


Thesis
The massive promise of generative AI has attracted exorbitant amounts of capital into the space. In the four years leading up to the launch of ChatGPT at the end of 2022, investors deployed ~$392 billion into AI companies. In the next 2.5 years after that, investors have almost matched that amount, investing over $357 billion up until June 2025. In addition, while AI represented ~19% of venture funding each quarter on average prior to the end of 2022, since then, it has grown to an average of ~35% of venture funding each quarter.
The size of the prize in AI has led to two approaches among most AI companies. First, because of the increased competition for compute, data, and talent, companies increasingly started focusing on proprietary AI models. Companies like OpenAI, Anthropic, and Google have focused on approaches like structured access models, where they can control how users interact with the model. As a result, open models have typically fallen behind closed-source models. Second, because there is so much demand for AI models and no shortage of funding to support that demand, AI companies haven’t focused on being particularly efficient. As of 2024, OpenAI had burned ~$5.5 billion to generate $3.6 billion in revenue. Anthropic was even worse, spending $5.6 billion to generate ~$1 billion of revenue.
Mistral AI was built with the intention of counter-positioning itself against the status quo of building closed proprietary models that burn huge amounts of cash. Instead, Mistral AI’s approach has focused on open source models that are as efficient as possible. Unlike more restricted proprietary models, Mistral AI’s models are built so enterprises can self-host them on a modest cluster or run in hybrid or on-premise environments, which helps reduce infrastructure and operational inference costs.
Founding Story
Mistral AI was founded by Arthur Mensch (CEO), Timothee Lacroix (CTO), and Guillaume Lample (Chief Scientist) in 2023. They met at university, where all three were studying across the field of artificial intelligence from 2011 to 2014.
Mensch spent much of his career attempting to make AI and machine-learning systems more efficient, first as a post-doc researcher at the École Normale Supérieure between 2018 and 2020, and later at Google DeepMind, where he contributed to projects such as Retro and Chinchilla. Lacroix and Lample worked at Meta’s AI division from 2014 to 2023, first as research interns and later as PhD students and researchers. They worked together on papers such as “Open and Efficient Foundation Language Models”, published in February 2023.
In 2021, the three founders, frustrated by the AI industry’s shift toward proprietary models, began discussing how they could help steer development back toward open source. They saw the technology’s rapid acceleration as an opportunity to take a different path. This vision shaped Mistral AI’s mission, which, as Mensch explained in a December 2023 interview, is “to create a European champion with a global vocation in generative artificial intelligence, based on an open, responsible, and decentralized approach to technology.” In a February 2024 interview, Mensch emphasized that efficiency was equally core to their company, stating that “we want to be the most capital-efficient company in the world of AI. That’s the reason we exist.”
In September 2023, Mistral launched Mistral 7B, a 7 billion parameter open source AI model. The team claimed that it was better than models twice its size. In December 2023, French President Emmanuel Macron praised the company, stating, “Bravo to Mistral, that's French genius." By January 2024, Mistral had hired over half the team behind Meta’s LLaMA model to work on its open-source models.
Product
Mistral AI develops foundation large language models (LLMs), offering both open source and premier models. The open source models are licensed under Apache 2.0, which allows the models to be used anywhere without any restrictions. As of September 2025, most of Mistral AI’s open source models are the smaller versions of its models. The premier models either fall under the Mistral research license, which allows users to use those models for research, personal, academic, and non-commercial purposes, or the commercial license, which users can pay for.
Mistral Medium 3
Announced in May 2025, the Mistral Medium 3 model is designed to deliver state-of-the-art (SOTA) performance at 8x lower cost compared to other AI models. When run on benchmarks, Mistral Medium 3 particularly stands out in coding and STEM tasks at a fraction of the price. Medium 3 additionally introduces multimodal support, a 128K token context window, and language output across 45 languages.
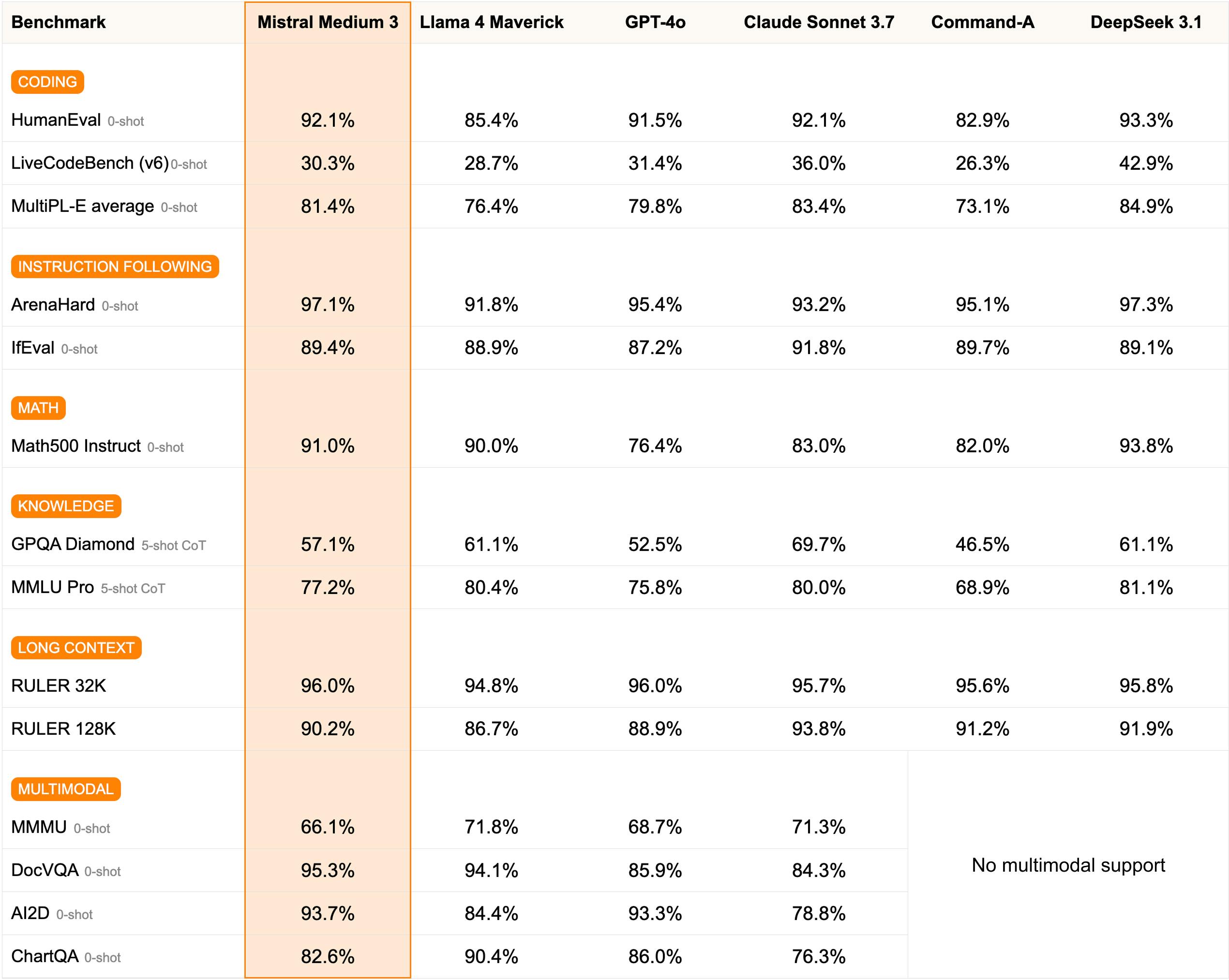
Source: Mistral AI
Magistral
In June 2025, Mistral AI introduced Magistral, its first family of reasoning models trained entirely through reinforcement learning (RL). The release includes two versions: Magistral Medium, a reasoning-tuned model built on top of Mistral Medium 3 via RL alone, and Magistral Small, a 24 billion parameter open-source model (Apache 2.0).
The Magistral Models use a Group Relative Policy Optimization (GRPO) as its RL algorithm with modifications such as removing the KL divergence penalty, a typical RL training mechanism to ensure the new model doesn’t diverge too far from its training data. Removing this enables more open deviations, while ensuring accuracy by leveraging GRPO.
