
The Economics of AI
In July 2025, The Wall Street Journal reported that AI capital expenditures, like data center hardware and infrastructure, have contributed more to 2025 US GDP growth than all consumer spending combined. While staggering, this statistic highlights the significant impact of AI both on the US economy and American culture in 2025.
AI has been integrated into nearly every element of everyday life, from parking cars to making coffee. The cultural reaction to this proliferation is most extreme among both technological “accelerationists” pushing for the next industrial revolution and pessimists predicting the fall of human society to artificial superintelligence. The growing volume in the conversation around potential right-around-the-corner breakthroughs in AI has been reflected in the stock market as well: as of August 2025, the Magnificent 7 now comprise more than 30% of the market cap of the entire S&P 500, attributable largely to expectations of how these companies will benefit from booming AI adoption.
As investors become increasingly concerned about the possibility of a bubble in both private and public market AI bets, critics of AI have been quick to remind both policy-makers and venture capitalists that no frontier AI company relying on third-party data centers is yet profitable. While AI leadership teams have made headlines recruiting talented AI researchers with compensation packages that rival the contracts of pro athletes, the fundamental challenges to AI profitability stem from the mismatch between the revenue from current users and the costs to develop and deploy models.
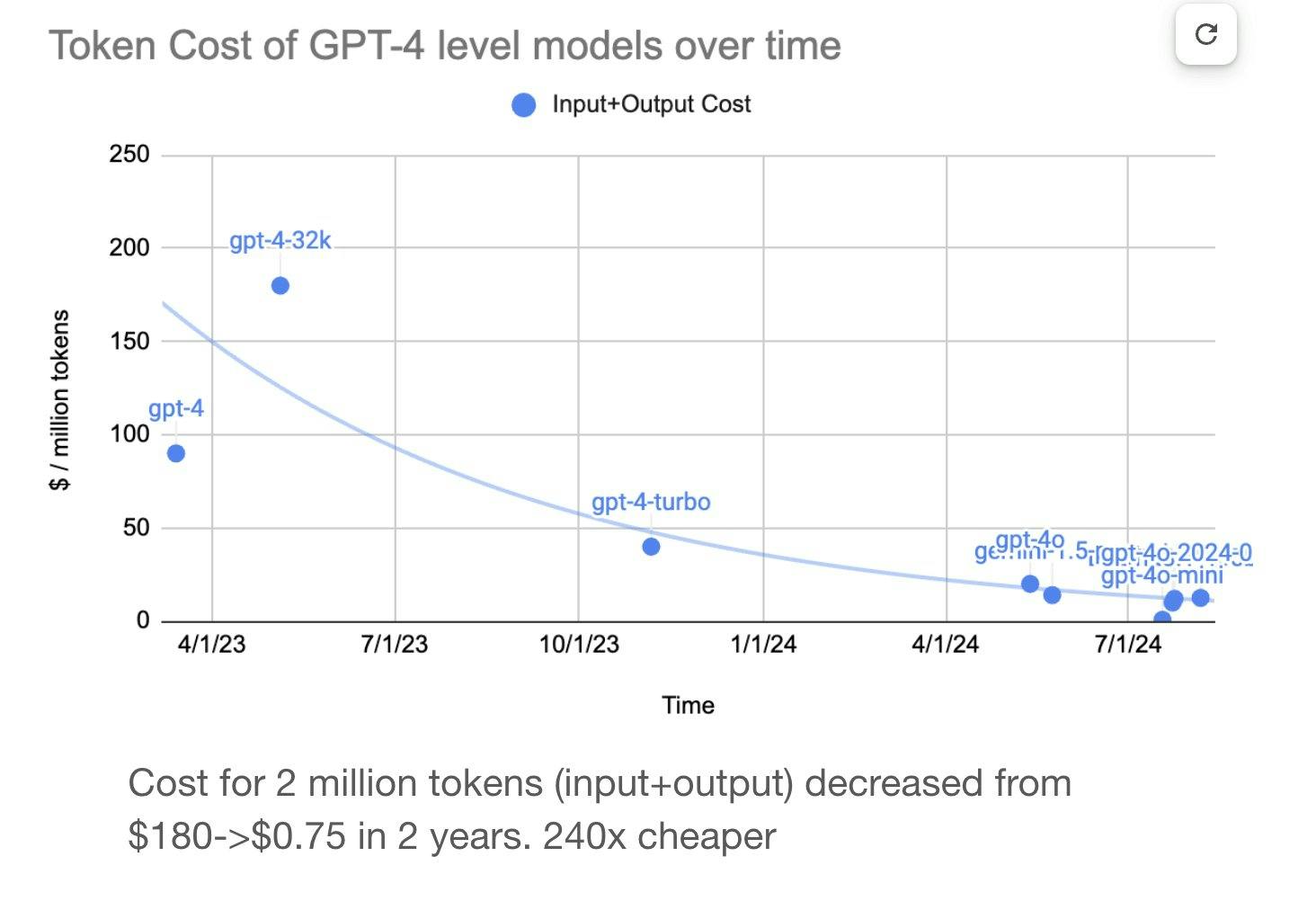
Put simply, frontier AI companies are not charging model users enough to recoup the costs of developing, training, and running their models. Despite this, public-facing press from these companies remains largely optimistic given the falling cost of inference, with OpenAI’s March 2025 letter to Congress noting that the cost of a given AI capability falls by an order of magnitude every 12 months.
Source: R&D World
The part of the equation this narrative fails to capture is the increasing demand for AI capabilities, requiring both larger and better-trained models and more frequent and complicated applications of those models. Both training volumes for off-the-shelf models and demands on those models have increased: by one estimate, model training sets have grown 350,000x in the last decade compared to only a 100x decrease in compute costs.
Compute costs stem from both technological advances in hardware, like semiconductors built specifically for AI use cases, and the land, buildings, electricity, cooling systems, and networks required to operate this technology. Collections of servers housed in collections of buildings purpose-built for these systems are referred to as AI data centers. Both upgrades to existing data centers and construction of new data centers are major expenses for the developers of AI models, either directly or via compute partners.
Can this infrastructure-heavy model ever support the economics of AI? While data centers provide part of the backbone of the internet and all profitable online services, AI companies are tasking data centers with unprecedented storage and compute requirements. As of August 2025, there is an imbalance between the present demands of data centers and the compute capacity they can provide. Correcting this imbalance will require massive investment in data centers, much of which has already begun, but it will not guarantee profitability for AI companies.
Cost per Query vs. Query Complexity and Volume
As of August 2025, the demands on AI systems can be simplified into two main components: the cost of running queries, and the volume and complexity of those queries.
The Cost of Running a Query
While teaching a model to learn patterns and make predictions from a dataset is known as training, using a trained model to answer user queries is known as inference. Technologists have lauded the “plummeting” cost of inference, citing order-of-magnitude decreases in the cost to train models with equivalent performance against benchmark tests.
In order to effectively parse the progress companies have made in improving the cost of inference, it is necessary to understand the currency of AI models: tokens. Model-building companies discretize the cost of inference to users in “tokens”, which represent units of compute required in running a model against a user’s query.
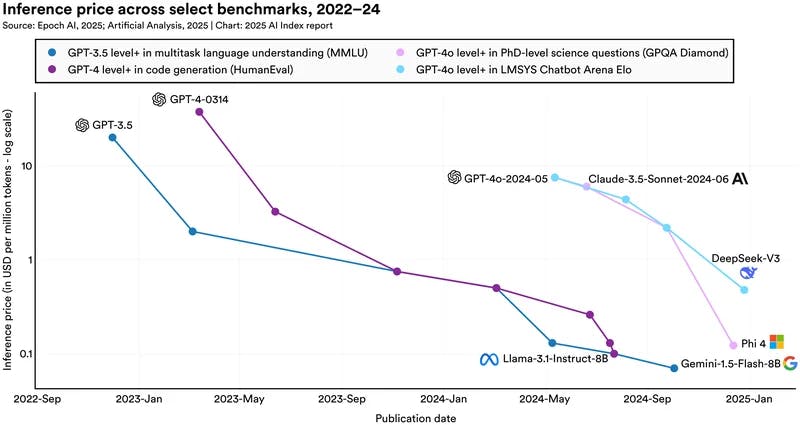
For example, an LLM chatbot query cost in tokens might be determined by the number of words in the user’s query, while a code editing query cost might be a function of the number of lines of code. Input tokens describe the length and complexity of the user’s query, and output tokens describe the complexity of the model’s response. Charts of inference costs falling are often shown in USD per million tokens, communicating how much it costs companies to run queries of equivalent complexity on improved models and hardware stacks.
