
Thesis
Companies like OpenAI at the forefront of machine learning have been pursuing reinforcement learning with human feedback (RLHF) for its large language models (LLMs) such as ChatGPT. An LLM is a large data set containing billions of words from various sources used to generate human-like responses to prompts. ChatGPT, which launched in November 2022, took just two months to reach 100 million global monthly active users, making it the fastest product of all time to reach that milestone, beating out previous record-holders like TikTok (9 months) and Instagram (30 months). LLMs are the key to the increasingly powerful generative AI chatbots like ChatGPT, Google Bard, and Bing Chat.
LLMs are data-driven prediction machines. One major challenge with the popularity of LLMs is hallucination, which occurs when they provide users with confident answers that are either factually or logically incorrect. Hallucination happens because LLMs are trained on vast amounts of third-party internet data, and sometimes the information the user needs is not in the training set. As a result, the model will give the most probable and linguistically well-formatted answers based on training data that is either stale or incomplete. The issue is underscored by the systems-level reality that LLMs are stateless during the inference stage, devoid of inherent mechanisms for integrating contextual information or recalling previous user queries. The output is generated solely based on the data and parameters included in the payload. Model fine-tuning is possible, but it is costly and inflexible. A potential solution to this problem is feeding contextually relevant data in real time to the LLMs. This necessitates the implementation of infrastructure components, such as vector databases.
Pinecone is a vector database where developers can store relevant contextual data for LLMs. Instead of constantly transferring vast sets of documents with each API call, developers can store the information in a Pinecone database and then select only the most pertinent ones for any given query — an approach known as in-context learning. Vector databases like Pinecone are specifically designed to support LLMs and machine learning models. They store vector embeddings and numerical representations of unstructured data (such as images, text, and video) in order to capture certain features. Vector embeddings enable the translation of semantic similarity into proximity in a vector space. They are well-suited for common machine learning tasks such as clustering, recommendation, and classification.
Founding Story

Source: TechCrunch
Pinecone was founded in 2019 by Dr. Edo Liberty (CEO). Liberty grew up in Israel and earned his BSc in Physics and Computer Science from Tel Aviv University before completing a Ph.D. in Computer Science at Yale University and publishing over 70 papers on algorithms and machine learning. Upon graduating from Yale, Liberty went on to become the Head of Yahoo’s Research Lab in New York, where he helped build horizontal machine learning platforms and improve applications such as online advertising, image search, semantic search, security, and media recommendation. Then, after becoming Head of Amazon AI Labs at AWS, Liberty had his first opportunity to build products for developers (instead of building for internal use at Yahoo) and led the development of services including SageMaker, Kinesis, QuickSight, and Amazon ElasticSearch.
During his time at AWS, Liberty began to develop the idea that machine learning development was being held back by the lack of access to vector databases, a type of database that powers machine learning models by storing data as high-dimensional vectors (also called vector embeddings). Vector embeddings are numerical representations of data that capture certain features and can represent many data types, including text, images, audio, time series data, 3D models, video, molecules, and more. Vector embeddings make it possible to translate semantic similarity as humans perceive to proximity in a vector space. Only large technology companies with ample resources, such as Google and Facebook, had been able to take advantage of them up until that point. Liberty decided to start Pinecone to make vector databases more broadly accessible.
Bob Wiederhold joined Pinecone full time in January 2023 to serve as President and COO. Prior to Pinecone, Wiederhold was the CEO of NoSQL database startup Couchbase, which IPO’ed at $1.2 billion in July 2021.
