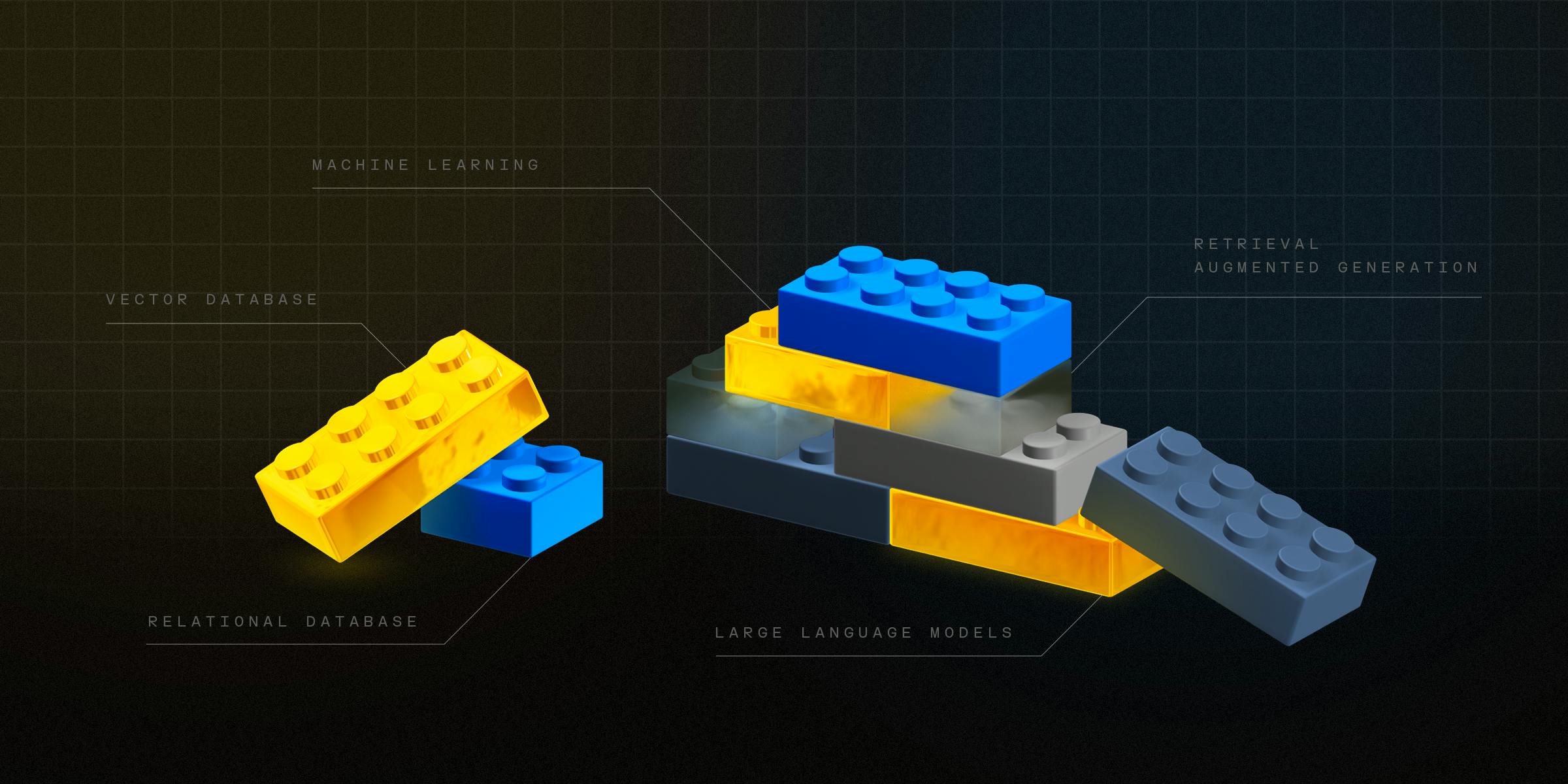
Actionable Summary
Much attention in the early 2020s has focused on generative AI. The broader conversation has revolved around how these tools will shape us and what impact they’ll have on how we write, code, animate, or consume information. But not nearly as much has been said about the shape of our tools.
By the late 1960s, information systems were inundated with large volumes of data, and the process of retrieving relevant information became increasingly costly to operate.
By the 1980s and 90s, relational databases had become the dominant solution, providing intuitive indexing and ensuring query efficiency. Relational databases enabled data to be represented as a collection of tables with structured relationships, facilitating faster data retrieval through query languages like SQL.
Mapped against the backdrop of how database architecture was evolving, specific companies struck their claim on each emerging market; from IBM to Oracle to Sun Microsystems to MongoDB.
Despite Oracle’s leadership in the relational database world, the way people store and access information has not stood still. For every new job to be done, people would figure out a new architecture to manage it.
The latest evolution of the database has come from the need to handle unstructured data. The schemas of the last 50+ years have largely revolved around structured data relationships. But increasingly, people needed a tool that could handle significantly more data obscurity. Enter vector databases.
Large language models (LLMs), specifically, transformer-based models like GPT, are capable of capturing long-range dependencies in text. However, maintaining long-text comprehension can prove computationally expensive. Vector databases can extend the context windows for these models.
As powerful as vector databases can be in AI use cases, they’re still effectively dumb pieces of infrastructure, operated by inputs and outputs. They lack the ability to understand or interpret the data they manage, serving merely as repositories that store and retrieve data as instructed, without any intrinsic intelligence or contextual awareness.
