Thesis
As AI usage has become more prevalent across enterprises, natural language processing (NLP) for business tasks and communication with users has become increasingly important. While the relevance of the technology has exploded, it has historically remained somewhat inaccessible. Hugging Face is focused on improving accessibility to natural language processing research and models for enterprise use.
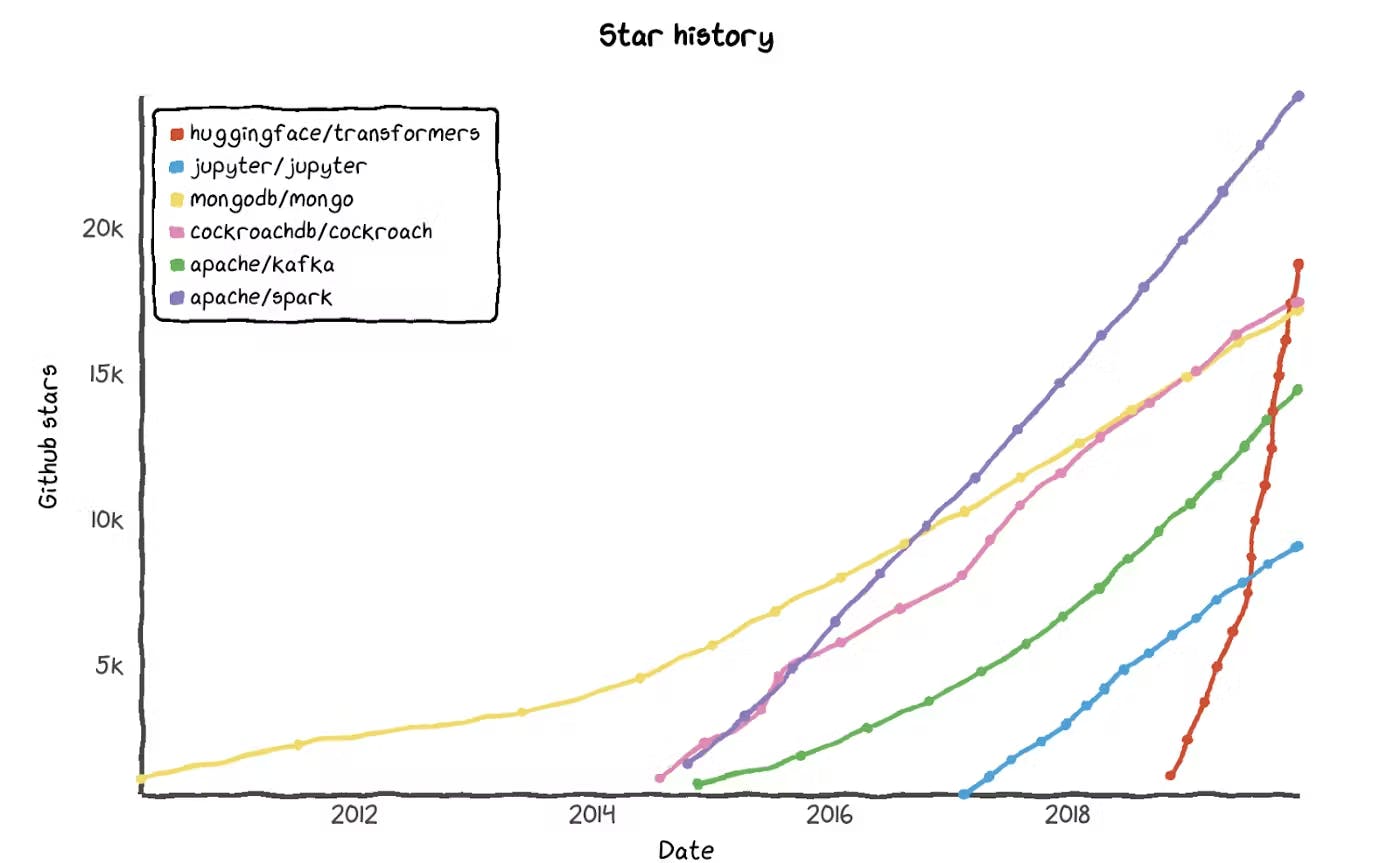
Hugging Face is an open-source hosting platform for NLP and other machine learning domains, such as computer vision and reinforcement learning. Large tech companies, such as Google, Facebook, and Microsoft, were traditionally the only commercial teams developing and using large NLP models due to the high cost and processing resources they require. For example, Grok 4 by xAI, which was released in July 2025, took $490 million to train.
