
Thesis
AI is transforming business operations across industries, with AI adoption surging to 72% of companies who responded to a May 2024 McKinsey survey, up from around 50% where it had been in the previous six years. As companies race to embed AI into product experiences and customer interactions, the demand for personalized, real-time, and context-aware AI applications is expanding. However, bottlenecks remain. As of 2022, 90% of data science projects failed to reach production, and even successful ML projects took an average of seven months to deploy.
The root of this problem lies in the data layer. Data scientists often work independently, processing raw data and creating features on local systems. When models are ready for deployment, they hand off projects to data engineers and other teams, resulting in prolonged iteration cycles and potential organizational friction. This challenge is particularly acute for "production ML" applications like Uber’s dynamic pricing or TikTok's recommendations that require the latest, most up-to-date features.
Tecton addresses such bottlenecks. The company provides a feature platform for machine learning with a unified system for defining, managing, and serving features. The platform empowers data scientists to own model deployment and integration, much like how DevOps practices revolutionized software engineering two decades ago, enabling 208 times more frequent and 106 times faster deployments. Tecton's approach goes beyond traditional feature stores, incorporating data pipelines and infrastructure typically built by data engineers. It acts as a central repository for business signals, enabling teams to discover, re-use, and govern features. By integrating with existing data infrastructure like Snowflake, Databricks, and AWS, Tecton aims to provide a best-of-breed solution rather than requiring migration to an end-to-end ML platform.
As Tecton CEO Mike Del Balso stated in a June 2023 interview with Contrary Research:
“Consumer experiences across every product, every piece of software that you interact with is going to be personalized, updated in real-time. It's going to be interactive and responsive. Everything from when you go to the doctor, to signing into your bank, to making a purchase online. And that's the world we think we're going to. And we think the kind of infrastructure that we're building is a key stepping stone to make it easy for people to get there.”
Founding Story

Source: Tecton
Tecton was founded in 2018 by co-founders Mike Del Balso (CEO) and Kevin Stumpf (CTO).
Tecton's origins trace back to Uber, where Del Balso and Stumpf developed the Michelangelo ML platform. Their experience tackling ML challenges at scale across various operational use cases laid the foundation for Tecton. Del Balso brought ML systems experience from his time as a Product Manager at Google, where he worked on ad auction ML systems. Stumpf contributed perspective from founding Dispatcher, an "Uber for long-haul trucking" startup, before joining Uber Freight and its ML platform team.
In 2015, Del Balso and Stumpf were tasked with developing an ML platform at Uber. As Del Balso recounted in a June 2023 interview with Contrary Research:
“The initial mission at Uber was democratized machine learning. There were no good ML platforms on the market. ML infrastructure was super nascent at that time.”
Their work exposed them to the unique challenges of "production ML" – high-stakes, user-facing ML applications requiring production-level SLAs, fresh data, and robust infrastructure. They observed a recurring pattern: data science teams built promising offline prototypes, but it took months of back-and-forth with engineering to fully operationalize and launch models in production.
This led to the development of Michelangelo, Uber's end-to-end ML platform released in 2017. However, the Tecton founders gained a key insight: the need for modularization. As Del Balso explained:
"What we learned at Uber Michelangelo was we need to modularize this thing. If you're the Uber Eats team or the self-driving car team, maybe you have your own special way to serve your models... So having these components be very modular and effectively breaking up the ML platform into different subcomponents that are plug-and-play was a pretty useful insight for us."
Recognizing that feature engineering and management were consistently the most time-consuming and challenging aspects of ML development, Del Balso, and Stumpf saw an opportunity to democratize production ML by focusing on the data layer. They founded Tecton in 2019 with the mission of simplifying the development and deployment of production-grade ML applications.
Product
Tecton's product offerings fall into three main categories: Predictive ML, Generative AI, and AI Data Platform. Predictive ML focuses on real-time machine learning predictions. Generative AI supports the creation of AI-generated outputs. The AI Data Platform facilitates feature engineering and management for deploying machine learning models efficiently.
Predictive ML
Feature Store
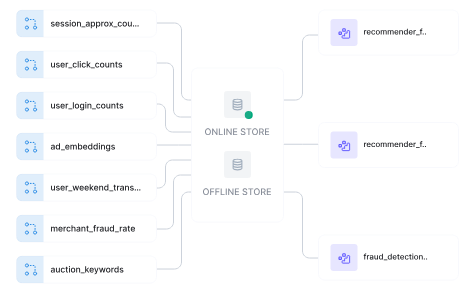
Source: Tecton
At the core of Tecton's platform is its feature store, which serves as a centralized repository for storing, managing, and serving features. The store supports both online and offline environments, which is crucial for maintaining consistency between model training and inference.
The online store is optimized for low-latency serving, capable of handling over 100K queries per second with median latencies of 5 milliseconds. This performance is achieved through advanced caching mechanisms and optimized data structures. The offline store leverages scalable data warehouses or data lakes like Snowflake or Amazon S3, which are capable of storing petabytes of historical feature data.
A key strength of Tecton's Feature Store is its seamless integration between online and offline stores, which addresses the critical issue of training-serving skew. This consistency assurance is particularly relevant for organizations deploying ML models in production environments where real-time decision-making is essential.
