
Thesis
In June 2024, it was estimated that OpenAI spends five times more on AI compute than its human workforce. This spend is driven by the cost of graphical processing units (GPUs), specialized electronic devices capable of handling computationally intensive tasks like machine learning, mathematical modeling, and video editing. Since the release of ChatGPT in September 2022, the demand for GPUs has surged.
OpenAI CEO Sam Altman believes AI “positions GPUs as a critical asset, akin to a new form of currency in the digital age” which will grow in importance as AI advances. Scale AI founder Alexandr Wang pointed out that more than $100 billion had been spent on NVIDIA GPUs as of 2024. GPT-4 cost an estimated $78 million to train and Google’s Gemini cost $191 million. With the increasing complexity of these models, the amount of compute required grows. From 2018 to 2024, the average compute required for training a frontier model increased by 4.2x.
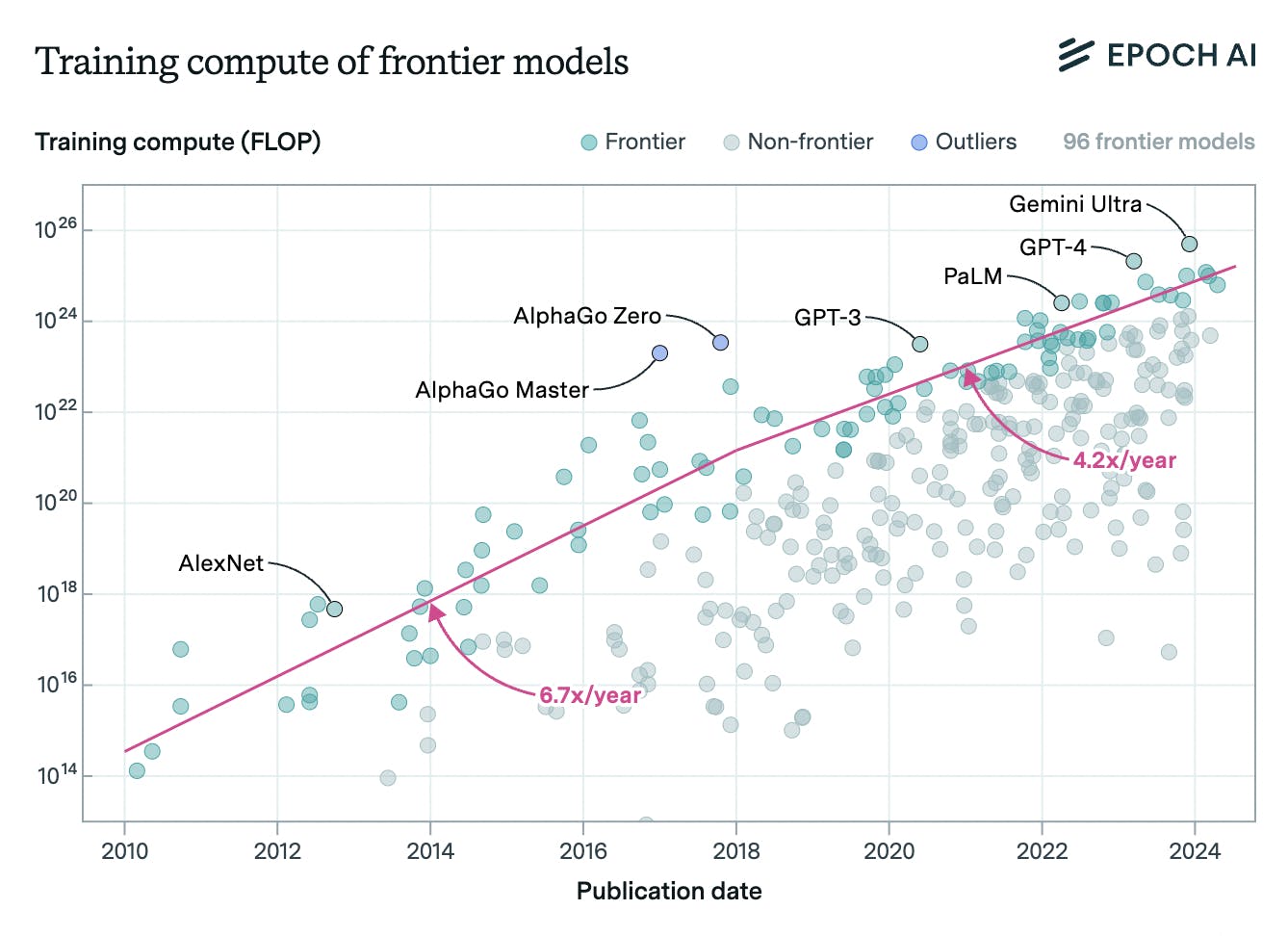
Source: Epoch AI
However, the cost of GPUs is a bottleneck for AI startups. Startups often lack both the necessary access to these highly sought-after GPUs — largely dominated by manufacturers like NVIDIA — and the billions of dollars companies like Microsoft and OpenAI can invest. Despite a growing demand for GPUs, supply remains constrained. While more than 10 million GPUs were deployed globally as of March 2024, many are neither efficiently utilized nor fully optimized for computing tasks. In 2018, OpenAI estimated that only 33% of GPU capacity was effectively used in heterogeneous workloads. Furthermore, many companies reserve a portion of their GPU processing power as a “healing buffer,” kept idle to mitigate potential failures during AI training workloads, further limiting their active utilization.
Foundry provides compute on-demand, offering users access to NVIDIA’s most advanced GPUs designed for complex computational tasks. These GPUs can be leveraged for a variety of use cases, including fine-tuning machine learning models, training large-scale AI systems, and running inference operations Users have the flexibility to reserve compute resources for periods ranging from a few days to several weeks, enabling them to harness processing power tailored to their project timelines. This model delivers a solution for scaling-intensive workloads without the need for long-term infrastructure investments.
Founding Story