GRPO can be thought of as grading on a curve in a classroom: the model writes several answers to the same question, and instead of being judged by an outside critic, each answer is compared against the average of the group. The better-than-average answers are rewarded, while weaker ones are penalized. This setup allows the model to improve by competing with its own work, encouraging exploration of different reasoning paths without the need for a separate “teacher” model.
The reward system acts like a set of exam rules. The model only gets credit if its work follows the required format (showing scratch work inside <think> tags, boxing final math answers, or compiling code that passes tests). Additional points are awarded for correctness, for writing in the same language as the problem, and for staying within a reasonable length. This ensures that Magistral’s reasoning is not only accurate but also well-structured, consistent, and multilingual. Magistral Medium scored 73.6% on the math exam, AIME 2024, and 90% with majority voting at 64, which yields a 50% increase in AIME-24 performance (pass 1) over the Mistral Medium 3 checkpoint.
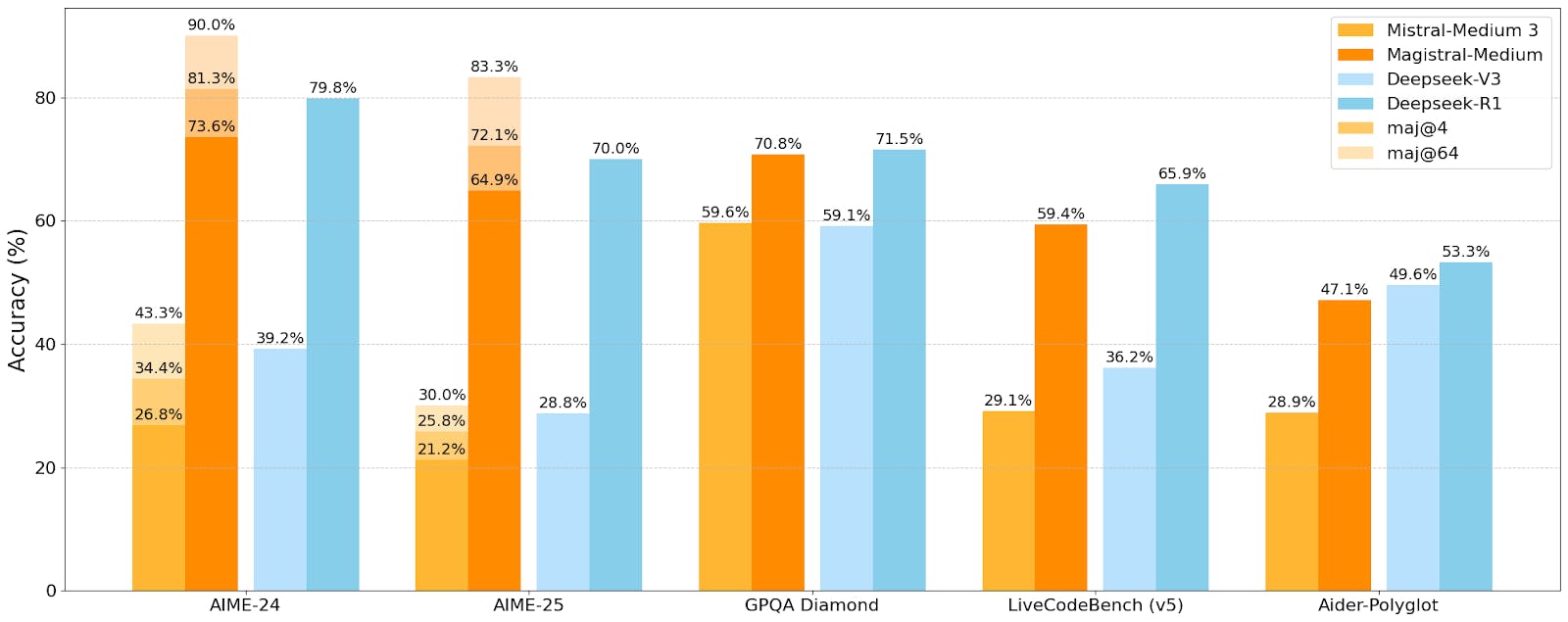
Source: Mistral AI
Voxtral
In July 2025, Mistral AI introduced Voxtral, a family of multimodal audio-text chat models designed to process both spoken audio and written inputs natively. These models can be used for tasks such as audio transcription, voice-to-function calling, text understanding capabilities, and multilingual support.
The release includes the models in two sizes: a 24 billion parameter variant for production-scale applications and a three billion parameter variant for local and edge deployments. Both versions are released under the Apache 2.0 license.
Voxtral is based on the transformer architecture and is split into three components: an audio encoder, an adapter layer, and a language decoder to generate text outputs.
Imagine the audio encoder as the ears of the model, listening carefully to speech and turning it into detailed representations. The adapter layer is like a skilled note-taker, condensing those dense representations into a more compact format without losing essential meaning, so the system doesn’t get overwhelmed by the sheer volume of sound data. Finally, the language decoder acts as the voice and reasoning engine, taking the condensed notes and producing fluent, context-aware responses in text. This design allows Voxtral to process audio files up to 40 minutes long with just a 32K token context window.
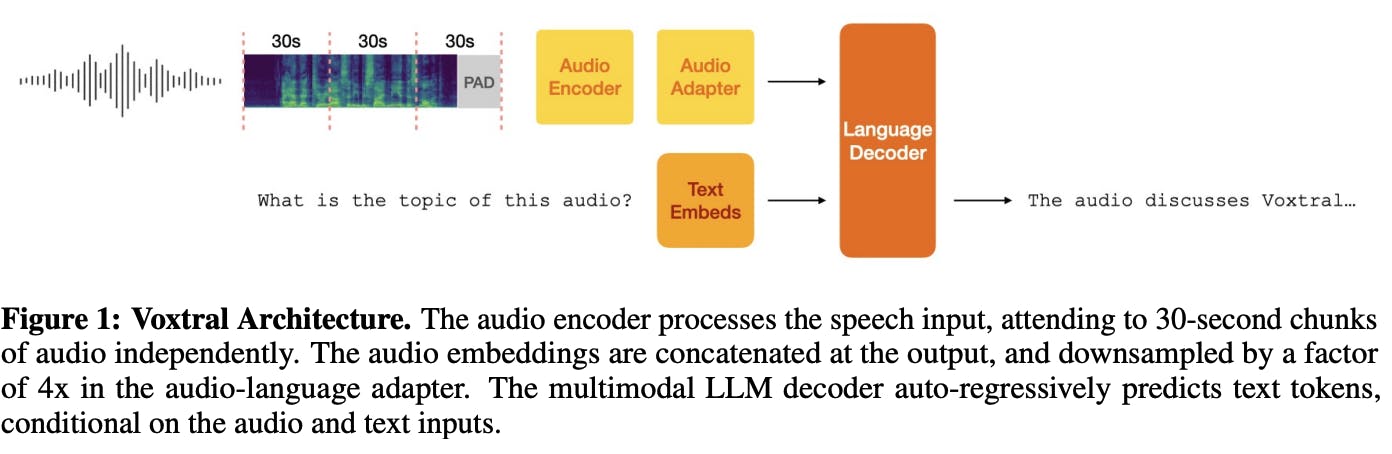
Source: Voxtral Paper
In benchmarks, the larger Voxtral model achieves SOTA performance in transcription and multilingual speech understanding, rivaling or surpassing closed-source systems like GPT-4o mini and Gemini 2.5 Flash. Both Voxtral models are free to download on Hugging Face, can be used via API, or interacted with in Le Chat.