Feature Engineering
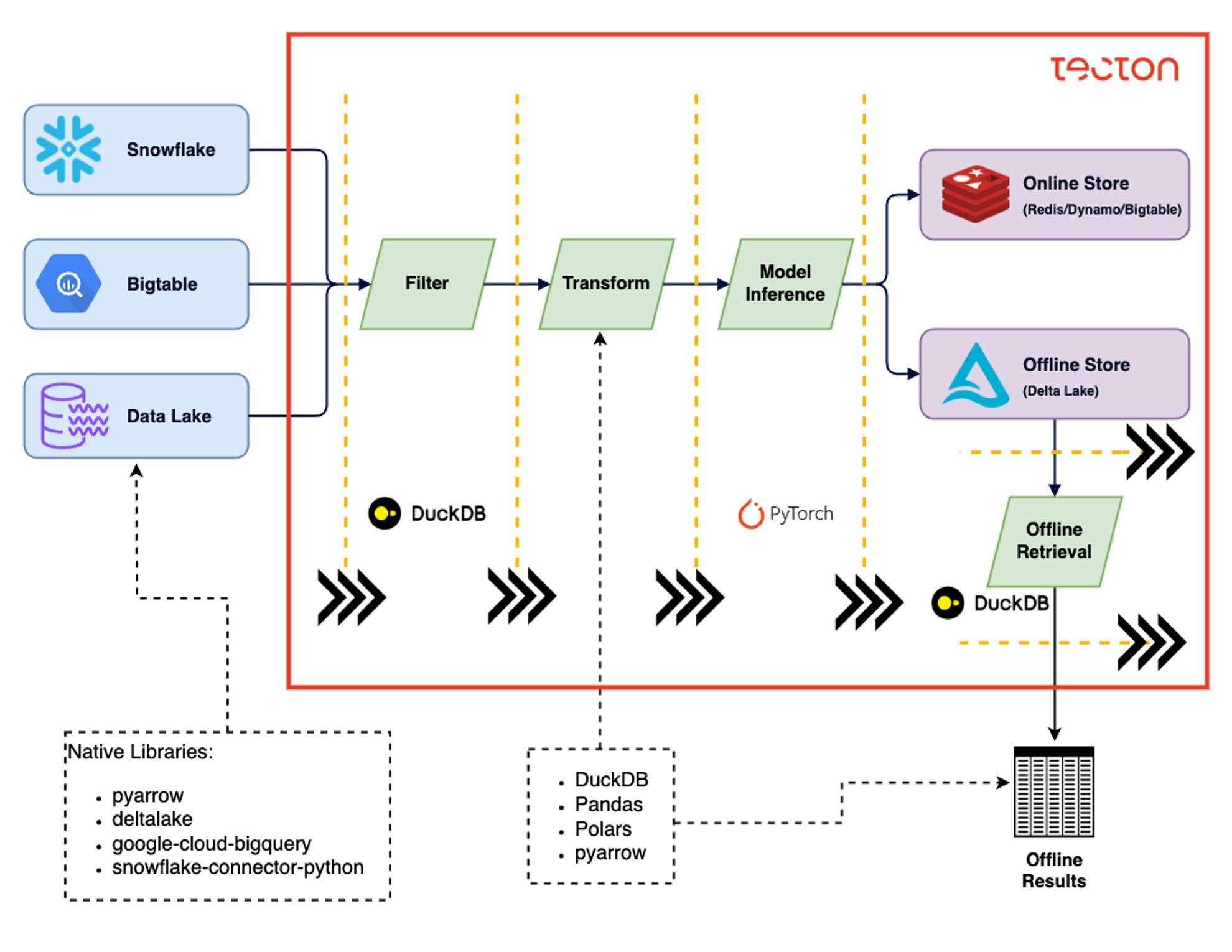
Tecton's feature engineering framework is built on a Python-based declarative system that allows users to define features as code. This approach enables version control, collaborative development, and easy integration with CI/CD pipelines. The framework supports a wide range of data sources, including (1) batch data from warehouses like Snowflake, (2) streaming data from platforms like Kafka, and (3) real-time data from application APIs.
A notable innovation is Tecton's ability to abstract away the complexities of data processing engines. Whether using Spark for batch processing, Flink for streaming, or Tecton's own Rift engine for real-time computation, the feature definitions remain consistent. This abstraction layer greatly reduces the engineering effort required to deploy ML features into production.
The collaborative development capabilities of the framework are also worth highlighting. By treating features as code, Tecton enables team-based feature development with full version control. This approach not only improves the quality and reliability of features but also facilitates knowledge sharing and reuse across an organization.
Time-Window Aggregations
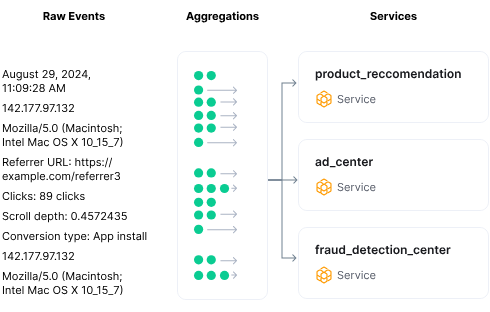
Source: Tecton
Tecton's time-window aggregation engine addresses the complex challenge of computing time-based aggregations efficiently in both batch and streaming contexts. The engine employs incremental aggregation to minimize computation costs, maintaining partial aggregates and updating them incrementally rather than recalculating entire aggregations from scratch. This approach is particularly effective for sliding window aggregations over large datasets or real-time streams, a common requirement in many ML applications
The engine's architecture is built on a distributed stream processing framework, allowing it to handle high-velocity data streams. It uses a combination of in-memory state management and periodic checkpointing to disk to balance performance and fault tolerance. For each aggregation, the engine maintains a state object that includes the current aggregate value and any necessary metadata, such as the number of data points included in the aggregation.
The system offers flexibility in defining time windows, ranging from fixed periods (e.g., "the last 7 days") to more complex configurations like offset windows and lifetime windows. To handle late-arriving data, a common challenge in distributed systems, the engine implements a watermarking mechanism. This allows it to determine when all data for a particular time window has likely arrived, triggering the finalization of aggregates. However, the system remains flexible, able to update "finalized" aggregates if extremely late data arrives, ensuring eventual consistency.
The engine also optimizes for different types of aggregations. For distributive aggregations like sum or count, it can simply combine partial aggregates. For holistic aggregations like the median, which cannot be computed from partial results, it uses approximate algorithms that provide accurate results with bounded error while maintaining efficiency.
