Thesis
The growth in usage of LLMs for both enterprise and personal use has dramatically outpaced the industry’s ability to evaluate them meaningfully. As of September 2025, there are over 320K public-facing LLM endpoints spanning dozens of frameworks, highlighting both the scale and fragmentation of the current model ecosystem. Evaluation still relies heavily on static academic benchmarks like MMLU or TruthfulQA, which rarely reflect how people actually interact with these systems in deployment.
This mismatch is increasingly recognized across industries. Scale’s 2024 Zeitgeist report noted that 72% of enterprises developing AI systems now conduct their own internal evaluations. These often involve custom prompts, application-specific metrics, or proprietary human-in-the-loop review pipelines, underscoring growing dissatisfaction with one-size-fits-all benchmarks. As adoption accelerates, teams need tools that measure model performance in real-world conditions, not just leaderboard scores.
At the same time, human preferences are playing an increasingly central role in how models are fine-tuned, evaluated, and compared. Reinforcement learning from human feedback (RLHF) has become a standard technique for aligning models with user expectations, and many research efforts now rely on human preference data to guide training and evaluation. But gathering this kind of data at scale, across diverse models and tasks, requires infrastructure that is both transparent and model-agnostic.
This is the gap LMArena is filling. Originally launched by the UC Berkeley Large Model Systems Organization (LMSYS) as an academic side project, LMArena has evolved into a company that helps answer the question of which AI models are best. It does so by allowing site visitors to compare anonymous AI responses to the same prompt and vote on which one they think is stronger. This provides LMArena a growing dataset of human preferences around AI answers, an alternative to the static benchmarks traditionally used to rank model companies. With over 3 million comparisons logged and over 400 models evaluated as of April 2025, LMArena has become a popular method for comparing and evaluating AI model performance.
Founding Story
LMArena was founded in 2025 by Anastasios N. Angelopoulos (CEO), Wei‑Lin Chiang (CTO), and Ion Stoica (Co-founder and Advisor) to build a more rigorous and transparent foundation for evaluating large language models. The company emerged from UC Berkeley’s machine learning research community, in which all three co-founders had deep academic and industry ties. The team’s original goal was simple: build an evaluation platform that actually reflects how LLMs are used in the real world, which static academic benchmarks were increasingly failing to do.
In 2023, when Angelopoulos and Chiang were both PhD students in EECS at UC Berkeley, the pair launched Chatbot Arena, a side project under the LMSYS research organization. Working closely with Stoica, a Berkeley professor and serial founder known for co-founding Databricks, Anyscale, and Conviva, the team created an open, side-by-side evaluation tool for LLMs grounded in human preferences. Their approach was simple: anonymize model outputs, let users vote on which response they preferred, and aggregate those results at scale. The idea quickly gained traction, such that within two years, the platform had hosted millions of head-to-head comparisons across more than 400 models.
Angelopoulos brought to the project a background in trustworthy AI systems, black-box decision-making, and medical machine learning. Before founding LMArena, he worked as a student researcher at Google DeepMind and was set to begin a postdoc with Stoica focused on evaluating AI in high-stakes settings. Chiang, meanwhile, studied distributed systems and deep learning frameworks in Stoica’s SkyLab and had prior research experience at Google Research, Amazon, and Microsoft. Together, they shared a vision of building AI infrastructure that met the reliability demands of real-world deployment.
By April 2025, the need to support a fast-growing user base and deepen the platform’s capabilities led to the formal launch of Arena Intelligence Inc.. While technically a spinout from academia, the company has retained its research-first ethos. The team is composed of talent from Google, DeepMind, Discord, Vercel, Berkeley, and Stanford, and the platform continues to operate under a clear philosophy of maintaining a neutral, science-driven evaluation framework that remains open, interpretable, and unbiased across model providers.
LMArena aims to innovate in the LLM evaluation space by collecting human preference data from real-world interactions to inform judgments. This allows organizations to gauge model performance in practical, diverse applications, moving beyond insights offered by static benchmarks. Its founding reflects a broader shift in AI from top-down evaluation pipelines toward community-led verification for trust and transparency.
Product
LMArena is an open, publicly accessible platform for evaluating LLMs through side-by-side, blind comparisons. Originally launched as Chatbot Arena by researchers at UC Berkeley, the platform allows users to vote on which model response they prefer, with no model names and no context clues, just given output against output. This simple mechanism powers a community-driven leaderboard that reflects human preferences rather than static benchmark scores. Since its inception, LMArena has collected over 3.5 million head-to-head votes across more than 400 models as of September 2025, making it one of the largest crowdsourced human-preference datasets in the field of LLM evaluation.