With the launch of GPT-3 in 2020, there was a notable shift in the landscape. AI could increasingly serve as the heart of a company’s product, not just an appendage to it. Transformer architecture, increased volumes of data, and improved levels of performance all set the stage for AI-native products.
As AI-native companies increase in number and scale, the need for tooling that supports AI-native use cases increases. The first wave of companies building with AI at the core largely focused on inference with existing models.
But with increasingly performant models (especially open-source ones that are readily accessible), companies can go deeper in building their capabilities as AI-native businesses. That expansibility opens up a world of opportunities for what the AI-native tech stack looks like.
The Tools that Shape Us
In 1967, John M. Culkin, a friend of Marshall McLuhan, said “We shape our tools and thereafter they shape us.” Building technology is no different. The infrastructure we use to build software has been constantly evolving to fit the needs of our building, and then our building is shaped by the infrastructure we’ve put in place.
Much attention in the early 2020s has focused on generative AI. Particularly, it has focused on the output; the text or code that is generated, the images that are rendered, the deep fakes that are crafted, or the music that is synthesized. The broader conversation has revolved around how these tools will shape us and what impact they’ll have on how we write, code, animate, or consume information. People discuss the comparative performance of large language models, both open and proprietary, the risks of hallucinations, or the platform vs. feature debate, alongside a similar debate between incumbents vs. startups.
But not nearly as much has been said about the shape of our tools. Fundamentally, the way we build technology has been shaped by the infrastructure we put in place for that building. The distribution of SaaS was supercharged by the internet, the prevalence of smartphones enabled mobile development, and the scalability of a generation of applications was spurred by cloud computing.
The prevalence of AI in our applications is a function of compute, model capabilities, and the orchestration of those models within a business use case. In this piece, we’re going to focus on that orchestration component. One key component of orchestrating any AI use case is a company’s database. Where the data is stored, manipulated, and called forward is a critical piece of the puzzle. But, as we’ll show, the history of the database has largely been that of a dumb piece of infrastructure. Increasingly, databases will have to be crafted to be a part of the generative equation if we’re going to maximize the usefulness of AI.
A Base For Data
In May 1959, the Conference of Data Systems Languages (CODASYL) convened for the first time with the intention of constructing “a universal language for building business applications.” By the late 1960s, information systems were inundated with volumes of data, and the process of retrieving relevant information became increasingly costly to operate.
The use of mainframe computers typically led to increases in MIPS (millions of instructions per second) costs given higher utilization of the mainframe from application maintenance, patches, and upgrade costs necessary for maintaining performance. Due to the complexity of database management, rigid hierarchical structures, and convoluted mapping of navigational structures, companies often required technical expertise to access select information, even forcing some developers to write entire programs to access relevant information.
In 1970, E.F Codd published "A Relational Model for Large Shared Banks," proposing a model in which tables could be linked by shared characteristics (namely, primary keys identifying unique records and foreign keys establishing relationships between tables). This made data retrieval from disparate tables possible with a single query. Rather than have data items linked on the basis of separately specified linking, Codd's relational database was predicated on relationships between data items, enabling flexibility in data manipulation and usage.
In 1973, a group of programmers at IBM San Jose Research began working on the System R project, demonstrating that a relational database system could incorporate complete functions required for production use, and still be highly performant. The team was responsible for developing a cost-based optimizer for database efficiency, and developments stemming from System R later resulted in the release of IBM’s first relational database product, SQL/DS.
At IBM Research, the System R team spearheaded a novel method for optimizing database queries, factoring in processing time to develop a relational database prototype based on Codd's proposed model. System R would contribute to the invention of SQL (Structured Query Language), which later became the industry standard language for relational databases, along with the IBM DB2 database management system. DB2, first shipped in 1983 on the MVS mainframe platform, quickly became widely recognized as the premier database management system.
By the 1980s and 90s, relational databases had become the dominant database solution, providing intuitive indexing and ensuring query efficiency. Relational databases enabled data to be represented as a collection of tables with structured relationships, facilitating faster data retrieval through query languages like SQL.
Relational databases were constructed around the assumption that they would be run on a single machine, but mass internet adoption in the 1990s and 2000s contributed to an overwhelming influx of data, creating workloads too heavy for a single computer to bear. Traditional SQL databases were architected to run on a single server and required users to increase physical hardware to match storage capacities, which proved prohibitively expensive for companies operating larger workloads.
The 2010s brought about an exponential growth in data and users for OLTP (online transaction processing), leading to the broader rise of distributed databases, data warehouses, and OLAP (online analytical processing). Relational databases and SQL were no longer tenable for the required application scale and complexity, and NoSQL databases emerged as a means to bolster performance (at the expense of ACID features; atomicity, consistency, isolation, and durability).
While relational databases were capable of storing and manipulating structured data, dealing with the overhead of joins and maintaining relationships among data proved difficult given the costs of create, read, update, and delete (CRUD) operations. Relational databases were well suited for handling relational data with logical or discrete requirements but were typically geared towards legacy systems built specifically for relational structures.
NoSQL emerged as a means of handling unstructured big data, providing data persistence to developers via a non-relational approach. Rather than using SQL as the primary query language, NoSQL provides access via application programming interfaces (APIs), ensuring higher scalability, distributed computing, reduction in costs, and schema flexibility. NoSQL databases operate an efficient architecture capable of scaling out horizontally, so increasing storage or compute capacity merely requires more servers or cloud instances. For businesses with data workloads geared towards more rapid processing or analysis of unstructured data, NoSQL databases became the preference.