Training Data Generation
Tecton's training data generation system is designed to solve the challenging problem of creating accurate, point-in-time correct datasets for model training. It leverages the platform's unified feature definitions to ensure consistency between training and serving environments, addressing the critical issue of training-serving skew.
The system can generate training datasets at a petabyte scale, supporting up to 1K+ columns across multiple dimensions. This capability is crucial for training large, complex models that require vast amounts of historical data. Tecton's architecture allows for distributed dataset generation, enabling rapid creation of training data even for massive datasets.
A key strength of Tecton's training data generation system is its integration with the platform's unified feature definitions. This ensures that the features used in training datasets are identical to those used in production, eliminating the risk of training-serving skew. For organizations, this translates to more reliable models and a significant reduction in the time and resources typically required to debug and optimize models for production use. The system also supports distributed dataset generation.
Tecton’s approach promotes feature reuse across different use cases within an organization, accelerating model development and reducing redundant work. The system also preserves every generated dataset, facilitating reproducibility and compliance with data governance requirements.
Real-Time Serving
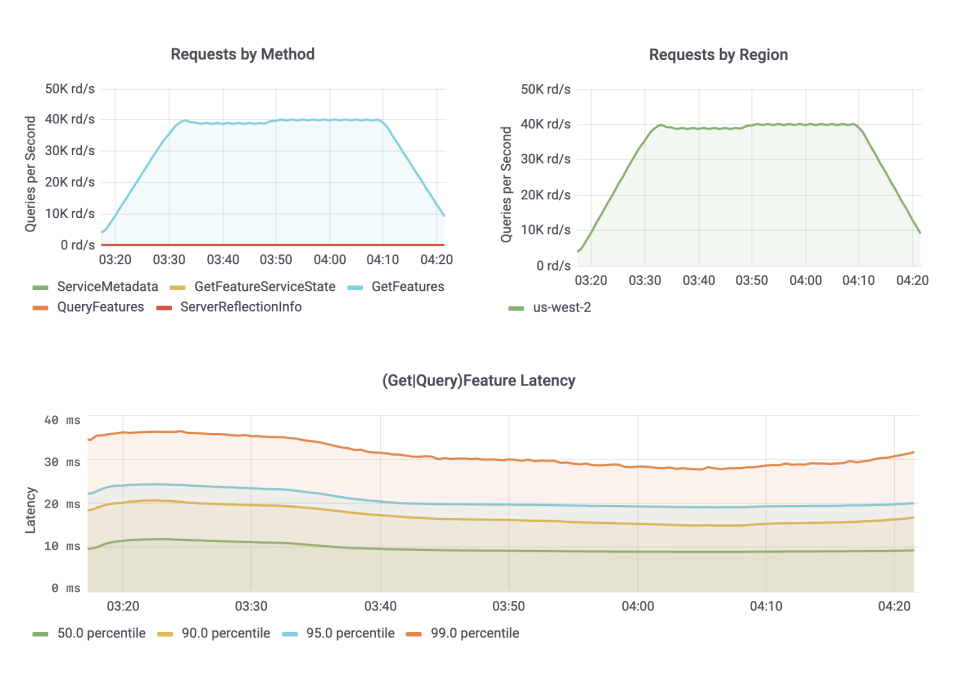
Source: Tecton
Tecton's real-time serving infrastructure is designed to meet extreme performance requirements, capable of serving feature vectors at over 100K queries per second with median latencies under 5 milliseconds. This performance is achieved through a combination of optimized data structures, intelligent caching mechanisms, and a distributed serving architecture. The system utilizes tailored data structures for rapid access and retrieval, complemented by strategic caching of frequently accessed data to reduce latency and backend pressure.
The serving architecture is inherently distributed, allowing for horizontal scaling to meet growing demand. Load balancing algorithms work in conjunction with this distributed design to evenly distribute incoming requests, maintaining consistent performance under heavy load. This architecture enables efficient handling of concurrent requests across multiple nodes, ensuring low latencies system-wide.
A key innovation in Tecton's infrastructure is its ability to seamlessly combine batch, streaming, and real-time computed features in a single serving request. This is accomplished through a sophisticated orchestration layer that coordinates feature retrieval and computation across different data sources and processing systems. The layer ensures all necessary features are gathered or computed within strict latency requirements, regardless of their origin or computation method. This unified approach simplifies the development of ML applications requiring both historical context and up-to-the-second data.