Jared Quincy Davis (CEO) founded Foundry in September 2022. Davis began his undergraduate education at Washington University of St. Louis in 2013, where he earned a full-merit scholarship and completed a double major in mathematics and computer science by 2016. He began his career as an associate at BCG, then moved to KKR as an associate in 2018 where his work centered around data center projects. In 2020, he went on to pursue a PhD in computer science at Stanford, specifically in machine learning.
While at Stanford, Davis was inspired by Google DeepMind’s AlphaGo, an AI model that mastered the complex game of Go using deep neural networks and reinforcement learning. AlphaGo gained fame in 2016 when it defeated world champion Lee Sedol, showcasing AI’s potential for strategic thinking. As a result, he began working for Google’s DeepMind as a research scientist in 2020:
“Part of the reason I started working in deep learning was I saw AlphaGo from DeepMind and I thought that technique, if extended to real-world problems, can be pretty transformative, but there are some limitations in that initial approach that made it not quite viable for problems at scale. So, I actively started working on filling those gaps.”
Davis’ advisor at Stanford was Matei Zaharia, the co-founder and CTO of Databricks. While working on his thesis, Davis had to reserve specific time slots to utilize the GPUs necessary to train his models. He and other students had to reserve time slots on Google Sheets to use the coveted hardware for finite amounts of time. Underutilization and poor allocation of resources were proving to be a bottleneck for his research, and Davis had noticed no practical solution for this inefficiency. As a result, he became increasingly cognizant of the market opportunities and tailwinds in the AI market.
In August 2024, Davis reflected that the most inspiring moments of his career were the release of AlphaFold 2 and ChatGPT. AlphaFold, developed by Google DeepMind, revolutionized biology by predicting a protein's 3D structure from its amino acid sequence — solving a 50-year-old challenge. According to Davis, the success of both innovations was driven by the availability of immense computational power for research labs.
Building on this momentum, Davis launched Foundry in September 2022 which he described as a “rare mix of technically rich and compelling, and near-term, economically viable.” Two months later, OpenAI released ChatGPT, which garnered global attention to the tune of 100 million weekly users a year after launch. With compute capabilities suddenly at the forefront, Foundry’s niche became more valuable.