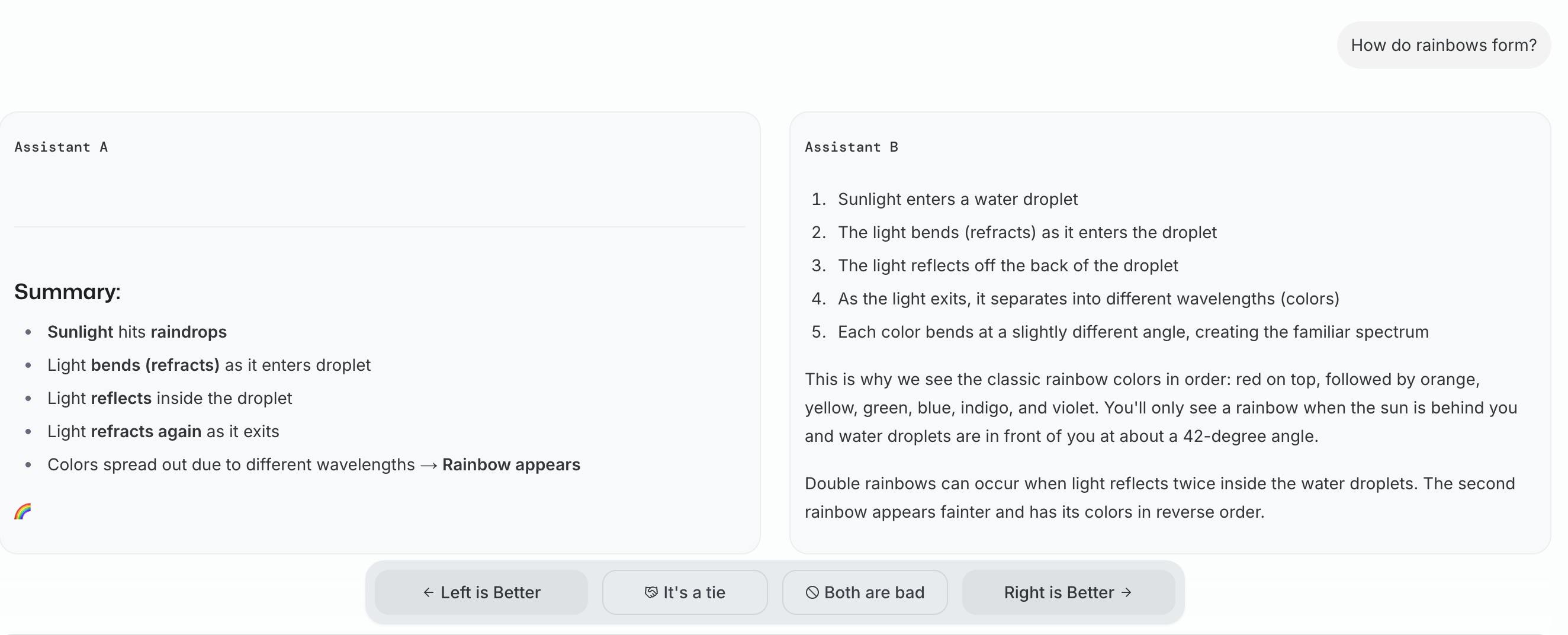
Text Chat
The core interaction on LMArena involves users submitting a prompt, anything from a casual question to a technical task, and receiving two anonymous responses from different LLMs. They then vote on which answer they prefer, with model identities revealed only after the vote is cast. This ensures unbiased comparisons and preserves the integrity of the leaderboard. To maintain fairness, any votes submitted after model identities are revealed are excluded from ranking calculations. This blind evaluation framework allows LMArena to gather reliable, preference-based data at scale.