Generative AI
Embeddings Generation
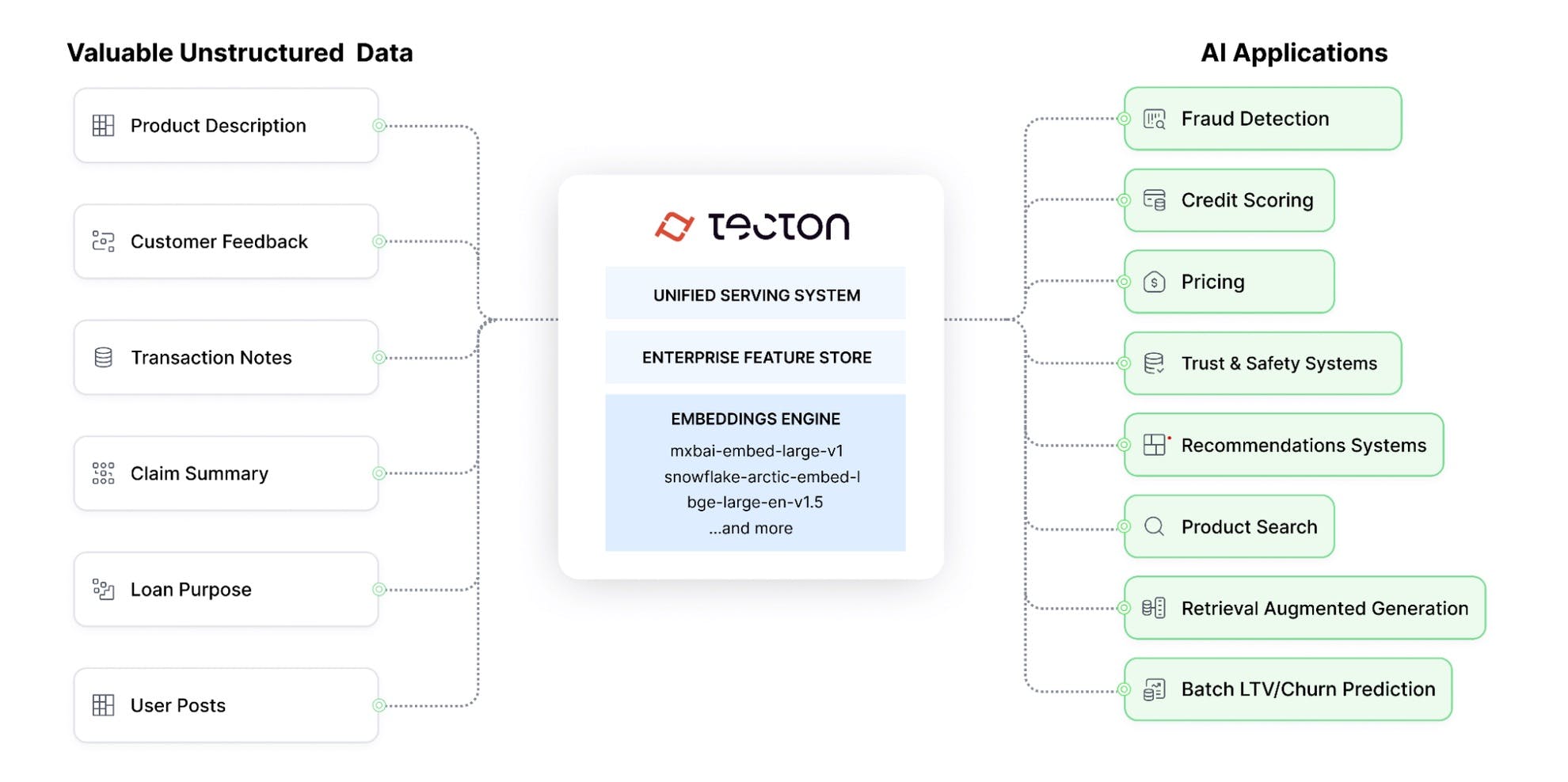
Source: Tecton
Tecton's embeddings generation service is designed for high-throughput, scalable embedding generation. This is achieved through a combination of GPU acceleration, efficient batching techniques, and several optimizations. These include:
Distributed Inference: Tecton's embedding engine supports single and multi-GPU instances, with the ability to distribute backfills across many concurrent jobs. This enables scaling to thousands of GPUs, with only up-front coordination and no jobs waiting for work.
Larger-than-Memory Datasets: The engine supports working with larger-than-memory datasets by implementing an output queue that writes to disk using Arrow's IPC format. This allows for efficient processing of large-scale data without memory constraints.
Input Length Sorting: To optimize batch processing, the engine sorts input strings by length within record batches. This reduces extra padding and improves inference time efficiency.
Dynamic Token Batching: The engine implements a sophisticated dynamic batching system that adapts to different sequence lengths and GPU combinations. It automatically selects an optimal token budget that leverages a sufficiently large portion of the GPU, maximizing throughput across various input sizes.
Automated Token Budget Selection: The system automatically determines the ideal token budget for each model and GPU combination. This process runs in seconds as part of the model inference stage, eliminating the need for manual tuning when adding new models.
CUDA OOM Batch Splitting: To handle occasional CUDA out-of-memory errors, the engine implements an automatic batch-splitting mechanism. This significantly improves job reliability by seamlessly retrying just the problematic micro-batch rather than failing the entire job.
One of the key technical innovations in Tecton's embedding service is its ability to incrementally update embedding as source data changes. This feature ensures that vector representations always reflect the latest information without requiring full recomputation of the entire embedding space. This approach significantly reduces computational overhead and ensures that AI applications always have access to the most up-to-date representations of their data.
Source: Tecton
The flexibility of the embedding service is another notable feature. By supporting a variety of embedding models, including custom PyTorch implementations, Tecton allows organizations to use the most appropriate embedding technique for their specific use case. This flexibility can be crucial in domains where specialized embedding techniques can provide a competitive edge.
In terms of performance, Tecton's Embeddings Engine has demonstrated impressive results. In bulk backfill tests using the all-MiniLM-L6-v2 model on g6.2xlarge instances (NVIDIA L4 GPU), the engine achieved an average of 100K embeddings per second across distributed inference jobs.
Prompt Engineering
Source: Tecton
Tecton's prompt engineering tools bring software engineering best practices to prompt development. Prompts are treated as code, with version control, CI/CD integration, and automated testing capabilities.