Product
Vector Database
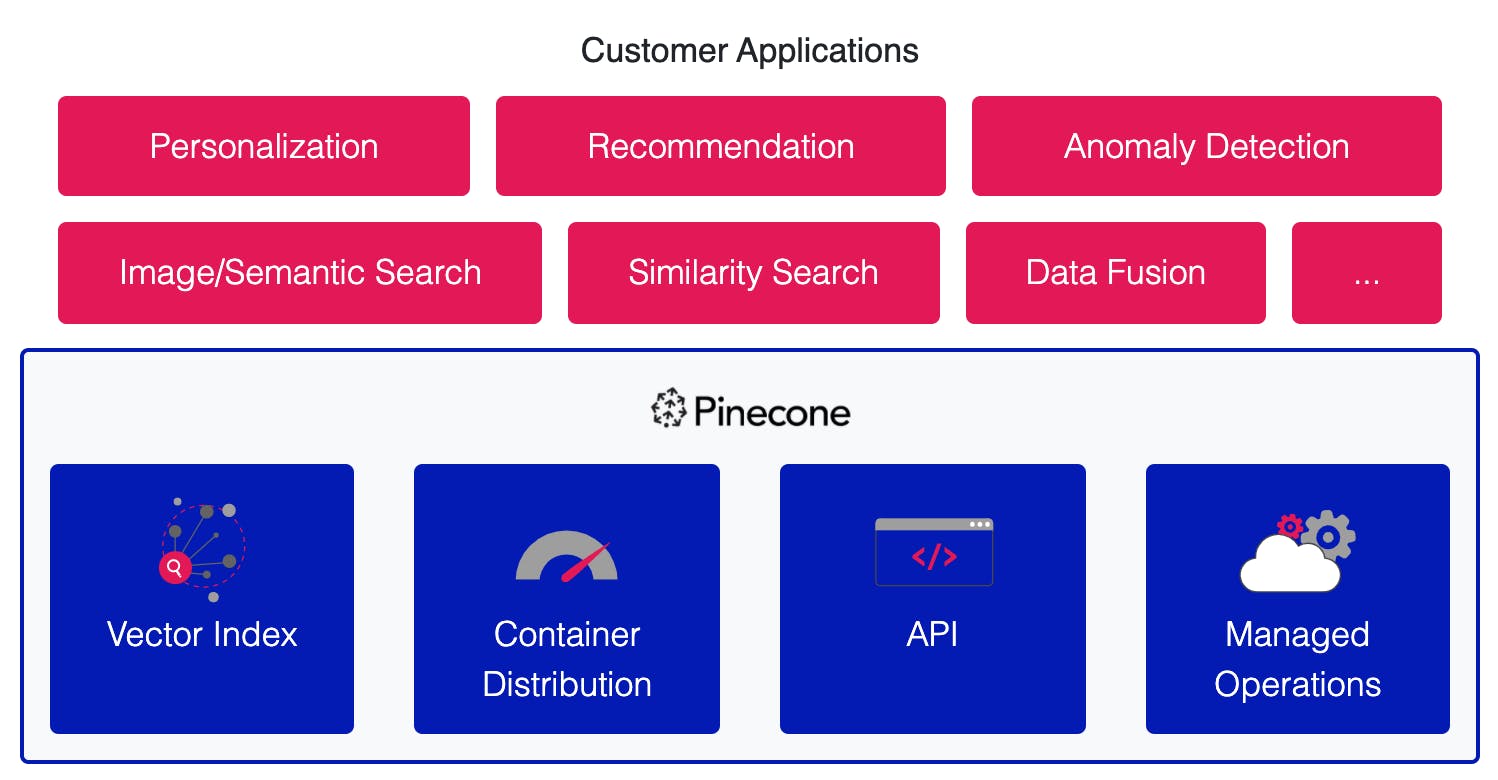
Pinecone is a managed vector database that helps developers build vector search applications with an API. Vector databases are designed to handle vector data used in machine learning applications. It allows developers to launch, use, and scale vector search service with its API without worrying about infrastructure or algorithms.
There are three components to Pinecone.
The first component is a vector engine, also known as a vector index, which translates high-dimensional vectors derived from third-party data sources into a format that can be ingested by machine learning. The engine enables users to index large amounts of high-dimensional vector data and search through them.
The second component is the container distribution mechanism which manages load balancing, replication, and name-spacing, among other tasks. It does this while maintaining latencies under 50 milliseconds for queries, updates, and embeddings.
The final component is a fully-automated cloud management layer that allows users to manage workflows and data transfers between source locations.
Pinecone is SOC 2 Type II certified and GDPR-ready. Developers do not need to maintain infrastructure, monitor services, or troubleshoot algorithms. They can start free, then pay only for what they use with usage-based pricing.
Source: Pinecone
Vector vs. Traditional Database
Historically, business data management has been underpinned by traditional databases: either relational databases like MySQL, PostgreSQL, and Oracle; or NoSQL databases, such as MongoDB and Cassandra. Using common programming languages, these systems simplify data querying and manipulation through their ability to house and sort data into structured formats, such as tables, documents, or key-value pairs.
