
Thesis
Artificial intelligence has evolved rapidly from a research frontier into critical infrastructure across a broad set of industries. From fraud detection in finance to drug discovery in biotech or automation in manufacturing. Meanwhile, the breakthrough success of large language models from companies like OpenAI and Anthropic has accelerated AI adoption, creating high demand for specialized computational resources.
Graphics processing units (GPUs), originally designed for rendering video game graphics, have become the backbone of AI development. Training state-of-the-art AI models requires clusters of thousands of high-end GPUs working together for weeks or months, as model sizes have grown from millions to hundreds of billions of parameters. DeepSeek-R1 required over 2K NVIDIA H800 GPUs over roughly two months. NVIDIA's H100 and H200 chips, specifically designed for AI workloads, can cost $25-40K each. Throughout 2025, the AI industry has continued to experience a shortage of necessary resources.
Traditional cloud providers face a fundamental mismatch with AI requirements. Built primarily for web services and databases, hyperscalers have historically treated GPUs as expensive add-ons, creating friction through slow provisioning, limited availability, and pricing models designed for different workloads. But as companies scale AI from experiments to production systems, they increasingly need infrastructure built for machine learning workflows.
Lambda addresses this gap by focusing on AI infrastructure. The company operates GPU clusters featuring NVIDIA H100 and H200 chips that customers can access within minutes, compared to the longer wait times required through traditional cloud providers. Lambda also manufactures and sells pre-built workstations and servers equipped with multiple GPUs, allowing companies to bypass NVIDIA's direct sales process and lengthy procurement cycles. With its direct partnerships with NVIDIA, Lambda has secured priority allocation during chip shortages to maintain inventory when competitors face supply constraints. As demand for AI capabilities accelerates, Lambda provides the specialized hardware and cloud services that general-purpose providers struggle to deliver at scale.
Founding Story
Lambda was founded in 2012 by twin brothers Michael Balaban (CTO) and Stephen Balaban (CEO).
Stephen Balaban, who studied Computer Science and Economics at the University of Michigan, was the first engineering hire at Perceptio, a startup focused on developing deep neural networks for face recognition that could run locally on iPhone GPUs. Apple acquired Perceptio in 2015, at a time when on-device neural inference was still nascent.
Lambda’s founding was influenced by the founders’ encounter with two significant market events. First, during its product development, the prohibitive costs and friction of running machine learning models on AWS exposed the need for affordable, AI-optimized infrastructure. Second, in June 2012, Facebook acquired Face.com and abruptly shut down its beloved facial recognition API, which stranded over 45K developers who relied on it. During this time, Lambda quickly pivoted from building an internal contact book app called HeadsUp that used its computer vision algorithms to launch an open beta version of the Lambda Face API, providing an alternative to Face.com. The API was compatible with Face.com’s output and was initially free to use. Within a year, it amassed over 1K active developers from startups and international companies, processing more than 5 million API calls per month.
Following 2013, it began selling GPU-powered workstations and servers tailored to researchers and machine learning teams who lacked simple and cost-effective compute resources. The company began building internal GPU cloud capabilities to support its own and customers' growing workloads, years ahead of the broader "AI cloud" trend.
By 2017, Lambda had introduced Quad Deep Learning GPU workstations and the Lambda Blade server, achieving some of the world’s first ready-to-use deep learning supercomputers under $20K. In 2018, Lambda launched the Lambda GPU Cloud and Lambda Stack, a curated AI software repository that enables over 50K machine learning teams to focus on research, not infrastructure management. In 2022, Lambda, in collaboration with Razer, released the Lambda Tensorbook, a high-performance laptop specifically designed for deep learning. Through a series of major funding rounds beginning in 2021, Lambda significantly scaled its cloud platform, deploying thousands of NVIDIA GPUs in colocation data centers across the US.
Product
Lambda's product portfolio spans three primary categories: cloud infrastructure services, on-premise hardware systems, and software tools. The company's cloud offerings include on-demand GPU instances, reserved clusters for large-scale training, and private cloud deployments for enterprises requiring dedicated infrastructure. Lambda manufactures and sells GPU workstations and servers designed for AI workloads, from single-GPU desktop systems to multi-GPU enterprise servers. All products come pre-configured with Lambda Stack, the company's curated software environment, and other machine learning frameworks. This integrated approach allows customers to deploy AI workloads immediately without the configuration overhead typically required when assembling GPU infrastructure from multiple vendors.
1-Click Clusters
Lambda’s 1-Click Clusters (1CC) are geared toward teams training large models, allowing instant access to pre-configured NVIDIA GPU clusters with full InfiniBand interconnects. These clusters range from 16 to 512 H100s or B200s, launched in a few minutes with no management overhead. These clusters include both GPU nodes and 3 dedicated CPU management (head) nodes per cluster for administration and scheduling, with management nodes accessible via static public IPs and SSH for direct cluster control.