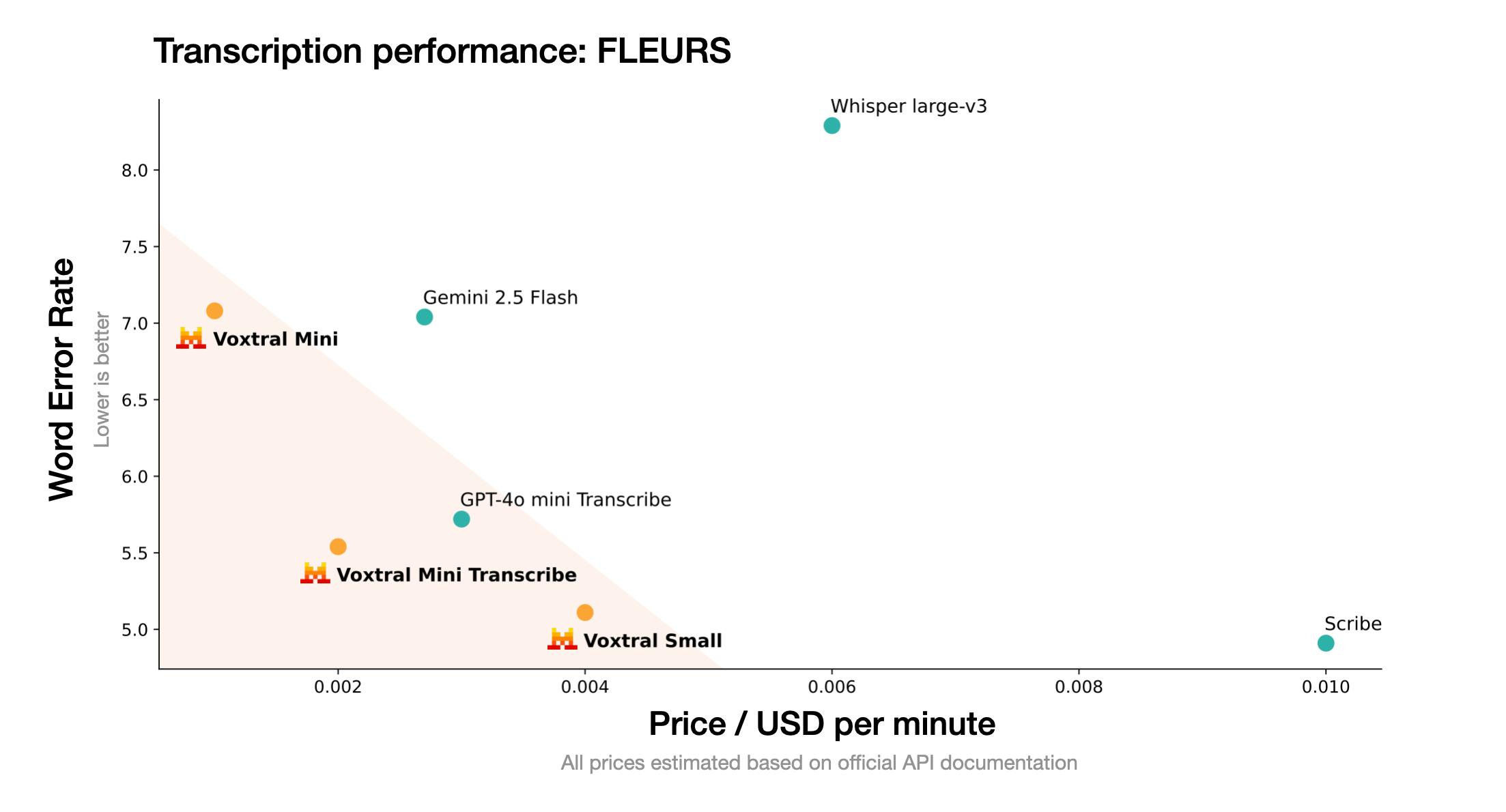
Source: Mistral AI
Pixtral
In 2024, Mistral AI introduced the Pixtral family, a line of multimodal large language models capable of processing both images and text. The lineup includes Pixtral Large, a 124 billion open-weights multimodal model built on top of Mistral Large 2, and Pixtral 12B, a 12 billion parameter model based on Mistral Nemo (Mistral’s drop-in replacement for Mistral 7B).
Pixtral 12B, released under the Apache 2.0 license in September 2024, is designed as a multimodal successor to Mistral Nemo 12B. The model is instruction-tuned and pretrained on large-scale dataset of multimodal data that included both images and text. Its architecture can be thought of as a reader, translator, and writer: the reader (vision encoder) ingests images at its natural resolution and aspect ratio, the translator (adapter) converts visual information into a shared representation, and the writer (decoder) generates fluent text grounded in both images and language. Pixtral 12B shows strong performance across a number of tasks, ranging from multimodal reasoning to instruction following.
The Pixtral Large, released under Mistral Research License and Mistral Commercial License, is designed as an extension of Mistral Large 2. The model is comprised of a 123 billion parameter multimodal decoder and a one billion parameter vision encoder. The model performs similarly to a number of 2024 models, such as GPT-4o, Claude-3.5 Sonnet, and Gemini-1.5 Pro.
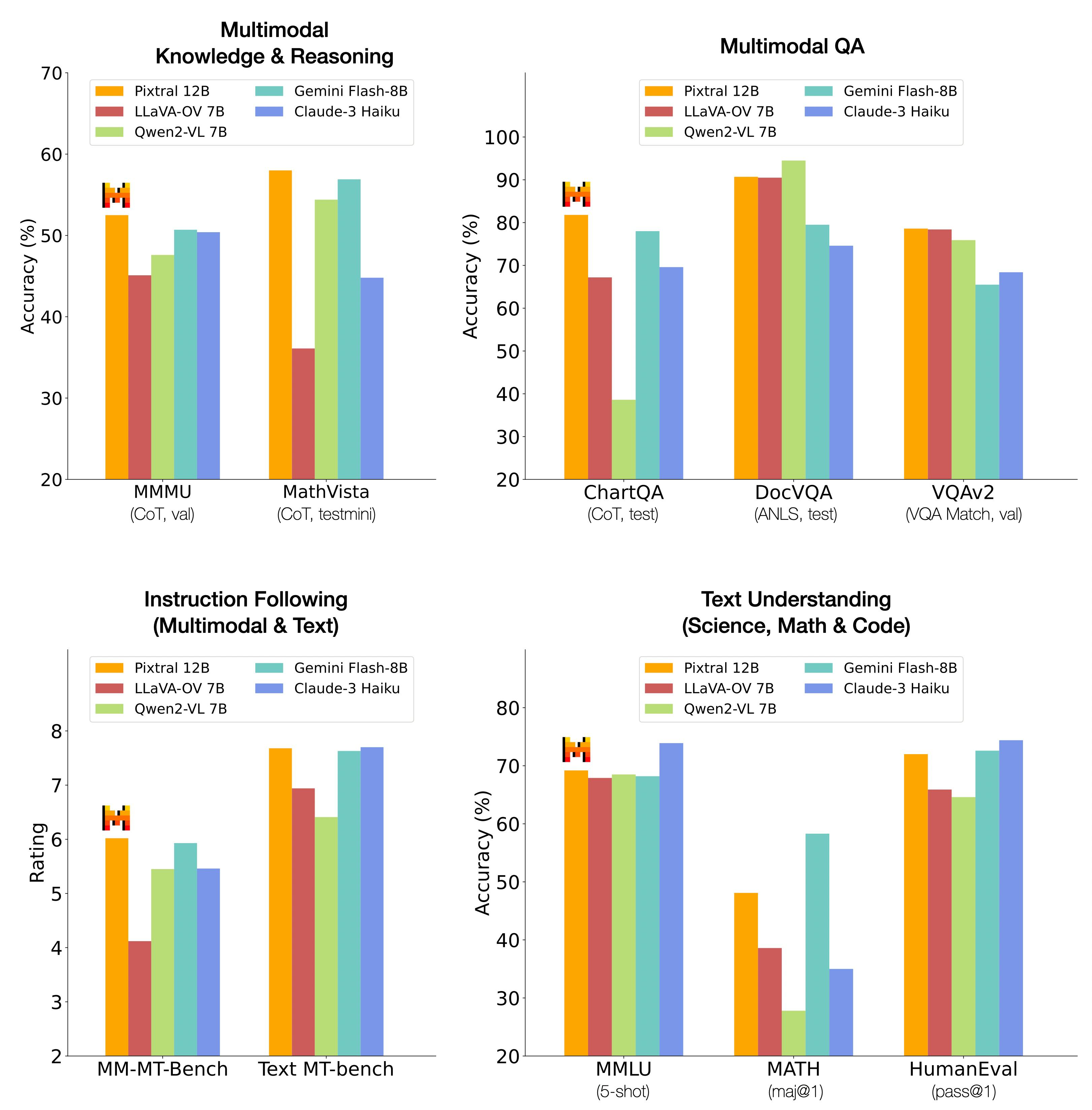
Source: Mistral AI
Legacy Models
As of August 2025, several of Mistral AI’s legacy models have been deprecated, meaning they are still available for existing deployments but are discouraged for new use. However, they continue to offer valuable insight into Mistral AI’s early methodological approaches.
