
An Internet Built for AI
For nearly forty years, openness has been a fundamental characteristic of the internet. The open web was founded on principles of openness, decentralization, universality, non-discrimination, collaborative development, consensus, and accessibility. This openness plays a crucial role in civic engagement and has enabled countless communities, creators, and knowledge-sharing platforms to flourish.
This landscape is changing rapidly due to automated traffic. Nearly 50% of all internet traffic in 2025 is generated by bots, much of it from automated scrapers and crawlers that will soon outpace human traffic entirely. The implications of this shift represent a restructuring of the way information flows, how value is created, and who captures that value in our digital economy.
The Invisible Middleman
The global web scraping market will hit $1.3 billion by 2025, with AI as a major driver. To understand this shift, it's worth examining how scraping has evolved from its origins.
JumpStation, one of the first "crawler-based" search engines, launched in December 1993 to organize the increasing number of internet webpages. Other early uses of scraping bots included gauging the size of the internet and identifying broken or dead links on servers. Crawlers were largely undisruptive and could even be beneficial, bringing people to websites from search engines like Google or Bing in exchange for their data. Websites then and now use machine-readable files, called robots.txt files, to specify what content they want crawlers to leave alone.
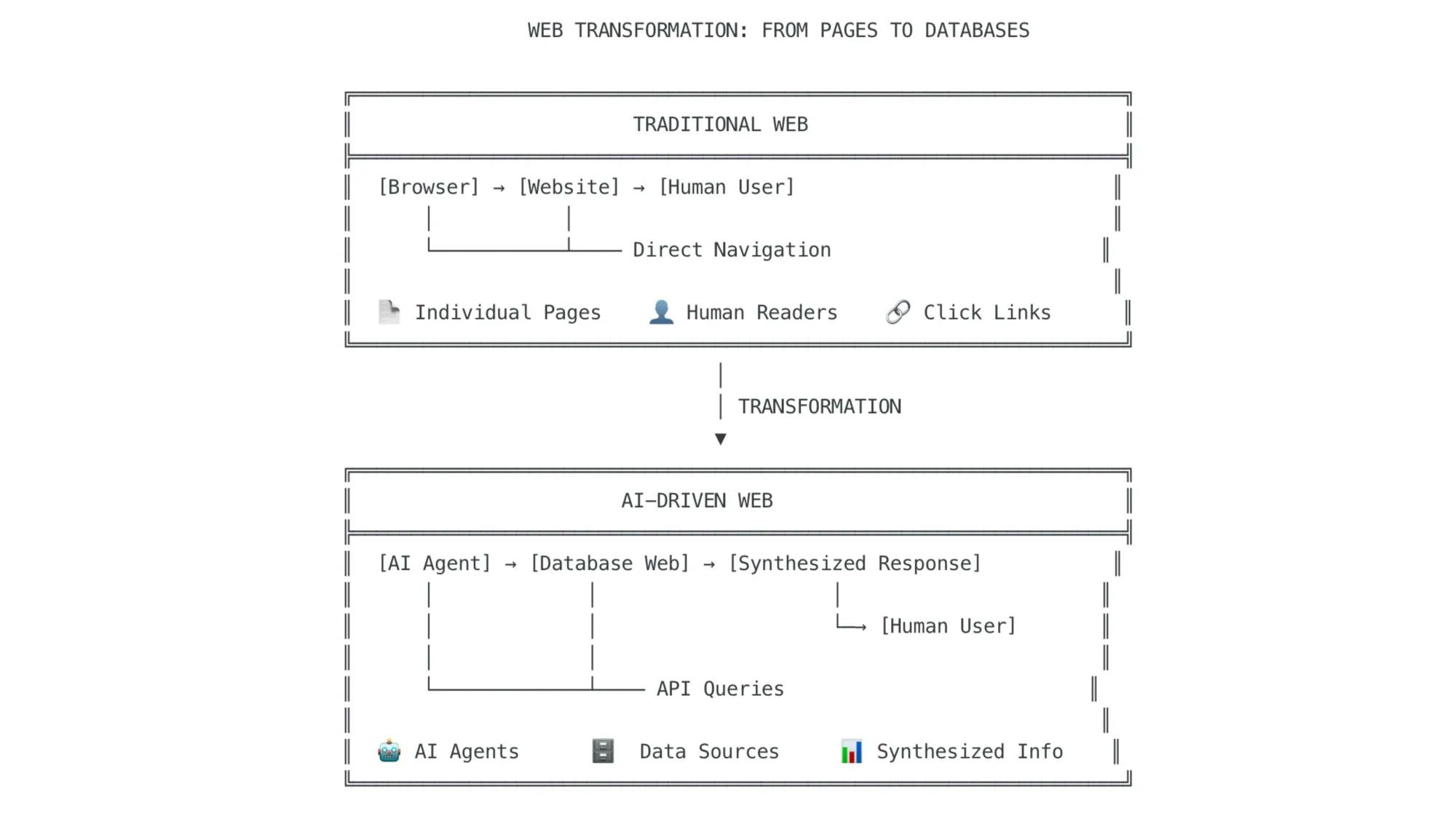
Web scraping has historically relied on three methods: HTML scraping, crawler-based scraping, and API access. These formed the backbone of early search engines and data aggregators. With the new wave of AI, scraping has moved from indexing to ingestion and generating new output. AI tools like Perplexity and ChatGPT can instantly summarize the internet and give users direct answers, creating what amounts to an invisible middleman effect. ChatGPT's prominence pushed internet scraping into the spotlight and exposed AI models' data scraping practices to widespread scrutiny.