Source: Elad Gil
Claims of tremendous improvements in inference costs can be misleading, however, for a number of reasons. First, improvement on tasks of different complexity has varied: models are now cheaper to use for the most complex tasks, but only somewhat cheaper for simple tasks:
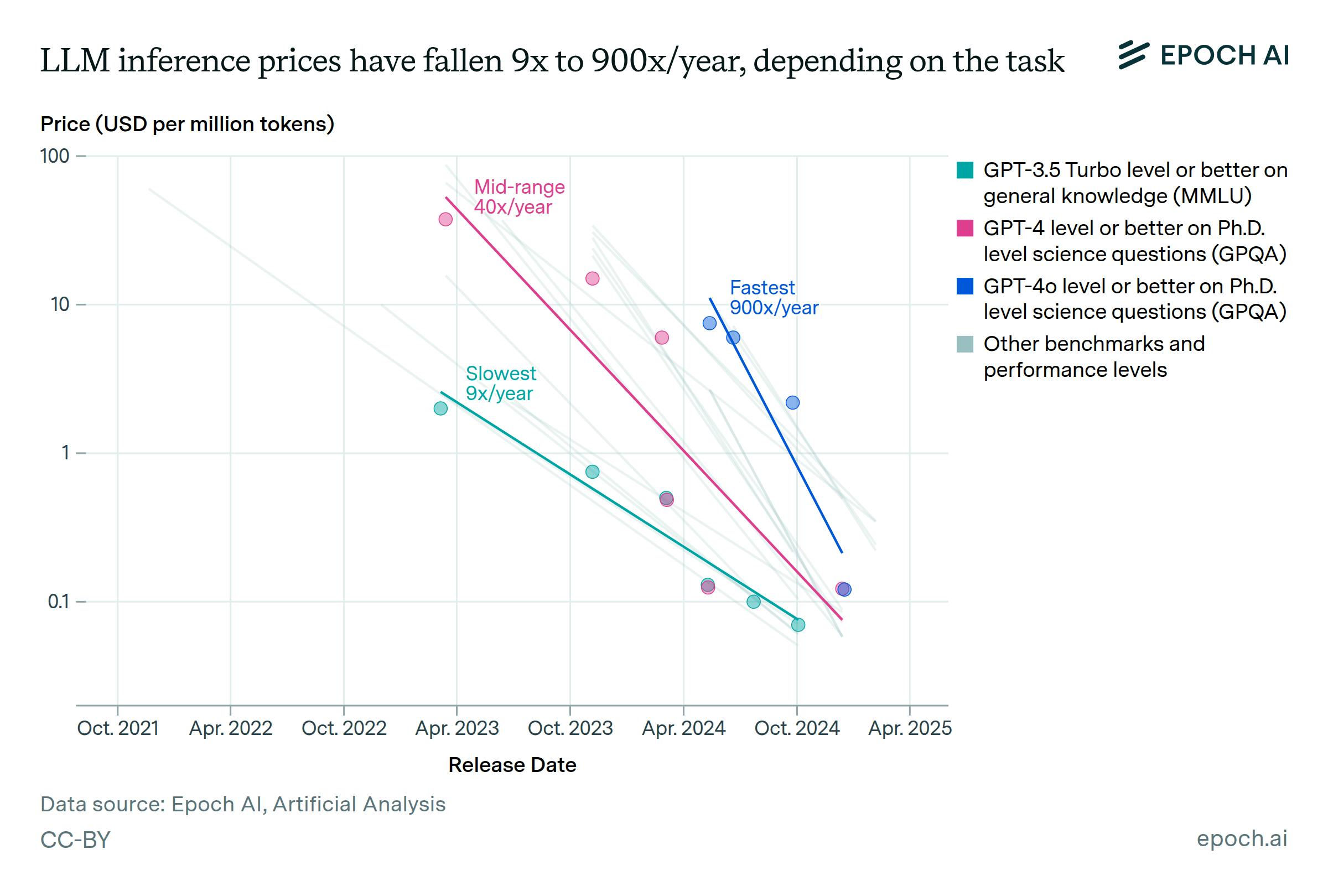
Source: Epoch AI
Further, the figures cited by analysts of AI companies compare the cost of inference to consumers instead of the cost of inference to companies. One analysis compared the cost of private inference, i.e., compute clusters maintained by organizations or individuals, versus public inference, or buying compute through model providers. It found that model providers are heavily subsidizing inference to achieve scale and adoption compared to the cost of inference for in-house setups.
Query Complexity & Volume
Falling inference costs are largely taken for granted as of August 2025, but the increasing volume and complexity of queries are often overlooked. The demands on AI infrastructure are outpacing the improvement in inference costs by orders of magnitude. These demands stem from the complexity of new models, which are trained on larger data sets and can handle more complex queries, and the volume of queries submitted by model users.
Query Complexity
As the complexity of AI applications and the expectations of AI accuracy increase, frontier AI companies are training models on larger and larger data sets, increasing the compute required to store and train on these data.
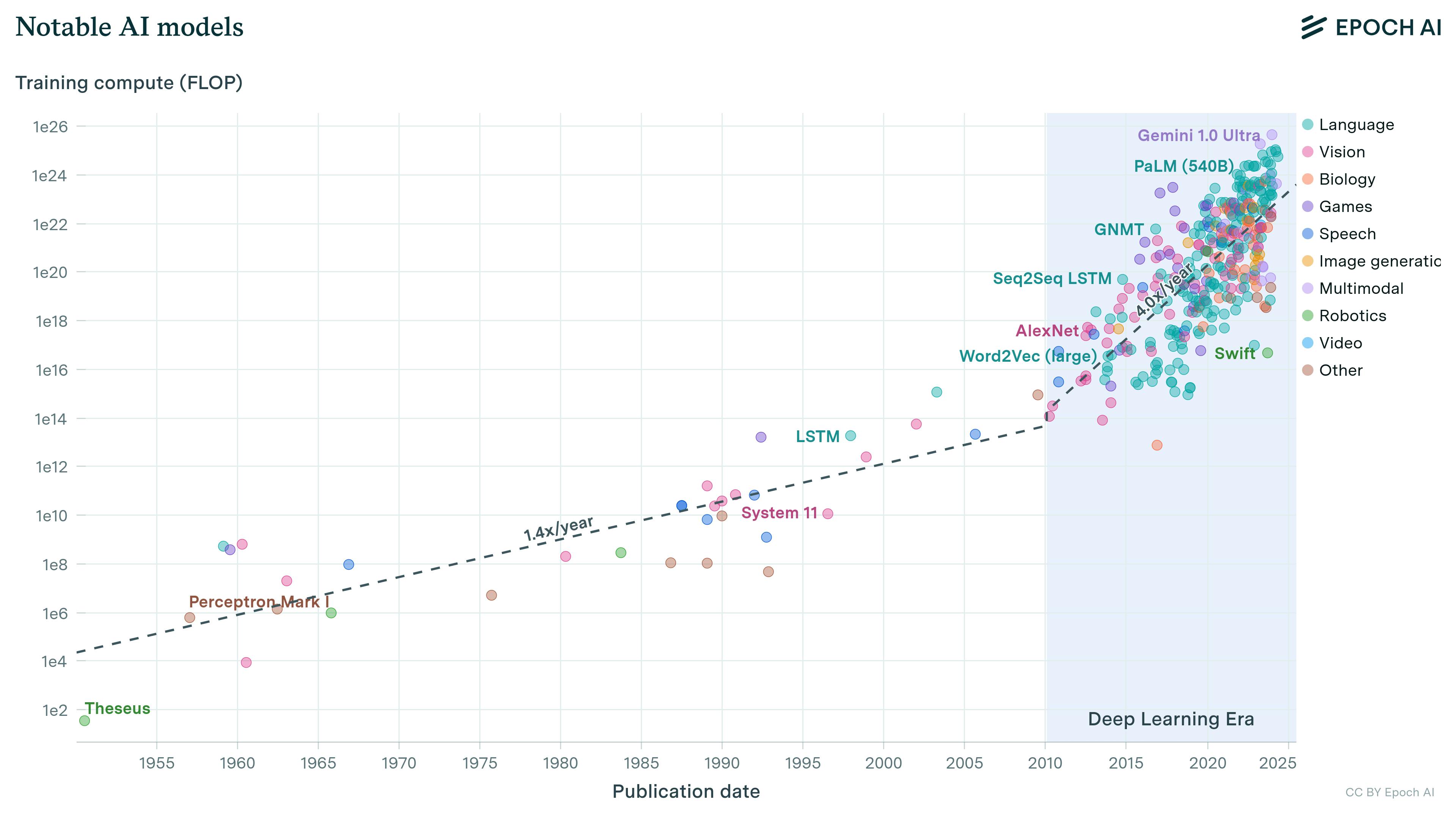
Source: Epoch AI
As new models with larger training bases are released, the cost to train those models has increased by orders of magnitude, even with the falling costs of inference.