Mistral 7B: Released in September 2023, Mistral 7B was the company’s first model before it was deprecated in November 2024. At the time of release, Mistral AI claimed this model, made up of seven billion parameters, outperformed “all currently available open models up to 13 billion parameters on all standard English and code benchmarks.”
Source: Mistral AI
Mistral 7B is fluent in English and code. Leveraging transformer architecture, it integrates components such as sliding window attention, rolling buffer cache, and pre-fill & chunking to improve efficiency and performance.
Sliding window attention can be explained using a metaphor: imagine someone is on a train moving through a landscape, but the window only allows them to see a few meters around them at any given time. As the train moves forward, their view shifts, allowing them to see new parts of the landscape while losing sight of the parts they’ve passed. This is similar to sliding window attention, where a model only focuses on a portion of the entire data (like the words in a sentence) at one time. This method helps the model efficiently process long sequences of data by focusing on smaller, more manageable chunks, improving both speed and resource usage without losing the context needed for accurate predictions. This helps the model be more efficient, reducing the computational cost while allowing each word to be influenced by its context.
To understand rolling buffer cache, imagine someone playing a video game on a console. To ensure the game runs smoothly without loading pauses, the console keeps the most recent and relevant data (like the immediate game environment) in memory, discarding older, less relevant data as the player moves through the game world. The rolling buffer cache works similarly in computing, storing recent inputs and then moving older, less relevant data out of the cache as new data comes in. This process allows the system to efficiently manage memory resources by ensuring only the most current and necessary data is kept ready for quick access, which is key for processing large amounts of data without overwhelming the system's memory capacity.
For pre-fill and chunking, imagine someone is planning to cook a large meal, and the recipe calls for numerous ingredients. Instead of measuring and cutting each ingredient as they go, they prep everything beforehand: chopping vegetables, measuring spices, and so on. Dividing each step into smaller, manageable portions (or "chunks"). This way, when it's time to cook, they can focus on combining these pre-prepped portions in the right order, without the need to pause and prepare each one. This method streamlines the cooking process, making it more efficient and ensuring that each step is ready to go as soon as needed. Similarly, "pre-fill and chunking" in the computational context means pre-loading the model with chunks of data (the "ingredients") so that processing (or "cooking") can happen more smoothly and efficiently, without the need to process the entire dataset from scratch every time a new piece is needed.
Mixtral 8x7B: In December 2023, Mistral AI released its second model, Mixtral 8x7b. In December 2023, according to the company Mixtral, outperformed Llama 2 70B on “most benchmarks” with 6x faster inference and matched or outperformed OpenAI’s GPT 3.5 on “most standard benchmarks.”
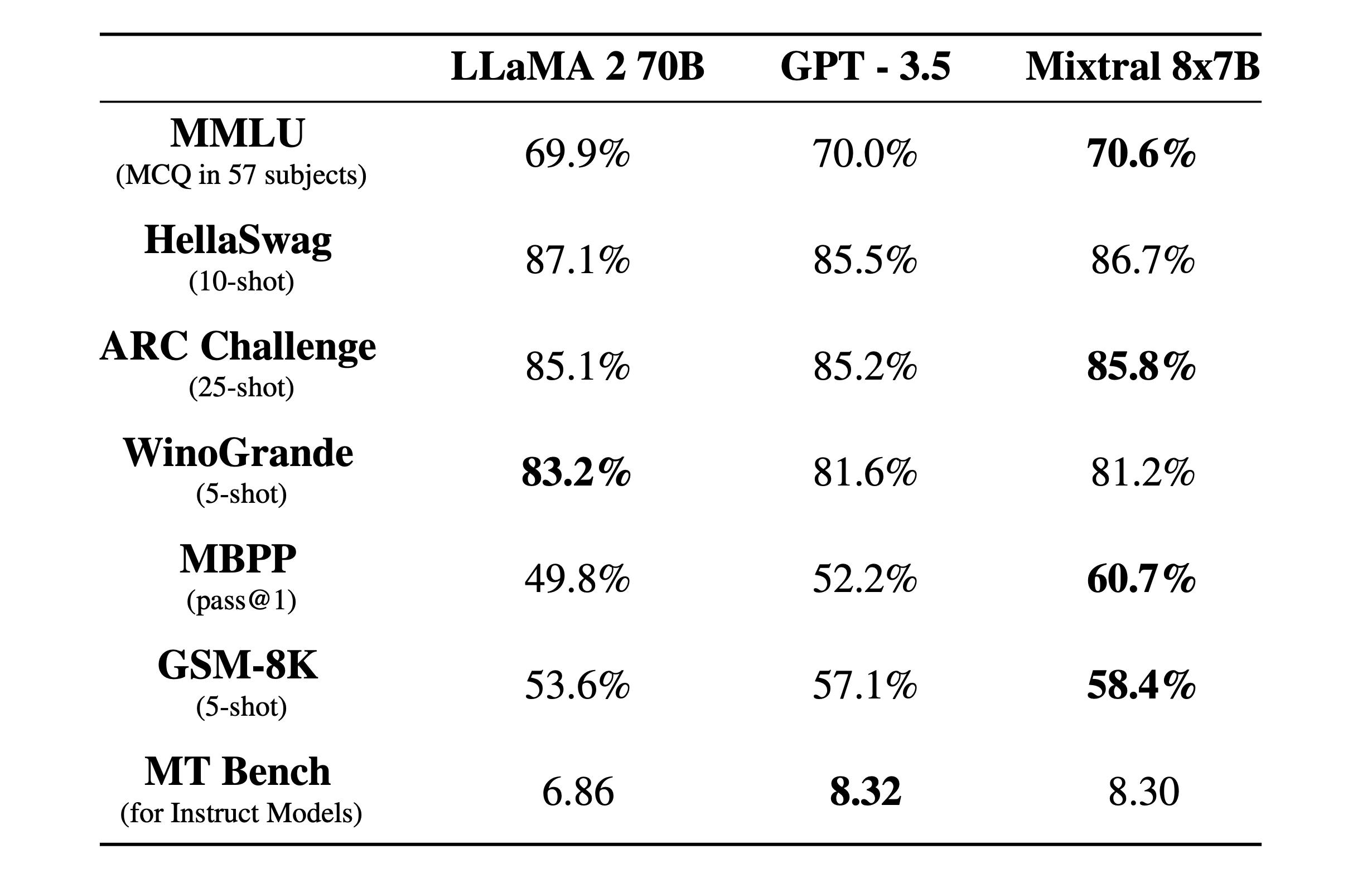
Source: Mistral AI
Mixtral 8x7B was a sparse mixture of expert models (SMoE) with open weights. Think of SMoE as a talent show where each participant (expert) has a unique skill, and the judges (gating network that controls how to weigh decisions) decide which acts to showcase based on the audience's current mood (input data). Instead of having every act performed every time, which would be time-consuming and irrelevant, the judges pick a few acts that best match the audience's interests, combining their performances to create an engaging show. This approach allows the show to adapt to different audiences efficiently, using only the most relevant talents. This mirrors how SMoE selects the "experts" for processing data. The SMoE technique increases the number of parameters of a model while controlling cost and latency, as the model only uses a fraction of the total set of parameters per token. Consequently, Mixtral 8x7B has 46.7 billion total parameters but only uses 13 billion parameters per token. Therefore, the model processes input and generates output at the same speed and for the same cost as a 13 billion parameter model.
Mixtral 8x7B handles a context of 32K tokens and is fluent in English, French, Italian, German, Spanish, and code. Like Mistral 7B, it is licensed under Apache 2.0 and can be used for free.
Mistral Code
Over the course of 2024 and 2025, Mistral AI introduced the Mistral Coding Stack, a full-stack approach to AI-native software development that combines Codestral for code generation, Codestral Embed for semantic search and retrieval, and Devstral for agentic multi-step coding workflows. Together, these components form an integrated system designed for enterprise environments. Unlike most SaaS-only copilots, Mistral’s AI tools coding stack can be deployed in the cloud, in a VPC, or fully on-prem.
At the foundation is Codestral, Mistral’s family of code models optimized for high-precision fill-in-the-middle (FIM) completion. The July 2025 release, Codestral 25.08, improves completion acceptance rates by 30%, boosts retention of suggested code by 10%, and halves runaway generations compared to its previous version. Released in May 2025, Codestral Embed is Mistral AI’s first embedding model specialized in code. As of August 2025, Codestral Embed outperforms other code embedders in the market, such as Voyage Code 3, Cohere Embed v4.0, and OpenAI’s large embedding model.