Source: PPC Land
Modern AI scrapers can extract, clean, and organize data from almost any website automatically, even adapting to changes in site structure or layout. AI-powered scraping tools in 2025 are so advanced that they can mimic human browsing, bypass anti-bot systems, and adapt to changes in website structure, making data extraction from almost any public site routine. These tools use machine learning to understand complex, dynamic content, including JavaScript-heavy pages, and employ techniques like human behavior emulation and dynamic proxy rotation to avoid detection and maintain reliable access.
Many of the most popular models, including OpenAI’s GPT 3.5, Google’s Gemini 2.0 Flash, and Meta’s Llama 2, use web-crawled data to train their artificial intelligence systems, with over half of the training data coming from Common Crawl. Common Crawl offers users "a copy of the Internet," serving as one of the largest and most widely used repositories of scraped data. Common Crawl spans 250 billion web pages over 18 years, encompassing everything from blogs and Wikipedia to news articles and code repositories. Over half of Llama 2’s training data came from Common Crawl, illustrating just how central scraped web content has become to the AI ecosystem.
The Death of the Link Economy
Traditionally, the web’s “link economy” meant that people visited websites, generating ad revenue for bloggers, forums, and niche media. Now, a growing share of users no longer want to browse links — they expect AI to distill the web into instant answers, reinforcing a feedback loop that deprioritizes original exploration. In the old model, attention flowed to the source; in the new model, content flows to the platform, competing directly with its sources of data. This shift is so significant that publishers and website owners are seeing dramatic drops in web traffic, as users increasingly get instant answers from AI systems rather than visiting sources.
The launch of Google's "AI Overviews" and "AI Mode" in 2025 was followed by immediate, dramatic declines in referral traffic to news outlets, with some publishers reporting traffic drops of 50% or more within weeks. Google's AI Overviews now appear above traditional links, significantly reducing click-throughs to publisher sites.
Major publishers are experiencing severe impacts:
New York Times: Organic search traffic dropped to 36.5% of total visits by April 2025, 44% less than three years earlier.
Washington Post: Search audience shrank by nearly half in 2025.
Nicholas Thompson, The Atlantic CEO, captured the broader trend: "Expect traffic from Google to diminish to nearly zero over time" as Google shifts from a search engine to an "answer engine."
By using publicly available data to train their LLMs, generative AI companies incur the direct advantages of scraping publicly available data. Conversely, the public bears the direct disadvantages of these companies' scraping of publicly available data. While major publishers can block or license to AI companies, independent creators and niche forums lack the resources to do so, making their content more vulnerable to scraping and uncredited summarization.
AI crawlers and scrapers contributed to a record 16% of all known-bot impressions in 2024, inflating traffic metrics and making it harder to measure genuine engagement. If users no longer visit sites, ad impressions fall, starving the revenue that funds free content, from niche sites to major outlets. As AI tools summarize and surface information directly, independent creators lose referral traffic, visibility, and potential ad or affiliate revenue, undermining the incentive to produce original work.
The collapse extends to knowledge-sharing communities. On Stack Overflow, the sum of questions and answers posted in April 2025 was down over 64% from April 2024, and more than 90% from April 2020, according to Stack Overflow's official data explorer. Developers are moving to Discord servers, niche forums, and even TikTok for code help, further fragmenting the traditional open web community.
Beyond the numbers, there's a temporal dimension to this crisis. Traditional journalism and research operate on human timescales. Processes like investigation, verification, and publication take days or weeks, whereas AI systems can process and synthesize information in seconds. While these systems still struggle with achieving the context and real-time accuracy that human journalists provide, they nevertheless create an asymmetric competition where human-generated content struggles to maintain relevance in fast-moving information cycles.
This speed differential particularly affects breaking news and technical documentation, where AI can provide instant summaries that reduce demand for the original reporting or detailed guides that took significant effort to produce.
Retreat Behind Paywalls and AI-Proofing
Websites are now fighting back for fear that AI crawlers will help displace them. But there's a problem: This pushback is also threatening the transparency and open borders of the web that allow non-AI applications to flourish.