Hugging Face is working to democratize the use of NLP models by making them accessible to everyone. They are reproducing and distributing pre-trained models as open-source software. In addition to its NLP ambitions, the company aims to become the GitHub of machine learning: Hugging Face is creating a repository for machine learning and a marketplace for researchers, data scientists, and engineers to share and exchange their work. The company’s mission is to “democratize good machine learning and maximize its positive impact across industries and society.”
Founding Story
Hugging Face was founded in 2016 in New York City by Clément Delangue (CEO), Julien Chaumond (CTO), and Thomas Wolf (CSO). According to Chaumond, he had known Delangue previously, and Wolf was an old friend from engineering school.
Before Hugging Face came together, its founders had already taken very different paths through the tech and research world. Delangue spent the early part of his career at Moodstocks working on product before moving through a series of roles at young startups, all of which were eventually acquired. By 2016, he was looking for a chance to build something new. Around that time, he reconnected with Chaumond, a close friend with a deep technical background who had been working as an engineer within France’s Ministry of Economy.
The two enrolled in an online Stanford engineering course and organized a large study group to work through the material. One of the participants was Thomas Wolf, a former academic researcher who had shifted into patent law (and also knew Chaumond through a band they played in together). By the end of the course, the three had agreed to start building a company together.
The original concept was a mobile chatbot aimed at teenagers: an “AI best friend” designed for entertainment and casual emotional interaction. The app used early in-house NLP models to make the bot conversational and expressive. The team chose the hugging-face emoji as the company name and brand to reflect the chatbot’s tone and target audience.
A key turning point came in late 2018, when Google released a new language model called Bidirectional Encoder Representations from Transformers (BERT). The Hugging Face team rapidly produced and open-sourced a PyTorch implementation of BERT within a week. Chaumond has said that this moment clarified the company’s direction and led Hugging Face to formalize its pivot in 2019 away from the consumer chatbot and toward building open-source machine learning infrastructure.
After developing their initial chatbot idea, the founders participated in the Betaworks accelerator, which provided early seed funding and helped the company establish a US presence. By 2019, Hugging Face had fully transitioned into the role it is now widely known for: an open-source AI platform providing model libraries, tooling, and infrastructure. The chatbot was discontinued, but it served as the technical foundation that led the founders to the company’s real opportunity.
Product
Transformers Library
In 2017, researchers at Google and the University of Toronto released a groundbreaking paper introducing a new artificial intelligence architecture called “transformers.” Transformers are artificial intelligence language analysis attention mechanisms that take into account the relationship between all the words in a sentence and can rank the importance of elements within sentences.
By ranking each element, transformers can efficiently interpret complex and ambiguous elements of a sentence much faster than traditional sequential NLP models. The unique architecture of transformers makes use of the parallel processing units found in GPUs for NLP training applications. Not all NLP training models use GPUs, but their fit to the model architecture of NLPs makes them a favorite for that purpose.
Companies like Google, Facebook, and OpenAI have all built large language models (LLMs) like BERT, ROBERTa, GPT-2, and GPT-3 based on transformer technology. However, not every enterprise can develop architectured transformer models from scratch, as they are expensive and require significant processing and computational resources.
Hugging Face created the Transformers library to help people and organizations overcome the built-in costs of training and hosting transformer-based models. This transformer library is an open-source repository hosting some of the most popular language models. Developers use an API to access thousands of off-the-shelf NLP and computer vision models offered through Hugging Face. After downloading each model, those developers can fine-tune it for specific use cases.
Source: Brandon Reeves
Hugging Face’s Optimum library extends Transformers by adding hardware-specific optimizations for training and inference. It provides optimized runtimes, quantization tools, and graph optimizations for accelerators such as NVIDIA TensorRT, Intel Gaudi, and AWS Trainum/Inferentia. Optimum is structured as a collection of backend-specific packages, allowing developers to run the same Transformers models with improved efficiency on their target hardware.