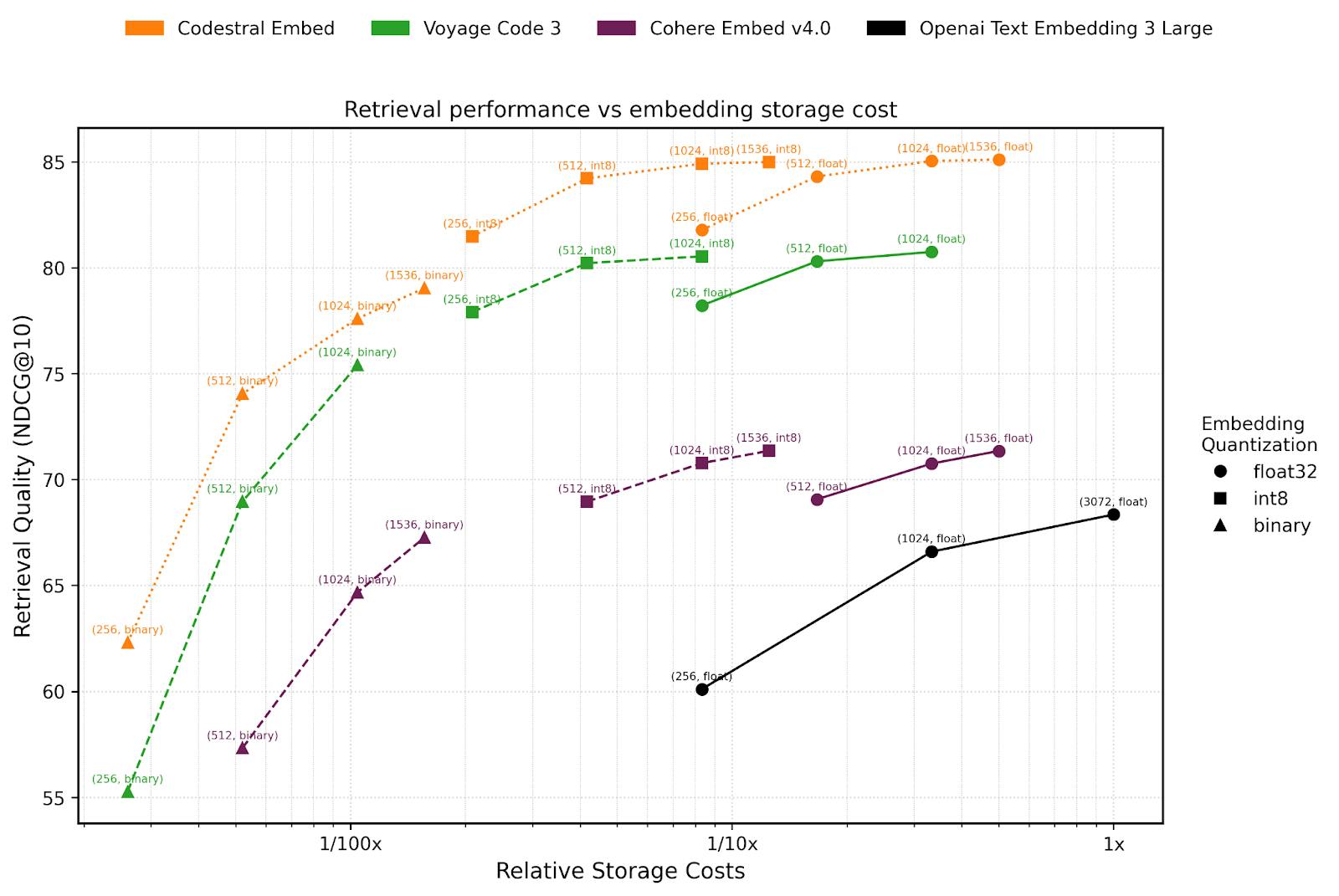
Source: Mistral AI
Released in May 2025, Devstral was built as a collaboration between Mistral AI and All Hands AI as an agentic coding system and handles tasks such as cross-file refactors, test generation, and PR authoring. All capabilities are surfaced through Mistral Code, a native JetBrains and VS Code plugin that acts as the interface for the stack. It brings inline completions, one-click automations (“fix function,” “add docstring”), and context from Git diffs and static analysis directly into the IDE.
Mistral Compute
Source: Mistral AI
Mistral Compute is a European-hosted AI cloud platform that brings together GPU infrastructure, orchestration tools, and model training/serving capabilities into an integrated offering. It is intended for AI builders who want less infrastructure setup overhead and more ability to ship, by offering bare-metal to fully managed cluster options, APIs, tooling, and deployment pathways. Key components include access to modern NVIDIA GPUs, reference architectures, and training recipes developed by Mistral.
The service includes several infrastructure options: bare-metal servers, managed clusters, or “Private AI Studio,” which allows customers to move between tiers without needing to refactor their stack. It supports full fine‐tuning, LoRA, continued pre-training over very large token counts (>100 billion tokens), evaluation tools (for example, MMLU, HELM, domain-specific test sets), built-in observability, GitOps pipelines, and automatic gating/regression. For serving production models, it provides REST endpoints and production deployment tools.
Mistral Compute emphasizes sovereignty, data locality, compliance, and security features. It uses EU-based data centers, which are certified across multiple international standards. Other capabilities include networking and isolation controls, encryption at rest, optional customer-held keys, and support for enterprise-type identity, access, secrets, and policy tools (SSO, RBAC, SLURM integration, SCIM provisioning). In addition, the platform supports integrations for data loss prevention (DLP), auditability, webhooks for CI/CD, and other controls required in regulated or enterprise settings.
La Plateforme
La Plateforme is Mistral AI’s developer platform. This platform leases “optimized” versions of the company’s models to developers through generative endpoints, accessible via an API. Models available include language, code, multimodal, and small/edge models with tools for model customization like fine‐tuning, distillation, embeddings, and function/tool calling.
The goal of La Plateforme is to offer efficient deployment and tailored customization for various use cases. As of September 2025, Mistral AI offers three types of access to its models: virtual cloud, edge, or on-premise. La Plateforme provides several additional features, empowering developers and enterprises to control the fine-tuning process, agent development, a playground to run experiments, and more.
Additionally, La Plateforme offers applied AI services: expert support to help customers tailor and deploy AI solutions, from proof-of-value to production, including services around use-case identification, custom model training, and performance optimization. It also emphasizes safety, monitoring, and operational visibility.
Le Chat
Le Chat is Mistral AI’s chatbot service, available via web, iOS, or Android, and is functionally equivalent to OpenAI’s ChatGPT but powered by Mistral AI’s foundation models. Le Chat automatically selects the appropriate tools to accomplish given tasks, including:
Agents: Agents are specialized virtual assistants that can be customized to answer questions with a specific style or structure, connect with other tools, and have custom guardrails for Agents’ responses.
Canvas: Canvas is Mistral AI’s interface for collaborating with writing, data, and coding projects.