Product
Foundry is a cloud platform tailored for AI workloads. It provides on-demand GPU access, enabling users to train, fine-tune, and run inference models. Foundry offers flexible compute options that can be reserved for as little as three hours, or longer term if needed. This flexibility is coupled with features like orchestration through Kubernetes and reliability systems to prevent downtime from hardware failures.
Foundry Cloud Platform
Reserved instances: Reserved instances for Foundry refer to compute resources that users can pre-book for specific periods, ensuring dedicated access to GPUs for their AI workloads. Specific time blocks are marked down for the desired duration, ranging from three hours to two weeks in increments flexible starting from 1 hour. Dedicated virtual GPUs are allowed for utilization during these specific times.
The process is completed in four steps — the user chooses the instance type and quantity, reserves specific time slots, acknowledges pricing, and is confirmed. Reserving compute instances can save 12x to 20x on price performance compared to other solutions. Unused instances can also be resold and saved as credit for future projects. Reserved quotas are the maximum number of future-reserved hours. Reserving one GPU instance for 36 hours is the same as four instances for nine hours, allowing time to be freed up in the reservation
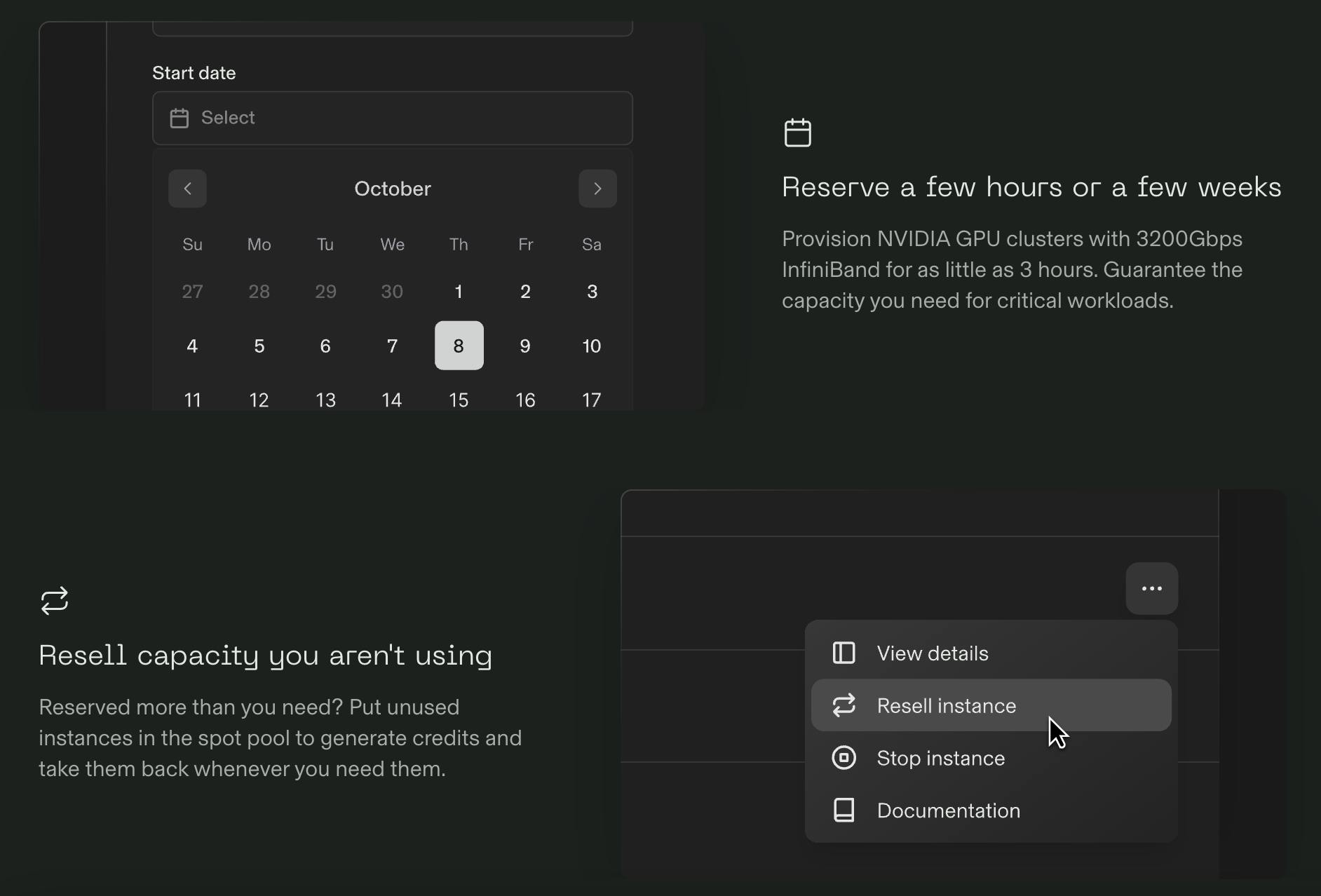
Source: Foundry
Spot instances: Spot instances for Foundry are compute resources offered at discounted rates by utilizing unused GPU capacity. Instantaneous blocks for virtual machines are calculated through price bids, where users can have immediate access to compute if their bid is