Diffusers
The Diffusers library is designed for generative diffusion models, supporting image, video, and audio generation through modular components such as noise schedulers and U-Net architectures. It enables inference and fine-tuning of pre-trained diffusion pipelines with a few lines of code, and includes memory-and latency-optimization options (e.g., offloading, quantization) for resource-constrained devices.
Tokenizers
The Hugging Face Tokenizers library is a high-performance tokenization engine written in Rust with bindings for Python. Tokenization remains a major bottleneck in preprocessing large text corpora, and Tokenizers speed this up significantly through parallelization and zero-copy memory design. It supports algorithms such as Byte Pair Encoding (BPE), WordPiece, and Unigram, along with customizable training pipelines for domain-specific tokenizers. The Tokenizers library is widely used beyond the Hugging Face ecosystem, including in production LLM workflows across research labs and enterprises.
Hugging Face Hub
The Hugging Face Hub is the flagship open-source platform offered by the company. It consists of pre-trained ML models, datasets, and spaces. As of January 2026, the Hub hosts over 2.4 million models covering various tasks, including text, audio, and image classification, translation, segmentation, speech recognition, and object detection.
As of January 2026, the Datasets Library contains over 730K datasets. Users can access and interact with the Datasets Library using a few lines of code. For instance, it only takes two lines of code (see image below) to access RedCaps, a dataset of 12 million image-text pairs scraped from Reddit.

Source: Hugging Face
Spaces
Spaces is the company’s platform for hosting interactive ML applications built with Gradio, Streamlit, or static HTML. Developers can use Spaces to help build their portfolios by sharing their NLP, computer vision, and audio models. Spaces support interactive demos (limited to 16GB RAM and eight CPU cores) for hosted models and versioning control with a Git-based workflow.
As of January 2026, Spaces hosts over 500K applications. Users can host an unlimited number of Streamlit, Gradio, and Static apps using Spaces. Notable developer Spaces on the platform include DALLE-E mini by dalle-mini, Stable Diffusion by stability, AnimeGANv2 and ArcaneGan by Akhaliq, and Latent Diffusion by multimodalart.
Source: Hugging Face
Accelerate
Accelerate is a lightweight library for scaling training across GPUs, TPUs, and multi-node clusters. It abstracts away device placement, distributed backends, mixed precision (FP16/BF16), and parallelization patterns like Fully Sharded Data Parallel (FSDP). Instead of forcing developers to rewrite code for specific hardware setups, Accelerate adapts the same training script to run on any configuration. This lowers the operational complexity of training large models and makes distributed training accessible to small teams and research groups.
Autotrain
Using Autotrain, users can upload their data onto the Hugging Face platform. Autotrain automatically finds the best model for the data, then trains, evaluates, and deploys it at scale. Hugging Face has published a video showing how Autotrain works.
Inference API
The Interface API enables organizations to integrate thousands of ML models through a fully hosted API. It also offers the infrastructure to support building large models requiring over 10GB of space. Hugging Face built the Interface API for enterprise customers, but has a free tier for hobby users as well.
Safetensors
The safetensors format is a file type created by Hugging Face to store model weights safely and efficiently. Traditional PyTorch weight files use Python’s pickle system, which can run hidden code when opened, which is a major security risk when downloading models from the internet. Safetensors avoids this by storing only raw numerical data, ensuring that loading a model cannot execute any unwanted code. It also loads faster because it is memory-mapped, meaning the system can access the data without reading the entire file into memory at once.
HuggingChat
HuggingChat is an open-source chat interface built by Hugging Face that lets people interact with language models in the same way they would use ChatGPT, but entirely with open models. It acts as a front-end that connects to models hosted on the Hugging Face Hub, allowing users to test and compare different systems in a simple chat window. Because it is open-source, developers can inspect how it works, customize it, or run their own version, something that’s not possible with most commercial chatbots.