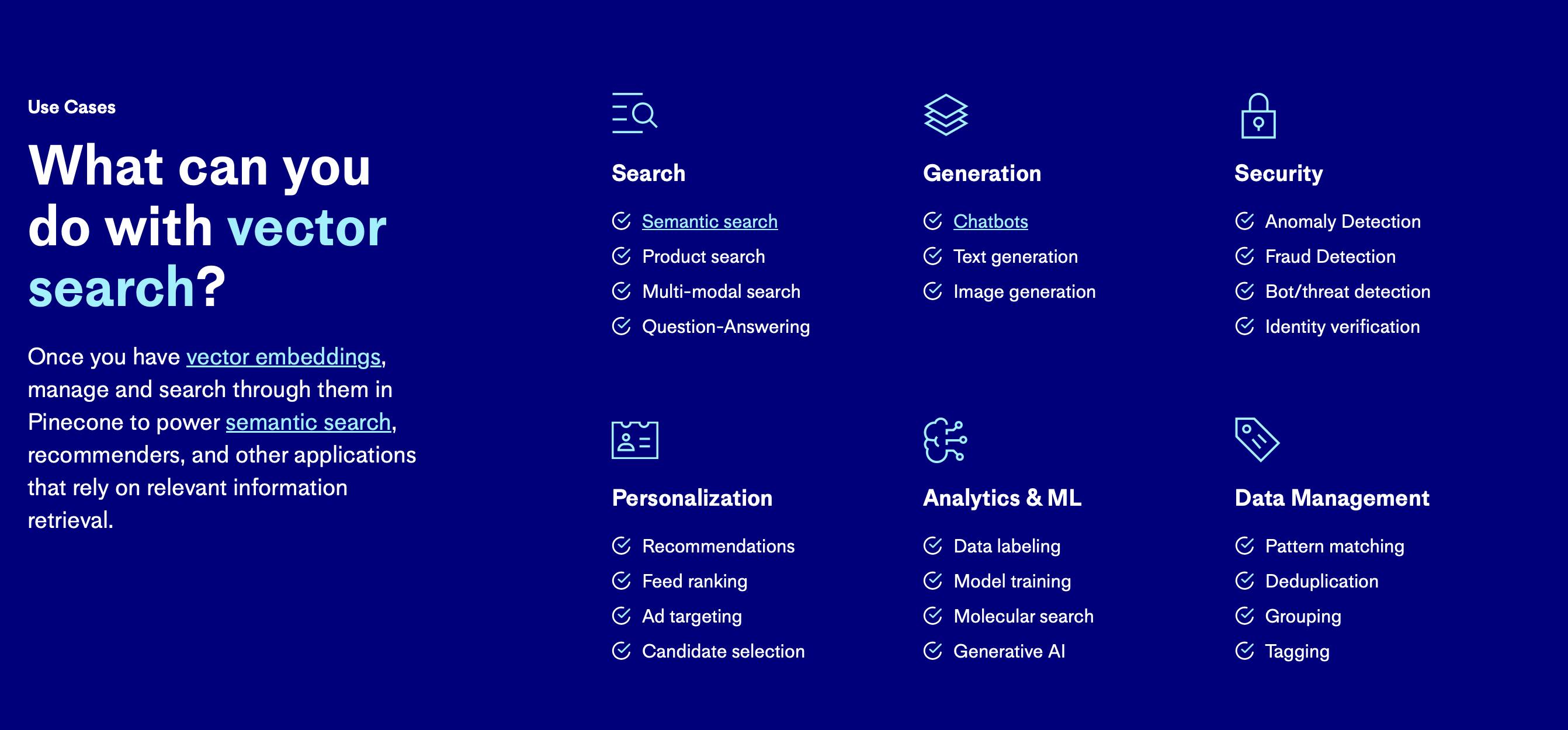
While traditional databases excel at managing structured, fixed-schema data, they often struggle with unstructured or high-dimensional data types such as images, audio, and text. A new era in data storage and retrieval has been ushered in by vector databases, which eliminate reliance on structured formats and store and index data as mathematical vectors in high-dimensional space. This process, referred to as "vectorization," enables more efficient similarity searches and improved management of intricate data types such as images, audio, video, and natural language.
Vector databases excel in their ability to quickly execute approximate nearest neighbor (ANN) searches, identifying similar items within large datasets. By using techniques such as dimensionality reduction and indexing algorithms, these databases can perform searches on a large scale, providing fast responses. As a result, they have become the technological foundation for LLMs and artificial intelligence due to their impressive speed and scalability.
