
When an obscure Chinese startup, DeepSeek, released its R1 model on January 20th, 2025, it stunned the world with performance that matched top-tier systems like OpenAI’s o1, supposedly at just 6-7% of the cost. Just seven days later, DeepSeek overtook ChatGPT as the most-downloaded free app on the iOS App Store in the US and caused a trillion-dollar wipeout in US equity markets in a single day.
DeepSeek’s feat was achieved amid an ongoing AI “arms race” between the US and China. The US, taking an industry-led and compute-focused approach, had bet on winning the race by amassing powerful compute resources (like NVIDIA’s H100 chips) and investing heavily in frontier model development. But DeepSeek’s arrival contested this model by supposedly using fewer chips and much smaller budgets to achieve the same results. American experts, who once deemed China to be at least several years behind the US in AI development, were spooked by a looming possibility: China may be closing the gap with the US in its AI development with a much more efficient and cost-effective ecosystem.
The reality, however, is much more nuanced than the narrative that China’s AI ecosystem is “winning”. While DeepSeek’s R1 model did mark an important leap in model development, it isn’t as clear why that happened as DeepSeek would like the world to believe. In addition, the broader political environment and development infrastructure in China may hinder accelerated progress into the future.
Two Different Approaches
The US Approach: Capital Markets-Driven & Compute-Rich
The US approach can best be characterized by a dynamic, capital markets-driven model of development. Private companies and investors dominate AI funding in the US, which has led to agile allocation of resources and rapid scaling of infrastructure to meet demand.
The compute required by US companies for training AI models has far outpaced traditional expectations. But the US AI ecosystem has been able to keep up with its exponential progress. For example, since 2012, the compute used for top AI training runs has grown roughly 300K times (doubling about every 3.4 months), far outpacing Moore’s Law’s two-year doubling benchmark. Public data confirms OpenAI’s data center clusters have reached 100K GPUs, with plans to exceed 300K by the end of 2025, reflecting its aggressive infrastructure expansion. While rival companies compete for the most capable model, they are also surprisingly willing to share key compute resources. One June 2025 report showed OpenAI onboarding Google Cloud TPUs, reducing reliance on Nvidia GPUs alone.
Private investment has also kept up with exponential scale-up in compute demands. Private investment in the US across AI reached $109 billion in 2024, nearly 12 times the amount invested in China. If the Stargate initiative, announced in January 2025, comes to fruition, it would see OpenAI deploy $500 billion over the next four years to build new AI infrastructure. The SoftBank, Oracle, and MGX-backed effort is set to increase the US’s almost two-thirds hold of the world’s total AI computing capacity. Thanks to an abundance of capital and greater total compute capacity, the US can support a diverse ecosystem of leading AI companies and iterate on more experiments. For instance, US institutions such as Google, Meta, and OpenAI produced 40 notable AI models in 2024, far surpassing China’s 15. Going forward, the US’ compute dominance means American labs can train multiple frontier models in parallel and deploy AI services at scale. In contrast, China will need to be more selective with its resources, which theoretically will result in slower innovation.
Outside of compute dominance, the US ecosystem’s greatest strength is perhaps how effectively market forces align investments with real-world needs. Because most American AI development is driven by private-sector incentives, resources like cloud data centers and chip supplies tend to expand (or contract) in response to actual demand signals. For example, CoreWeave and Core Scientific, both former bitcoin mining companies, pivoted to AI cloud computing as demand for vast computing power and large data centers soared. This responsive scaling helps avoid severe overcapacity or idle hardware. Furthermore, the US’s vibrant open-source AI community (exemplified by tools like PyTorch and HuggingFace) creates tools that lower implementation and maintenance costs and accelerate time to value from proprietary AI tools. Overall, the American model can be summarized as well-resourced and optimized: a combination of abundant compute, top talent, private capital, and supportive infrastructure that together maintain the country’s edge in AI development.
The Chinese Approach: State-Led Ambition & Hurdles
In China’s AI ecosystem, the state plays a much more prominent role in setting priorities and steering investments. Since 2017, Beijing has declared AI a national strategic priority, and government directives and funding have spurred a rush of activity across the country.
This top-down drive has its advantages. For instance, China has rapidly built up AI research programs that have led globally in the number of AI research publications and patents in recent years. By 2023, China accounted for nearly 70% of all AI patent filings globally and accounted for 47% of the world's top AI researchers as of May 2025, reflecting an enormous push in R&D and potential for intellectual property generation. This suggests that China’s AI research community may help keep pace, despite being under-resourced relative to the US.