higher than the market price. If the user is outbid, they will be pre-empted with a five-minute warning. A successful bid turns into an allocation to be accessed. Higher bids can be placed in urgent situations, while lower bids can be reserved for projects with less intensive timelines. Spot quotas are the maximum number of concurrent instances that can be run during a session.
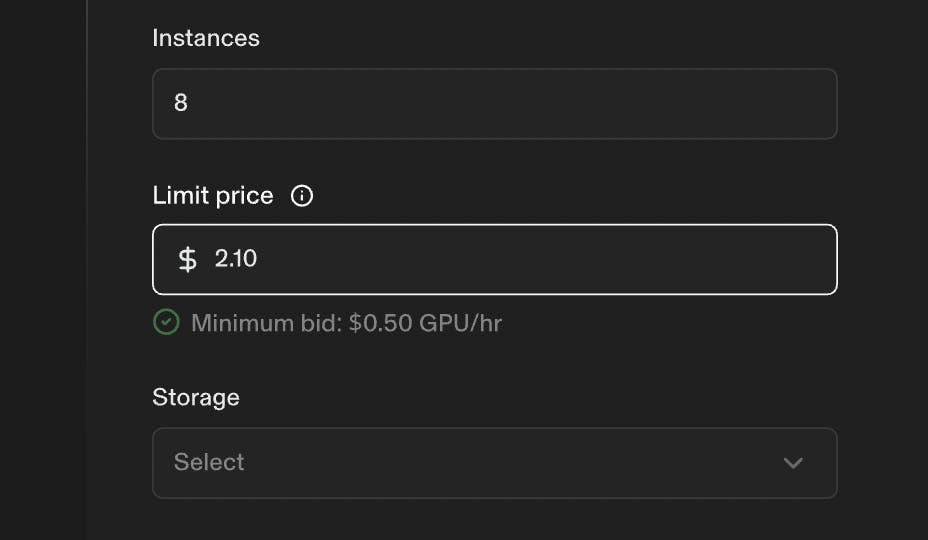
Source: Foundry
Foundry offers four different types of NVIDIA GPUs for utilization. A single instance of any GPU can offer up to 80 GB of memory, eight in quantity, 192 CPU cores, and over 2K GB of RAM. This allows users to scale compute power according to the scale required. The available GPUs, ranked from least to most powerful, are as follows:
A40 PCIe: Primarily operating as a workstation GPU, this is designed to offer rendering capabilities, but less so for powerful AI compute. It provides 5x throughput compared to previous iterations of the hardware, and it can offer around 37 teraFLOPs of single-precision compute power.
A5000 PCIe: The A5000 is a more powerful version of the A40, and can begin managing some extent of graphics or machine learning workflows, but is still geared primarily towards engineers and creatives. It can deliver around 80 teraFLOPs of single-precision compute.
A100 SXM: The A100 is the “engine of the NVIDIA data center platform”, with up to 20x higher performance compared to previous generations and accelerating CPU throughout by 249x. The SXM is proprietary to NVIDIA, and designed for the highest performance of GPU connection. It is generally optimal for “large-scale AI workloads.” It can deliver up to 312 teraFLOPS of deep learning compute.
