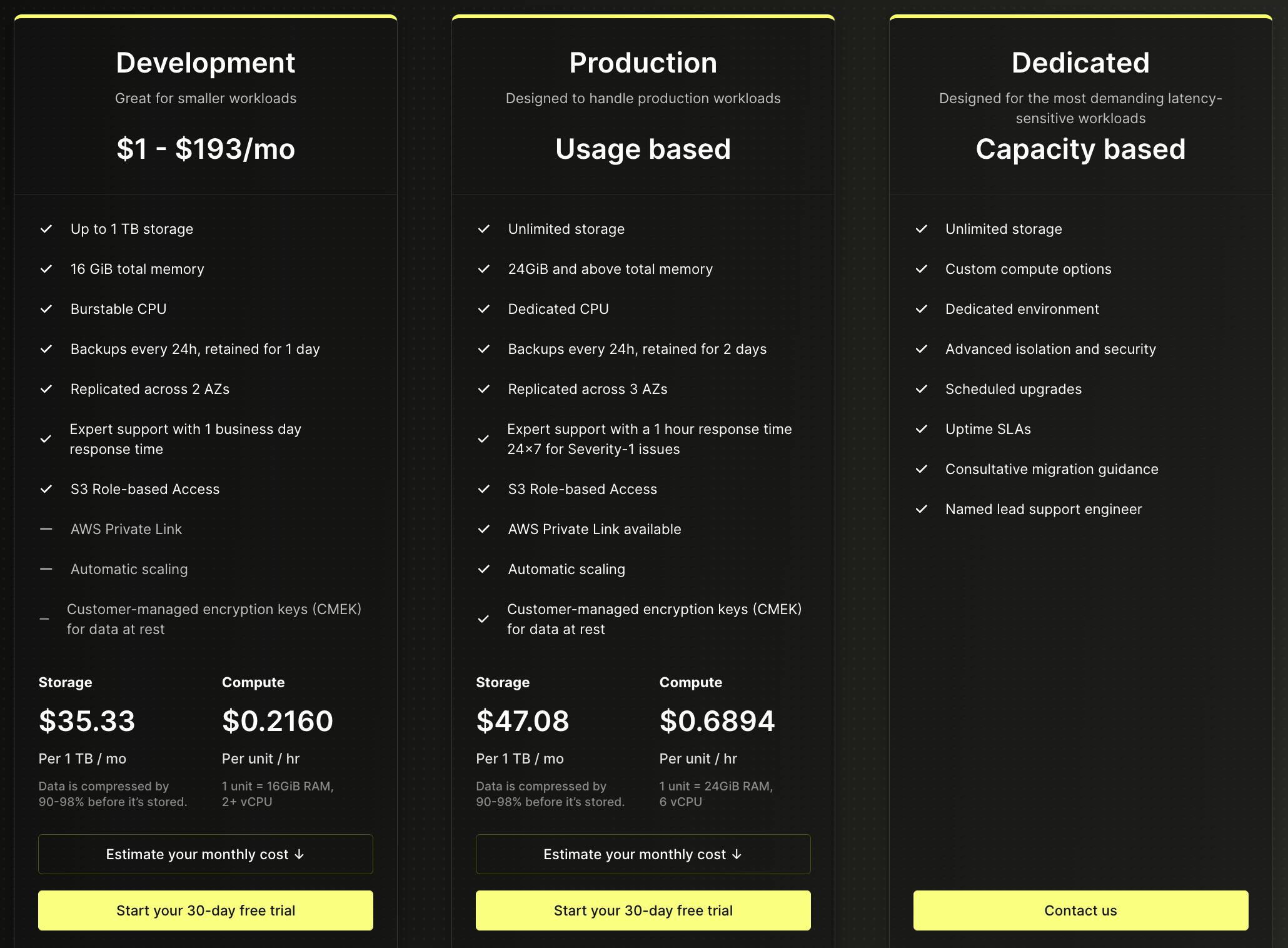
Source: ClickHouse
The company's major costs likely include expenses associated with cloud infrastructure, research and development, and expanding its product and engineering teams. ClickHouse has emphasized a product-led growth (PLG) strategy, investing in product improvements to drive adoption rather than investing heavily in sales and marketing. This approach suggests a relatively asset-light model, which relies more on software and cloud infrastructure than heavy physical assets. However, long-term structural costs could include ongoing development to maintain competitiveness and potential expansion of cloud infrastructure to support growing user demand.