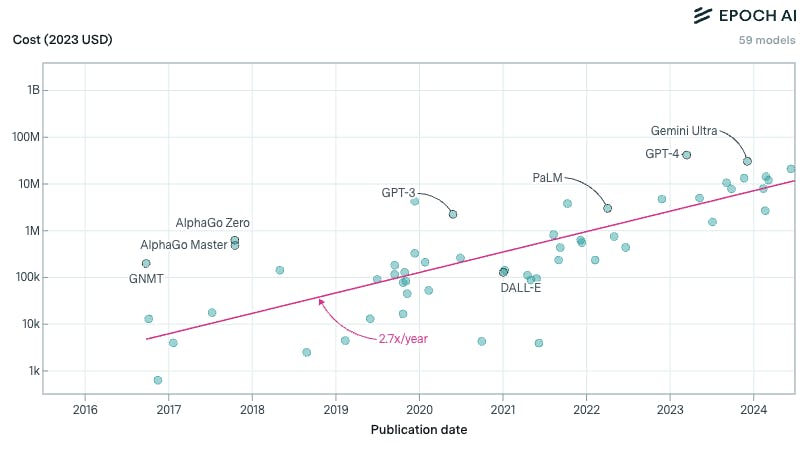
Source: Epoch AI
Query Volume
By design, these improved models are gaining traction among users more quickly than earlier models. According to OpenRouter, an LLM usage data collector, LLM usage alone has increased by 30x in the last year. However, each one of these queries may be orders of magnitude more expensive in number of tokens than past queries as AI applications become more complex. Meanwhile, Anthropic has reported that agentic AI models (which are not shown on the graph below) may cost 4x - 15x as much as LLM chatbots for queries of the same complexity.
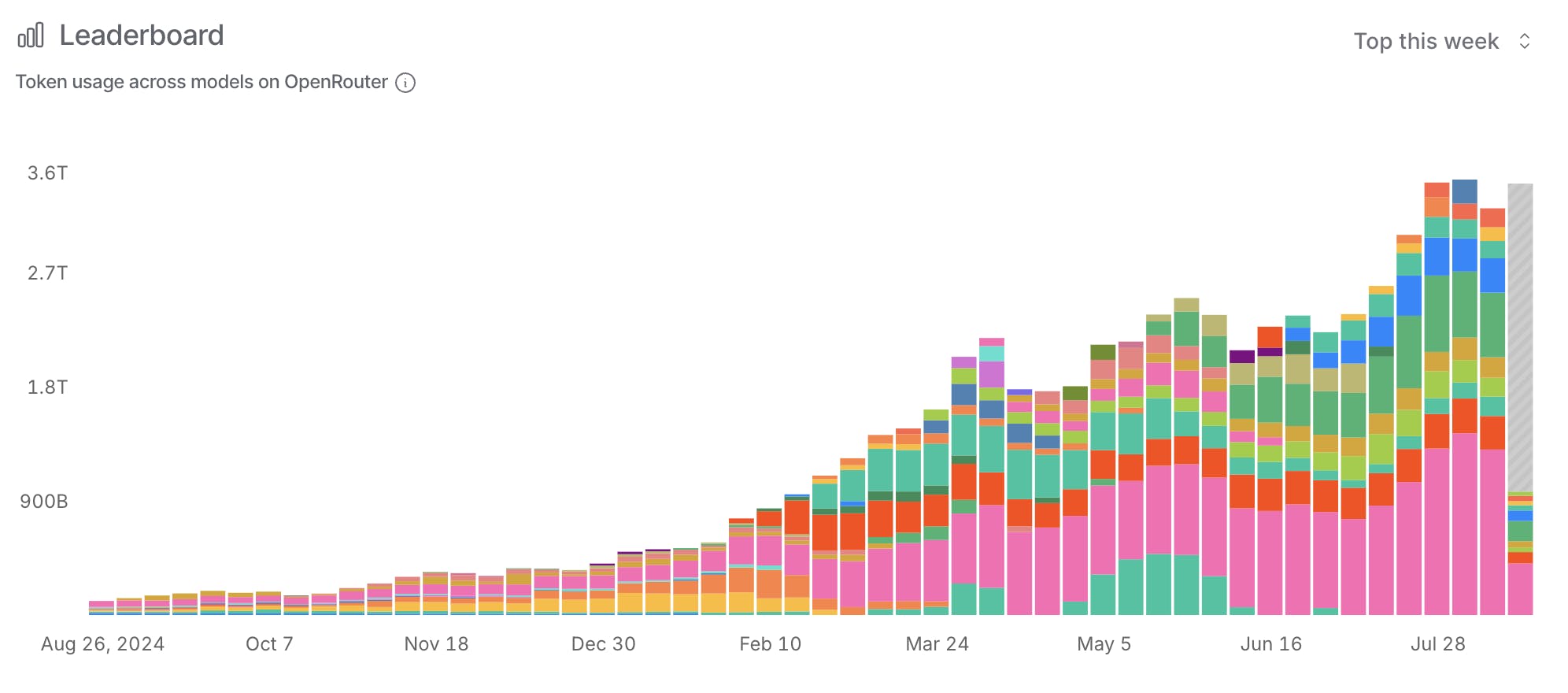
Source: OpenRouter
AI companies cognizant of this shift, including model builders like OpenAI and LLM wrappers like Cursor, have set token limits in an effort to limit losses generated by the cost of queries exceeding the revenue from those users. While realistic costs for model hosts are represented in tokens, many subscriptions to AI models or LLM wrappers charge users a monthly fee for unlimited or simply capped usage, not on a per-token basis. “Inference Whales”, or heavy users of AI tools, particularly coding assistants, have used as much as $35K in tokens monthly as members of a $200 per month subscription. As models improve, users consistently want to use the best available models without a changed subscription price, even when new models cost orders of magnitude more to train.
Efficiency Gains vs Runaway Usage
This tension between falling costs per token and soaring aggregate costs from model complexity and query volume understates the magnitude of the imbalance. For every improvement in model complexity or increase in user queries, data centers must be built or upgraded to maintain the inference capabilities these demands require. This mandates building out and replacing infrastructure and consuming more power. NVIDIA’s roadmap predicts that the server racks of 2027 will require 30 times the energy of existing standard server racks as of 2025 due to more compact and powerful chips.