H100 SXM: The H100 is a stronger model of the A100, capable of reaching four petaflops at 6x faster speeds, a 50% increase in memory, and training model transformers up 6x faster. This comes at a price tag that is 1.5-2x higher yet operates at 3x performance. Utilized to “accelerate exascale workloads” at billions of computations per second, the H100 is shown to improve LLMs innovation by 30x compared to previous legacy models. It can deliver more than 1K teraFlops of compute.
Accessing instances is possible through an IP address and an SSH key, which is an access credential in the SSH protocol. Instances have their own respective ephemeral (temporary) storage, which is available for no additional cost. Persistent disks can also be created in each region, which can store large quantities of data and accelerate workloads. Foundry also offers native Kubernetes, a cloud-native architecture, to improve workflow organization.
Market
Customer
Foundry says its product was built for AI engineers, researchers, and scientists. AI hardware can cost millions of dollars to own, Foundry is designed to offer an affordable alternative. Foundry is also an option for enterprises, as it claims it can save such companies up to 20x on price performance. As of March 2024, enterprise customers such as KKR and LG have used Foundry for compute resources. Other notable customers include Arc Institute, Harvard Data Science Institute, and Infinite Monkey.
Market Size
Foundry falls under the infrastructure-as-a-service market, which was estimated globally to be valued at $130 billion in 2023, and is projected to grow at a CAGR of 21.4% to reach $738 billion by 2032. It also taps into the cloud computing market, globally projected to be valued at $2.3 trillion by 2032. It is estimated that 67% of the worldwide cloud computing market is dominated by four major companies as of May 2024: Amazon Web Services, Microsoft Azure, Google Cloud, and Alibaba Cloud.
Growth in compute demand, driven by AI advancements, could drive Foundry's expansion. For instance, in February 2024, Sam Altman was seeking between $5 trillion and $7 trillion to establish semiconductor plants to boost GPU production. Additionally, the generative AI chip market was projected to reach $50 billion by year-end and the GPU-as-a-service market is expected to grow from $6.6 billion in 2023 to $61 billion by 2031.
Competition
Startups
Run:ai: Run:ai was founded in 2018 and has raised $118 million in total funding as of December 2024. Its focal product is the Run:ai Cluster Engine, which includes an AI workload scheduler, GPU fractioning, node pooling, and container orchestration to optimize GPU utilization. All of these facets are combined to optimize workloads on infrastructure, which can save up to 10x. In April 2024, NVIDIA acquired Run:ai for somewhere between $700 million and $1 billion. In NVIDIA’s announcement article, it released an acquisition memo that stated:
“Together with Run:AI, NVIDIA will enable customers to have a single fabric that accesses GPU solutions anywhere. Customers can expect to benefit from better GPU utilization, improved management of GPU infrastructure, and greater flexibility from the open architecture.”
While Foundry provides on-demand GPU compute for training and inference, Run:ai focuses on managing and scaling these resources efficiently across both on-premises and cloud environments. With its emphasis on AI workload management, resource scheduling, and cost optimization, Run:ai positions itself as a competitor by targeting organizations that need to optimize their GPU usage for AI projects at scale.
Union: Union was founded in 2020 and had a total funding amount of $29.1 million as of December 2024. Union focuses on AI optimization through consolidating resources and workflow efficiency. The platform “offers software that helps in maintaining and managing deployments, setting up Kubernetes infrastructures, and provisioning security and data policies”. Like Foundry, Union targets users who need scalable, high-performance computing power for training and inference of machine learning models. With a focus on flexibility, accessibility, and cost-effective solutions, Union positions itself as a competitor in the GPU-as-a-service space, catering to businesses and researchers with dynamic compute needs.
RunPod: RunPod was founded in 2022 and has raised a total of $22 million as of December 2024. The company allows users to deploy GPU workloads to simplify machine-learning processes. It offers 50+ preconfigured environments for deployment. Runpod competes with Foundry by providing on-demand GPU cloud computing services tailored for AI and machine learning workloads. Similar to Foundry, Runpod offers scalable access to powerful GPUs, allowing users to rent compute resources as needed for tasks like model training and inference. With a focus on flexibility and cost efficiency, Runpod positions itself as a competitor in the GPU-as-a-service market, targeting users who need dynamic compute resources for AI projects.