Teams get private, isolated networks for their clusters, passwordless secure access between machines, and tools to move data in and out. After a reservation ends, all data is securely wiped. Each cluster comes loaded with the latest ML libraries, Jupyter integration, and SSH access, enabling teams to expand their operations as needed. Each machine offers large NVMe storage for training data, and users can transfer files using popular tools, connect to private cloud storage, or just use built-in options from the dashboard. Clusters can be reserved for as little as one week, making them suitable for startups, research teams, and enterprise labs that need short-term high-density compute without CapEx.
In July 2025, Lambda announced that 1CC would integrate with NVIDIA’s Scalable Hierarchical Aggregation and Reduction Protocol (SHARP). SHARP offloads collective communication operations, such as allReduce, from CPUs and GPUs to the NVIDIA Quantum InfiniBand network, reducing latency and redundant data transfers. Internal benchmarks showed bandwidth improvements of roughly 45-63% across clusters ranging from 16 to 1.5K GPUs, with corresponding reductions in training iteration times. The feature is now available at no additional cost on Lambda’s 1CC infrastructure, provided users enable the SHARP plugin and adapt their training code to use SHARP-aware collective communication libraries. NVIDIA’s own tests cited 17% faster BERT training and up to an 8x reduction in communication latency on SHARP-enabled systems.
On-Demand Cloud
Lambda’s on-demand GPU cloud platform provides instant access to NVIDIA GPUs, including H100, H200, B200, GH200, and A100. Instances are billed by the hour with no long-term contracts, and customers can manage their infrastructure through a web dashboard, CLI, or REST API, enabling full automation. Lambda supports multi-GPU and multi-node configurations, and all instances are backed by high-speed NVIDIA Quantum-2 InfiniBand networking, low-latency NVMe storage pools, and high-bandwidth compute-to-network ratios suitable for distributed LLM training. All data transfers have no egress fees, and customers benefit from minute-level billing, volume discounts, and optional reserved pricing.
Private Cloud
Lambda’s Private Cloud product delivers secure, air-gapped, reserved GPU clusters dedicated to single enterprises. Clusters are deployed in Lambda-hosted, SOC 2 Type II-certified data centers and are ideal for companies operating in regulated industries.
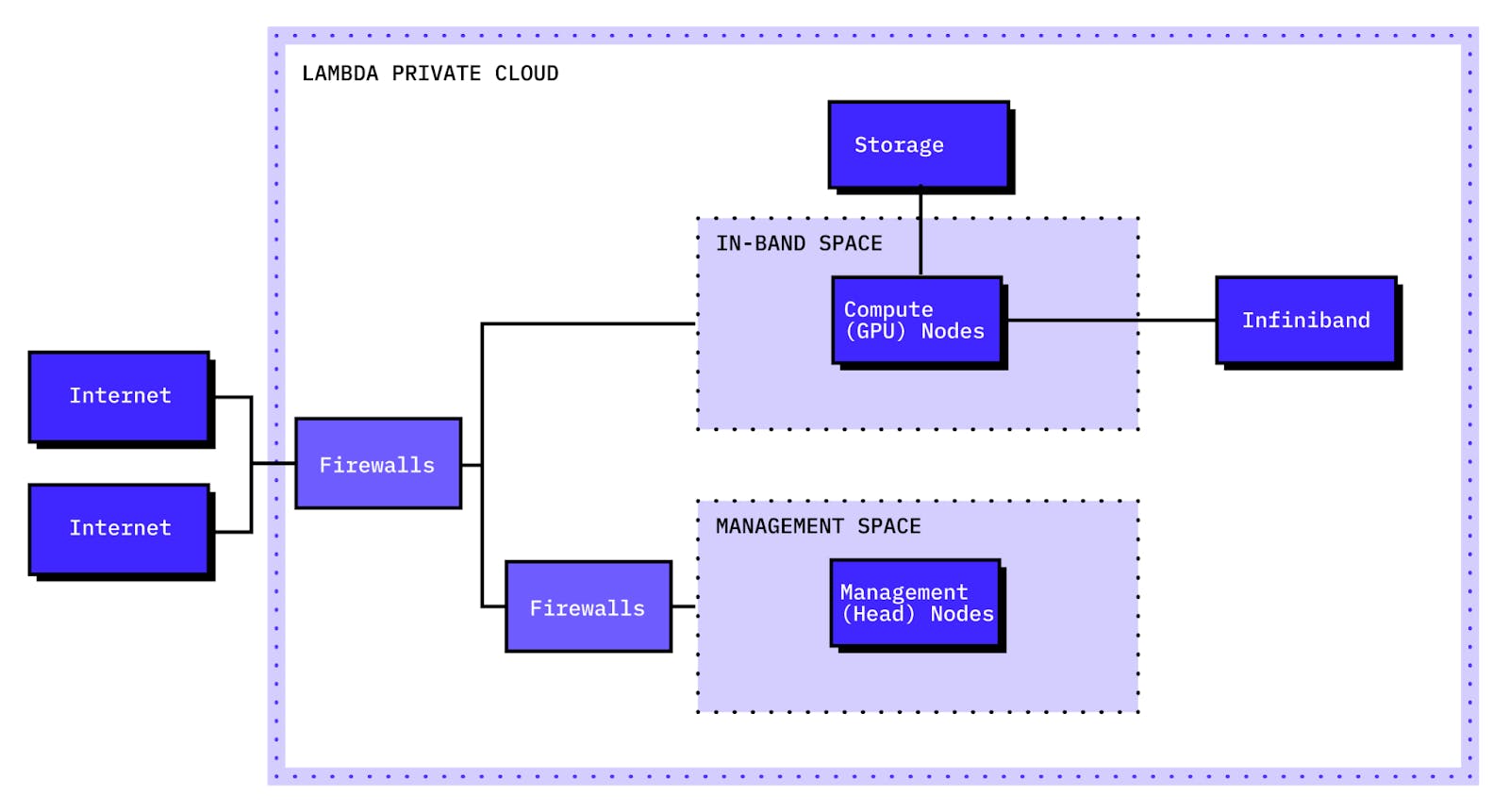
Source: Lambda Docs
These clusters are capable of supporting thousands of NVIDIA GPUs at once connected via NVIDIA Quantum-2 InfiniBand and optimized for large-scale workloads like foundation model training, simulations, or sovereign cloud hosting. Private Cloud includes:
Optional high-availability zones
Dedicated subnets and VLAN separation
Customer-specific VPN/SSH ingress
Full API control and dashboard integration
Orchestration
Lambda provides multiple orchestration frameworks, including Kubernetes, Slurm, and dstack, each suited to different levels of control and complexity for managing AI and GPU workloads. These tools support scheduling, scaling, and automation across Lambda’s cloud environments, including 1-Click Clusters and Private Cloud deployments. The goal is to improve resource efficiency, accelerate multi-node training, and reduce infrastructure costs for teams working with distributed ML jobs.