One McKinsey report from April 2025 predicts that 170 to 220 gigawatts will be required by AI data centers by 2030. The same report estimated that data centers would need to spend $6.7 trillion by 2030 to keep up with the demand for compute, including $5.2 trillion for AI compute alone.
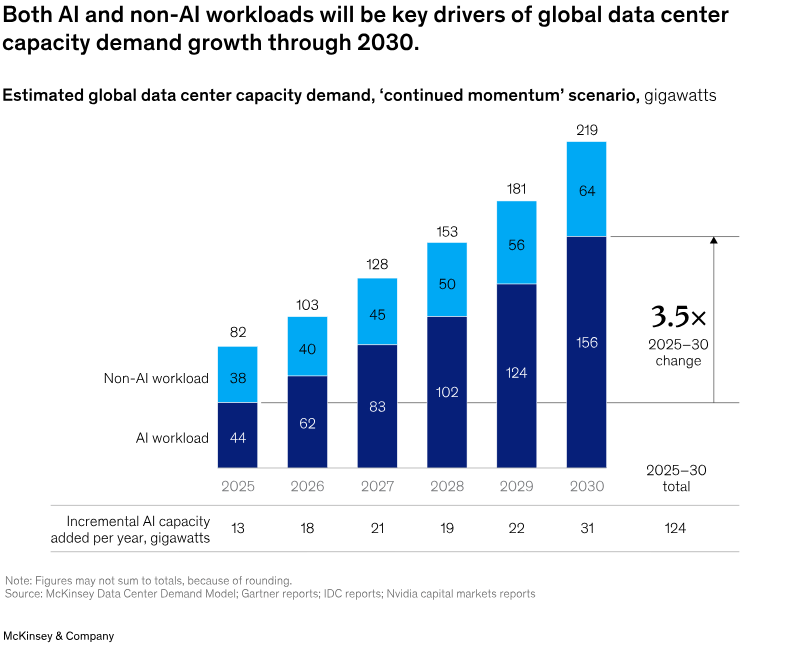
Source: McKinsey
The cloud computing market is continuously seeking out ways to drive efficiency, such as purpose-built AI semiconductors, servers, and data centers. However, these providers are limited by some structural limitations of the technology that make the cost of compute unavoidably high; from hardware to energy, cooling, and beyond.
Physical Limits of Compute
AI data centers are the physical high-performance computing (HPC) facilities that store model data, train models, and execute queries on behalf of users. Data center hardware includes AI-specific semiconductors integrated with primary and backup power sources, networking equipment, and cooling systems.
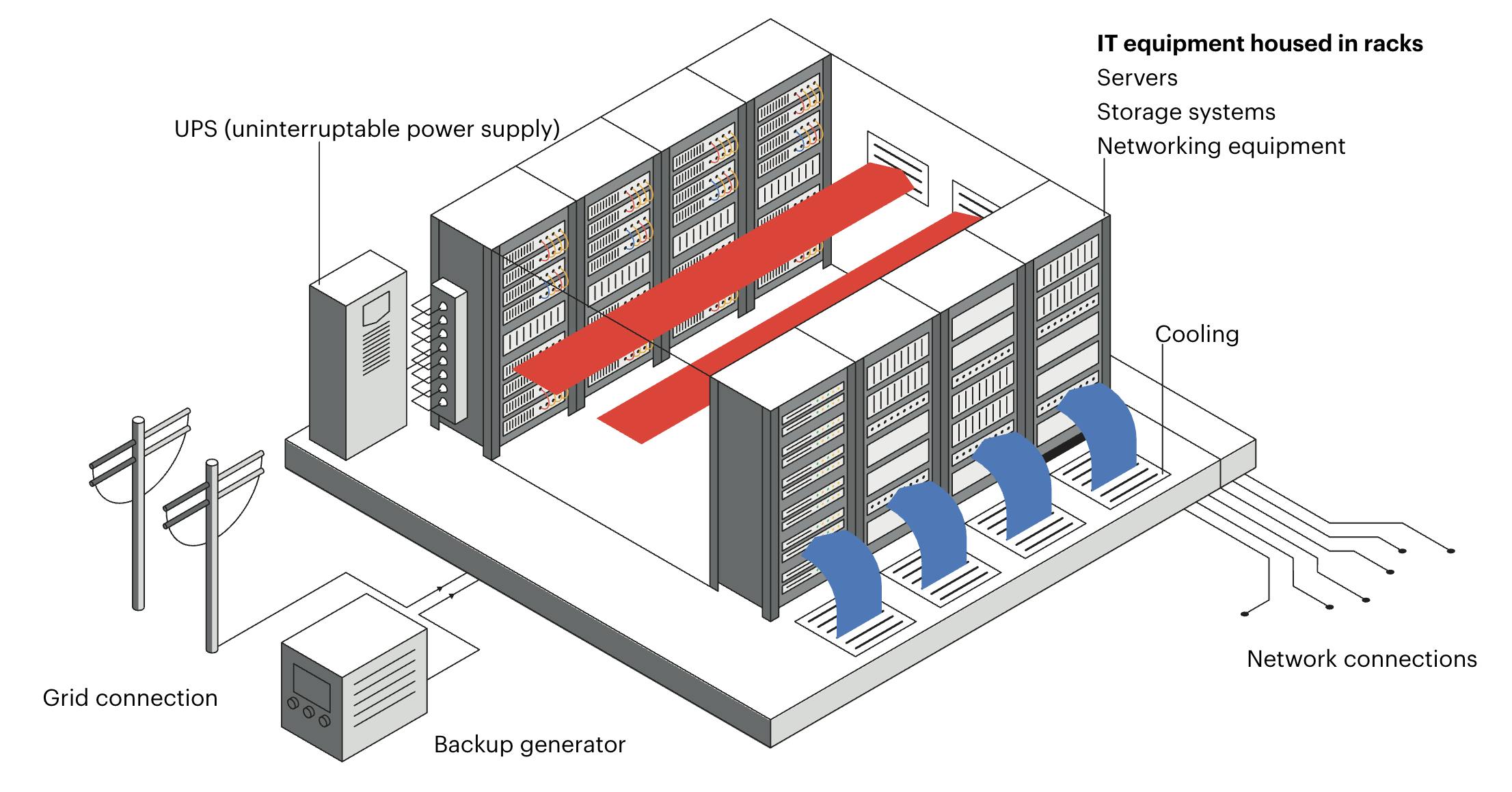
Source: IEA
The primary costs associated with AI data centers are semiconductors optimized specifically for AI model development and use, and the power required to operate the data centers, followed by the land and water costs for housing and cooling these systems.
What are AI Semiconductors?
AI semiconductors are specifically designed for parallel processing of large amounts of data, and often have high bandwidth memory (HBM) stacks embedded in the chip as opposed to relying on external memory stores. These features of AI-optimized chips (GPUs) aren’t present in traditional central processing unit (CPU) semiconductors. AI semiconductor networks are increasingly configured using accelerators like field-programmable gate arrays (FPGAs) and aApplication-specific integrated circuits (ASICs) in addition to GPUs.
GPUs: Semiconductors originally designed for rapid processing of video or image data via parallel processing. GPUs have been adapted since their inception for AI model training and inference. GPUs can process many simple tasks simultaneously using thousands of individual simple compute cores.
ASICs: parallel computation hardware components specifically designed to increase efficiency in AI stacks.
Tensor processing units (TPUs): TPUs are a kind of ASIC designed specifically for large matrix calculations and other tensor operations required for deep learning neural networks. TPUs were invented by Google for the development of Gemini and other Google AI tools.
FPGAs: FPGAs are integrated circuits that can be programmed after manufacturing (or “in the field”) to accommodate custom circuit architecture. FPGAs are used in AI systems to decrease system latency.