Source: Pinecone
Market
Customer
Pinecone serves a diverse range of customers, from startups to Fortune 500 companies. These customers include small teams storing a few thousand vectors to large enterprises storing 50+ billion vectors. Notable customers include Shopify, Hubspot, Zapier, and Gong, among others.
Customers can use Pinecone’s API to store and query the vectors generated by their own models and build AI-powered applications powered by their own proprietary data. Customers can also leverage Pinecone’s API and AI models (such as OpenAI) to build a retrieval-enhanced generative question-answering system.
For instance, customers can take language, text, documents, paragraphs, or search queries and pass them through OpenAI’s models, get embeddings, store those embeddings in Pinecone, then query those by similarity, relevance, etc. Instead of using a traditional keyword search for an answer, they could use Pinecone to retrieve the most relevant semantic answers and then use generative AI models to synthesize the results into one answer.
Market Size
It is estimated that up to 80% of generated data will be unstructured by 2025. Unstructured data already accounted for 80% of the world’s enterprise data in February 2023 and is estimated to grow at 55-65% annually, outpacing the growth of structured data, which is estimated to grow at 12% annually.
Vector databases like Pinecone are designed to store, index, and retrieve high-dimensional vectors and unlock value from unstructured data, making them an ideal choice for various machine-learning applications, including image and text classification, recommendation systems, and anomaly detection. As such, the size and growth of Pinecone’s addressable market are tied to the size and growth of its applications:
The image recognition market is set to be worth $109.4 billion by 2027.
The recommendation engine market was worth $2.1 billion in 2020 and is set to reach $15.1 billion by 2026.
The chatbot market was worth $2.9 billion in 2020 and is set to be $10.5 billion by 2026
The global database software market is estimated to grow from $85.7 billion in 2020 to $189.2 billion in 2030.
Competition
Redis Labs: Redis Labs sponsors the open-source database Redis and is the commercial provider of Redis Enterprise, a real-time data platform. Redis was founded in 2011 and has raised $356.8 million from investors including Bain Capital Ventures, TCV, Francisco Partners, Tiger Global Management, and SoftBank. It raised a Series G round in 2021 valuing it at over $2 billion. Redis is a key-value cache server that can store a mapping of keys to values, while Pinecone is a vector search engine specifically designed for machine learning and aimed at data scientists. Redis Labs released its vector database solution through its Vector Similarity Search capability in 2022. Like Pinecone, it allows developers to retrieve information based on audio, natural language, images, video clips, voice recordings, and other data types.
Qdrant: Qdrant is an open-source vector database and vector similarity search engine written in Rust. Qdrant provides vector similarity search services with an API to store, index, and manage massive embedding vectors. It was founded in 2021 and has raised $9.8 million from investors like Amr Awadallah (co-founder and ex-CTO of Cloudera). While Qdrant is open-sourced, it does not offer a free tier for its managed cloud services, unlike Pinecone. In April 2023, it launched its managed cloud offering to help developers through one-click deployments, automated version upgrades, and backups.
Chroma: Founded in 2022, Chroma is an open-source embedding database. It lets developers add state and memory to their AI-enabled applications. Developers use Chroma to give LLMs pluggable knowledge and prevent hallucinations. It has raised $20 million in funding.
Weaviate: Weaviate is an open-source vector search engine that enables users to scale their machine-learning models. It stores both objects and vectors, allowing for the combination of vector search with structured filtering. In addition, it offers the fault tolerance and scalability of a cloud-native database. It can be accessed through GraphQL, REST, and various language clients.
Weaviate was founded in 2019 and has raised $67.7 million from investors including New Enterprise Associates, Battery Ventures, and Index Ventures. Though users can access the open-source project for Weaviate, it does not provide users with a free tier of its managed service, unlike Pinecone. In addition, while Pinecone may, according to some users, have an advantage over Weaviate in terms of ease of setup and support, Weaviate has an advantage in cost.
Zilliz: Milvus is an open-source vector database developed and maintained by Zilliz. Since its founding in 2017, Zilliz has raised $113 million in funding. While Milvus is an open-source project that users can access for free, Zilliz offers a fully-managed cloud version of the platform for a cost. In contrast to Pinecone’s approach of offering a free tier, Zilliz offers only a 30-day free trial. Zilliz has over one thousand enterprise customers, including Walmart, Nvidia, Tencent, Intuit, and eBay.