Market
Customer
Hugging Face’s paying customers are primarily large enterprises seeking expert support, additional security, autotrain features, private cloud, SaaS, and on-premise model hosting. In the early days, the company’s target market was indie researchers, machine learning enthusiasts, and SMB organizations with lower security requirements to deploy their NLP models.
As of June 2025, the company reports more than 2K paying enterprise customers, including clients such as Intel, Pfizer, Bloomberg, and eBay. Additionally, the platform is used by over 50,000 organizations (many of whom may be non-paying or using free tiers) in some capacity. Hugging Face’s enterprise product suite supports on-premises or private-cloud deployment options, including partnerships with infrastructure providers, like the Dell Enterprise Hub on Hugging Face for on-premises model deployments.
Market Size
Hugging Face participates in the broader AI software and model-infrastructure market, which is expanding quickly as enterprises adopt large language models and build internal AI capabilities. Global spending on generative AI was estimated to reach $644 billion in 2025, reflecting rapid growth in model development, deployment tooling, and inference workloads.
Analysts also expect significant growth in the underlying software layer that includes model hubs, fine-tuning systems, and MLOps platforms. Forecasts show the AI platforms software market reaching $153 billion by 2028, driven by increased enterprise adoption of foundation models and model-lifecycle tooling. Broader enterprise AI investment is expected to push total AI spending toward more than $630 billion by 2028.
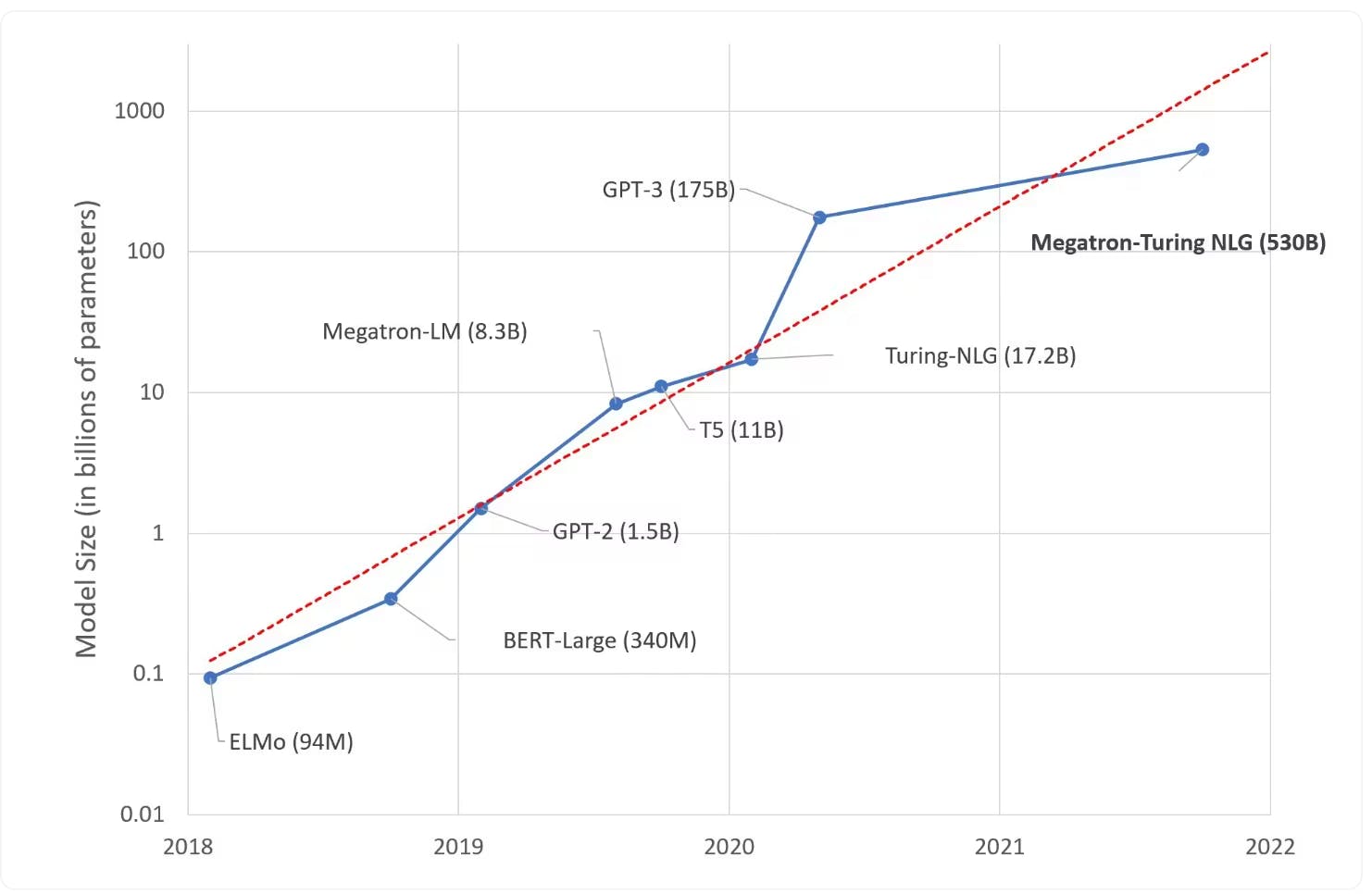
Growth in model size helps illustrate why the market is expanding. In 2018, BERT contained about 340 million parameters. In 2019, OpenAI's GPT-2 debuted with 1.5 billion parameters, Nvidia’s Megatron-LM with 8.3 billion parameters, and Google’s T5 with 11 billion parameters. Microsoft introduced Turing-NLG with 17.2 billion parameters in early 2020. OpenAI then released GPT-3 in June 2020 with 175 billion parameters and was considered at the time to be the largest language model ever made. However, Nvidia and Microsoft broke the record in 2021 when they unveiled Megatron-Turing NLG with 530 billion parameters. Hugging Face joined the fray in July 2022 when it released BLOOM with 176 billion parameters.
As organizations train and deploy increasingly large models, spending concentrates on the categories Hugging Face serves, including model hosting, inference, evaluation, fine-tuning, and enterprise deployment infrastructure.