Salad: Salad was founded in 2018 and has raised a total of $37.2 million as of December 2024. Its product allows users to deploy AI/ML models on its selection of GPUs, which can lead to savings of up to 90%. Salad competes with Foundry by utilizing a decentralized model that harnesses idle consumer hardware, such as gaming PCs, to create a distributed network of GPU compute resources. This approach contrasts with Foundry’s centralized cloud model and offers a cost-effective alternative for AI training, rendering, and other high-performance computing tasks. Salad’s ability to scale using everyday devices positions it as a disruptive competitor in the GPU-as-a-service market.
Together AI: Together AI was founded in 2022 and has raised a total of $228.5 million at a valuation of $1.1 billion as of December 2024. The platform provides access to Together GPU Clusters, comprised of NVIDIA’s H100, H200, and A100 GPUs. It offers 3.2K Gbps of networking speed, more than twice that of Amazon Web Services. Together AI competes with Foundry by providing open-source AI models and infrastructure optimized for training and inference at scale. Its cloud platform focuses on offering collaborative and accessible tools for building large AI systems, targeting researchers and developers. This emphasis on open-source solutions and cost-effective compute resources positions Together AI as an alternative for organizations seeking flexibility and transparency in their AI workloads, overlapping with Foundry's market focus.
OctoAI: OctoAI was founded in 2019 and has raised a total of $131.9 million as of December 2024. Its goal is to accelerate machine learning deployment for enterprises, through OctoAI, to allow adjustments to suit hardware for the correct use cases. Its products are most optimized for text and media generation. Octo AI competes with Foundry by offering a platform for on-demand GPU cloud computing, focused on AI model training and inference. Similar to Foundry, Octo AI provides scalable compute resources, enabling users to access powerful GPUs without the need for heavy upfront investment in hardware. Its emphasis on flexible, cost-efficient GPU-as-a-service options positions it as a competitor to Foundry in the growing AI cloud computing space.
Public Companies
Nebius AI: Nebius AI, owned by Nebius Group, was founded in 2022 to build everything from search to autonomous transportation. Nebius Group went public on the NASDAQ in 2011 and has a market cap of $6.3 billion as of December 2024. Nebius AI, one of four companies owned under Nebius Group, is a cloud platform offering scalable and flexible tools for developing, deploying, and managing AI models and machine learning workflows. Similar to Foundry, it offers a GPU auction functionality for utilizing L40s, H100, and H200 compute. According to Nebius CEO Arkady Volozh, the company is a “great cloud partner in NVIDIA” as it has access to the latest of NVIDIA’s GPUs. The Netherlands-based firm operates in a nearly identical niche to Foundry, posing direct competition.
NVIDIA: NVIDIA was founded in 1993, and has a market cap of $3.6 trillion as of December 2024. NVIDIA is the largest maker of GPUs in the world, and it had an 80.2% market share in Q2 2023. NVIDIA develops GPUs, but it could aim to make a long-term play in GPU accessibility. Foundry’s driving differentiation is the market platform that it advertises and sells instances of GPU usage. The GPU technology utilized is proprietary to NVIDIA, so the supplied technology has no intrinsic moat. Were NVIDIA to delve into a similar venture, it could be a major danger to Foundry’s appeal.
Amazon: Amazon was founded in 1994, and has a market cap of $2.4 trillion as of December 2024. AWS announced plans for an AI supercomputer called “Ultracluster" in December 2024, built with hundreds of thousands of its Trainium chips. The cluster, called Project Rainier, will support AI startup Anthropic, which, in November 2024 Amazon invested an additional $4 billion in. Project Rainier is expected to be operational in 2025. Additionally, AWS introduced a new server, Ultraserver, featuring 64 interconnected chips, at its re:Invent conference in Las Vegas in December 2024.