Source: Tecton
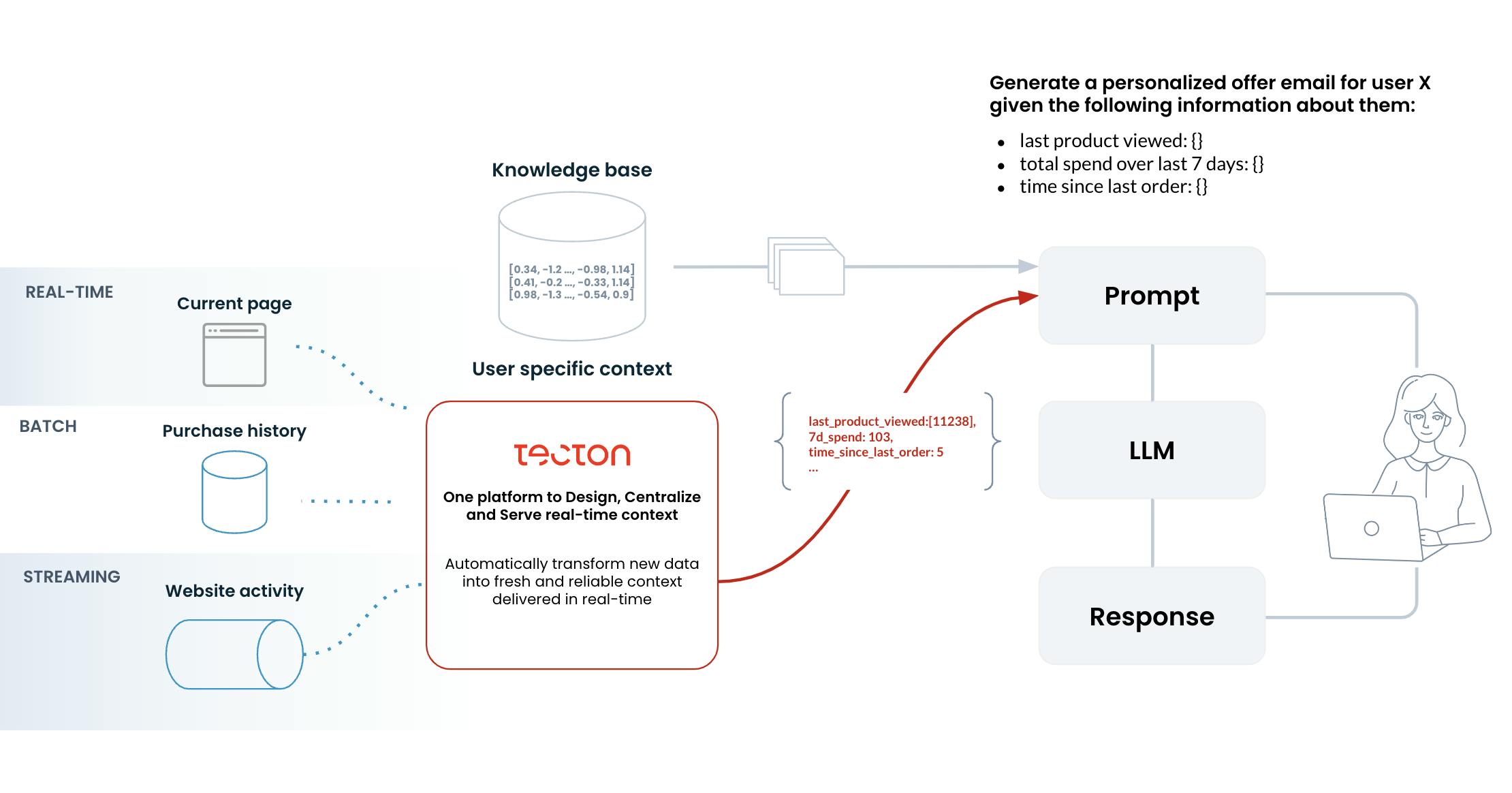
The system also has support for dynamic prompt enrichment. This capability allows prompts to be augmented with contextual data at runtime, achieved through a flexible templating system that can incorporate feature values, user context, and other relevant information. This dynamic enrichment enables the creation of more personalized and context-aware responses from LLMs, potentially improving the quality and relevance of AI-generated content.
Fine-Tuning Datasets
Source: Tecton
Tecton's fine-tuning dataset generation system leverages the feature store to create rich, contextually relevant datasets for model fine-tuning. This is not commonly found in standalone dataset generation tools. It supports advanced techniques like automatic data balancing and deduplication, integration of historical feature values for temporal consistency, and prompt completion pair generation based on existing data.
AI Data Platform
Declarative Framework
Source: Tecton
Tecton's declarative framework allows users to define all aspects of their AI data pipelines using a consistent, Python-based syntax. This abstraction layer allows users to specify all aspects of their feature engineering and serving processes in a unified manner.
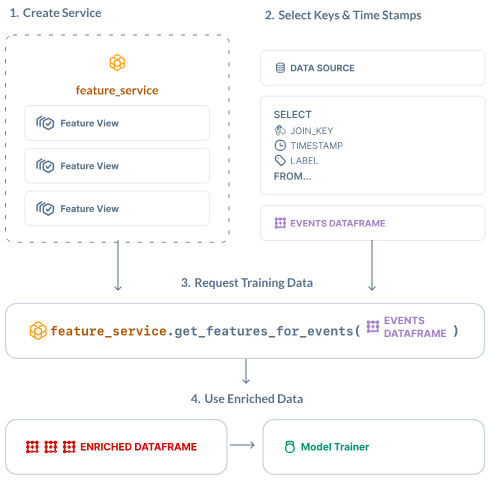
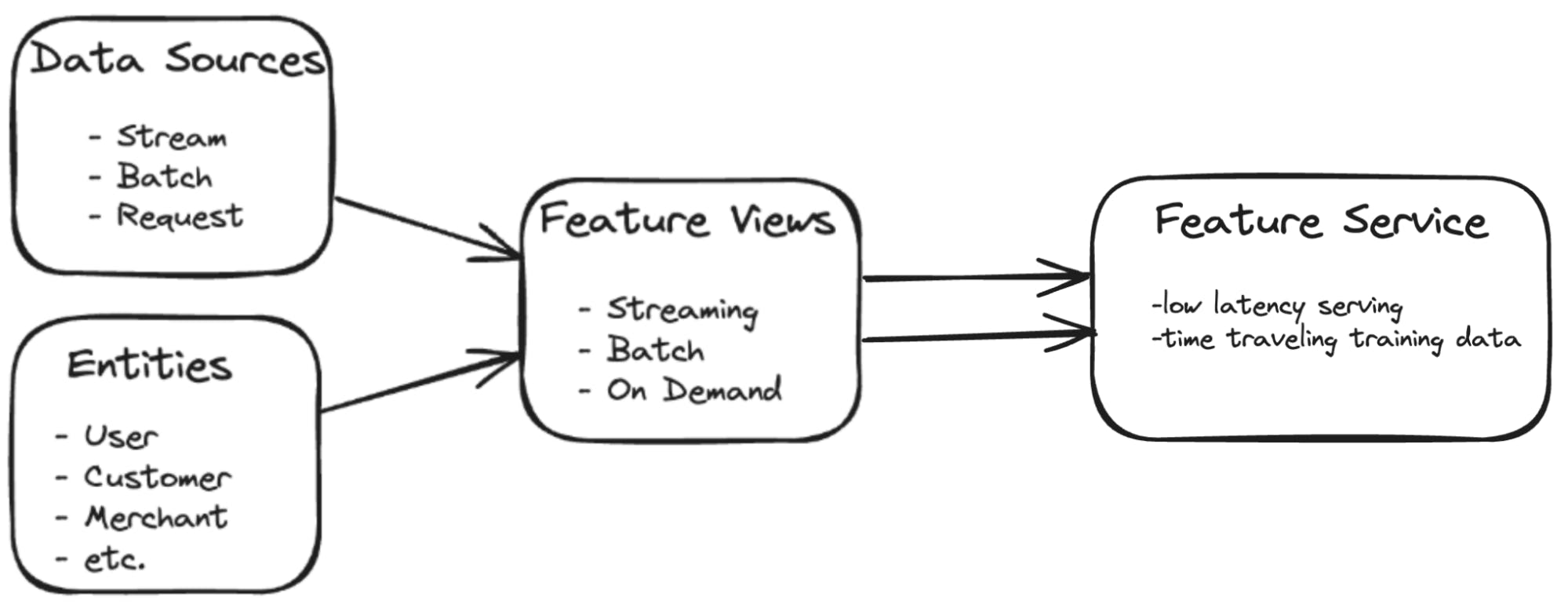
This framework enables the definition of feature views, which contain the complete logic for transforming raw data into ML-ready features. These feature views can be composed of multiple components, including data source configurations, transformation logic using Python and SQL, entity definitions, and aggregation specifications. The framework supports feature dependencies, allowing users to build complex feature hierarchies where derived features can depend on other feature views.
The declarative nature of the framework extends beyond just feature definitions. Users can specify data freshness requirements, service level agreements (SLAs), and backfill parameters directly within their pipeline definitions. This allows for fine-grained control over how features are computed and served, enabling teams to balance between data recency, computational resources, and latency requirements. Additionally, the framework incorporates robust versioning capabilities, ensuring that changes to feature definitions can be tracked, audited, and rolled back if necessary.
Unified Compute
The platform's unified compute layer abstracts away the complexities of distributed data processing. It supports various execution engines and automatically optimizes resource allocation based on workload characteristics and user-defined SLAs. This level of automation can significantly reduce the operational overhead associated with managing complex AI data pipelines.
Retrieval System
Tecton's retrieval system is built on a distributed architecture optimized for low-latency, high-throughput serving. It incorporates advanced caching mechanisms, including multi-level caching and predictive pre-fetching based on usage patterns. The system supports complex query patterns, including multi-key lookups and range queries, crucial for serving feature vectors in production ML applications.
Context Registry

Source: Tecton
The context registry provides a centralized hub for managing AI assets across an organization. This system goes beyond basic cataloging to offer a suite of advanced features that enhance collaboration, governance, and efficiency in AI development. The registry provides unified discoverability for a wide range of AI artifacts, including features, prompts, embeddings, and tools. Its search and exploration capabilities allow teams to quickly find and understand available AI context, significantly reducing redundant work and accelerating project timelines. The system supports detailed metadata, versioning, and documentation for each asset, ensuring teams can make informed decisions about which contexts to use.