Lambda Stack
Lambda Stack is a pre-configured software environment for deep learning that installs PyTorch, TensorFlow, CUDA, cuDNN, and NVIDIA drivers in a single setup step. It’s intended to reduce the time required to configure a working machine learning environment on Ubuntu systems. The stack is versioned and updated regularly to stay compatible with the latest frameworks and GPU drivers, and can be used on both Lambda hardware and other supported systems.
Professional Services
Lambda's Professional Services support organizations throughout various stages of the machine learning lifecycle. The services include building AI roadmaps and proofs of concept to accelerate business adoption of machine learning, designing ML workflows and infrastructure that can scale to multi-node deployments across on-premise, colocation, or cloud resources, and model optimization services.
Prior Business Units
Historically, Lambda has offered several on-premise hardware products, including its Vector, Vector One, and Vector Pro workstations and its Scalar and Hyperplane servers. In August 2025, Lambda ended its support for those products. While the company committed to continuing to support warranties, potential customers are now instead referred to the company’s cloud products. Instead, Lambda has concentrated investment and product focus on its GPU cloud, offering on-demand H100/H200/B200 instances and private clusters, positioning these services as a simpler path to scale than running gear locally.
This strategy shift is in line with industry dynamics, given persistent AI-GPU scarcity and the economics of at-scale data center deployments. In September 2025, Nvidia signed a $1.5 billion deal with Lambda to lease back 18K GPUs over the course of four years. Arrangements like that reinforce the idea that centralized cloud pools are a more capital-efficient approach than dispersed on-prem fleets.
In addition, Lambda previously offered two tightly-coupled cloud services: the Inference API and Lambda Chat (its chat-application layer). In September 2025, both products were deprecated. This shift is likely in line with Lambda’s continued shift to a full-featured GPU cloud platform, rather than maintaining separate API products for inference and chat. By consolidating focus on large-scale GPU instances, private clusters, and managed training/inference infrastructure (rather than a specialized Chat product plus API layer), Lambda can streamline operations, simplify its product portfolio, capture more of the value chain (infrastructure vs just API), and better align with rapid hardware cycles and enterprise contract scale.
Inference API
Lambda’s Inference API provides serverless endpoints for deploying and running large AI models, such as language models, without needing to manage infrastructure. It’s designed to handle high-throughput inference with low latency and does not enforce request rate limits. This makes it suitable for teams that need to serve models in production environments with variable or unpredictable traffic.
Lambda Chat
Lambda Chat is a privacy-focused AI assistant for developers, researchers, and enterprise users. Accessible from the browser, it supports both text and image-based prompts with open-source and proprietary models, including DeepSeek, Llama, Hermes, and Qwen variants, and offers tools such as web search and file uploads. It integrates with the Lambda Inference API for programmatic model access.