Source: Hugging Face
Competition
OpenAI: Founded in 2015, OpenAI develops frontier multimodal systems such as GPT, DALL·E, and Sora and offers enterprise-grade APIs for model hosting, fine-tuning, and agentic workflows. In October 2025, the company completed a secondary share sale that valued it at $500 billion. As of January 2026, it has raised an estimated $79 billion in total funding. OpenAI competes with Hugging Face for enterprise inference and fine-tuning budgets, although its model stack is fully proprietary and vertically integrated, while Hugging Face positions itself as an open, neutral platform that hosts and supports many model families, including OpenAI competitors.
Anthropic: Founded in 2021, Anthropic builds the Claude family of models and provides APIs and enterprise deployments optimized for reliability and safety. In September 2025, the company raised $13 billion at a valuation of about $183 billion, with participation from ICONIQ, Fidelity, Lightspeed, and Google. Total funding exceeds $33.7 billion as of January 2026. Anthropic competes with Hugging Face in enterprise LLM usage, but differs in strategy: Anthropic is a pure proprietary-model lab, while Hugging Face is a model-agnostic ecosystem that distributes open-weight models and provides tooling that can wrap around Claude and others.
Databricks: Founded in 2013, Databricks provides a unified data and AI platform used for data engineering, analytics, training, and increasingly agentic/LLM workloads. In September 2025, the company raised $1 billion at a valuation above $100 billion. As of January 2026, total capital raised exceeds $25 billion across equity and structured financing. Databricks overlaps with Hugging Face, where enterprises want integrated data-to-model pipelines, but its core is data infrastructure. Hugging Face plays the complementary role of housing the model ecosystem, evaluation tools, and open-source libraries that Databricks often integrates.
Mistral AI: Founded in 2023, Mistral AI develops open-weight and commercial LLMs such as Mistral, Mistral Large, and Codestral, and offers a production API. The company raised €1.7 billion ($2 billion) in September 2025 at a valuation of €11.7 billion ($13.5 billion), bringing total capital to roughly €2.8 billion ($3.2 billion) as of January 2026. Mistral competes with Hugging Face at the model level by releasing models that users can host or consume via API, but many users also obtain Mistral models through Hugging Face’s Hub and inference endpoints. Thus, Mistral is both a competitor and supplier in Hugging Face’s broader open-weights ecosystem.