As chip hardware rapidly evolves, data center manufacturing teams face a trade-off between keeping their stacks state-of-the-art and turning a profit. Despite proliferating demand for AI compute, AI model builders are interested in training and running their models on the most up-to-date hardware stacks, which require orders of magnitude less power for the same tasks. Even with the premiums that data centers can charge for upgraded hardware, some models are optimized for performance on particular chips, making alternative hardware less desirable. In addition to this dynamic, many AI chips in production last less than three years.
In 2024, cloud computing company CoreWeave spent 4x more on capital expenditure than its annual revenue. As of August 2025, 8% of the total revenue of the Magnificent 7 comes solely from NVIDIA sales of GPUs to Meta, Amazon, Microsoft, Google, and Tesla.
How are AI Data Centers Powered?
Both critics and proponents of AI see the massive energy demand of AI data centers as a meaningful roadblock to scaling. Google’s data centers, for example, used 30.8 million megawatt-hours of electricity in 2024, over twice the amount used in 2023 and over 7x the amount used in 2014. The average American home, for perspective, uses 10.5K kilowatt-hours of electricity each year, making Google’s data center power usage equal to 2.9 million American homes. Electricity costs more than water for data centers, so building in locations with sufficient power sources often supersedes selecting areas with abundant water. When water is limited in these locations, some companies turn to electric cooling instead, making data centers’ power footprints even larger.
Grid Usage
Growing data center power demands make data centers an increasing share of the overall strain on local grids and the power sources that supply them. Meta’s data centers, for example, use 11.4% of Oregon’s power annually as of November 2024, and some expect that Meta could eventually consume over 15% of Louisiana’s electricity. In the US, municipalities are required to supply power to entities in their jurisdiction, regardless of whether those entities are households or massive data centers. In Arizona, where 151 data centers are in operation as of August 2025, the primary utility provider Arizona Public Service (APS) estimated in 2023 that 55% of its future electricity demand would come from data centers. In the same report, the APS said its 2023 infrastructure would be insufficient for the demand on the grid it anticipated by 2030. Electricity demand from data centers in the US as a whole is expected to double by 2035 as compared to 2025.
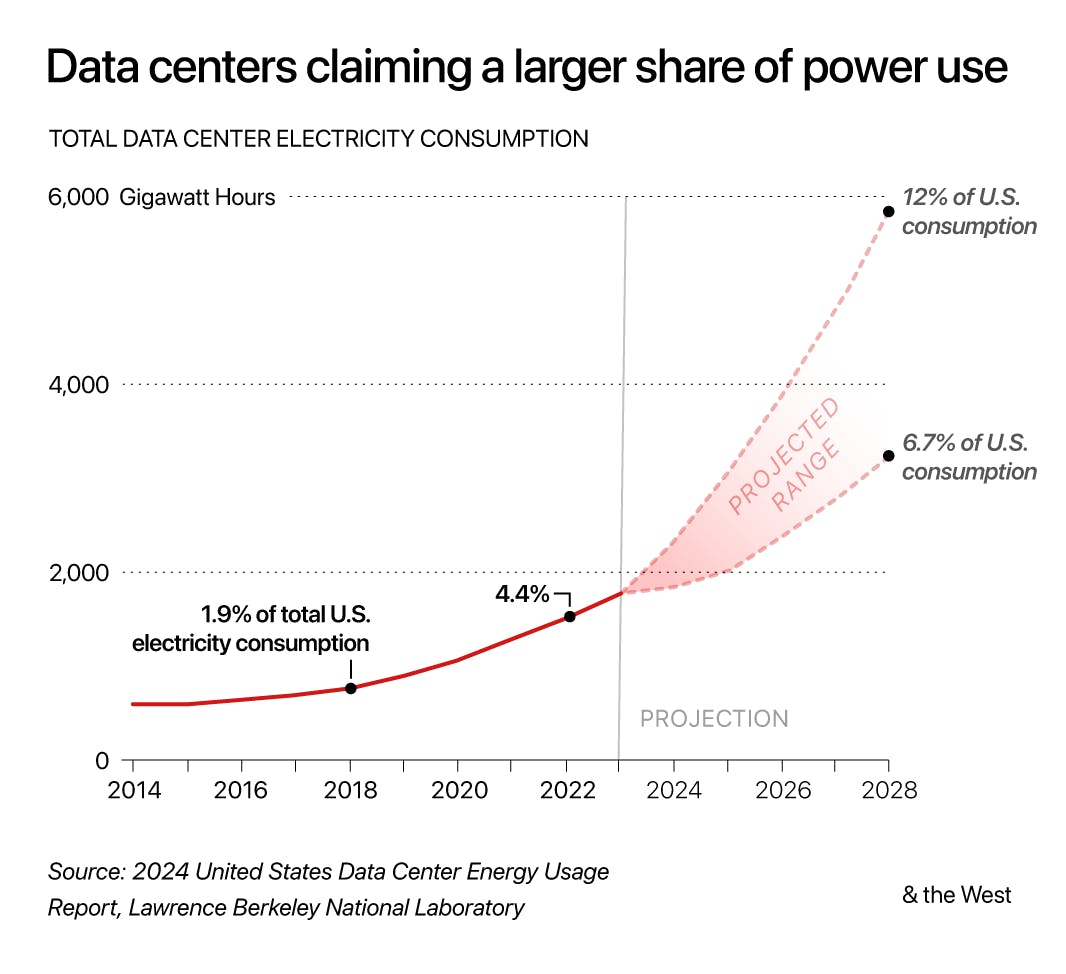
Source: DOE
Grid Upgrades
Electric grids insufficient to support data centers require updates, expansion, and new power sources to be brought online, raising the question of who is responsible for paying for the cost of grid upgrade projects: all power recipients from the grid, or those whose demands make the existing grid insufficient. As of August 2025, these costs are leveraged across all grid users, ideally proportional to their demands on the grid, though this is often not the case. One energy research study found that major energy electricity bills were insufficient to cover the costs of the equipment required to service them, meaning “the utilities either need to socialize the cost to other ratepayers or absorb that cost — essentially, their shareholders would take the hit.” Another report found that government-set energy prices incentivize the construction of large projects like data centers to the detriment of citizens via non-standard pricing methodologies, political incentives, and non-transparent energy usage information.
One study published in June 2025 found that energy demand from data centers and cryptocurrency generation infrastructure could raise electricity rates across the US by 8% on average by 2030. Without changes in power regulation or rating systems, electricity bills for civilians are predicted to increase up to 25% in places like Ashburn, VA, known as “Data Center Alley” and home to 140 data centers. Data center managers like Microsoft have stated that they have no intention of increasing power charges for individuals, though citizens are still resistant to new data center projects, given a history of opacity around the developments.
Rate hikes have already taken effect concurrent with data centers coming online in some areas, sparking controversy among critics who point to legislatures' refusal to hike rates in order to fund grid expansion to places without electricity, like Native American reservations. In response to these concerns, one California legislator has proposed that households and data centers use a different pricing schema. One Santa Clara planning committee chairman called data centers “the tapeworms of the city,” saying, “it consumes, it grows, it uses resources. It doesn’t kill you, but it doesn’t make you healthy.”
Some companies concerned about grid readiness and adaptability have begun exploring co-locating power sources alongside data centers. Meta is working to build a 300 MW solar panel field and battery array near Meta’s new data center in Mesa, AZ. Google has pledged to use only carbon emission-free electricity sources to power its operations, leading to the exploration of alternative energy sources, including solar, wind, geothermal, and nuclear power supplies. In August 2025, the Department of Energy announced the selection of 11 advanced nuclear reactor projects to receive federal funding to support bringing nuclear power online at industrial scale (Aalo Atomics, Antares Nuclear, Atomic Alchemy, Deep Fission, Last Energy, Oklo, Natura Resources, Radiant Industries, Terrestrial Energy, and Valar Atomics*).