Market
Customer
Lambda's ideal customer profile consists of organizations deploying computationally intensive AI applications that require immediate access to the latest NVIDIA hardware. Unlike general-purpose cloud providers that optimize for diverse workloads, Lambda targets customers specifically running machine learning training, large language model inference, computer vision processing, and scientific computing tasks. These workloads demand specialized GPU infrastructure that traditional cloud providers often struggle to deliver quickly or affordably.
Customer segments include academic institutions, AI startups seeking rapid prototyping without infrastructure management, and enterprise customers in finance, healthcare, and automotive, requiring GPU-accelerated computing for AI workloads. Notable customers, as reported in Lambda materials and analyst summaries, include Apple, MIT, Microsoft, Tencent, Kaiser Permanente, Stanford, Harvard, Caltech, and the Department of Defense.
Lambda increasingly serves Fortune 500 companies and government agencies, particularly where private and sovereign cloud deployments are necessary due to regulatory compliance or data sovereignty as a growing trend.
Market Size
Lambda operates within the GPU cloud services market, a subset of the broader AI infrastructure market valued at $47.4 billion in 2024. As of 2024, the global GPU-as-a-Service (GPUaaS) market was valued at around $4-5.7 billion. The market is projected to expand rapidly at a CAGR of 23% through 2030, fueled not only by AI and LLM training but also by surging demand in industries like healthcare, gaming, and manufacturing automation.
The addressable market breaks into three components that align with Lambda's business model. Public cloud GPU services represent the largest segment, where customers rent compute by the hour or through reserved capacity. Private cloud deployments serve enterprises requiring dedicated, compliant infrastructure. On-premise hardware sales target organizations needing direct control over their AI infrastructure.
Lambda's core market, public GPU cloud services, benefits from structural demand drivers. Training large language models requires thousands of coordinated GPUs for weeks or months. OpenAI's GPT-4 training required an estimated 25K NVIDIA A100 GPUs over 90-100 days. Meta's Llama 2 training used 2K A100s for approximately 184K GPU-hours. This creates predictable, high-value demand for cloud GPU providers.
The broader context shows a significant expansion opportunity. North America remains the dominant region for GPUaaS, contributing 37% of global revenue in 2024. The $16.9 billion data center GPU market includes cloud, enterprise, and research deployments, with cloud service provider infrastructure alone reaching $10.2 billion in 2024. GPU supply constraints favor established providers with secured inventory, while enterprise AI adoption accelerates toward an estimated 80% penetration by 2026.
Competition
The AI cloud infrastructure market is split between hyperscale tech giants and a fast-growing group of GPU-native startups. Major clouds have advantages in global distribution, enterprise relationships, and multi-service ecosystems. However, specialist providers have gained traction by targeting machine learning workloads with the latest GPU hardware, streamlined provisioning, and purpose-built APIs.
The central competitive dynamic centers on access to high-end NVIDIA GPUs for training and deploying large models. While hyperscalers benefit from procurement leverage and existing data centers, many ML teams find general-purpose clouds slow to provision and abstracted for evolving AI needs. GPU-specific companies work directly with NVIDIA, prioritize hardware rollouts, and offer pricing designed for ML workflows.
The market remains fragmented, with no single player commanding a dominant market share in GPU cloud services specifically. NVIDIA controls 70-95% of AI chip supply, which creates a key bottleneck, making direct relationships with NVIDIA crucial for competitive positioning. Lambda competes by focusing exclusively on AI workloads, maintaining direct NVIDIA partnerships for early hardware access, and offering cost-effective pricing through infrastructure built specifically for machine learning.
Emerging Players
CoreWeave
CoreWeave was founded in 2017 and went public on March 28, 2025, debuting on the Nasdaq under the ticker symbol "CRWV." At its IPO, the company priced its shares at $40 each, offering 37.5 million shares and raising approximately $1.5 billion. This established an initial market capitalization of approximately $23 billion at IPO. Since the IPO, CoreWeave's market capitalization has fluctuated significantly. As of October 2025, its market cap stands at approximately $65 billion.
Both companies focus exclusively on GPU cloud infrastructure optimized for deep learning workloads. CoreWeave differentiates through large-scale capacity expansion and enterprise deployments, while Lambda emphasizes direct NVIDIA partnerships and ML-optimized software environments. CoreWeave typically lists H100 pricing around $2.99–$3.19/GPU/hr and B200 at $3.85/GPU/hr, with a strong focus on Kubernetes-native orchestration, enterprise-scale deployments, and custom hardware configs and liquid-cooled clusters. On the other hand, Lambda prioritizes immediate deployment through its 1-Click Clusters and integrated software stacks that eliminate configuration overhead.