Cohere: Founded in 2019, Cohere builds language models and enterprise deployments designed for private, secure, and regulated environments. In August 2025, it raised roughly $500 million at a valuation near $7 billion, led by Radical Ventures and Inovia Capital. As of January 2026, total funding has reached $1.7 billion, with support from Nvidia, Salesforce, Oracle, Cisco, and others. Cohere competes with Hugging Face for enterprise LLM adoption, especially in regulated industries, but it primarily delivers its own vertically integrated stack, whereas Hugging Face offers a multi-model environment with open tools for evaluation, fine-tuning, and deployment.
H2O.ai: Founded in 2012, H2O.ai provides open-source and enterprise AutoML tools used across financial services, healthcare, and insurance. Its most recent primary round in 2021 brought in $100 million at a valuation of about $1.7 billion, with total funding exceeding $250 million as of January 2026, from investors such as Goldman Sachs, Wells Fargo, and Nvidia. H2O.ai’s overlap with Hugging Face is primarily in enterprise ML deployment, but its focus remains classical ML and AutoML workflows, while Hugging Face has become the central ecosystem for transformer-based models and open-source LLM development.
Business Model
Hugging Face uses a freemium, open core model in which its most widely used assets, including the Transformers library, the model hub, and the dataset hub, are free and open source. This structure helps the company attract developers and researchers who contribute models, datasets, and tools that strengthen the platform overall. The open source foundation also makes Hugging Face a default starting point for machine learning projects, which drives broad adoption at the individual and academic level.
Hugging Face generates revenue through a combination of subscription plans, usage-based infrastructure fees, and enterprise contracts. Individual users can subscribe to the PRO plan for $9 per month, which provides additional features, larger storage limits, and enhanced collaboration tools. Teams and organizations typically use paid workspaces, which begin at $20 per user per month and include access controls and workspace management. Customers who deploy high volume or production workloads pay for compute on a usage basis, with inference endpoints and hosting priced per hour, depending on hardware, beginning at $0.033 per hour for CPU-based instances.