Amazon's Ultracluster and Foundry both provide AI compute power, but they target different needs. AWS's Ultracluster is an enterprise-focused infrastructure designed for large-scale AI model training, offering extensive resources for companies like Anthropic. In contrast, Foundry emphasizes flexibility and scalability, targeting startups and larger companies alike with on-demand, high-performance AI compute solutions. While both offer AI training capabilities, Foundry may appeal more to those seeking tailored, accessible options at potentially lower costs, while AWS focuses on offering vast, cloud-based compute power suited to larger, enterprise-level projects.
Business Model
Foundry operates on a usage-based pricing model, charging users based on the specific compute resources and time consumed during tasks on its GPU infrastructure. Market prices for both reserved and spot instances are dynamically adjusted based on demand, but once a reservation is made, prices remain fixed for the duration of the booking. For users with consistent, long-term needs, traditionally reserved contracts can also be arranged upon request. As of December 2024, Foundry has not publicly disclosed detailed pricing specifications for its GPU offerings.
Traction
Early adopters of Foundry include large enterprises, research labs, and universities. Notable customers include KKR, LG, Core Investigator, Harvard Data Science Institute, Stanford, MIT, and Carnegie Mellon. Foundry also has cluster partnerships with VCs such as Lightspeed Venture Partners and Pear VC, allowing its portfolio companies to access Foundry’s platform. In an interview, Davis expressed that Foundry was posting eight figures in revenue as of March 2024.
Valuation
Foundry raised an undisclosed seed round led by Sequoia in September 2022. In March 2024, it emerged out of stealth with a $80 million Series A in March 2024 co-led by Sequoia and Lightspeed Venture Partners at a valuation of $350 million. Other notable investors include Microsoft Ventures (M12), Conviction, Jeff Dean (Chief Scientist at Google), Eric Schmidt (former Google CEO), Liam Fedus (founder of ChatGPT at OpenAI), Matei Zaharia (co-founder of Databricks), and George Roberts (co-founder of KKR).
Key Opportunities
Increasing Demand for Compute
The amount of training compute utilized in notable ML models has increased by an estimated 4.1x per year since 2010. In scientific research contexts, namely within researching hierarchical biological networks or structural systems biology, there has been an even more pronounced increase in demand. The training compute necessary for biological sequence modeling has been estimated to grow by 8.7x since 2018. These tailwinds within the demand for compute could continue to benefit Foundry.