Runpod
Runpod, founded in 2022, takes a marketplace approach by aggregating GPU supply from various sources, including consumer-grade hardware. The company has raised over $22 million, including a $20 million seed round led by Intel Capital and Dell Technologies Capital in May 2024.
While Lambda operates dedicated data centers with consistent NVIDIA hardware and guaranteed availability, Runpod aggregates GPU supply from various sources, including consumer-grade hardware. Runpod’s pricing for H100s can be as low as $2.39/hr, undercutting Lambda’s rates, but supply, performance consistency, and support vary considerably depending on the provider and whether workloads are running in "Community" (cheapest) or "Secure" (enterprise-grade) mode. The Community Cloud leverages a decentralized peer-to-peer GPU network connecting individual compute providers with consumers. Runpod’s approaches appeal most to very cost-conscious or burst-workload users wanting per-second billing, but is less consistent for mission-critical enterprise use. Runpod's variable supply model makes it less suitable for the large-scale training workloads and enterprise deployments that represent Lambda's core market.
Paperspace
DigitalOcean acquired Paperspace for $111 million in cash in July 2023. Founded in 2014, Paperspace has raised over $35 million from notable investors including Battery Ventures, Intel Capital, SineWave Ventures, and Sorenson Capital. The acquisition combined Paperspace's GPU cloud platform and AI development tools with DigitalOcean's broader cloud services.
Paperspace provides cloud infrastructure for building and deploying AI models, targeting smaller teams and individual developers. The platform offers pre-configured ML notebooks, prices A100s at $3.09/hr, and emphasizes easy setup and accessible workflows rather than Lambda's focus on large-scale enterprise clusters.
Incumbents
Amazon Web Services
Launched in 2006, AWS is a dominant cloud provider, holding 30% of the global cloud infrastructure market in 2025 and $29.3 billion in Q1 2025 revenue. AWS offers GPU instances, including NVIDIA A100, H100, and V100, integrated with services like SageMaker and S3. The platform competes through massive scale and procurement power, but treats GPUs as one component of a broader platform. AWS H100 pricing ranges from $3.90-$4.92 per hour, higher than specialized providers like Lambda, and users report complex provisioning processes and limited availability during peak demand compared to AI-focused competitors.
Google Cloud Platform
Founded in 2008, Google Cloud Platform generated $33.1 billion in revenue in 2023 and $12.3 billion in Q1 2025, representing a 28% year-over-year growth. Google Cloud holds about 12% of the global cloud infrastructure market share as of Q1 2025.
Google Cloud offers NVIDIA A100 and H100 instances integrated with Google's AI models and data services through Vertex AI, along with custom TPU chips optimized for AI workloads. The platform's strength lies in data integration and research-oriented features, appealing to enterprises requiring advanced AI and analytics capabilities. However, H100 pricing sits approximately at $11/hour, much higher than specialized providers like Lambda, and GPU provisioning can be slower and more complex comparatively.
Microsoft Azure
Microsoft Azure holds 22% of the global cloud market and benefits from its $13 billion OpenAI partnership that provides preferential access to GPT models. Launched in 2010, Azure helped drive Microsoft's $245 billion in fiscal 2024 revenue. The platform offers GPU instances through NC-series and ND-series virtual machines but struggles with H100 pricing at $6.98/hour and limited GPU availability. Azure's strength lies in enterprise integration with Microsoft's broader software ecosystem, including Microsoft Fabric, Teams, and development tools.
Business Model
Lambda operates a hybrid hardware and cloud business model, where its primary revenue comes from its public cloud platform. Pricing follows a pay-as-you-go model with hourly rates that vary by GPU type and commitment level, with discounted reserved pricing for longer commitments. Lambda has also expanded into developer tools and managed services, through its APIs for serverless inference and orchestration of large distributed clusters. It generates additional revenue from direct hardware sales and managed services, with cloud revenue being largely recurring.
Lambda's infrastructure strategy is asset-heavy: it owns and operates its own high-density GPU clusters, racks, and data center infrastructure, which enables direct performance control and rapid deployment of the newest NVIDIA hardware. This approach requires substantial capital investment, as top-tier GPUs are among the most expensive hardware in modern data centers, costing anywhere from $25K-40K per unit as of 2025. However, Lambda remains more focused than hyperscalers by dedicating its infrastructure specifically to AI and machine learning workloads rather than a broad portfolio of general-purpose cloud services.
In terms of specific product pricing, Lambda lists three main pricing categories: 1-Click Clusters, On-Demand Instances, and Private Cloud. In all cases, the pricing page emphasizes transparent pay-as-you-go terms (“pay by the minute”), discounted reserved-capacity commitments, and that the lowest published rates apply when meeting longer commitments and larger scale.