The OG Database Wars
Mapped against the backdrop of how database architecture was evolving, specific companies struck their claim on each emerging market. Just after IBM had shipped System R, a 33-year-old Larry Ellison read that same paper by Codd on relational databases. Ellison and his two co-founders built a company intended to be compatible with System R, but IBM made that exceptionally difficult. As a result, the trio built their business around a new flagship database product; Oracle Databases. Since then, Oracle’s database has been a leading product, with ~28.7% market share as of May 2024.
Just a few years before Oracle’s IPO in 1986, another company entered the database arena. Sun Microsystems had gotten its start in 1982 selling a myriad of computer components, but became famous for contributions like the Java programming language, the Network File System, and more. Importantly, in 2008, Sun Microsystems acquired an open-source database management system called MySQL. Just two years later, Oracle would acquire Sun Microsystems (including MySQL). Almost fifteen years later, as of May 2024, two leading databases are Oracle (28.7% market share) and MySQL (~17.3%).
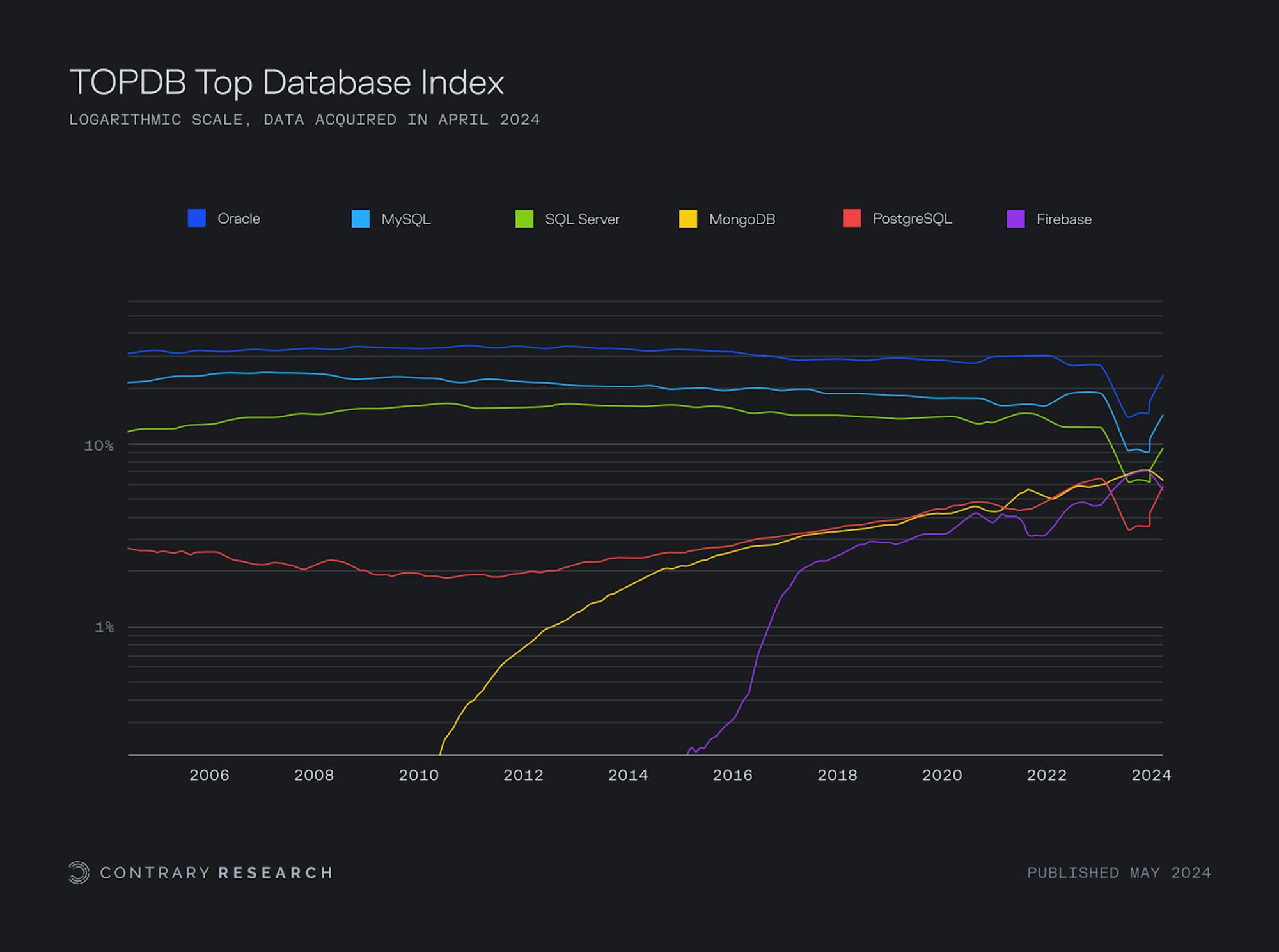
Source: TOPDB Top Database index; Contrary Research
Despite Oracle’s leadership in the relational database world, the way people store and access information has not stood still. For every new job to be done, people would figure out a new architecture to manage it. From document stores, like MongoDB (2007) and Databricks (2013) to time-series databases, like InfluxDB (2013) and Prometheus (2012), to graph databases, like Neo4j (2007) and Cosmos (2017) – the list of specialized databases goes on and on. As relational databases have steadily declined in popularity, these new fringe needs have been met with different solutions.