Business Model
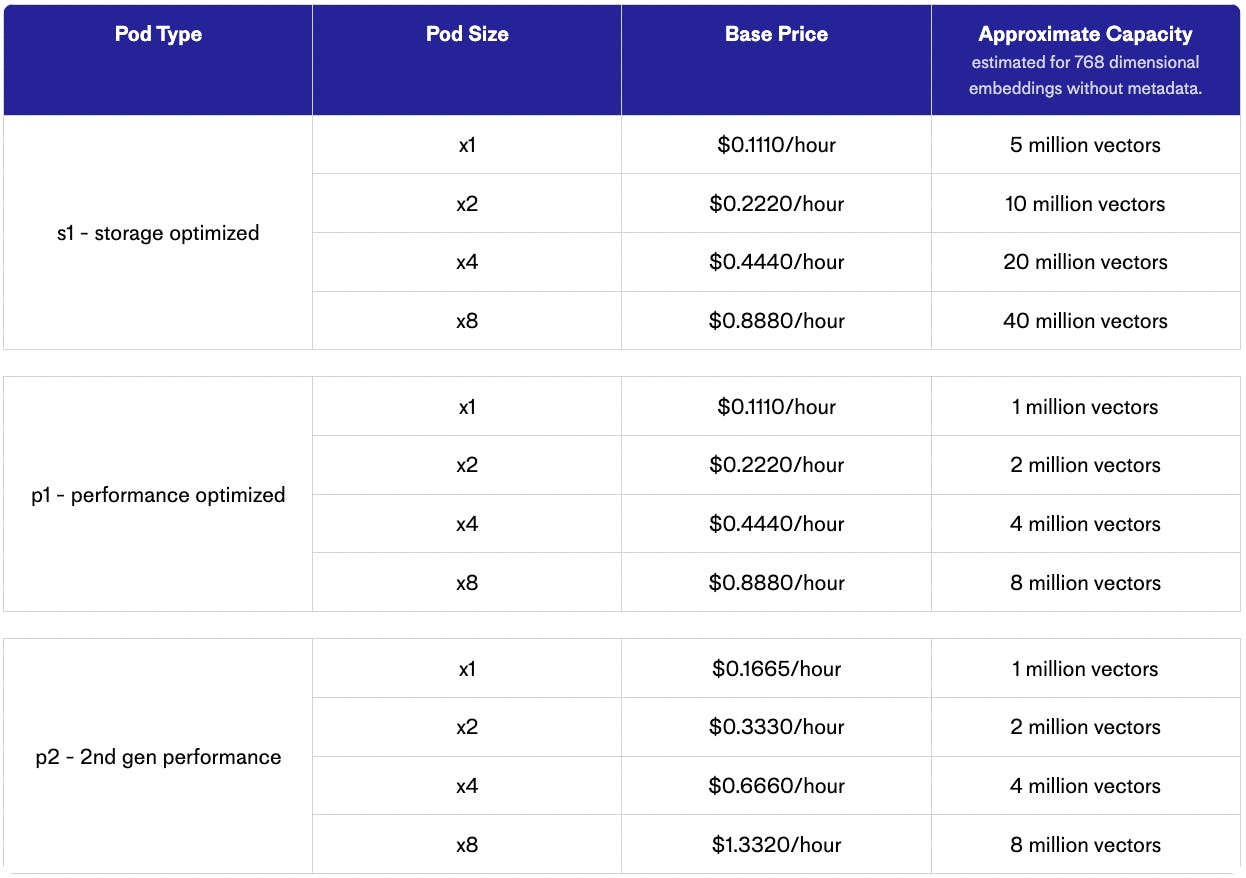
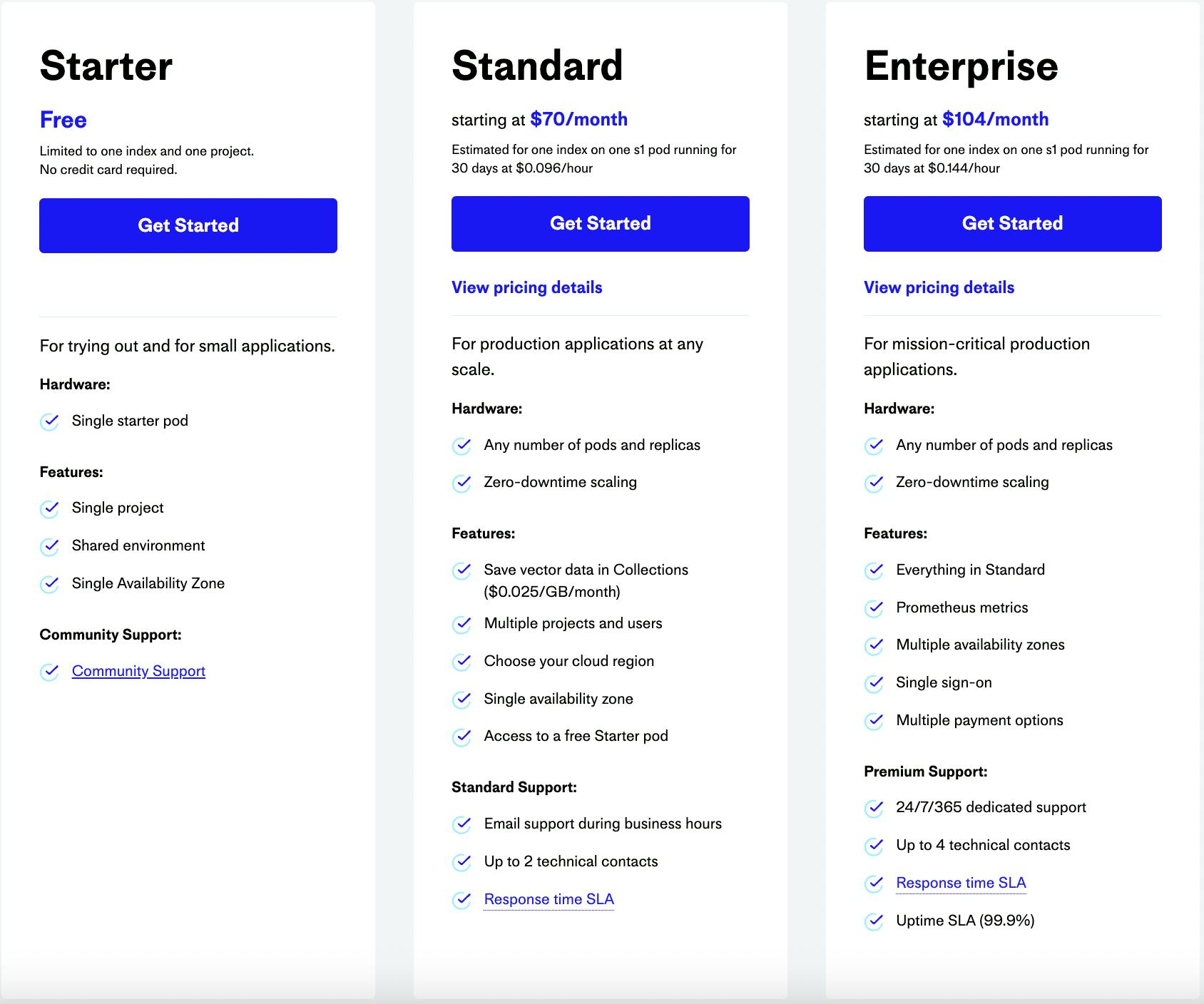
Pinecone's business model is based on providing a fully-managed vector database that developers can use to build applications that require vector search, recommendation systems, and more. Pinecone employs usage-based pricing and offers three pricing plans — Free, Standard, and Enterprise — based on the number of vectors and pod sizes users use.
Pods are units of cloud resources (vCPU, RAM, disk) that provide storage and compute for each index. Pinecone offers users different pod sizes for users to choose from based on their needs.
Source: Pinecone
Pinecone’s free “starter” plan is limited to one index and one project, designed to help users try out the product with small applications.
The standard plan is priced at $70 per month. It allows users to use any number of pods and replicas (adding pods increases the capacity and throughput for an index while adding replicas increases only the throughput). The standard plan provides users with zero-downtime scaling, multiple projects and users, the ability to choose their cloud region, access to a free Starter pod, and standard customer support.
Lastly, the enterprise plan is priced at $104 per month. On top of offerings under the Standard plan, the Enterprise plan provides multiple availability zones, single sign-on, multiple payment options, and premium customer support.