Governance is a core strength of the context registry. It implements fine-grained access controls, allowing organizations to manage permissions at a granular level. This ensures that sensitive AI assets are only accessible to authorized personnel. The system also provides automated lineage tracking, creating a clear audit trail of how AI contexts are created, modified, and used across different projects and models. This lineage information is crucial for compliance, debugging, and understanding the impact of changes. This centralized approach to AI asset management can improve collaboration, reduce duplication of effort, and enhance the overall governance of AI initiatives within an organization.
Market
Customer
Tecton targets companies with relatively mature ML teams that are looking to build and deploy production-grade ML applications, particularly those requiring real-time capabilities. As Tecton CEO Mike Del Balso noted in a June 2023 interview with Contrary Research:
"Generally it's people who have needs for building production ML and they have fast data and they're completely on the cloud. So if you're on-prem, we just don't do that." This focus on cloud-native, real-time ML applications distinguishes Tecton's target market from companies still in the early stages of ML adoption or those primarily focused on batch processing.”
The ideal Tecton customer is typically dealing with high-value, real-time ML use cases such as fraud detection, recommendation systems, and dynamic pricing. These applications often require orchestration of batch, streaming, and real-time data sources, presenting complex technical challenges that Tecton's platform is designed to address. As Del Balso explained:
“If this is not an important use case for you, it still takes a lot of work to put these ML systems in production. And if it's not important it's probably not going to be successful. So we spend time with people for whom machine learning-driven product experiences are a priority.”
This value proposition is particularly compelling for customers who have struggled with the challenges of transitioning machine learning projects from data scientists to data engineers, including the time and effort required to re-implement data pipelines for production. According to Stumpf, many teams without a feature platform require two data engineers to support a single data scientist, whereas a feature platform can reverse that ratio. It also appeals to organizations deploying operational machine-learning applications that must meet strict SLAs, achieve scalability, and ensure reliability in production. Additionally, it benefits teams seeking standardized feature definitions and the ability to reuse features across multiple models.
While many large tech companies have built in-house feature stores or ML platforms, Tecton positions itself as a solution for organizations that can't afford to build and maintain such systems internally. As Del Balso pointed out:
“Facebook or Google literally have hundreds of people working on the data infrastructure for the real-time ML application. We're basically building that team for everybody. Your favorite insurance company may not be able to hire hundreds of Google engineers for this, but they'll be able to work with Tecton and have those same capabilities.”