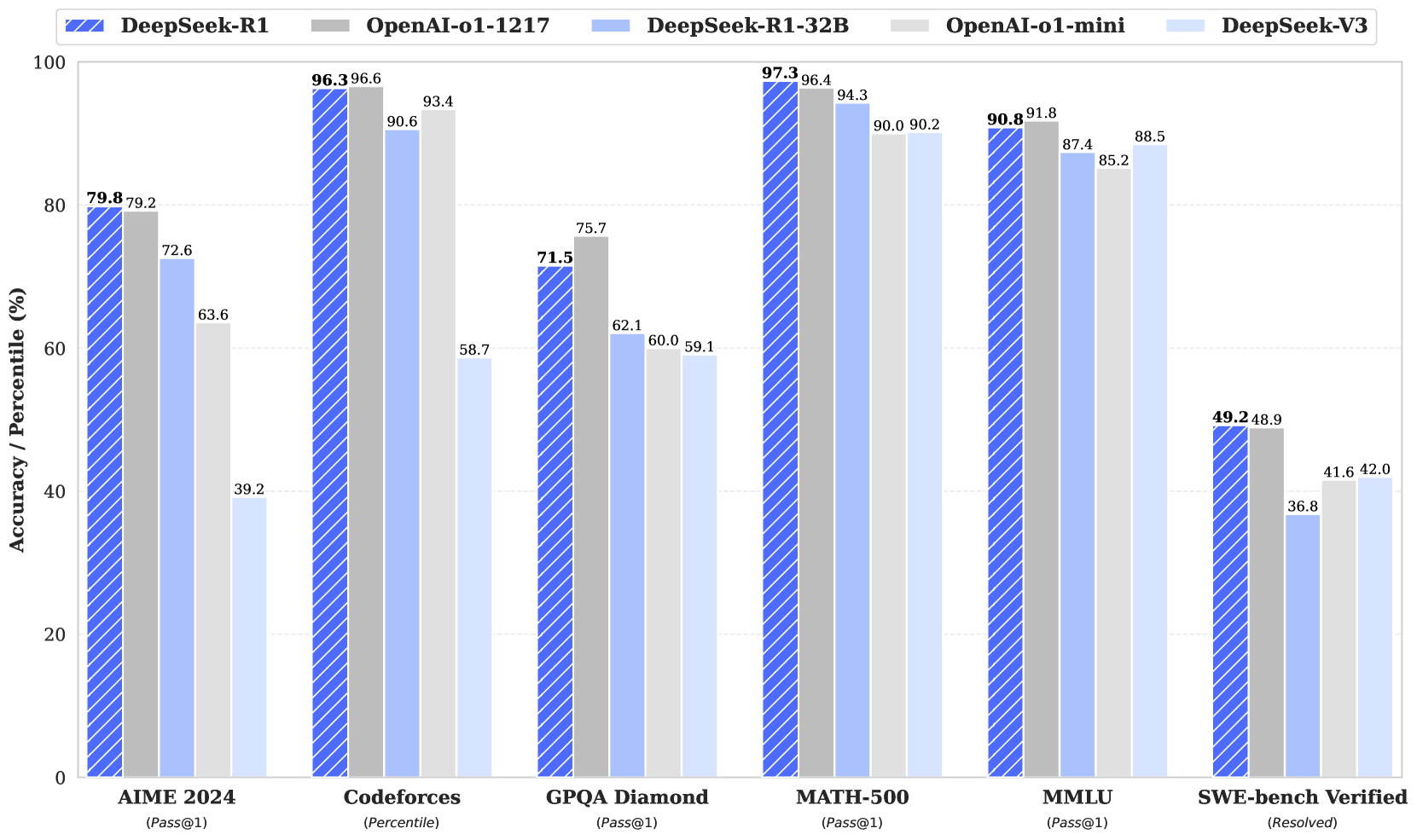
DeepSeek exemplifies the strength of Chinese AI talent to overcome geopolitical challenges and drive innovation. The company published five major papers on arXiv between 2024 and 2025, involving 223 authors. The team’s academic credentials are impressive; on average, each DeepSeek researcher has published 61 works and received over 1K citations, while the core group of 31 researchers who contributed to all five papers on arXiv boasts an average of 1.5K citations per author and a median h-index of 10; a metric used to evaluate the significance of a scientist’s or scholar’s research output. This compares favorably to OpenAI’s o1 team, which had a median h-index of only 6. Notably, more than half of DeepSeek’s AI researchers were trained exclusively at top Chinese universities such as Tsinghua, Peking, and Nanjing.