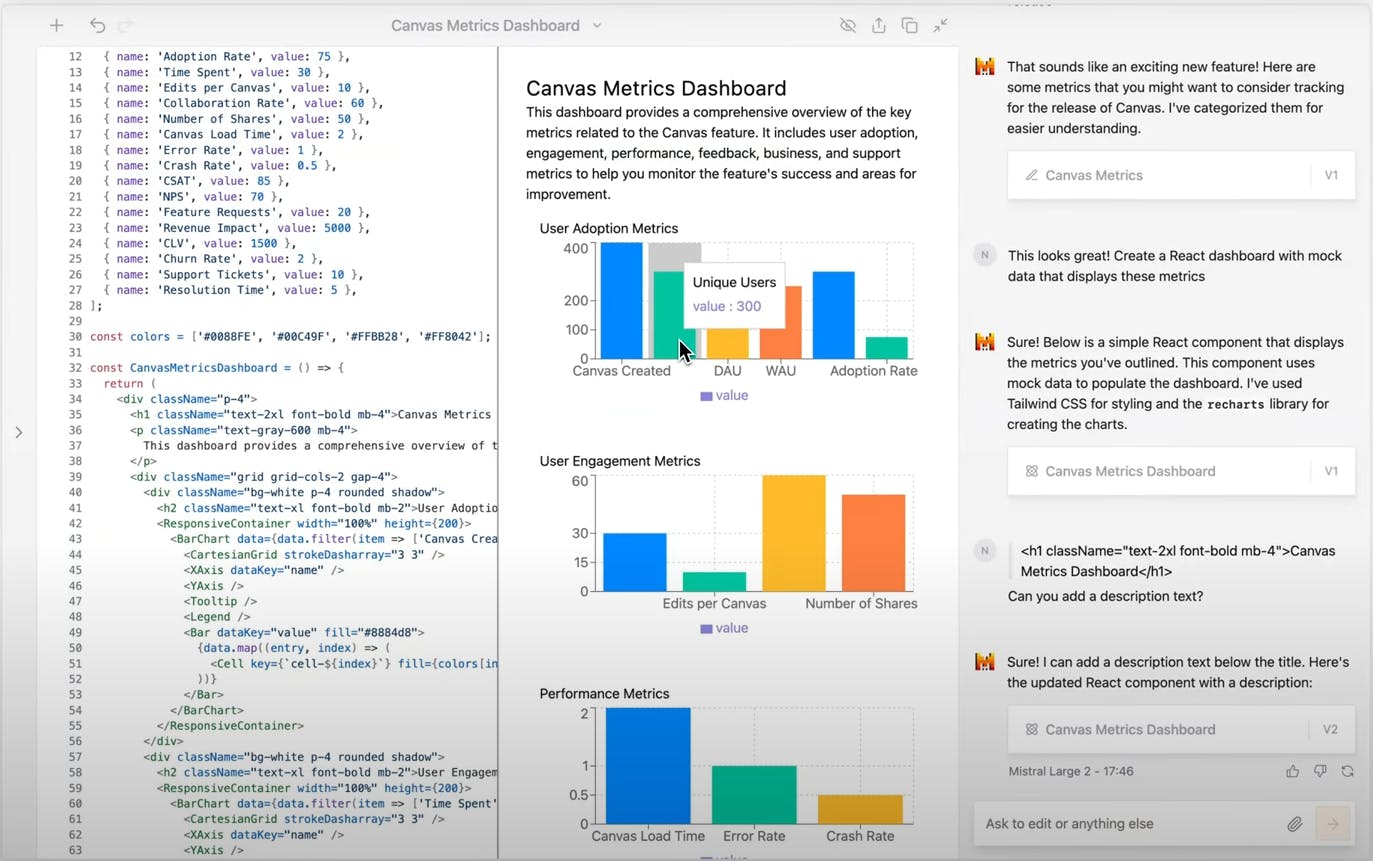
Source: Mistral AI
Code Interpreter: Code Interpreter allows Le Chat to generate Python code and execute the scripts directly in a sandboxed environment.
Connections: Custom connectors supercharge Le Chat by ****linking it to user-specified external data sources (such as your email account or your calendar). As of August 2025, this feature is in beta mode and has available connections to Gmail, Google Calendar, Google Drive, and Microsoft SharePoint.
Document and Image Understanding: Le Chat can properly extract content from uploaded text documents, PDFs, and images. Le Chat uses a vision model to interpret images.
Image Generation: Powered by Black Forest Labs diffusion models, this feature allows users to create visual content based on natural language instructions.
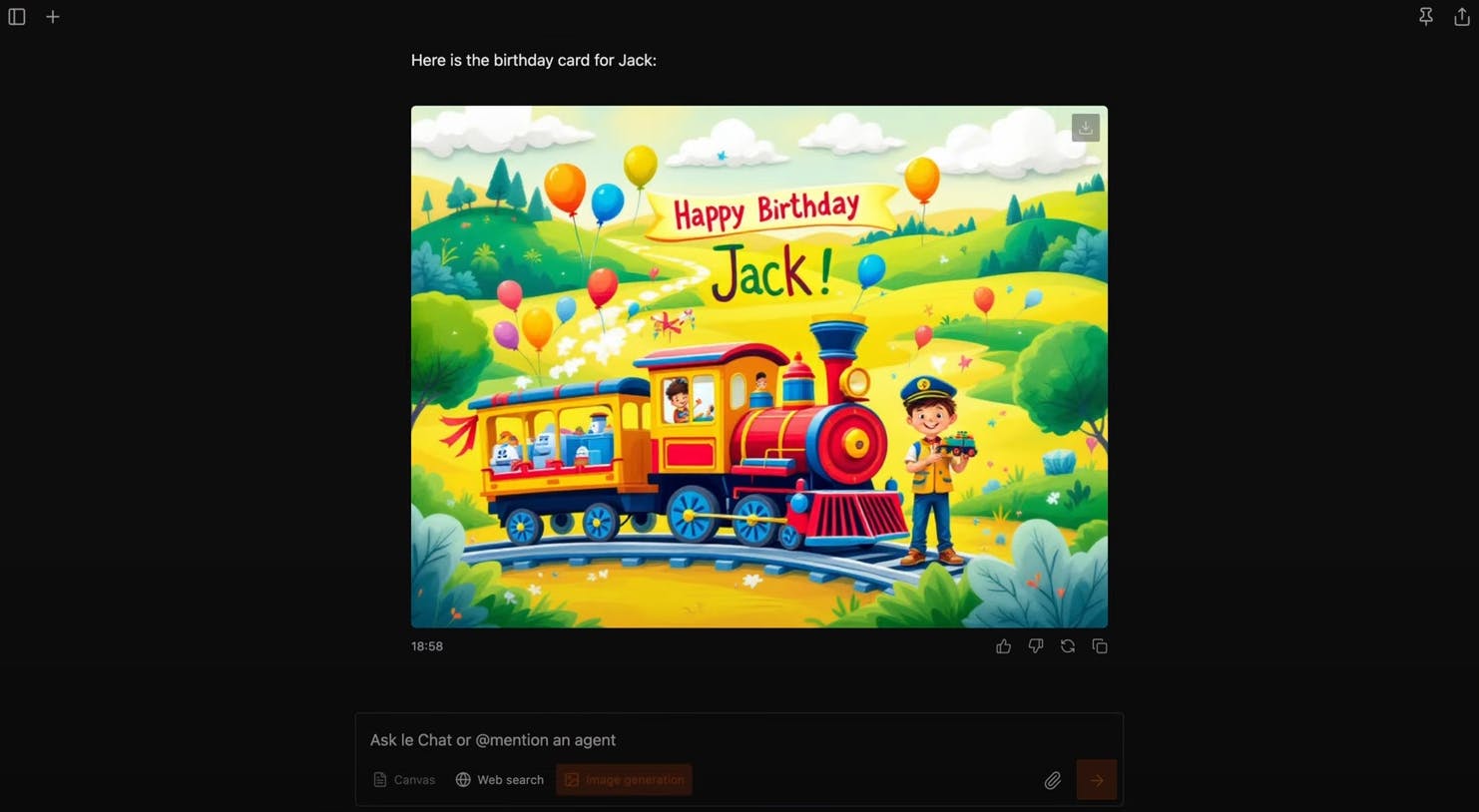
Source: Mistral AI
Web Search: When enabled, Le Chat can retrieve up-to-date information from the internet (and from trusted sources such as Agence France-Presse (AFP) and AP news agencies) to provide context to answer user-inputted questions.
As of September 2025, Le Chat can use Mistral Large, Mistral Small, Mistral Next, a model “designed to be brief and concise,” or Codestral. Users can access Le Chat for free. Mistral AI also offers Le Chat Enterprise, which offers advanced features such as hybrid deployment to either be self-hosted, in your enterprise’s cloud provider, or a service hosted in the Mistral cloud, and advanced solutioning where Mistral AI helps tailor models for specific use-cases.
Market
Customer
Mistral AI targets “the performance-cost frontier” for businesses looking to implement generative AI in its offerings. In terms of cost, Mistral Medium 3 was reportedly much cheaper than both Claude Sonnet 4 and GPT-4 in terms of metrics like input cost per million tokens (e.g., Mistral Medium 3 costs $0.40 compared to Claude Sonnet 4 at $3.00). As of September 2025, notable Mistral AI customers include BNP Paribas, Cisco, IBM, the French Ministry of Defense, Qonto, SAP, and Snowflake. In March 2024, Mensch indicated that he wants to push Mistral AI towards even more enterprise deals.