Tecton's sales process typically involves multi-month enterprise sales cycles, targeting engineering or data science leaders. The adoption process often requires significant stakeholder buy-in and careful planning. For instance, at HelloFresh, the data science team spent several months gathering requirements and creating organizational buy-in before incrementally rolling out Tecton to an initial set of eight teams over a six-month period.

Source: Tecton
Market Size
The market for MLOps, including feature platforms like Tecton, is nascent and highly fragmented. As of 2022, this market was estimated at $720 million in size, which is projected to grow to $13 billion by 2030. The landscape is diverse, with Gartner tracking over 300 MLOps companies in 2022. This fragmentation is partly due to the complex and multifaceted nature of MLOps, encompassing various aspects of the ML lifecycle from data preparation to model deployment and monitoring.
This complexity has led to a proliferation of specialized tools and solutions. ML researcher Chip Huyen noted 284 MLOps tools in 2020, of which 180 were startups. Among the Forbes AI 50 in 2019, seven companies focused on tooling, reflecting the increasing emphasis on data-centric AI and the development of tools for data labeling, management, and related tasks. Of the MLOps startups that raised money in 2020, 30% were in data pipelines. Despite the abundance of specialized tools, enterprises often adopt a hybrid strategy, combining cloud provider offerings with specific MLOps solutions. As one VP at Gartner Research put it:
“Most enterprises create a hybrid strategy. That is, they use Amazon, Azure or Google as a backplane, depending on their enterprise center of gravity, and plug in components where capabilities might be missing or where they need hyper-customization or specialization.”
Competition
Tecton faces competition from various sources in the MLOps and feature platform market, with the landscape broadly divided into in-house solutions, cloud and data platform providers, and specialized MLOps startups.
In-house solutions represent Tecton's most significant competition. Feature stores have become an industry standard component for many large tech companies, with established companies like LinkedIn, Airbnb, Instacart, DoorDash, Snap, Stripe, Meta, Spotify, Uber, Lyft, and X developing their own feature stores or ML platforms. The Tecton-supported open-source feature store Feast is used by companies like Shopify, Postmates, and Robinhood, often serving as a starting point for organizations beginning their ML infrastructure journey.
However, building and maintaining an internal feature store is costly and often not a core competency for many organizations. Tecton CEO Mike Del Balso highlighted this challenge, stating:
"A top fintech company is our customer, and they have four different versions of this system that they've tried to build at different points in time over the past ten years. And they have this graveyard of internal things that support something, but they hate it, and it's a big maintenance burden."
Cloud providers and data platform companies represent another competitive force. Amazon announced the SageMaker feature store in 2020, Google introduced a feature store as part of its ML platform Vertex AI in 2021, and Databricks launched its Feature Store in 2022. While these solutions may not yet offer all the capabilities of Tecton's platform, they benefit from tight integration with their providers' broader cloud ecosystems and are rapidly evolving.
These solutions are particularly focused on enhancing their streaming and real-time data capabilities. For instance, Snowflake has introduced streaming tools like Snowpipe and Materialized Views. Databricks CEO Ali Ghodsi noted the growing demand for streaming capabilities:
"We're seeing huge demand for streaming. It's finally real, and it's going mainstream. We're going to see it grow even more because there are so many low-hanging fruits we've plucked... More and more people are doing machine learning in production, and most cases have to be streamed."
Database and streaming solution providers form a third category of competitors. These companies aim to solve the core problem of building real-time feature pipelines and feature stores, though they typically don't provide the broader feature governance and orchestration capabilities that Tecton offers. Notable players in this space include:
Datastax: Datastax, founded in 2010, offers a NoSQL database solution based on Apache Cassandra and was valued at $1.6 billion in June 2022. Datastax’s streaming database powers real-time applications for customers like Home Depot, Verizon, and Capital One. Datastax has rebranded itself as a Real-Time AI company, and announced a new “real-time AI for everyone” mandate in January 2023. DataStax competes with Tecton by providing real-time data platforms that support AI and machine learning workflows, including data storage, streaming, and integration for feature engineering and model deployment.
Materialize: Materialize, founded in 2019, offers a streaming SQL database. It raised a $60 million Series C at an undisclosed valuation in September 2021 which brought its total funding to $100.5 million. Materialize aims to make it easy for businesses to use streaming data in real time. Materialize’s streaming database is actively marketed as a real-time feature store. Materialize competes with Tecton by offering real-time streaming and data transformation capabilities that can be used for feature engineering in machine learning applications.
Business Model
Tecton operates on a software-as-a-service (SaaS) model, offering its feature platform as a managed service. The company has not publicly disclosed its pricing structure or specific details about its business model as of January 2025.
Tecton's pricing model appears to be evolving as the company grows. According to one Tecton customer at a health technology company, Tecton initially offered some clients flat-rate pricing agreements, especially for early adopters in their first year of usage. However, Tecton seems to have transitioned towards a usage-based pricing model for most customers.
For example, one data product management director at a food delivery company explained that Tecton's usage-based pricing is typically structured around "Tecton credits", which correspond to the volume of data rows being written to or read from the feature store. Customers purchase a certain number of credits upfront and can buy additional credits as needed if they exhaust their initial allocation.
However, Tecton must navigate challenges related to pricing and adoption. Some potential customers have found Tecton's pricing to be a barrier. In December 2022, A principal machine learning engineer at a logistics company noted:
"Tecton was checking all the boxes, except price... something like $10K a month per model. It was something completely cost-prohibitive for us to use Tecton at the time."
This pricing structure could slow down adoption and drive users to open-source solutions or cloud provider offerings, particularly for organizations in the early stages of their ML journey or those with less complex use cases. Tecton has reported gross margins above 80%, which is notably higher than some other data platform companies. For comparison, in 2024, Snowflake reported gross margins of around 72%.