The latest evolution of the database has come from the need to handle unstructured data. The schemas of the last 50+ years have largely revolved around structured data relationships. But increasingly, people needed a tool that could handle significantly more data obscurity. Enter vector databases.
Rise of The Vector Database
With the broader proliferation of large language models (LLMs) and generative AI, vector databases have emerged as tools capable of handling unstructured, multimodal data. While traditional relational databases (Postgres, MySQL) work best with structured schema, vector databases are equipped to store and query vector embeddings, or numerical representations of data that contain semantic meanings relative to the weights of a language model. Rather than the rows and columns typically employed in relational databases, vector databases represent data as points within multi-dimensional space, matching data based on similarity rather than exact values.
Source: DeepAI
Depending on the embedding model used, data can be represented in different vector spaces and varying dimensions. Vector embeddings capture the semantic meaning of data points, facilitating the retrieval of similar objects from a vector database by searching for objects closest to each other.
Word2Vec, for instance, helps map words to vectors, capturing the meaning, semantic similarity, and contextual relationship with other text. The algorithm employs a shallow neural network to derive the meaning of specific words from a broader corpus of text, identifying any synonymous terms via logistic regression. Other methods of obtaining embeddings include singular value decomposition and principal component analysis, which help extract embeddings without relying on deep neural networks.
Distance metrics help determine the relative “distance” between points in vector space, with common methods including Euclidean distance, Manhattan distance, cosine distance, and Jaccard similarity. K-nearest neighbors, along with approximate nearest neighbor which help improve execution times by simplifying similarity search for images, videos, or other multimodal inputs.
Vector-only databases like Weaviate, Chroma, Qdrant, and Pinecone help developers grapple with large-scale data, specifically in terms of facilitating searches across unstructured inputs. Unlike traditional relational databases (e.g. PostgreSQL), which store tabular data in fixed rows and columns, or even NoSQL databases (e.g. MongoDB), which store data in JSON documents, vector databases are specifically equipped to handle vector embeddings. While conventional databases store data as scalars, vector databases only store vectors, leveraging indexing techniques like quantization and clustering to optimize search operations.
Transformer-based LLMs like GPT are capable of capturing long-range dependencies in text. However, maintaining long-text comprehension can prove computationally expensive. While contemporary LLMs are capable of capturing global dependencies of token pairs across inputs, time and space complexities lead to computational resource challenges, limiting input text length during training and effective context windows during inference.
For multidimensional cases, relative positional encoding is difficult to implement, and most approaches to encode relative positions require a robust mechanism for positional embeddings, which contributes to performance degradation during inference. When dealing with longer sequences, vector databases can be crucial in serving as a model’s long-term memory, even when text length increases. Usage of vector databases may streamline tasks like text completion or summarization, where the full passage context might be necessary for the generation of accurate results.
Vector databases can power Retrieval Augmented Generation (RAG), where the vector database can be used to enhance prompts passed to the LLM by including additional context alongside the original query. Because LLMs often rely on self-supervised training models, they often struggle with domain-specific tasks that require specific knowledge or higher accuracy thresholds. RAG can help verify, trace, or even explain how responses are derived while mitigating hallucinations that may arise from a lack of context around the query in question.
Developers can also combine knowledge graphs and vector search to extend LLMs beyond the data on which they are trained, with tools like Microsoft Research’s GraphRAG facilitating prompt augmentation when performing discovery on private datasets. Baseline RAG often struggles to holistically understand summarized semantic concepts over large data collections, so tools like LlamaIndex and GraphRAG construct knowledge graphs based on private datasets.
Developers may opt to use knowledge graphs over RAG based on specific requirements or use cases. Meanwhile, vector databases are equipped for similarity search and perform best in document or image search, along with recommendation generation, knowledge graphs are suited for reasoning and inference (particularly useful when ingesting data, extracting entities along with interconnected relationships before traversing those relationships).
For applications requiring real-time or near-real-time data processing, vector databases might be preferable given lower latency queries. By ingesting and storing embeddings, vector databases facilitate faster retrieval of similarity searches, matching inputted prompts with similar embeddings. Similarity rankings help support a wide range of machine learning tasks ranging from recommendation systems, semantic search, image recognition, and other natural language processing applications.
Vector databases are critical in enhancing the performance of LLMs through enabling efficient storage and retrieval of vector embeddings, which enable automated understanding of natural language at scale. But vector embeddings represent an N+1 innovation; they are still a form of data, like relational or time-series data before them. Legacy database vendors have started to launch vector capabilities, like MongoDB’s Atlas Vector Search, SingleStore’s vector database, or Neo4J’s vector search indexes. And as powerful as vector databases can be in AI use cases, they’re still effectively dumb pieces of infrastructure, operated by inputs and outputs. They lack the ability to understand or interpret the data they manage, serving merely as repositories that store and retrieve data as instructed, without any intrinsic intelligence or contextual awareness.
For the newest generation of AI-native applications, that is unlikely to be enough. Increasingly, companies are building with AI models at the core of what they do. As a result, if their applications are going to demonstrate increasingly intelligent capabilities, then they’ll need those same intelligent capabilities from their infrastructure.
First-Generation AI-Native Companies
Since academics first started studying artificial intelligence at Dartmouth in 1956, practical use cases have driven the field forward. For example, in the late 1960s, Joseph Weizenbaum built a computer program called ELIZA. Its simple approach to simulate conversation through pattern matching was used in rudimentary therapy-like conversations; the first chatbot.