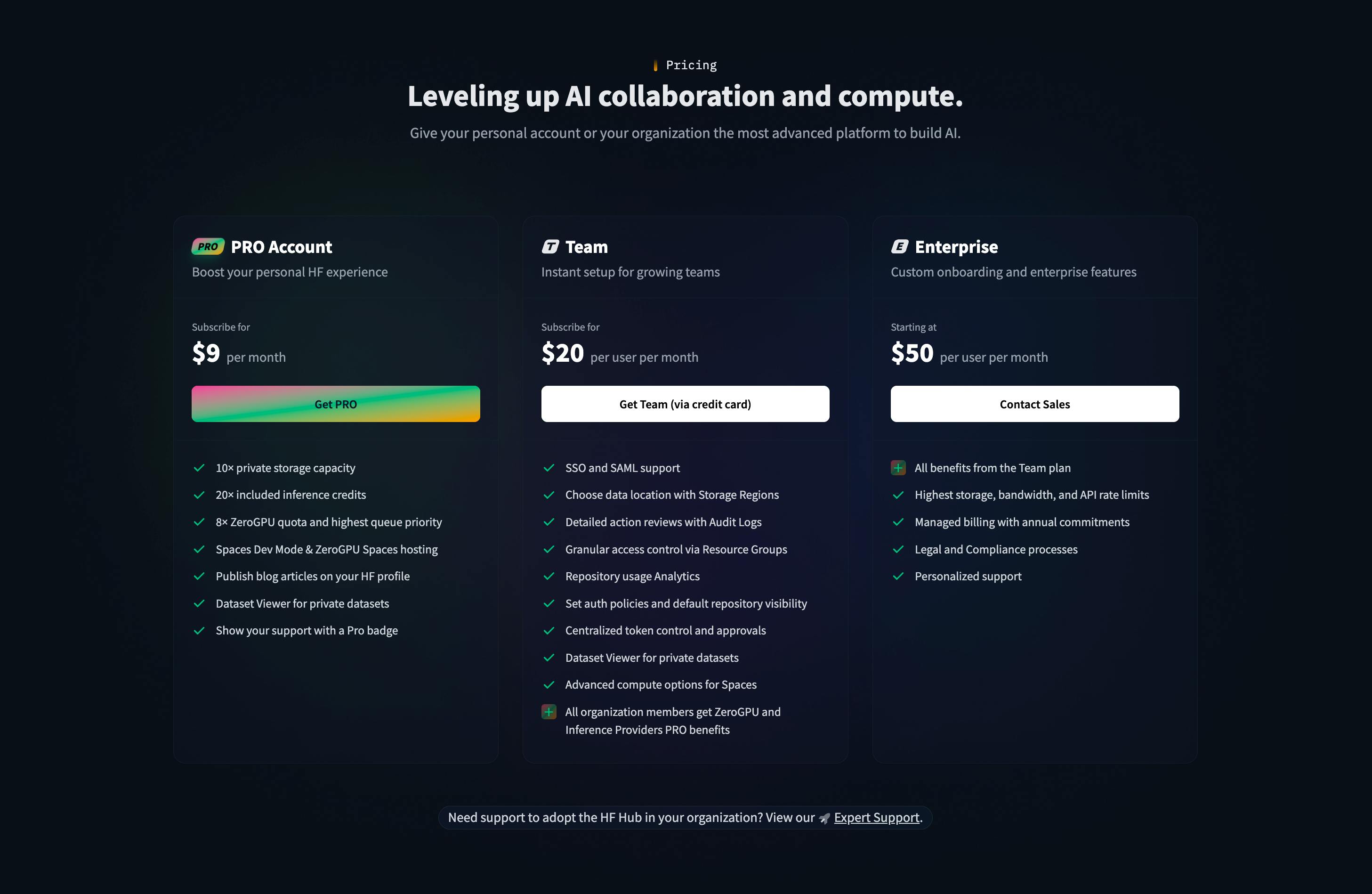
Source: Hugging Face
Larger organizations purchase enterprise plans that provide custom infrastructure, advanced security controls, audit logs, SSO integrations, and managed billing. These customers often use private cloud or on-premises deployments of the Hugging Face Hub for compliance and governance reasons. This model allows Hugging Face to convert widespread community adoption into paid usage as companies scale their model training, hosting, and inference needs.
Traction
Hugging Face has experienced growth in both product adoption and commercial revenue since it began monetizing in 2021. In its first year of paid features, the company generated about $10 million in revenue. Estimates suggest revenue increased to roughly $15 million in 2022. By 2023, Hugging Face reached approximately $70 million in ARR. In 2024, revenue estimates continued to rise, reaching approximately $130 million.
In 2022, more than 10K organizations used Hugging Face’s platform in some capacity. As of January 2026, that number had climbed to 50K. The traction of the company’s products can be attributed to its initial focus on building a community instead of monetizing users. Pat Grady, a Partner of Sequoia Capital, said the following about Hugging Face prioritizing building a strong community early on:
"They prioritized adoption over monetization, which I think was correct. They saw that transformer-based models working their way outside of NLP and saw a chance to be the GitHub not just for NLP, but for every domain of machine learning."
Valuation
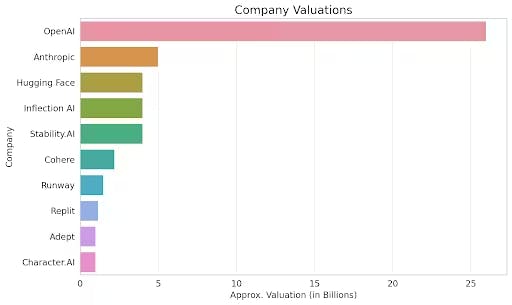
Source: Maginative
Hugging Face has raised a total of $395.2 million as of January 2026 from investors including Lux Capital, Sequoia, Coatue, Addition, Coatue, SV Angel, Betaworks, AIX Ventures, Thirty-Five Ventures, and Olivier Pomel (co-founder & CEO at Datadog). The last funding round was a $235 million Series D in August 2023, led by Salesforce Ventures at a post-money valuation of $4.5 billion.