Source: Pinecone
Traction
In February 2023, Pinecone announced that thousands of developers were building on its free start plan and over 200 paying customers had chosen Pinecone to power their large-scale AI applications, including companies such as Shopify, Gong, Zapier, Workday, BambooHR, and Hubspot. The company also said it reached millions of dollars in annual recurring revenue in February 2023. An unverified source estimates Pinecone’s annual revenue to be around $7.1 million in May 2023.
Valuation
Pinecone has raised a total of $138 million in funding, including a $100 million Series B in April 2023 that valued the company at $750 million. In addition to being backed by venture capital firms such as Andreeson Horowitz, Wing Venture Capital, Menlo Ventures, ICONIQ, and Tiger Global Management, Pinecone is also backed by industry veterans such as Bob Muglia (former CEO of Snowflake) and Yury Malkov (inventor of the Hierarchical Navigable Small Worlds algorithm).
As of May 2023, public database companies such as MongoDB and Elastic had enterprise revenue multiples of 13.9x and 5.3x, respectively. Assuming $7 million in ARR, Pinecone's last valuation gave it a 21x multiple.
Key Opportunities
Fast-Growing Applications
The market for vector databases has the potential for rapid growth. The low-latency vector search they enable powers several applications, such as image recognition, text analytics, recommendation engines, anomaly detection, and chatbots, each with substantial fast-growing markets. Image recognition, poised to be a $109.4 billion market by 2027, finds wide-ranging uses across security and surveillance, medical imaging, visual geolocation, facial or object recognition, barcode reading, gaming, social networking, and e-commerce. The text analytics market, valued at $5.8 billion in 2020, is set to reach $29.4 billion in 2030. The recommendation engine market, worth $4.1 billion in 2023, is set to reach $21.6 billion by 2026. The anomaly detection market is set to be worth $8.6 billion by 2026. The chatbot market, valued at $5.4 billion in 2023, is estimated to reach $15.5 billion by 2028.
An Explosion of Unstructured Data
Machine learning models can unlock the power of unstructured data by re-structuring them as vectors and enabling increased storage of unstructured data. Unstructured data already accounts for 80% of the world’s enterprise data and is estimated to grow at 55-65% annually, outpacing structured data, which is estimated to grow at 12% annually. Pinecone is well-positioned to capitalize on this tailwind.
Vertical Expansion
Vector databases sit at a critical point in the machine learning toolchain. Any company that secures a substantial customer base in this domain is strategically placed to broaden its offerings along this pipeline. For instance, it's plausible to envision a future where Pinecone starts providing a model hosting service, thereby overseeing the complete vector data processing. There's even potential for Pinecone to branch out into the online analytical processing database market, positioning itself as the Snowflake or Databricks for unstructured data.
Key Risks
Threat from Cloud Giants
The success of Pinecone has drawn the attention of cloud industry leaders such as AWS and Google Cloud. Google Cloud, in particular, launched its own vector search solution in 2021. Such companies are monetizing their offerings by integrating them into their existing infrastructure platforms. With a reach extending to over 5.2 million business customers, AWS (3.2 million) and Google Cloud (2 million) are well-positioned to promote their own solutions like AWS OpenSearch and Google Vertex Matching Engine. As one industry insider stated:
“I think the risk is something like AWS squeezes the market where people are like, ‘We like Pinecone, but now I need to try the AWS thing, because I've got to spend all my AWS credits. I've got AWS credits I've got to use”.
New Entrants from Adjacent Spaces
The surge in popularity of AI and LLMs has prompted technology companies to think about how they can position themselves to capture the wave. With strong existing adjacencies, database companies such as Elastic and MongoDB are positioned to build competing vector database offerings. Furthermore, as seen from Snowflake’s Neeva acquisition, companies may also consider M&A to enter the fast-burgeoning space.
Vertical Integration
A potential risk that vector database companies such as Pinecone face is vertical integration from artificial intelligence companies such as OpenAI and Cohere. Players such as Cohere may decide to build vector databases in-house and combine embeddings and vector search into one single API.
Summary
Pinecone, a vector database, offers a solution to “hallucinations”, which is when LLMs provide confident but factually incorrect answers. Developers can store contextual data for LLMs in Pinecone, selecting only the most relevant information for each query using "in-context learning". Pinecone’s managed vector database allows customers to store and query the vectors produced by their own models, enabling the creation of AI-powered applications based on proprietary data. Pinecone serves various customers, from emerging startups to Fortune 500 companies. Its client list includes names like Shopify, Hubspot, Zapier, and Gong.