Traction
Since becoming open source in 2016, ClickHouse has seen mass adoption among the developer community despite its relative newness. As of April 2024, it had amassed over 34.2K stars on GitHub and 130K commits, as well as over 100K developers using the product.
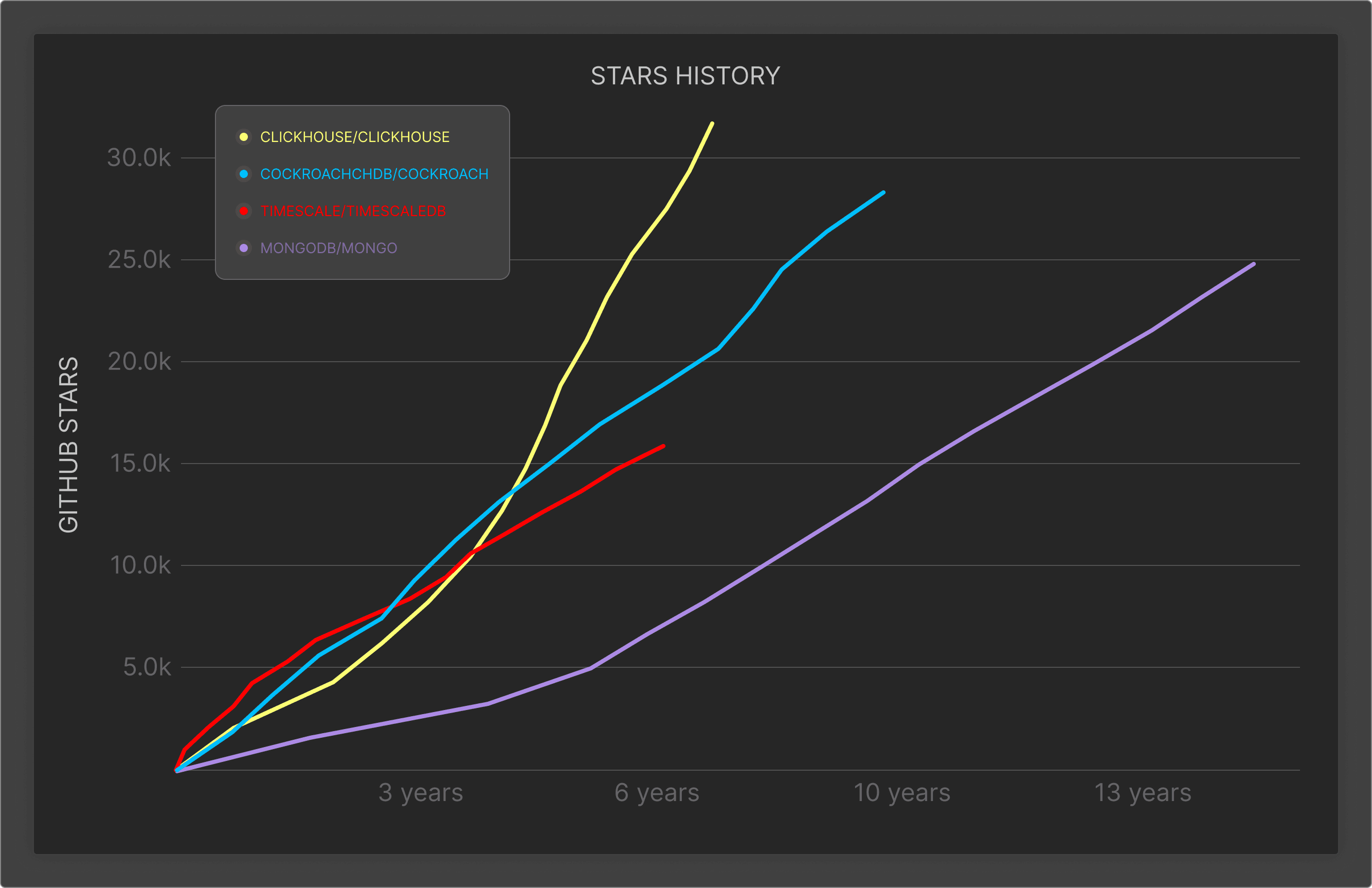
Source: ClickHouse
As of April 2024, notable customers of ClickHouse include IBM, Microsoft, Cisco, Spotify, Sony, Lyft, Gitlab, Deutsche Bank, HubSpot, Checkout.com, Cloudflare, eBay, Twilio, and ServiceNow. According to an unverified third-party estimate, the company’s annual revenue was $28.5 million as of 2024.