For most of the history of utilizing AI in business use cases, the improvement of AI has been incremental. Before the term AI was in vogue, the term machine learning was more often used to refer to the same technology, i.e. “statistical algorithms that can learn from data and generalize to unseen data, and thus perform tasks without explicit instructions.” In terms of public awareness, AI reached an inflection point on November 30th, 2022 when OpenAI released ChatGPT. But from a technological perspective, the turning point happened well before that.
In November 2017, the Financial Stability Board, an international regulatory body created to monitor the global financial system, wrote an overview of how machine learning would impact financial services. Increasingly, financial services firms were using machine learning to do things like “assess credit quality” which could “contribute to a more efficient financial system” – i.e. something that could increase efficiency but didn’t constitute an existential imperative.
Machine learning, meanwhile, kept getting better and better. Then, in May 2018, OpenAI published research into the history of the compute required to train large models, showing that compute had increased 300K times, doubling every 3.4 months, since 2012. The next month, in June 2018, OpenAI published the first introduction of the GPT model.
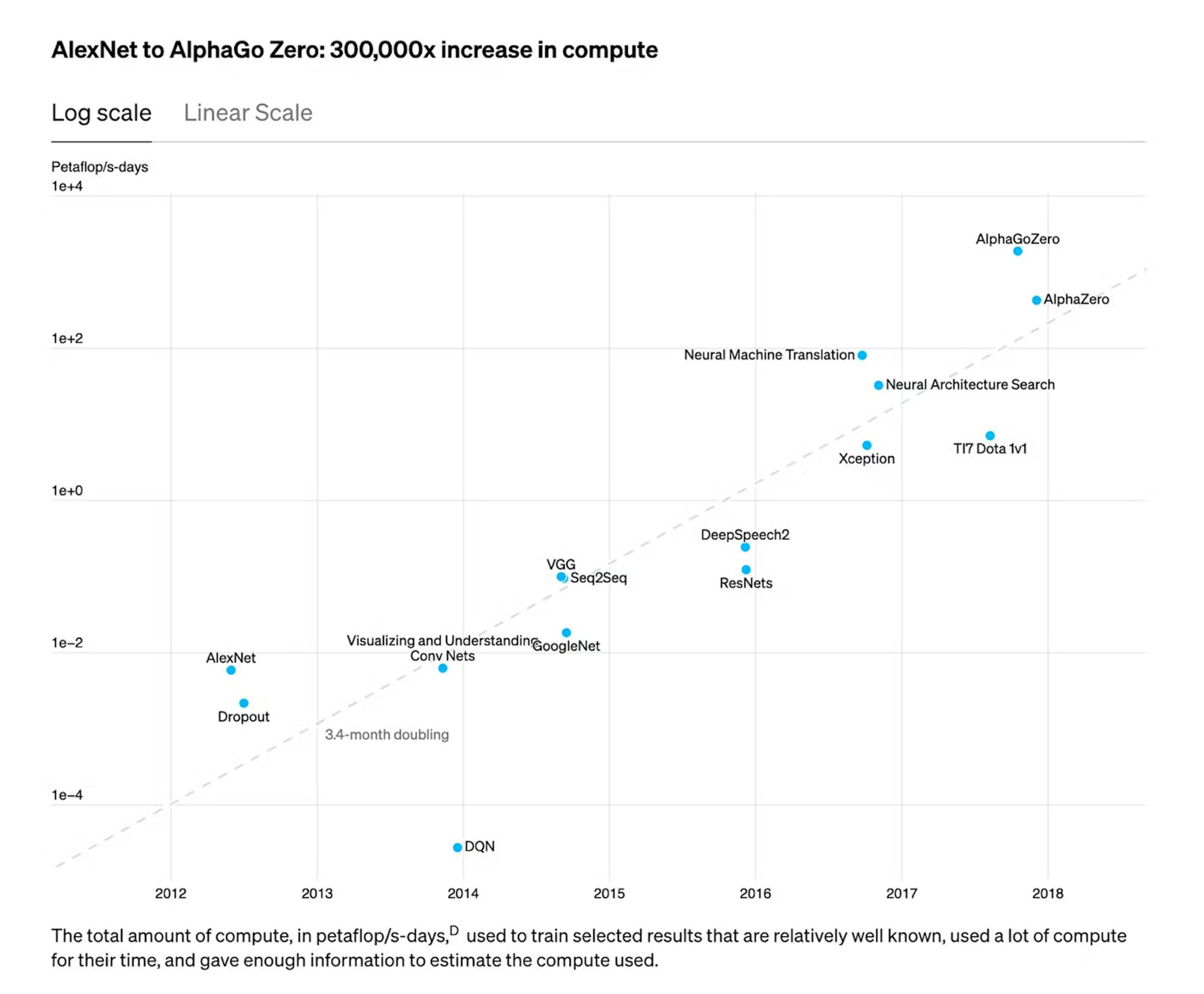
Source: OpenAI
An argument was forming between two camps. On the one hand, many people believed that the continued growth of larger and larger models would have diminishing returns. The other camp, of which OpenAI was a member, believed performance would continue to improve as scale increased. In January 2020, OpenAI researcher and Johns Hopkins professor Jared Kaplan, alongside others, published "Scaling Laws for Neural Language Models”, which stated:
“Language modeling performance improves smoothly and predictably as we appropriately scale up model size, data, and compute. We expect that larger language models will perform better and be more sample efficient than current models.”