How are AI Servers Cooled?
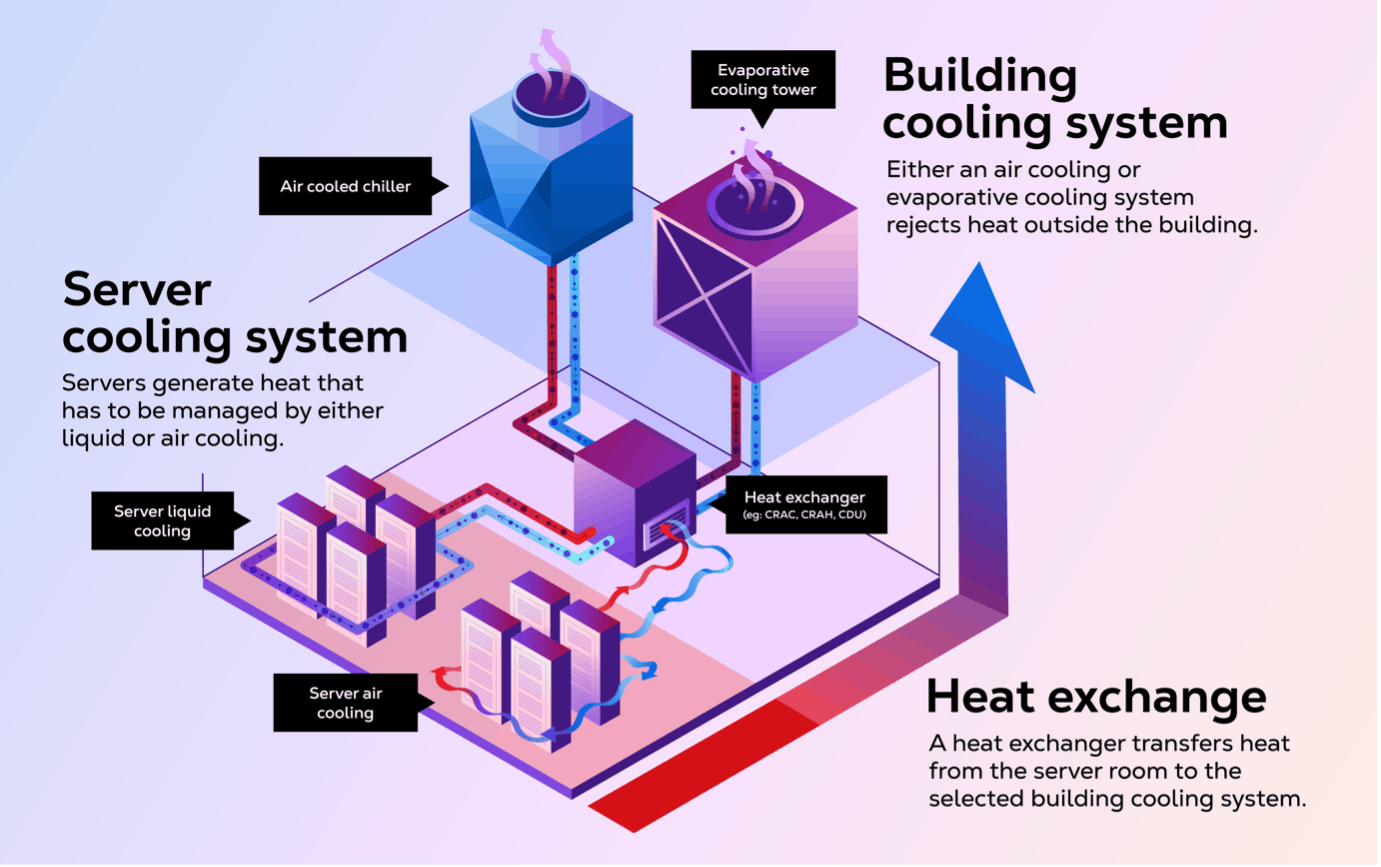
Source: CDO Trends
In addition to extreme power requirements, data centers require extensive cooling, with companies like Google and Meta utilizing billions of gallons of water each year in their facilities. The Department of Energy reported that US data centers used 5.6 billion gallons of water in 2014, a figure that had tripled to 17.4 billion gallons by 2023. Of this total, 84% was being used for the “hyperscale” data centers. These figures actually understate the total water use increase attributable to AI data centers, as they incur increases associated with both cooling server racks and cooling the power plants brought online specifically in response to AI data center demand.
Water use associated with AI data centers has impacted citizens living near a data center in Newton County, GA, where homeowners’ water supplies were contaminated and their wells went dry after the construction of a Meta data center that draws from the same water table. Citizens of other cities where data centers are planned have concerns that the same will happen to them, prompting some residents to even conduct water tests ahead of any new construction to have a baseline for comparison. Data center buildings at one planned development in Pennsylvania would each have their own well, with a footprint spanning two watersheds and potentially drawing down available well water for citizens in the surrounding communities.
In an effort to address the public perception surrounding data centers, Meta announced in February 2025 that by 2030, it would restore more water to the Mesa, AZ, region than it used in operations of its new data center being constructed there. Other companies, like Amazon and Apple, have pledged to use reclaimed wastewater in their data centers to avoid drawing on potable water supplies. Still others have used alternate names or shell corporations to purchase land to delay being associated with the projects. In July 2025, the White House released America’s AI Action Plan, a guide to the administration’s goals and commitments towards supporting US dominance in AI. This plan includes guidelines on AI Infrastructure that suggest AI Data Centers be granted special exclusions from environmental protection policies outlined in the Clean Water Act, the Clean Air Act, and other NEPA policies.
Alternatively, less water-intensive cooling systems are also being explored. Data centers exploring closed-loop cooling systems aim to reduce their water dependence by reusing cooling water multiple times. Some companies are even exploring free cooling, a method of cooling data centers with circulation of outside air for facilities in colder climates.
Where are AI Data Centers Built?
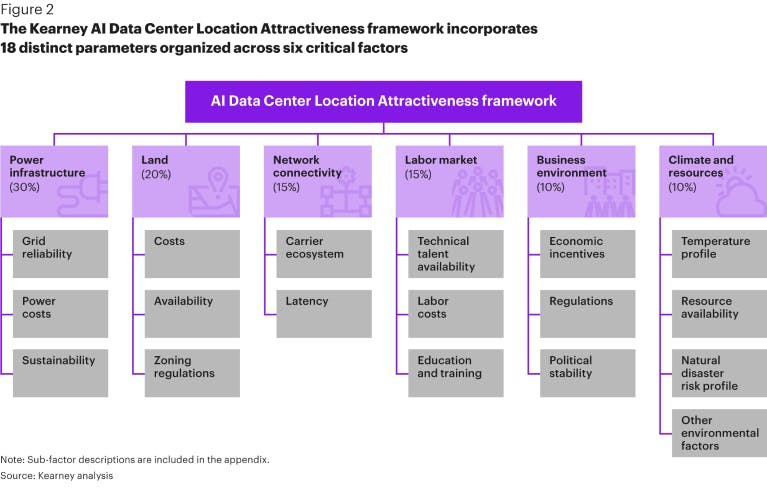
Source: Kearney
While electrical power remains the number one determinant of where data centers can be constructed, characteristics like tax incentives, fiber optic infrastructure, available construction workforce, and natural disasters also influence decisions about where to build. As of August 2025, all 50 states have data centers. Texas is home to the greatest number of data centers and the highest data center power consumption, with 346 data centers as of May 2025.
As of August 2024, a new data center was opening somewhere in the world every three days. Even with new data centers coming online, marginal increases in demand must be largely addressed with new construction because 75-85% of new data center capacity through 2029 has already been leased, with average leases lasting 7 years.