Source: Mistral AI
Market Size
The global artificial intelligence market was valued at $150.2 billion in 2023 and was expected to reach $1.35 trillion by 2030, growing at a CAGR of 36.8%. Generative AI, the capability enabled by foundation models, could add between $2.6 trillion and $4.4 trillion annually to the world economy, according to one report. Across categories like banking, retail, and consumer packaged goods, generative AI could add between $200 billion to $660 billion a year per category. Foundation models, such as the ones developed by Mistral AI, underpin much of this growth by providing versatile platforms that can be customized for a variety of applications across multiple industries.
Competition
Companies such as OpenAI, Anthropic, and Google develop “proprietary” models where the technology is owned and controlled by the entity, with access restricted. Alternatively, Mistral AI develops “open” models where all of the company’s models are accessible to the public for free and distributed through an open-source license, while larger versions of the same models may be available through commercial licenses.
OpenAI
Founded in 2015, OpenAI was initially a non-profit before starting to try and transition to a for-profit in 2019. The company created its Generative Pre-trained Transformers (GPT) series of AI models, which the company first introduced in 2018. In particular, the company is best known for its consumer-facing chat product, ChatGPT, which reached 700 million weekly active users in September 2025. In August 2025, OpenAI raised $8.3 billion at a $300 billion valuation led by Dragoneer Investment Group.
Initially, OpenAI had an open approach to model development; for example, it released the source code and model weights for GPT-2 in November 2019. The company later changed its approach; following the launch of GPT-4 in March 2023, co-founder Ilya Sutskever stated “we were wrong” about OpenAI’s development of open models in the early days, and explained the company’s shift. OpenAI believes that a combination of competition and safety makes open development impractical.
However, after the release of DeepSeek in January 2025, an open-source Chinese AI model, OpenAI started to adjust its thinking. Shortly after the release, Sam Altman made a surprising acknowledgement about the shifting landscape in regards to open source. In January 2025, in response to the question of whether OpenAI would consider releasing model weights and research, Sam Altman responded:
“I personally think we have been on the wrong side of history here, and need to figure out a different open source strategy. Not everyone at OpenAI shares this view, and it's also not our current highest priority.”
Since then, OpenAI released an open-weight model in August 2025 that provided more access and fine-tuning flexibility, though these are not fully open source in terms of training data, code, or full transparency.
Anthropic
Founded in 2021, Anthropic produces AI research and products with an emphasis on safety. The company develops Claude, a family of closed foundation AI models trained and deployed through a method it dubbed “Constitutional AI” where the only human oversight during training is through a list of rules, principles, and ethical norms. Anthropic was founded by former OpenAI employees who left OpenAI due to “differences over the group’s direction after it took a landmark $1 billion investment from Microsoft in 2019.” In March 2025, Anthropic raised its $3.5 billion Series E at a $61.5 billion post-money valuation led by Lightspeed Venture Partners. In August 2025, Anthropic raised a $5 billion round at a $170 billion valuation led by Iconiq Capital.
Meta AI
Established in 2013, Meta AI develops the LLaMA series of open-source foundation AI models. As such, these models are in direct competition with Mistral AI’s models. In April 2025, Meta released its Llama 4 herd. In 2025, Meta announced its Superintelligence Lab focused on advancing AI and assembled a 44-person “superintelligence team”, reportedly offering salaries up to $100 million, to compete in the AI race. Meta additionally invested $14.3 billion into Scale AI, “acquihiring” Scale AI’s former CEO Alexandr Wang to lead the Superintelligence Lab as Meta’s chief AI scientist. Alongside this, Meta recruited former GitHub CEO Nat Friedman and Daniel Gross, the co-founder of Safe Superintelligence, to senior roles in Product & Applied Research, signaling an emphasis on bolstering leadership with external expertise.
Concurrently, Meta is reorganizing its AI divisions under what it calls the Meta Superintelligence Labs (MSL) structure, splitting into subgroups including research, product/applied research, infrastructure, and a “TBD Lab” focused on large-language models. There are indications that the performance of Llama-4 did not meet internal expectations, leading to the development of a successor codenamed “Behemoth”, as well as tightened oversight and expectations for AI model competitiveness. As of August 2025, Meta had also paused or frozen broader hiring in AI beyond explicitly approved roles, reflecting caution after its aggressive talent acquisition and budget outlays.
Google AI
Google has been advancing AI research since it acquired DeepMind in 2014, notably with projects like AlphaGo and the 2017 research paper "Attention is All You Need" that introduced transformer architecture. Between 2014 and 2023, Google’s AI departments were divided between Google Brain and DeepMind. In April 2023, the company consolidated these departments under the Google AI brand. In December 2023, Google AI launched Bard (rebranded to Gemini in February 2024). As of September 2025, Google’s Gemini-2.5-pro is ranked #1 on LMArena’s text and vision benchmarks.
Cohere
Cohere develops open and closed generative AI models optimized for enterprise use. It was founded in 2018 by Aidan Gomez, a former Google Brain investigator and one of the original authors of the 2017 “Attention is All You Need” paper. Its proprietary LLMs offer services like summarization, text creation, and classification to corporate clients via its API. These models are designed to be augmented with additional training data from users. Like Mistral AI, Cohere offers a chatbot assistant dubbed Coral, as well as a Cohere Embed. The company had raised $1.6 billion in total funding as of September 2025. It was valued at $6.8 billion after raising $500 million in August 2025 in a round led by Radical Ventures and Inovia Capital.
DeepSeek
In 2023, Liang Wenfeng founded DeepSeek, a spin-out of quantitative hedge fund High-Flyer, to focus on developing AGI. In December 2024 and January 2025, DeepSeek released its V3 and R1 models, respectively, which drew widespread attention for both their technical capabilities and the low cost at which they were developed. DeepSeek reported spending just $5.5 million to train V3 and $6 million for R1, representing only 6-7% of GPT-4’s estimated training cost, while still matching the capabilities of leading systems such as OpenAI’s o1. DeepSeek adopted a Mixture of Experts (MoE) technique to decrease training costs without compromising accuracy. In January 2025, DeepSeek became the most downloaded free app on both the Apple and Google Play app stores, surpassing competitors such as ChatGPT.
Business Model
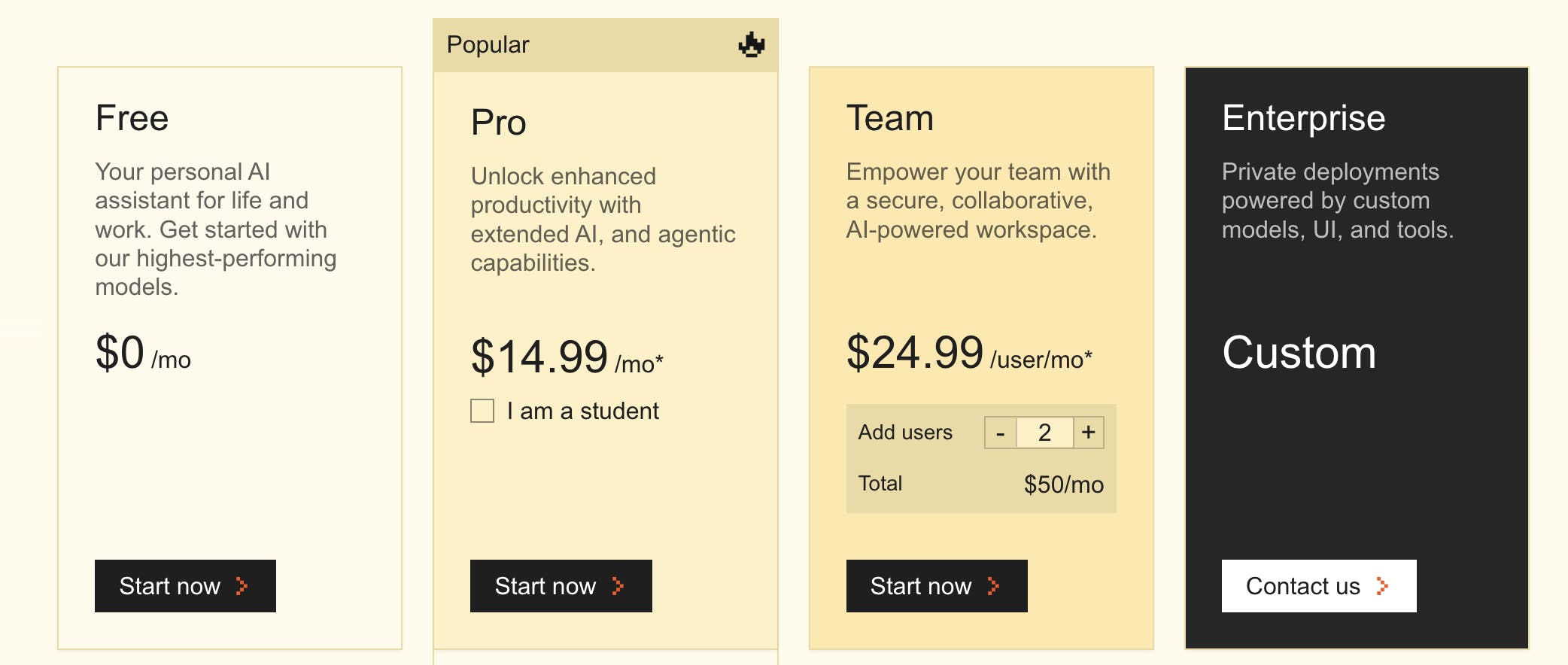
Source: Mistral AI
Mistral AI offers its open models for free through the Apache 2.0 open-source license. The company also charges via a tiered model for individual users of Le Chat, premier versions of its products using a pay-as-you-go business model for its various APIs, custom quotes for enterprise deployments and Mistral code, and customized applied AI services for enterprise customers.