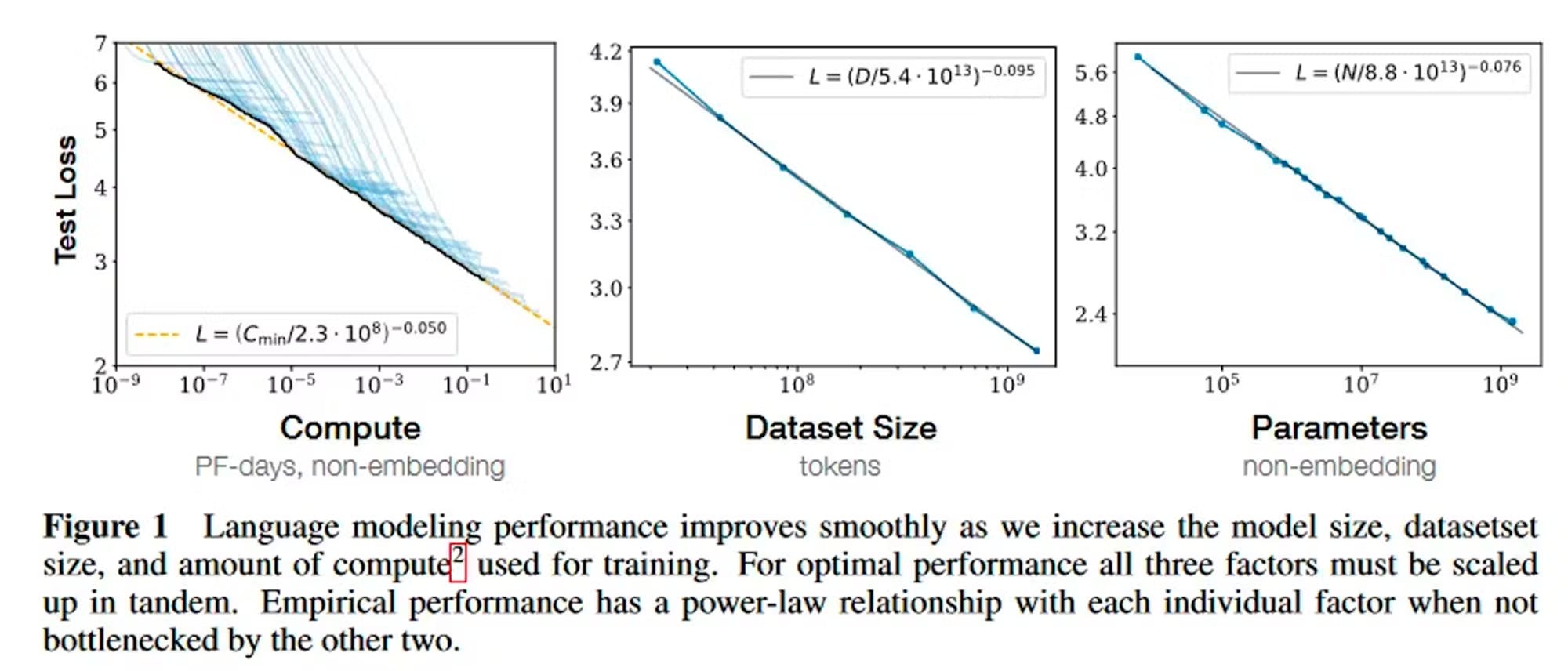
Source: OpenAI
In May 2020, OpenAI published a paper on GPT-3, "Language Models are Few-Shot Learners”, which demonstrated smooth scaling of performance with increased compute.
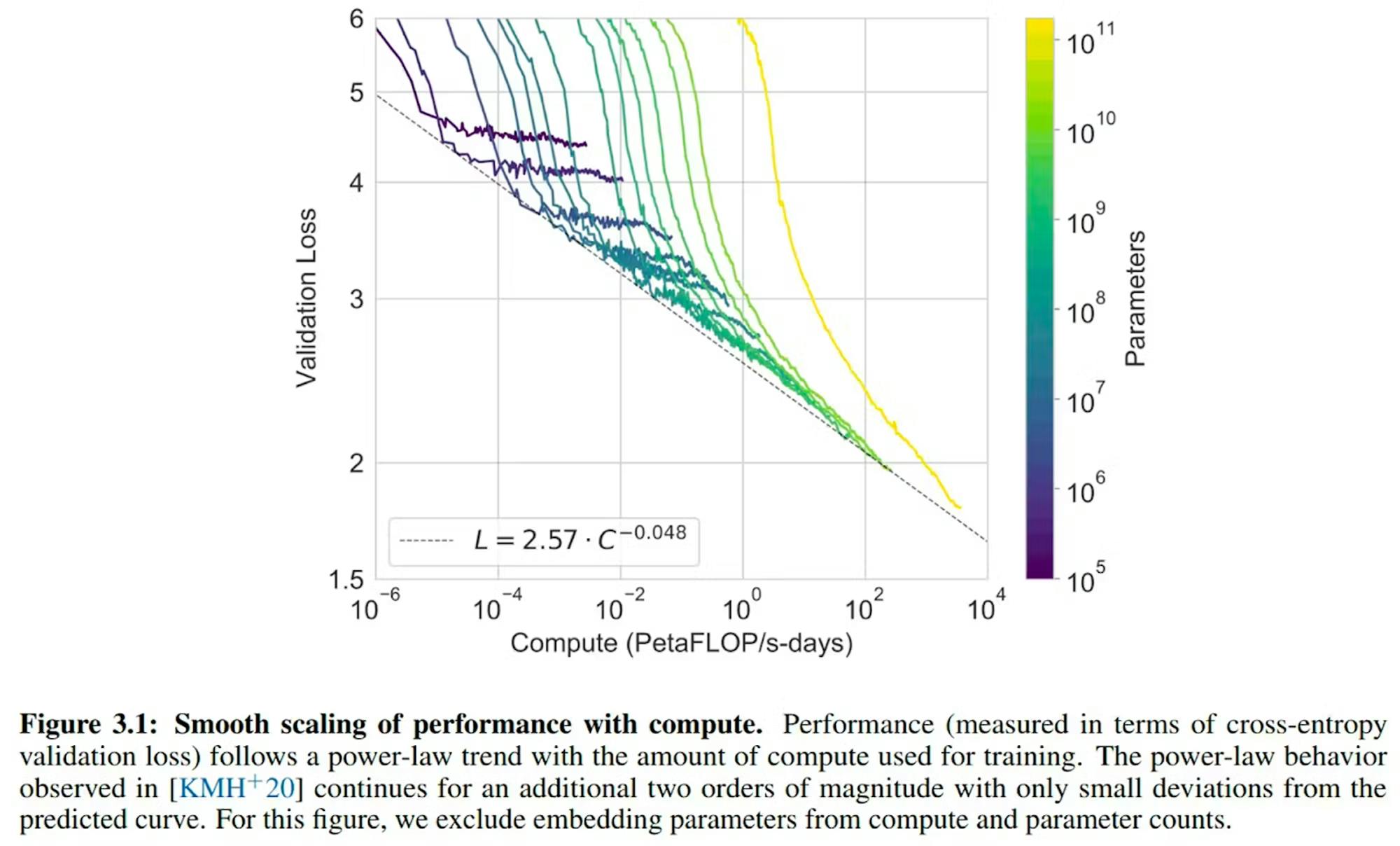
Source: OpenAI
Furthermore, OpenAI found that increasing scale also improves generalizability, arguing that “scaling up large-language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches.” Gwern Branwen, a freelance researcher, coined The Scaling Hypothesis in a blog post, and stated:
“GPT-3, announced by OpenAI in May 2020, is the largest neural network ever trained, by over an order of magnitude… To the surprise of most (including myself), this vast increase in size did not run into diminishing or negative returns, as many expected, but the benefits of scale continued to happen as forecasted by OpenAI."
That surprise that Branwen felt was a shift in the landscape. AI could increasingly serve as the heart of a company’s product, not just an appendage to it. Transformer architecture, increased volumes of data, and improved levels of performance all set the stage for AI-native products.
The age of the AI native company started when models could perform well enough to serve as the core of a product. Soon after the May 2020 launch of GPT-3, companies like Writer and Jasper built copywriting products with AI models at the center of their business. Companies like Harvey and EvenUp built legal tech with AI at their center. Companies like DeepScribe and Freed built medical transcription with AI at their center. But just as new cases precipitated database evolution in the past, the birth of AI-native products meant that. the infrastructure behind each company’s tech stack needed to change and adapt.
An AI-Native Database
As AI-native companies increase in number and scale, the need for tooling that supports AI-native use cases increases. The first wave of companies building with AI at the core largely focused on inference from existing models. They have an application, and maybe some purpose-built workflow tools, whether for copywriting, medical transcription, etc. The core of the product is an output from a model; text generated, or images created.
After OpenAI’s DevDay in November 2023, a meme started circulating about how “OpenAI killed my startup.” Certain specialized GPTs or AI agents seemed like they were taking on the role of some of these early AI-native startups because they, too, were focused on inference from existing models. OpenAI just happened to be the provider of both the model and the application.