The scale of large AI data centers, known as “hyperscale” data centers, is hard to overstate. These data centers require land equivalent to seven football fields, making conversion of existing office parks and warehouses no longer an option, as had been the case for traditional data centers. The Digital Gateway project, a data center that was blocked from construction in August 2025, would require 2.1K acres and 750K homes’ worth of power. Stargate, an OpenAI data center under construction, is expected to create 100K construction and operations jobs, though the majority of these would not be permanent.
Land parcels available to accommodate projects of this size have seen prices increase by up to 40%. According to one report, there are three main ways that real estate companies participate in the development of AI data centers: (1) purchasing or leasing land that could be attractive to data center developers, (2) “flipping” land eligible for data centers by outfitting plots of land with basic power infrastructure, and (3) building out the shell of data centers, including buildings or “dark shells”, and even network connections or “powered shells”, and selling or leasing those properties to data center companies. Data center flippers have seen land sell for multiples of the original price. In OpenAI’s RFP for Stargate, the company laid out the quantitative and qualitative considerations it would want a potential development partner to make about the project.
Federal interest in accelerating data center construction in the United States has contributed to the scrutiny around potential data center sites. The Trump administration announced $90 billion in funding for AI infrastructure in Pennsylvania, despite protests against the environmental impacts expected from these projects. Trump also signed an executive order on July 23, 2025, outlining requirements for federal agencies to streamline the permitting process for AI data centers. In April 2025, the US Department of Energy identified 16 federal land sites that it considered suitable for potential data center construction.
In lieu of available land parcels, some data center developers are considering alternative sites. Google has launched a data center on the ocean floor, known as Project Natick, which is expected to operate for 25 years with an efficiency 40-60% greater than that of land-based data centers. Others have even considered the possibility of data centers in space, where colder temperatures and abundant solar radiation would mitigate some challenges with cooling and powering. Some proponents of California’s long-promised high-speed rail between San Francisco and Los Angeles have suggested leasing the land alongside the future railway to data centers and using solar grids to power both the trains and the data centers.
The New Oligopoly in Compute
Given its criticality and the costs associated with increasing supply, compute capacity is becoming the new oil: a small number of large players control the space, and newer participants must either partner with these behemoths or build their own operations. As of April 2025, the four largest US data center operators, Amazon Web Services, Microsoft, Google, and Meta, control 42% of US data center capacity. Frontier AI companies (Anthropic, OpenAI, Gemini/DeepMind, Llama) are dependent on these compute providers today, though some have ambitions to change that.
Hyperscalers
Amazon and Microsoft are the majority providers of cloud compute in the US, followed by Google and Meta. Amazon Web Services (AWS) hosts over 100 global data centers, housing over 1.4 million servers with a presence on every continent except Antarctica. Microsoft similarly hosts over 400 data centers around the globe via its Azure cloud computing arm. Google operates data centers in 11 countries globally, comprising 8% of the cloud infrastructure market as of 2023, behind Amazon and Microsoft. Meta is the fourth-largest data center operator globally, with leased and owned data centers in the US and abroad.
Hardware
Hyperscalers differ in that some rely on external hardware, like NVIDIA GPUs, while others rely on hardware designed in-house. AWS data centers use semiconductors Trainium and Inferentia designed for AWS by Israeli chip company Annapurna Labs, which are smaller and easier to cool than the widely used NVIDIA chips. Similarly, Google is the inventor of TPU AI chips, which it uses in its data centers, but does not sell. Meta has developed its own chips for its facilities via its Meta Training and Inference Accelerator (MTIA) program, and also uses NVIDIA GPUs.
By contrast, as of August 2025, Microsoft data centers are primarily built around NVIDIA GPUs. Microsoft rents a portion of its access to NVIDIA GPUs from cloud computing company CoreWeave, making up nearly two-thirds of CoreWeave’s 2024 revenue, up from 35% in 2023.
Key Customers
While some hyperscalers provide compute specifically to AI companies under the same parent company, others have key partnerships with external clients. Google’s primary AI data center customers are its own Gemini and DeepMind projects. Google has partnered with NVIDIA to build out open source resources for developers using NVIDIA and Google Cloud, optimize Gemini models for performance on NVIDIA chips, and bring Gemini models to private customer data centers on NVIDIA Blackwell chips. Google Gemini will be the first major AI model to be available to private data centers. Meta’s Llama open source models are also run on Meta compute, though they are configured to run on local clusters as well. Meta has made the models available to run on both AWS and Azure as well.
AWS and Microsoft represent the data-centers-as-a-service model. One of AWS’s key AI data center customers is Anthropic, which made AWS its primary cloud provider in exchange for Amazon’s investment of $8 billion in Anthropic as of August 2025. Microsoft Azure’s key AI data center customer is OpenAI. Microsoft has invested over $13 billion in OpenAI since 2019 in a series of deals that secured Microsoft the rights to 20% of OpenAI’s profits through 2030, allowed for integration of OpenAI models into Microsoft products, and limited OpenAI to use Azure as its sole cloud compute provider, among other considerations. In January 2025, Microsoft and OpenAI amended this agreement to allow OpenAI to use cloud services provided by other companies, including Microsoft’s competitors.
Expansion Plans
One thing that all hyperscalers have in common is ongoing investment to scale operations. In early 2025, Amazon announced plans to expand data centers in Pennsylvania, Georgia, and Ohio. Reports surfaced in April stating that AWS had paused some data center lease commitments; AWS responded that this was “routine capacity management”. AWS is building a 2.2 gigawatt data center on 1.2K acres in Indiana specifically for Anthropic. This new data center is the first to be built by AWS as part of Project Rainier, AWS’s effort to stand up a computing cluster 5x the size of Anthropic’s cluster as of August 2025.
In January 2025, Microsoft shared that it planned to spend $80 billion on new and existing cloud data centers for AI applications. In March 2025, however, it was reported that Microsoft had abandoned several data center projects in the United States and Europe, which were then picked up by Google and Meta.
Google has invested $25 billion in constructing new data centers in North America in 2025 and 2026, which includes planned developments in Texas, Virginia, South Carolina, and Indiana. Google has also invested $6 billion in a 6-gigawatt data center in India and $1 billion in a 100-megawatt data center in the UK.
Meta has announced plans to invest hundreds of billions in AI data centers in the coming years, including up to $72 billion in 2025 alone. These investments will be financed in part by the sale of over $2 billion of existing data center land and construction assets, and in part by private credit facilities. The company has announced several new data centers in 2025, including Prometheus in Ohio and Hyperion in Louisiana, which are expected to run at 1 and 5 gigawatts, respectively. Concerns have been raised about these projects, given the issues with Meta’s data center under construction in Newton County, GA, where homes near the new data center have lost water access. Prometheus is an extension of an existing data center complex, which is being constructed under tents to speed development.
Despite these expansion efforts, as of August 2025, Meta requires more compute than its own data centers can provide, relying historically on cloud infrastructure from AWS and Microsoft and signing a $10 billion contract to use Google Cloud data centers for the next six years.
Vertical Integration Push
Alongside the expansion of hyperscale data centers, Frontier AI companies, traditional data center operators, and AI hardware manufacturers are pursuing AI cloud compute capacity. Frontier AI companies are looking to vertically integrate compute clusters under their own operations, while traditional data centers and hardware manufacturers are aiming to capitalize on the demand for AI compute while leveraging their existing operations.
Frontier AI Companies
OpenAI
OpenAI is one of the frontier AI companies that has most publicly discussed plans to bring its own data centers and power sources online in the near future. Under its 2025 operating model, OpenAI is not expected to turn a profit until 2029, though Microsoft is likely to profit off its arrangement with the company in the meantime. In January 2025, OpenAI announced Project Stargate, a new effort intending to invest $500 billion in US AI infrastructure for OpenAI from 2025 to 2029. Project Stargate was funded by SoftBank, OpenAI, Oracle, and MGX. OpenAI announced a partnership with Oracle to build a 4.5 gigawatt datacenter in Abilene, TX as part of Project Stargate in July 2025, at the same time OpenAI was released from its compute exclusivity agreement with Microsoft. The Project Stargate data center is set to come online as early as summer 2026, with completion in early 2027. It isn’t clear whether Project Stargate plans to pursue assembly of chips for AI stacks as well as data centers.