1-Click Cluster Pricing
For 1-Click Clusters, users can provision 16 to 2,040 NVIDIA HGX B200 or H100 GPUs. The rate for B200 starts “as low as $3.79 per GPU-hour” on an on-demand 2-weeks-to-12-months commitment, with 1-year reserved capacity at $3.49 per GPU-hour. For H100 clusters, the pricing begins at $2.40 per GPU-hour on a 1-week to 3-month on-demand commitment, and goes down to $1.85 with a 1-year+ reservation.

Source: Lambda
Under On-Demand Instances, Lambda offers many GPU configurations billed by the minute with no egress fees. For example: 8 × NVIDIA B200 (180 GB VRAM per GPU) is $4.99 per GPU-hour, 8 × H100 SXM is $2.99, 8 × A100 SXM 80 GB is $1.79, 8 × A100 SXM 40 GB is $1.29, down to 8 × Tesla V100 16 GB at $0.55 per GPU-hour. Smaller cluster sizes (4-GPU, 2-GPU, 1-GPU) are also listed with rates such as $3.09 (4 × H100), $1.29 (4 × A100 PCIe 40 GB), and $0.75 (1 × A10 24 GB) per GPU-hour.

Source: Lambda
For Private Cloud, tailored for large single-tenant deployments (thousands of GPUs, multi-year contracts), Lambda provides specifications (e.g., 8×B200 networks: 3.2 Tb/s per 8×B200) and directs customers to contact sales for pricing.
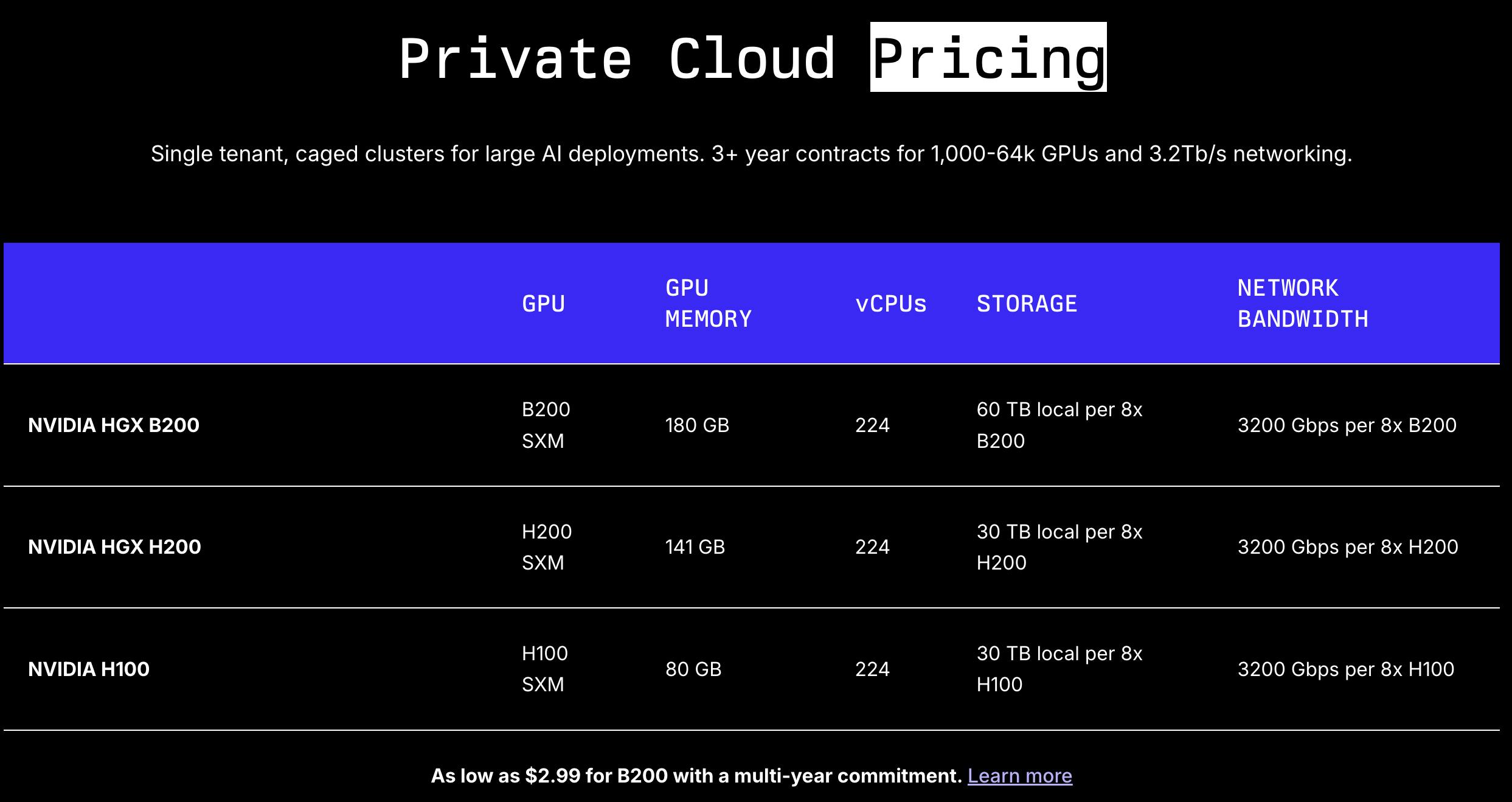
Source: Lambda
Traction
Lambda reported $425 million in revenue as of 2024, representing 70% year-over-year growth from $250 million in 2023. The company's revenue has grown from $20 million in 2022, driven by increased GPU cluster deployments and expanding enterprise adoption.