Mistral offers three tiers for Le Chat, where the paid subscriptions unlock 6x more messages, 40x more images, and advanced features like AI agents plus chatbot support. API pricing is dependent on the specific models of interest and is charged per million tokens processed, for both inputs and outputs. For example, as of September 2025, Mistral Medium 3 costs $0.40 per million input tokens processed and $2.00 per million output tokens. Le Plateforme helps users track API usage and spending. Enterprise customer quotes are not publicly listed, but can include additional options such as hybrid deployment and customized pre-training.
Traction
In August 2025, it was reported that Mistral’s annual revenue was on track to exceed $100 million for the first time based on current sales. Moreover, in May 2025, Mensch said Mistral AI tripled its revenue in the last 100 days.
One way to determine the success of Mistral AI’s products, at least its open models, is through the number of downloads on Hugging Face. Several of Mistral AI’s models have been downloaded hundreds of thousands of times, including Mistral Small 24B Instruct (907K downloads as of September 2025).
Mistral AI partnered with Microsoft in February 2024 to make its open and commercial models available on Microsoft Azure. Alongside this, Microsoft invested $16.3 million into the company. In March 2024, Mistral AI partnered with Snowflake to make its models more accessible to enterprises by integrating them with Snowflake's Cortex. In September 2025, Mistral AI announced a partnership with ASML, where ASML would invest €1.3 billion in Mistral AI. The collaboration will span ASML’s product portfolio, R&D, and operations, with the aim of accelerating time to market and enhancing the performance of its lithography systems. As part of the agreement, ASML CFO Roger Dassen will join Mistral’s Strategic Committee to provide advisory input on the company’s strategy and technology development.
Valuation
As of September 2025, Mistral AI had raised a total of €2.8 billion across eight rounds from investors including ASML, Microsoft, a16z, Databricks Ventures, and Lightspeed Venture Partners. ASML’s €1.3 billion investment in September 2025 represented an 11% stake in the company, indicating a valuation of €11.8 billion.
Key Opportunities
Emerging Markets
According to the International Monetary Fund (IMF), emerging market economies represented a 53% share of the world economy on a global PPP-adjusted GDP scale as of 2013, and are expected to grow at a faster rate than developed markets. In January 2024, the IMF highlighted that AI was set to impact 40% of jobs in emerging markets and 26% of jobs in low-income countries. This indicates a substantial demand for AI technologies in these regions to fuel economic development, improve societal outcomes, and enhance competitiveness on the global stage. However, one of the biggest obstacles for emerging markets adopting AI is the technology’s cost. Moreover, most emerging markets include countries in Asia, Africa, Latin America, and parts of Eastern Europe, where English is not the native language.
Mistral AI’s models are designed to “target the performance-cost frontier”. For example, Mistral Medium 3 reportedly reaches “frontier-level performance” at 90% of the cost of Anthropic’s Claude models. Another of Mistral AI’s value propositions is its models’ multi-lingual capacity. The Mistral Small and Mistral Large models are not only fluent in English, but also in French, Italian, German, and Spanish. Moreover, the Mistral Large model outperformed the comparative model LLaMA 2 70B in French, Italian, German, and Spanish as of February 2024.
The ability to both serve international markets in their native languages and to do so at a significantly cheaper cost makes Mistral AI a prime candidate to serve emerging markets as they increasingly adopt AI. As one example, in September 2025, Mistral AI signed a partnership with The Ministry of Digital Transition and Administration Reform of Morocco in order to support “local competencies in artificial intelligence through education, applied research, and knowledge sharing.”
Efficiency Improvements
Arthur Mensch has emphasized that efficiency was a core part of the company, stating that “we want to be the most capital-efficient company in the world of AI.” In a world where training runs of AI models could cost upwards of $1 billion, there is a significant need for efficiency. Mistral designs its models to be deployable in less demanding infrastructure settings. Medium 3 is built so enterprises can self-host it on a modest cluster or run in hybrid/on-prem environments, which helps reduce infrastructure and operational inference costs.
Already, that approach has paid off in terms of Mistral AI’s ability to undercut competitor pricing on its models. Mistral Medium 3 was introduced as delivering state-of-the-art performance “at 8× lower cost” relative to many of the premium offerings on the market. It is priced at US$0.40 per million input tokens and US$2 per million output tokens, substantially below many competitors, such as Claude Sonnet 4 at $3.00.
As model costs increase, both in terms of training, inference, and data, the opportunity for Mistral AI is to leverage its purpose-built efficiency to continue to undercut competitor prices, while demonstrating cutting-edge capabilities and enterprise readiness.
Key Risks
Regulatory Concerns
Regulatory concerns, specifically EU regulation, pose a significant risk for Mistral AI. The EU's AI Act, the world's first major legislation on AI, strictly regulates general-purpose models and applies to models operating in the EU. For Mistral Large, as an example, Mistral AI will have to comply with transparency requirements and EU copyright law, which includes disclosing that the content was generated by AI, designing the model to prevent it from generating illegal content, and publishing summaries of copyrighted data used for training.
Since EU AI regulation is stricter than AI regulation in the US as of September 2025, and Mistral AI is a European company, there is a risk that the company’s development could be slowed down; Mistral AI needs to make sure it is complying with all EU regulation requirements while its competitors abroad can operate more freely. For example, in February 2024, Microsoft’s investment in Mistral AI drew regulator scrutiny; an EU AI commission spokesperson stated that the commission was “looking into agreements that have been concluded between large digital market players and generative AI developers and providers.”
Hiring Top Talent
The demand for AI and specialized tech skills in 2025 continues to far outstrip supply, creating a pronounced talent shortage. According to one report, the global demand-to-supply ratio for key AI roles is about 3.2:1, meaning there are more than three job opportunities for every qualified person to fill. In parallel, 85% of tech executives report postponing or scaling back AI projects due to an insufficient number of AI engineers.
Compensation pressures and hiring process inefficiencies further complicate attracting top talent. For example, job postings that include AI skills offer approximately 28% higher salaries (roughly US$18,000 more per year) than otherwise similar roles without AI requirements. This is even more notable in regard to the highest quality talent, with companies like Meta reportedly offering employment contracts in excess of $100 million.
The demand for AI talent everywhere, from leading AI labs to existing enterprises, will make hiring significantly more difficult for Mistral AI to not only attract but also retain top AI talent, which could slow its growth.
Summary
Mistral AI aims to shape the future of artificial intelligence by developing open-source alternatives to proprietary models created by the likes of OpenAI and Google. The company also puts emphasis on creating models that are efficient and cost-effective, coupled with a commitment to transparency and accessibility. This approach can help Mistral AI expand into markets where AI technology has not seen significant penetration, such as emerging markets. As available data and compute power grows exponentially, Mistral AI can further enhance the performance and efficiency of its AI models. However, AI regulation, particularly European AI regulation, as well as the widening gap between AI talent supply and demand, pose challenges.