Valuation
ClickHouse raised a $250 million Series B in October 2021 at a $2 billion valuation. The round was led by Coatue and Altimeter and included participation from Index Ventures, Benchmark, Lightspeed, and Redpoint. The company stated that the funding it raised was intended to help grow the team, scale the product, and build a more commercial-grade cloud solution. As of April 2024, the team has raised a total of $300 million over three funding rounds.
Key Opportunities
Data as the Foundation of AI/ML
AI models require processing and analyzing large datasets to train and make predictions. Data must also be stored to be fed into AI models or to extract insights from AI outputs. The demand for sophisticated data analytics pipelines increases as AI and ML models become more integrated into business processes.
Data management can be tricky, and ClickHouse has already begun to establish itself as the source data system for managing multiple stages of the machine learning data workflow — from data exploration and preparation to feature and vector storage and, finally, observability. ClickHouse has established itself as a solution to the bloat of AI solutions and invested in AI products and features like GenAI-powered query suggestions and integration with existing AI models directly through SQL workloads.
Cloud-Native Expansion
ClickHouse's ongoing development of a cloud-native architecture, in which compute and storage are more decoupled, aligns with the broader industry shift towards cloud services. This evolution presents a significant opportunity for ClickHouse to expand its reach and appeal to a broader range of customers migrating to cloud-based solutions for scalability and flexibility.
Investments in Complementary Technologies
No one database solution can feasibly take over the entire data market, meaning there are broader opportunities to find complementary solutions and leverage individual product strengths. ClickHouse has openly acknowledged its strength as an OLAP solution and has even shared strategies for integrating with complementary systems and database management systems like PostgreSQL. Some customers have also shared their stories of migrating certain elements out of Postgres and into ClickHouse.Source: ClickHouse
Key Risks
Competitive Landscape
ClickHouse shines in some very specific areas of processing and database management, but many companies are largely dependent on existing data tooling and management systems. ClickHouse's success will be largely dependent on strong and growing user adoption alongside clear data migration paths and adoption strategies.
ClickHouse Tuning and Best Practices
ClickHouse is known for its speed, though much of the performance optimization is reliant on finely tuned table structures (including the design of the underlying data), as well as the proper configuration of the infrastructure. Getting the most out of the product depends on users and companies knowing what the tool is most optimized for, as well as optimally building their applications and queries to take advantage of the many product features.
Summary
Global data generation has quickly increased from two zettabytes in 2010 to 120 zettabytes in 2023, driving an evolution in enterprise data management systems. Traditional data warehouses faced limitations in scalability and real-time analytics, leading to the rise of cloud warehouses like Snowflake and Databricks. However, these solutions still struggled with real-time requirements, prompting the development of ClickHouse, a real-time processing warehouse optimized for interactive data visualizations and analytics.
Founded in 2021 by Alexey Milovidov, Yuri Izrailevsky, and Aaron Katz, ClickHouse initially served Yandex before being open-sourced in 2016, gaining traction among developers. With notable customers like IBM and Microsoft, ClickHouse operates on a usage-based pricing model and raised $300 million in funding by April 2024, positioning itself in a market projected to grow to $154.6 billion by 2030. Opportunities lie in its role as a foundation for AI/ML workflows, expansion into cloud-native architectures, and integration with complementary technologies, while risks include competition and the need for proper tuning and best practices.