As a result of the team’s strength in research, DeepSeek was able to bypass strict export sanctions that limit access to cutting-edge chips and develop models with comparable performance to US state-of-the-art models (SOTA). In one cornerstone approach, the company used a Mixture-of-Experts (MoE) architecture. Instead of activating every part of a large neural network for each query (like using your whole brain for every single thought), MoE partitions the model into smaller specialist expert modules, and only the relevant experts are engaged to answer a given question. The result is a model that conserves resources, slashing both training and inference costs without sacrificing capability.
In fact, MoE supposedly allowed DeepSeek to train enormous models with far fewer chips. DeepSeek’s team claims they needed only about 2K GPUs to train their V3 model, compared to 16K normally used by leading AI companies. In another key approach, DeepSeek relied on reinforcement learning (RL) to train its R1-Zero reasoning model, foregoing the costly supervised fine-tuning (SFT) phase entirely while achieving results comparable to SOTA models from US companies. DeepSeek’s efficiency-focused approach, which yielded surprising leaps in model performance, underscores the successful parts of China’s top-down approach.
Source: arXiv
The less successful areas of China’s approach are seen in its state-directed AI investment strategy, which faces growing pains and inefficiencies stemming from inexperienced operators and short-sighted goals. In the rush to lead in AI, industry associations revealed that the country had overbuilt its computing infrastructure, resulting in vast underutilized capacity. For instance, at least 150 data centers were completed by the end of 2024, yet up to 80% of these resources went unused. Instead, these facilities turned into distressed assets, with investors trying to offload them below market rates. In effect, massive data halls full of servers are running at half capacity or less, as the anticipated flood of AI workloads has yet to materialize.
The root cause is that many projects were approved with little regard for actual demand or technical feasibility. The race for project approval was driven by hype and political pressure rather than market needs. While China's AI boom initially saw over 144 companies register with the Cyberspace Administration of China to develop large language models in 2024 alone, the frenzy quickly lost momentum, with only about 10% still actively investing in large-scale model training by the end of 2024. After DeepSeek released its cost-effective R1 model that didn’t rely on compute-intensive pretraining, many smaller players have given up on pretraining their models or otherwise shifting their strategy, while only a few top tech companies in China are still drawing heavily on computing power to train their AI models. Thus, Chinese authorities have not only failed to anticipate this shift in the landscape towards more affordable data centers, but their pattern of misalignment in data center supply also reflects China’s highly centralized political system. In this system, local officials prioritize short-term, high-profile infrastructure projects to advance their careers rather than focusing on long-term development.
The post-pandemic economic downturn intensified this dynamic as officials scrambled for alternative growth drivers after the real estate sector, which had been the backbone of local economies, slumped for the first time in decades. In this vacuum, AI infrastructure became the new stimulus of choice. By 2023, major corporations with little prior AI experience, including unlikely players like Lotus (an MSG manufacturer) and Jinlun Technology (a textile firm), began partnering with local governments to capitalize on the trend, often viewing AI infrastructure as a way to justify business expansion or boost stock prices. This gold-rush approach created a push to build AI data centers with little regard for practical use, led by executives and investors with limited AI infrastructure expertise who, in their rush to keep up, constructed projects hastily that fell short of industry standards.
The final hurdle for China’s AI ecosystem is a relative weakness in foundational software and toolchains. Despite its aspirations for tech self-reliance, China remains heavily reliant on US-based AI frameworks and platforms for its development work. As of 2019, most Chinese AI labs still use open-source tools like TensorFlow (Google) or PyTorch (Meta) as the backbone for model training, since domestic alternatives are few and less mature. As one expert points out, it’s hard to claim true AI leadership if your core software stack is dominated by another country’s ecosystem. This reliance raises questions about how China can insulate its AI efforts from external control, especially in light of sanctions, which could become a bottleneck if geopolitics shifts.
What’s The Verdict?
Distinct Advantages
The US-China AI race has entered a new phase where both ecosystems demonstrate distinct competitive advantages that may coexist rather than converge. The US maintains a commanding lead in compute capacity, controlling approximately two-thirds of global AI compute, which translates into a superior ability to deploy AI applications at scale. However, China's breakthrough with DeepSeek R1 and V3 in January 2025 fundamentally challenged assumptions about the relationship between compute resources and AI capability.