Companies on the internet previously made data publicly available and generated revenue through ads. However, the current business model is shifting toward safeguarding data on private websites, making it accessible only to registered or paying users. More than two-thirds of leading newspapers across the EU and the US now operate some kind of online paywall, a figure that has steadily increased since 2017. The New York Times alone boasts 10.8 million digital-only subscribers, with digital subscription revenue nearing $1 billion annually.
The rise of private APIs follows similar logic. While private APIs enable businesses to protect intellectual property and monetize data, they also limit experimentation, interoperability, and the free flow of information that defined the early web. Since mid-2023, websites have erected crawler restrictions on over 25% of the highest-quality data.
Some publishers have signed licensing deals; others are pursuing legal action or blocking bots. Major licensing deals include Reddit's $60 million per year agreement with Google (2024), giving Google access to Reddit's data for AI training, and the Associated Press's multi-year licensing deal with OpenAI (2023). The New York Times secured a three-year, $100 million deal with Google for a content and distribution partnership, but explicitly forbids scraping for AI training by other companies.
While major AI developers like OpenAI and Anthropic publicly commit to respecting website restrictions, reports suggest inconsistent compliance. Website operators have documented cases of aggressive crawling that overwhelms servers or ignores or circumvents robots.txt directives, despite their public statements. This has spawned a new industry of protective services; companies like TollBit and ScalePost offer monetization tools for AI data usage, while infrastructure providers like Cloudflare have developed bot detection and traffic management systems to help websites control automated access.
Legal cases are mounting. The New York Times is pursuing an ongoing lawsuit against OpenAI and Microsoft for copyright infringement over the use of its articles in AI training datasets. Over 88% of top US news outlets now block AI data collection bots from OpenAI and others.
A Self-Cannibalizing Knowledge System
This retreat behind paywalls creates a spiral into knowledge inequality. As premium content becomes increasingly gated, AI systems trained on freely available data may become less accurate or comprehensive over time, particularly for specialized domains. Meanwhile, those who can afford multiple subscriptions gain access to higher-quality information, while others rely on potentially degraded AI summaries.
Furthermore, as AI-generated content floods the web, it creates a feedback loop where new models train on synthetic data from previous AI systems. This risks what researchers call "model collapse", which is a degraded output quality when training data becomes increasingly artificial rather than human-generated. In image generation, this manifests as increasing blurriness and artifact accumulation. In text, it appears as semantic drift and reduced diversity in expression.

Source: Nature
More critically for the web's future, as AI systems produce content faster than humans can create it, the internet risks becoming primarily a training ground for machines rather than a space for human creativity and discovery.
What Kind of Internet Are We Building?
We are undergoing a transition from an open knowledge commons to a privatized, AI-intermediated information ecosystem. Bundled content and exclusive partnerships are becoming more common. The EU and UK are considering opt-out copyright regimes for AI training, requiring explicit permission for scraping; California is advancing legislation to mandate transparency of materials used in AI training; and the US is increasing debate over new copyright protections for digital content.
The European Union's AI Act includes provisions for transparency in training data usage, while California's proposed legislation would require AI companies to disclose their data sources. However, enforcement remains challenging, particularly for international operators or companies that don't primarily operate in these jurisdictions. More fundamentally, regulation tends to lag technological change. By the time comprehensive AI training data regulations are implemented and enforced, the current generation of models will already be trained, and new technical approaches may circumvent existing rules. Although lawmakers acknowledge the need for regulation, they fear restrictive regulations may lead the United States to lose its lead in the AI "arms race." Trying to force the web back to its early form won't work—that era was shaped by slower tools, different incentives, and a web less crowded by algorithms.
Despite the challenges, new models for content creation and distribution are emerging. Substack and similar newsletter platforms provide direct creator-audience relationships that bypass traditional advertising and search traffic dependencies. Patreon and OnlyFans demonstrate sustainable creator economies based on direct payment rather than attention arbitrage. Some publishers, like the Financial Times, are experimenting with creating content specifically designed to be discovered and cited by AI systems, with business models based on attribution and link-backs.
An alternative future involves collaboration rather than competition between AI systems and human creators. Tools like GitHub Copilot demonstrate how AI can augment rather than replace human creativity. Similar approaches in journalism and content creation could preserve the web's collaborative spirit while leveraging AI's capabilities. Some platforms are experimenting with "human-in-the-loop" AI systems that provide initial content generation but require human editing and verification before publication. This hybrid approach could maintain content quality while reducing production costs.
Ultimately, the open web doesn't ‘die’, rather it becomes a training ground for AI companies, increasingly synthetic and AI-generated, less economically viable for human creators, and accessible only through AI intermediaries for most users. The open web is becoming a raw material source, driving a shift away from foundational values of openness and accessibility and toward closed systems, paywalls, and machine-to-machine content loops. The speed and scale of this shift mean the next few years will determine whether the internet preserves its role as an open platform for independent creators, diverse voices, and knowledge-sharing or becomes primarily infrastructure for machine learning.