Hugging Face has plans to become a publicly traded company. Brandon Reeves from Lux Capital, an investor in Hugging Face since 2019, believes Hugging Face could be a $50-100 billion company. According to the company’s CEO, Clément Delangue, he has turned down multiple acquisition offers for his company. In a 2022 Forbes interview, Delangue made the following comments about his plans to take Hugging Face public:
"We want to be the first company to go public with an emoji, rather than a three-letter ticker. We have to start doing some lobbying to the Nasdaq to make sure it can happen."
Key Opportunities
Expand Product Offerings to MLOps
Hugging Face already provides autoML solutions enabling organizations to build AI models without code generation. The next reasonable step would be to enter the MLOps market by serving enterprise customers with model management, deployment, and monitoring.
The MLOps market is expected to reach $6.2 billion in 2028, up from $612 million in 2021. Several well-funded startups exist in the space, notably Weight and Biases, DataRobot, Comet, and Dataiku. Hugging Face could develop and cross-sell MLOps model monitoring, observability, and management products to its existing enterprise customers.
Build Large Language Models
Hugging Face released its first open-source large language model, BLOOM, in July 2022. The model has a similar architecture to OpenAI’s widely popular GPT-3 as well as other LLMs with multi-language training data. In the past, Hugging Face relied on large language model creators to open-source their models, or for external researchers to replicate them, before Hugging Face added them to its library. However, large language model creators like OpenAI are increasingly keeping their models proprietary and commercializing them.
The unveiling of BLOOM shows a clear intent from Hugging Face to pursue creating its own large language models. BLOOM was downloaded over 40,000 times as of August 2022. If successful, BLOOM could present Hugging Face with an opportunity to become a formidable player in the large language model space rather than just a marketplace for open-source NLP models.
Key Risks
Biases and Limitations in Datasets
AI models, particularly NLP, have long struggled with biases in datasets used to build them. Human biases such as overgeneralization, stereotypes, prejudice, selection bias, and the halo effect are prevalent in the real world. Large language models are trained with vast volumes of data, often scraped from the internet, that could contain some of these biases. For instance, researchers found that men are over-represented in online news articles and on Twitter conversations. So, machine learning models trained on such datasets could have implicit gender biases.
Other researchers discovered NLP models underrepresent women in certain career fields like computer programming and medicine. In a task determining the relationships between words, the models associated occupations such as nursing and homemaking with women and doctor and computer programming with men.
NLP models are used across all sectors of the economy, from banking and insurance to law enforcement. Organizations could use some of Hugging Face’s popular models to make business decisions, such as credit approval and insurance premium calculations, that may impact marginalized and underrepresented groups.
Hugging Face acknowledged the issue and even showed how some models in its library, such as BERT, contain implicit biases. It put some checks and fine-tuning in place, including the Model Card feature intended to accompany every model on the platform and highlight its potential biases. However, these measures may not be enough since they warn users but do not fully tackle them.
Trends to Commercialize Language Models
Hugging Face hosts over 2 million models as of January 2026. However, some popular architectures like GPT-3, Jurassic-1, and Megatron-Turing NLG are not available in the company’s library because companies, such as OpenAI and AI21 Labs, began commercializing their proprietary models.
Commercialized models usually contain more parameters than open-source models and can perform more advanced tasks. If the commercialized model trend continues, some of the content in Hugging Face’s library could become obsolete. Models they can host would become less accurate, have fewer parameters, and could not perform advanced tasks as well as commercialized models, driving users away from the platform.
Summary
Hugging Face’s open-source library and model repositories are helping to drive access to ML models as the field explodes, and have become popular among ML engineers, data scientists, and researchers. For the first five years of the company, Hugging Face prioritized gaining free users and building a community over monetization. In 2021, the company began focusing on the enterprise market. They developed enterprise-grade products and services with more security features and processing capacity.
Hugging Face is well capitalized. In May 2022, after its $100 million Series C round, the company also had roughly $40 million in the bank from previous rounds, bringing its cash reserves to $140 million. This position allows the company to continue to grow its library and potentially focus on expanding beyond NLP into MLOps, accelerating commercialization efforts, and fighting the inherent bias in ML models.