The company serves over 10K customers as of 2024, doubling from approximately 5K customers in 2023, with over 100K Lambda Cloud sign-ups. Lambda further claims broad adoption in academia, with workstations and servers reportedly deployed in 97% of US universities. Lambda’s Stack software environment has been adopted by over 50K machine learning teams globally.
In August 2025, Lambda announced a partnership with Supermicro where Lambda would build “AI factories” using Supermicro’s GPU-optimized server cluster based on NVIDIA Blackwell (including HGX B200/B300). The announcement followed Lambda’s June 2025 milestone of deploying the first NVIDIA HGX B200–accelerated clusters in Columbus (at Cologix), built on Supermicro platforms, and was later complemented in September 2025 by a Supermicro-built, hydrogen-powered installation of NVIDIA GB300 NVL72 systems with ECL in Mountain View
While Lambda is regarded as a prominent provider of high-density NVIDIA GPU clusters powering cloud AI workloads, the exact number of GPUs deployed across its data centers has not been publicly disclosed as of 2025. In September 2025, Lambda announced a $1.5 billion deal where Nvidia would lease back 18K GPUS from Lambda.
Valuation
Lambda has raised over $1.4 billion across equity and debt financing since 2012. The company has raised equity and secured debt financing to fund GPU purchases and infrastructure expansion.
Lambda's early funding consisted of multiple seed tranches totaling approximately $4 million between 2015 and 2018, backed by Gradient Ventures, 1517 Fund, and Bloomberg Beta. The company raised a $15 million Series A and secured a $9.5 million debt facility in July 2021, followed by $39.7 million in venture funding in November 2022 and a $44 million Series B led by Mercato Partners in March 2023.
The Series C in February 2024 marked Lambda's transition to large-scale financing, raising $320 million at a $1.5 billion valuation. The round was led by Thomas Tull's US Innovative Technology Fund with participation from B Capital, SK Telecom, T. Rowe Price, and existing investors. Lambda generated $425 million in revenue in 2024, placing the Series C valuation at approximately 3.5x revenue.
Lambda secured a $500 million debt facility from Macquarie Group in April 2024, designated specifically for purchasing NVIDIA's latest AI chips and scaling GPU inventory. This financing allowed Lambda to expand aggressively without equity dilution and demonstrated the company’s close operational alignment with NVIDIA’s hardware roadmap. In August 2025, the company closed on an additional $275 million credit facility from JPMorgan.
That alignment deepened further in February 2025 with Lambda’s $480 million Series D at a $2.5 billion post-money valuation. The round was co-led by Andra Capital and SGW with participation from NVIDIA as a direct investor, alongside ARK Invest, G Squared, and notable individual investor Andrej Karpathy. Strategic hardware investors, including Pegatron, Supermicro, Wistron, and Wiwynn, also participated, underscoring Lambda's position in the AI supply chain.
Lambda's valuation, as of October 2025, represented approximately 5.9x its 2024 revenue, reflecting premium pricing for specialized AI infrastructure providers. CoreWeave, Lambda's closest competitor, had a market capitalization of approximately $68 billion in October 2025, representing 23.4x LTM revenue. By comparison, cloud infrastructure leaders show varied multiples of LTM revenue, with Amazon trading at 3.6x, Microsoft at 13.4x, and Alphabet at 8.7x. Meanwhile, hardware providers like NVIDIA trade at 29.6x LTM revenue.
Key Opportunities
Enterprise AI Adoption at Scale
The enterprise AI market is experiencing high growth as Fortune 500 companies increasingly use AI in their operations. According to one report, 80% of enterprises will have used generative AI APIs or deployed generative AI-enabled applications by 2026, up from under 5% in 2023. This shift demands massive computational infrastructure that traditional IT departments are unprepared to manage. Lambda's focus on enterprise-grade GPU clusters with dedicated support and security features positions it to capture significant market share as companies seek alternatives to hyperscaler complexity. Some estimates project enterprise AI infrastructure spending will reach $143 billion by 2027, creating a substantial addressable market for specialized providers.