Separate from the Project Stargate development underway, Sam Altman has also previously stated his intentions to raise trillions to revolutionize chips for AI, and ultimately the entire AI hardware stack. In August 2025, Sam Altman reinforced that, saying “you should expect OpenAI to spend trillions of dollars on data center construction in the not very distant future.”
xAI
As of August 2025, xAI is building a series of supercomputers called Colossus to power its AI model training and execution. The first Colossus supercomputer is in Memphis, and was built in only 122 days, far faster than external estimates or comparable data centers. Citizens of Memphis near the supercomputer have complained of unpermitted gas emissions from turbines taking an extreme toll on local air quality, causing asthma and COPD episodes. xAI announced in July 2025 that it would be importing a power plant for a new data center, though it has not said from where. In July, xAI raised $12 billion in debt to fund Colossus 2 and purchased a former gas power plant site in Southaven, Mississippi, to help power the project.
DeepSeek
While there is not much publicly available information about the data centers used by leading Chinese AI lab DeepSeek, the company’s research papers report that its models were trained on NVIDIA GPUs, which analysts speculate were supplied by lead investor High-Flyer Capital Management. Because DeepSeek runs its own data centers, it can optimize compute configurations specifically for enterprise needs.
Traditional Data Centers
Oracle
As of August 2025, Oracle is a newer provider of AI-suitable data centers, partnering with OpenAI for the Stargate Project in a deal that will supposedly net $30 billion per year for Oracle, compared with a total cloud services revenue from all customers of $24.5 billion in fiscal year 2025. Oracle said in June 2025 that it expected to spend almost $50 billion on new data centers over the next two years, though it's unclear how much of this is part of Project Stargate.
Oracle is also building a 1.4 gigawatt data center in Shackelford County, TX, that is powered exclusively by on-premise gas generators, given electricity limits in the area. Oracle CEO Larry Ellison, who once called cloud computing “complete gibberish”, said in March 2025 that Oracle will be “the #1 builder and operator of cloud-infrastructure data centers,” and operate more of such data centers “than all of our cloud-infrastructure competitors combined.”
CoreWeave
CoreWeave, a New Jersey company that started out building GPU stacks for Ethereum mining, has become a notable cloud computing provider as of August 2025. CoreWeave operates data centers dedicated to individual clients, including IBM, Microsoft, and NVIDIA, as well as smaller AI companies and visual effects labs. CoreWeave went public in March 2025, despite widespread criticism of the company’s financials and business model, and the company founders selling $500 million in equity prior to the IPO. CoreWeave’s market cap as of August 2025 is over $50 billion, up more than 135% from its IPO.
As of August 2025, Microsoft rents a portion of its access to NVIDIA GPUs from CoreWeave, with Microsoft making up nearly two-thirds of CoreWeave’s 2024 revenue, up from 35% in 2023. In March 2025, CoreWeave announced a contract with OpenAI that will earn $11.9 billion over five years. Given this deal and a number of others, CoreWeave expects Microsoft to make up less than 50% of its revenue going forward. In March 2025, OpenAI invested $11.9 billion in CoreWeave in exchange for $350 million equity in the company, a decision that analysts see as another effort from OpenAI to reposition itself relative to its dependence on Microsoft for compute.
Foxconn
In August 2025, Foxconn announced that its revenue from AI data centers exceeded that of manufacturing, which typically makes up 20-30% of its annual revenue, for the first time. Foxconn is building data centers in Taiwan as well as the US, where it is working with SoftBank to build equipment for the Stargate project. Foxconn completed a share exchange with TECO Electric & Machinery Co. in July 2025 to better enable assembly of AI data centers.
AI Hardware Manufacturers
Groq
Groq is a semiconductor manufacturer that primarily creates chips for AI hardware stacks and is one of the primary competitors to NVIDIA. Unlike NVIDIA, Groq operates data centers built up from its own hardware, with operations in the US, Canada, Saudi Arabia, and Finland. NVIDIA does not operate any large-scale data centers of its own. Groq has not publicly shared the customers of its AI data centers versus its other hardware products.
Groq’s newest data center is in Helsinki, where the relative availability of geothermal energy and colder climates make the location compelling for data center construction. Potentially following Groq’s lead, Jensen Huang signed infrastructure deals for development in Germany, Italy, and Armenia in June 2025, saying that AI computing capacity in Europe will grow by a factor of 10 in the next two years.
Underlying Imbalance
Vertical integration and expansion of existing operations to include AI data center operation may change who pays utility providers directly, but doesn’t change the underlying economic imbalance of AI companies unless pricing for model users increases substantially. Put differently, data center “middlemen” are not effectively selling power to AI companies for orders-of-magnitude multiples above the raw costs, meaning the calculus is relatively unchanged by cutting these players out and connecting to power sources directly.
While the development of new AI data centers, both from hyperscalers and from other players, may not address the underlying economics of AI business models, there may still be benefits from improvements to the grid and integration of renewable energy sources. Infrastructure build-out ahead of profitable demand is one of the biggest benefits of a potential bubble. For example, the networking build-out led by Cisco during the dotcom bubble laid the groundwork for the future ubiquity of the internet.
The Real AI Bottleneck: Power
If funding for AI companies and government encouragement of American data center construction continue, the capacity of AI data centers in the US could increase 2.7x between 2025 and 2030. Bringing trillions of dollars of new infrastructure online, however, is not possible without substantive upgrades to the existing US grid and access to new power sources. Hyperscalers anticipating bottlenecks in power, even in locations selected for their proximity to grids with available capacity, are exploring alternative power sources and scrutinizing where power is spent in running AI models.
Microsoft is investing in bringing new power sources online to service its data centers, including signing a contract with Constellation Energy in October 2024 to bring back online a Pennsylvania nuclear energy plant at the site of the 1979 partial meltdown at Three Mile Island. Meta is also pursuing bringing dedicated energy sources online for data centers, including building new power plants, like its co-located solar arrays in Arizona, specifically to power these new data centers.
Similarly, Google made news in August 2025 by announcing a deal with Kairos Power and the Tennessee Valley Authority (TVA) to direct up to 50 megawatts into the TVA grid, which services Google data centers in Tennessee and Alabama, from Kairos’s Hermes 2 Plant in Oak Ridge beginning in 2030. Google has pledged to use exclusively carbon-free energy sources for its data centers and has invested in geothermal, fission, fusion, and other solar energy sources. AWS data centers also use exclusively carbon-free power sources (via renewable energy matching), making Amazon the largest corporate buyer of renewable energy in the world for the last 5 years.
Proponents of nuclear and other renewable energies are hopeful that AI can become the driving customer of next-generation nuclear and energy infrastructure that may one day be used for all electrical grids, not only those associated with data centers. Even if this transpires, it may not happen soon enough to correct the economic imbalance AI companies face as of August 2025. Demand may outstrip supply even faster than innovation can reduce costs, a pattern that has borne out in the skyrocketing costs of semiconductors. The role of the government in regulating energy prices could mitigate the cost of power in the adjustment period, but only if those costs were passed to other grid users.
Sustainability of the AI Build-Out
AI is now the US economy’s single largest driver of growth, but it is built on economics that are fundamentally unstable as of 2025. Investors and technologists alike are reconsidering whether AI progress and investment can continue at the same breakneck pace: will efficiency gains, new hardware paradigms, and novel energy sources keep the boom going? Or will the mismatch between falling unit costs and ballooning total costs eventually break the business model entirely?
Unless models evolve to achieve the same performance in meaningfully more efficient ways (e.g., evolution away from transformer architecture), the future of AI hinges less on progress in algorithms and far more on the economics of industrial-scale infrastructure.
*Contrary is an investor in Valar Atomics through one or more affiliates.