Tecton's business model appears designed to support land-and-expand strategies within customer organizations. By allowing customers to start with a smaller implementation and grow their usage over time, Tecton can reduce initial barriers to adoption while positioning itself for revenue growth as customers scale their ML operations.
Traction
In 2022, Tecton reported having ”hundreds of active users” and indicated that its customer base had grown fivefold over the previous year. The company serves a range of industries and company sizes, from growth-stage startups to Fortune 50 enterprises across North America and Europe, with notable customers including Atlassian, Plaid, HelloFresh, Tide, Cash App, Square, and Coinbase.
In July 2022, Tecton announced that over the previous year, its ARR had grown by three times. At that time, some reports indicated that Tecton had less than $6 million ARR, suggesting growth in the intervening period. Tecton has been recognized as a Gartner Cool Vendor and became the first sponsor of the MLOps community. Tecton hosts its own apply() conference, which had 24K+ attendees in 2024. In terms of strategic partnerships, the company has teamed up with Google Cloud and integrated with ModelBit to streamline ML model deployment and feature management workflows.
Valuation
In July 2022, Tecton raised a $100 million Series C round, which brought the company’s total funding to $160 million, where it remained as of January 2025. The round was led by Kleiner Perkins, with participation from previous investors a16z, Sequoia Capital, Bain Capital Ventures, and Tiger Global. Other investors also included Snowflake and Databricks, indicating interest from players in the data platform space.
Reports in September 2022 following the Series C round indicated that Tecton's post-money valuation was approximately $900 million. For context, other late-stage companies in adjacent spaces were commanding lower, but still substantial, multiples around the same time. Databricks was valued at around 27 times its revenue in June 2024, while Snowflake traded at approximately 15.2 times LTM revenue as of August 2024. According to an unverified estimate, Tecton’s annual revenue for 2024 was $24.6 million, which implies a revenue multiple of about 37x at the $900 million valuation from September 20202.
Key Opportunities
Rise In Real-Time ML
Tecton is positioned to capitalize on the growing demand for real-time machine-learning applications. As companies increasingly seek to personalize customer experiences and accelerate decision-making, the need for robust infrastructure to support these initiatives is becoming critical. A 2022 survey found that 78% of CIOs and technology leaders consider real-time data a "must-have" for their organizations. Tecton CEO Mike Del Balso highlighted this opportunity in a June 2023 interview with Contrary Research:
"This isn't some offline analytical machine learning exercise. If it breaks, you can't just hit retry... Running in that domain is substantially different from what everyone else is doing, but there's a growing demand for it and the market is moving to that. It's characterized by scale, speed, real-time, in production, and reliability."
Expanding Data & ML Platform
The company's strategic position as a feature platform provider also creates opportunities for expansion into a more comprehensive ML platform. Tecton currently manages some of the most valuable data assets within an organization - the features used to train ML models. This position could serve as a springboard for extending the platform's capabilities to include model management, continuous retraining, and advanced ML paradigms like continual learning.
Tecton CEO Mike Del Balso indicated this direction in a June 2023 interview with Contrary Research:
"We're going to get to the point where if you're building a data application with ML in production, it's just going to be obvious that you use Tecton. So that involves expanding beyond the feature platform and doing it very intentionally."
Such an expansion could allow Tecton to capture a larger share of the growing MLOps market, which is projected to reach $13 billion by 2030.
Benefiting from the Trend Toward Best-of-Breed ML Solutions
As the ML landscape matures, organizations are increasingly adopting a hybrid strategy, using major cloud providers as a foundation while integrating specialized tools for specific needs. Gartner Research indicated that "most enterprises create a hybrid strategy. That is, they use Amazon, Azure, or Google as a backplane, depending on their enterprise center of gravity, and plug-in components where capabilities might be missing or where they need hyper-customization or specialization."
Tecton's focus on providing a robust feature platform that integrates with existing cloud infrastructure positions it well to capitalize on this trend, potentially becoming a key component in many organizations' ML stacks.
Key Risks
Early Innings for Real-Time
While there is growing interest in real-time ML applications, widespread adoption may take longer than anticipated. Even sophisticated technology companies can take several years to fully transition from batch to real-time ML solutions, as noted by the co-founder of Kaskada, a real-time ML company:
"Just recently, industry leaders in this space have concluded that real-time ML is the way to go, something that required 5-7 year journeys from batch to real-time ML for leaders like Netflix and Instacart."
If the adoption of real-time ML proceeds more slowly than expected, it could limit Tecton's growth potential in the near to medium term. The company's focus on high-value, real-time ML use cases means it is heavily dependent on organizations being ready and willing to implement these advanced applications.
Vendor Consolidation
Major cloud providers and data platform companies are increasingly offering integrated MLOps solutions, including feature store capabilities. This trend toward vendor consolidation poses a risk to Tecton's market position.
While these solutions may not yet offer all the capabilities of Tecton's platform, they are rapidly evolving. As noted earlier, major players like Databricks are increasingly focusing on streaming capabilities. Tecton may find it challenging to differentiate its product and maintain its market position, especially given the tendency of some organizations to consolidate vendors and stick with existing providers. As one startup CTO noted:
"Because [our company] was early in its journey, we tried to put everything into SageMaker... And one of the goals that I took on was to actually reduce the number of tools and consolidate the platforms we were using."
The company may need to continually demonstrate superior capabilities and integrations to justify its adoption alongside or in place of native solutions from established cloud platforms.
Summary
Tecton operates in the growing MLOps market, offering a feature platform for production-grade machine learning applications. The company focuses on real-time ML use cases and integrates with existing cloud infrastructure. Tecton targets organizations with mature ML teams working on high-value applications like fraud detection and recommendation systems.
While Tecton has gained traction with notable customers, it faces competition from in-house solutions and major cloud providers. The company's growth is tied to the broader adoption of real-time ML applications, which may progress slowly. Tecton must also address pricing challenges and the trend toward vendor consolidation to maintain its market position.