This divergence suggests a nuanced competitive landscape: the US compute advantage does enable better distribution of AI applications, with companies like Meta reaching 600 million monthly active AI users as of December 2024 and Microsoft's Azure AI serving more than 70K enterprises as of May 2025. Yet China's efficiency innovations raise difficult questions about whether raw compute supremacy guarantees long-term dominance. The critical uncertainty centers on whether China can develop chipmakers to rival Nvidia, where some reports claim that China’s most advanced chip, Huawei's Ascend 910B, is already less than one generation behind Nvidia’s H20 series chips.
Talent also flows increasingly in favor of China's ecosystem, with nearly one in two top AI researchers globally coming from China as of April 2024, and increasing numbers choosing to remain rather than emigrate. The US retains quality advantages, producing 90% more top AI PhD researchers than China as of January 2025, but faces growing challenges from restrictive immigration policies.
The Inference Revolution
The AI industry's pivot from training to inference optimization represents a fundamental shift that favors distributed architectures over centralized GPU clusters. Unlike training workloads requiring tightly coupled systems, inference can be geographically distributed, enabling sub-10ms response times through edge processing while reducing bandwidth costs.
This architectural evolution particularly benefits China's approach, as inference workloads are less dependent on cutting-edge chips, where US export controls are the most stringent. As a result, specialized inference hardware has emerged as a critical battleground. For instance, following Deepseek R1’s success, Chinese tech companies flocked to purchase H20 chips from Nvidia, causing Nvidia to receive scrutiny. H20 chips, despite being export-restricted versions, were widely sold in China. In some use cases, these chips proved capable of delivering 20% better inference performance than H100s. And Nvidia seems determined to sell more export-control versions of its leading chips to China despite pushback.
Economic optimization also drives this transformation through dramatic cost reductions: inference costs plummeted from $60 per million tokens in 2021 to $0.06 in 2025. In other words, the cost of LLM inference has dropped by a factor of 1K in three years. This commoditization of AI inference enables new applications previously considered economically unviable, while forcing both US and Chinese companies to compete on efficiency and distribution rather than pure performance.
Coexistence Through Specialization
The most likely scenario involves both ecosystems maintaining competitive capabilities while specializing in different strengths. The US is expected to continue to dominate frontier model development through its compute advantage and integrated ecosystem (from Nvidia hardware to application deployment), while China excels in efficiency innovation, cost-effective deployment, and serving markets where US technology faces restrictions.
The inference optimization trend fundamentally alters competitive dynamics by reducing dependency on cutting-edge training infrastructure, where the US maintains its greatest advantage. As specialized inference hardware proliferates and costs continue plummeting, success will increasingly depend on deployment effectiveness and market access rather than raw computational power.
Thus, three critical uncertainties will shape this evolution: whether China's efficiency innovations can overcome semiconductor limitations to achieve genuine training capability parity, whether the US can maintain talent and innovation advantages amid immigration restrictions and market maturation, and whether one type of state or industry-directed AI development proves to be more prudent than the other.
The Implications
The US-China AI competition has evolved from a simple race for technological supremacy into a complex ecosystem rivalry where different approaches may coexist and even complement each other. For now. While the US maintains overall leadership, China's rapid progress ensures continued competitive pressure that ultimately benefits global AI advancement. But this particular competition has much broader implications for the broader global order.
From increased Chinese aggression towards Taiwan to Chinese support for Russia against Ukraine and financial support of Iran, it is clear that the geopolitical aims of the US and China are increasingly at odds. If a global conflict between the US and China were to occur, the outlook would not be optimistic for the US. Since 2017, the RAND Corporation has been saying that “US forces could, under plausible assumptions, lose the next war they are called upon to fight.” Meanwhile, China has become a formidable opponent. Chinese companies represent 80% of the commercial drone market, 536 times more shipbuilding capacity than the US, ~33% of global manufacturing; what’s more, China is willing to leverage that industrial power to achieve its goals.
But AI is the critical lynchpin in any potential conflict. Salt, tea, oil, and even nuclear capabilities have all sparked their fair share of conflicts throughout history. But AI represents a fundamentally self-reinforcing capability. In other words, whoever has the most capable AI is likely the most capable of using that AI to continue to stay ahead. The race to demonstrate AI superiority is far from won. But the result of that race won’t just be who has the fastest chatbots or most personalized ads. It could potentially dictate the future world order.