Increasing Costs of Compute
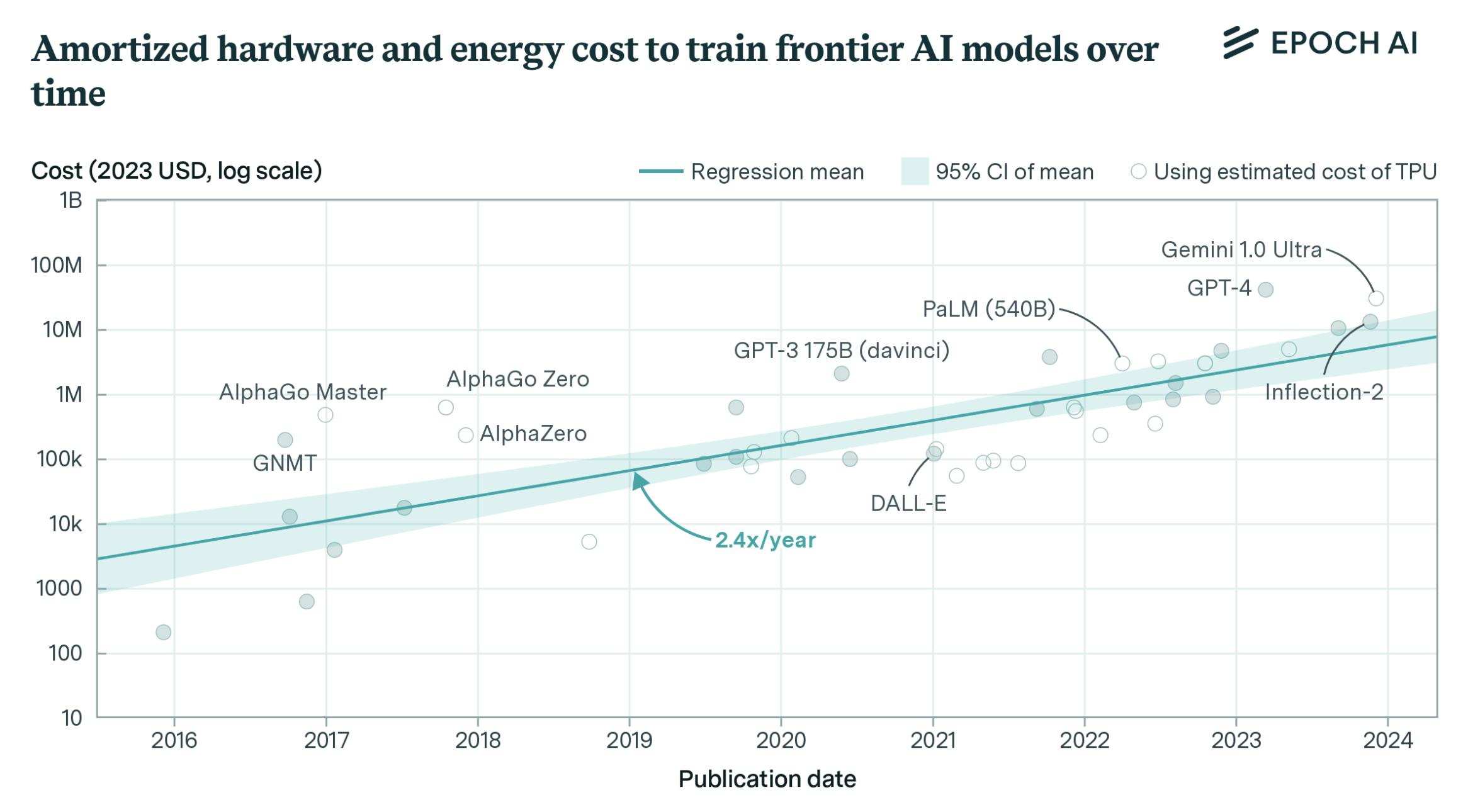
Source: Epoch AI
In June 2024, it was estimated that the total amortized cost of developing large-scale ML models like Gemini Ultra was around $130 million, excluding an additional $670 million required for hardware. The increasing scale of hardware resources needed for such models has driven up training costs, which have grown approximately 2.4x annually since 2016. Hardware acquisition costs have also increased by about 2.5x per year over the same period. This presents an opportunity for Foundry to optimize the efficiency and cost management of large-scale ML model development and deployment by streamlining workflows, improving resource utilization, and offering scalable solutions to address escalating training and hardware expenses.
Key Risks
GPU Dependence
Foundry relies on NVIDIA GPUs, including the available A100 SXM, H100 SXM, A40 PCIe, and A5000 PCIe. While it maintains a close partnership with NVIDIA as of 2024, Foundry could become solely dependent on this one partnership to maintain its business model. With such a close emphasis on this connection, some foresight is potentially required to avoid putting all eggs in one basket. With GPU shortages in 2024 exacerbated by both extreme demand and geopolitical tensions between the US and China in the semiconductor market, it might prove costly for Foundry scale in the future given continued waning supply. The increasing fear of an “AI bubble” is also a dangerous trend for the firm to consider for the future.
Regulatory Scrutiny of Incumbents
AI antitrust probes, particularly one against NVIDIA in 2024, could pose regulatory risks for the industry as a whole. NVIDIA faced two DOJ antitrust probes for its acquisition of Run:ai for $700 million in April 2024. While this may benefit Foundry as a competitor to NVIDIA which may be able to take market share, since Foundry also relies on NVIDIA GPUs it could also prove harmful.
Summary
Foundry is an on-demand AI compute company that provides users and enterprises with the ability to reserve compute, optimizing for the necessary processing and instances required. Its website interface provides ease of access and dynamic pricing to make state-of-the-art GPUs available at a fraction of competitor pricing. With a team comprised of veterans of Google DeepMind and Stanford, Foundry has been able to carve out a niche in the cloud computing industry. Foundry may need to ward off competitors operating in similar niches and also mitigate risks related to the growth of AI.