Sovereign & Private Cloud Demand
Regulatory demands and data sovereignty requirements are fueling substantial growth in private cloud and on-premises infrastructure, particularly across highly regulated sectors. Heightened privacy protection, including HIPAA in the U.S., sector-specific state rules, and expanding federal and international privacy mandates, are prompting organizations to seek greater data control and compliance, often outside broad public cloud environments.
The EU AI Act and similar regulations in other jurisdictions mandate strict, risk-based compliance requirements for high-risk AI applications. Lambda’s on-premise hardware offerings and private cloud capabilities are designed for environments with stringent compliance and data locality requirements. While hyperscalers comply with these standards, they have faced ongoing regulatory scrutiny and challenges in fully meeting regional sovereignty demands; for example, difficulties ensuring all data physically resides within certain countries and difficulties adapting sovereign cloud solutions like Microsoft Cloud for Sovereignty or AWS GovCloud to varying local laws. Private cloud infrastructure for AI workloads is expected to grow at a 27% CAGR through 2028, significantly outpacing public cloud growth rates.
Partnership Leverage
Lambda's direct relationship with NVIDIA grants it exclusive, preferential access to the latest GPU architectures, including H200, B200, and Blackwell chips. This partnership is strengthened by NVIDIA’s investment in Lambda and Lambda’s status as a Platinum sponsor and award-winning partner in NVIDIA’s Partner Network. As of 2025, NVIDIA's GPU shortage is ongoing, making rapid hardware access a significant competitive advantage. As NVIDIA introduces new architectures optimized for inference and edge deployment, Lambda is positioned to offer faster time-to-market than competitors, dependent on secondary suppliers or general-purpose cloud providers who must balance GPU allocation across diverse workloads.
Key Risks
Competitive Pressure From Hyperscalers
Microsoft's $13 billion investment in OpenAI exemplifies how tech giants are vertically integrating AI infrastructure with advanced models and enterprise software. This creates bundled offerings that could undermine Lambda's value proposition for enterprise customers already embedded in Microsoft's ecosystem. Amazon's $8 billion investment in Anthropic and Google's internal AI model development follow similar patterns, allowing hyperscalers to offer integrated AI platforms with compute, storage, networking, and frontier models in a single contract.
Beyond partnerships, hyperscalers possess structural advantages that intensify competitive pressure. Microsoft, Google, and Amazon invest tens of billions annually in data center infrastructure and can absorb losses on GPU pricing to gain market share. AWS alone spent over $50 billion on capital expenditures in 2023, significantly dwarfing Lambda's entire revenue. These companies can also use their existing enterprise customers, compliance certifications, and global data centers to bundle AI infrastructure into current cloud contracts, potentially commoditizing Lambda's specialized offerings.
Supply Dependency
Lambda's business model relies heavily on access to new NVIDIA hardware, creating dependency risk around a single supplier. NVIDIA controls 70-95% of the AI chip market, and any changes to its partner program, pricing, or supply decisions could significantly impact Lambda's costs and hardware availability. NVIDIA's GPU shortage continues with lead times of 9-12 months for H100 systems, and the company prioritizes supply to its largest customers, potentially disadvantaging smaller cloud providers during shortages.
Additionally, emerging competitors like AMD's MI300 series and Intel's Gaudi chips are gaining traction, potentially reducing NVIDIA's dominance and requiring Lambda to diversify its GPU offerings or risk becoming outdated. If NVIDIA's advantages weaken or if hyperscalers develop custom silicon like Google's TPUs or Amazon's Trainium chips, Lambda could lose its edge in GPU access. The company's entire value proposition depends on offering the latest, highest-performance GPUs, making disruption to NVIDIA relationships or supply chains a fundamental business risk.
Infrastructure-Only Focus Limiting Enterprise Appeal
Lambda primarily focuses on infrastructure and does not deliver a full "AI platform" experience like those offered by hyperscalers. Customers must integrate separate tools for MLOps, deployment, monitoring, and data pipelines to build complete workflows, which creates friction for enterprise adoption. This infrastructure-only approach makes Lambda harder to use for organizations without strong internal machine learning expertise and limits growth into less technical customer segments. While Lambda's specialized focus enables competitive pricing and performance, it may put the company at a disadvantage against competitors offering complete AI platforms as the market matures.
Summary
Lambda operates as a GPU-native infrastructure provider focused exclusively on AI computing workloads. Founded in 2012 by Stephen and Michael Balaban, the company offers on-demand access to NVIDIA GPUs, reserved clusters, private cloud deployments, and on-premise hardware systems, all pre-configured with its Lambda Stack software environment.
As of 2024, Lambda was serving a customer base that includes Fortune 500 companies, research institutions, and AI startups, generating $425 million in revenue with 70% year-over-year growth. Lambda competes against hyperscale providers like AWS and Google Cloud, as well as GPU-focused competitors including CoreWeave and RunPod.