Innovation was happening so fast around model capabilities that it started to feel like a threat to startups. But the opposite was also true; with increasingly performant models (especially open-source ones that are readily accessible), companies could go deeper in building their capabilities as AI-native businesses.
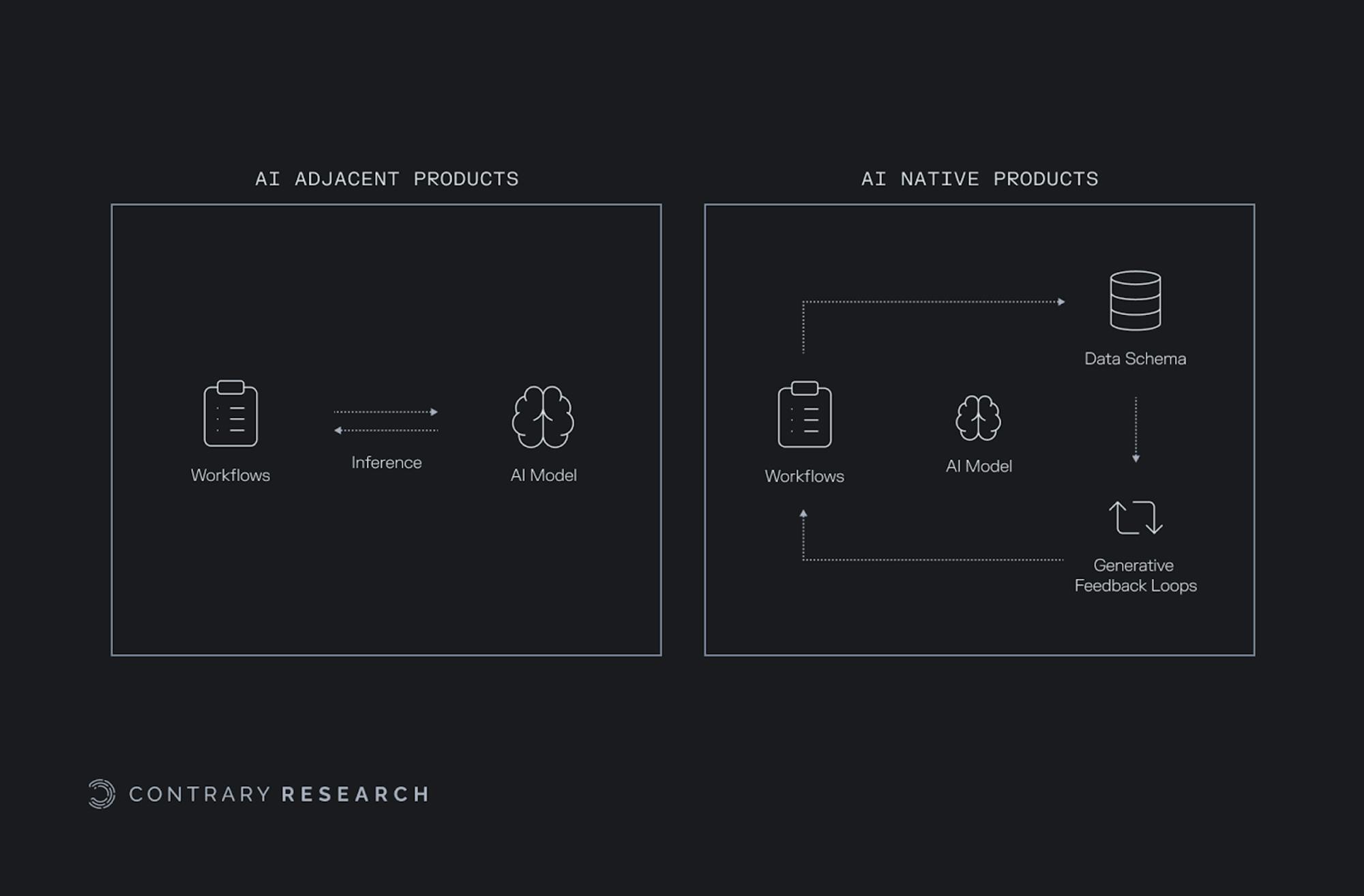
Building an AI-native tech stack is more than just adding components around a model. What does a database, for example, that is purpose-built for AI look like? With inference as a critical output, an AI-native database wouldn’t just store and retrieve data; it would be able to take contextual instructions about what to do with the data it’s storing.
One example of this might be personalizing product descriptions for ecommerce. A vector database could not only store vector embeddings around product SKUs and descriptions, but it could also store embeddings around user personas. Using all this contextual data from the database, the infrastructure could leverage generative feedback loops where a query for a product description also triggers a query for the relevant user personas, and then crafts the product description based on that relevant user persona.
Similarly, language can be used as a generative feedback loop. For example, a user might want to generate a product description in various languages. Product descriptions can be generated that are not just personalized to the user, but translated into the user’s language of choice. These types of instructions can be built directly into the database because use cases, like generative AI, will increasingly become central to an application’s function.
Source: Weaviate
The evolution of infrastructure to fit a use case isn’t new. Originally, developers were building applications in the browser using Javascript to make websites interactive and dynamic. But as developers realized they could bring that to the backend, node.js was born. Then, as developers started to make more mobile applications, you saw the emergence of JavaScript Object Notation (JSON), which enabled more dynamic, responsive, and data-driven applications. MongoDB was perfectly suited to that wave, as a company arose to address evolving infrastructure requirements.
History is repeating itself again with AI. As needs change, infrastructure will have to evolve to meet those needs. The biggest questions will be: what kind of companies do people want to build, and what kind of infrastructure is best suited to those companies? As Bob articulated in an interview with Matthew Lynley:
“I strongly believe that every application in the future will have AI in it. Some applications will have AI sprinkled over them, some will have it at the heart of the application, if you take the AI out it doesn’t exist anymore. If you build a web app and you want to sprinkle some AI over it, great, use MongoDB, especially if you’re already using it… If you want to build an ai-native application that has AI at the heart of the application, that’s when you should consider Weaviate.”
Going forward, companies will decide whether they’ll build a product with AI as an appendage, or as Bob says, a “sprinkle,” or if it will become the crux of their product.
The AI-Native Tech Stack
Source: Contrary Research
For companies that want to build with AI as a core component of their product, their existing infrastructure will likely be inadequate. With legacy tools, data storage, cleaning, and execution are built in one silo, while automation is built in another silo. The drawback of this approach is a loss of context from things like generative feedback loops that could better inform, and improve, a product.
For companies coming from an “AI adjacent” stack, the inference from a particular model will often be limited to the context window. Some believe that as the capacity of a given context window increases, it can replace a vector database. However, the opposite is likely true where the vector database could evolve to replace the context window. Vector embeddings are critical to generative models, and the infrastructure for generative results should treat vector embeddings as first-class citizens.
Rather than simply increasing the size of a context window, a vector database can be woven into the model to offer the contextual understanding of a context window and the reliability and scalability of a database. In particular, the more general purpose a model is, the less purpose-built it will be for any specific jobs. An AI-native vector database will enable more specific capability.
General purpose models, like GPT-4, are built to be deliberately general in their knowledge. If a product depends on some simple finetuning, the underlying model will never become a uniquely valuable part of that business. Building an AI-native product will, in addition to leveraging a model, entail building the product around a more interwoven stack. That stack will provide the scale of a database, and the capability of a model, which results in a more competent product.