Source: LMArena
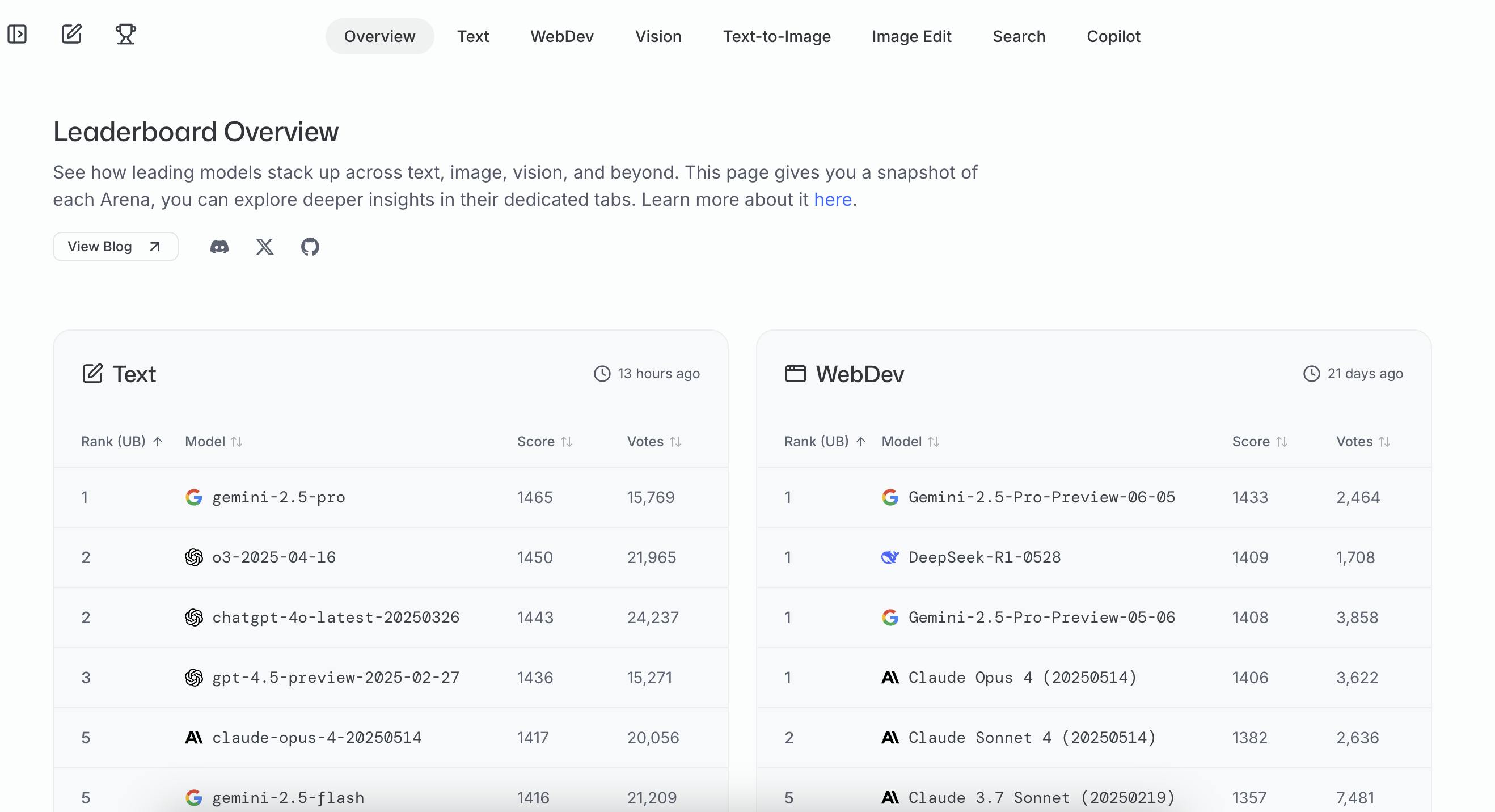
Leaderboard
LMArena ranks models using a variant of the Bradley-Terry model to compute Elo-style scores, where each head-to-head vote is treated as a match between two models, with one “winning” over the other. Unlike static benchmarks such as MMLU or GSM8K, which rely on multiple-choice questions with fixed answers, this system captures how models perform on open-ended tasks using real human preferences. To address data scarcity and avoid inflated or noisy scores, especially for models with limited exposure, LMArena incorporates Bayesian regularization to estimate per-prompt skill within the Bradley-Terry framework. This approach enables fine-grained, continuous updates to the leaderboard, ensuring robust comparisons even when vote distributions are uneven.
Source: LMArena
Early in the platform’s evolution, some models were under-ranked due to limited data or mismatches between prompt types and model strengths. To address this, LMArena introduced Prompt-to-Leaderboard (P2L), a prediction model trained on historical vote patterns to estimate which model would be preferred on a given prompt. Additionally, Arena Categories help contextualize results across domains, such as coding, reasoning, or conversation, providing a more accurate view of model performance across a variety of potential tasks.
WebDev Arena
In December 2024, LMArena launched WebDev Arena, a real-time AI coding competition where large language models face off in web development challenges. Users submit prompts describing a desired app or UI functionality, such as a to-do list, calculator, or animated interface, and two anonymous LLMs generate full web applications in response using HTML, CSS, JavaScript, and interactive components. Once both apps are generated, users can interact with each one live in the browser and vote on which implementation performs better. This interactive, crowdsourced format brings model evaluation closer to real-world development tasks and user expectations. Rankings in WebDev Arena are calculated using the same Bradley-Terry framework as the main leaderboard, enabling consistent scoring. As of March 2025, the competition had attracted over 80K head-to-head votes, establishing itself as a new benchmark for evaluating LLMs on end-to-end software generation.
Search Arena
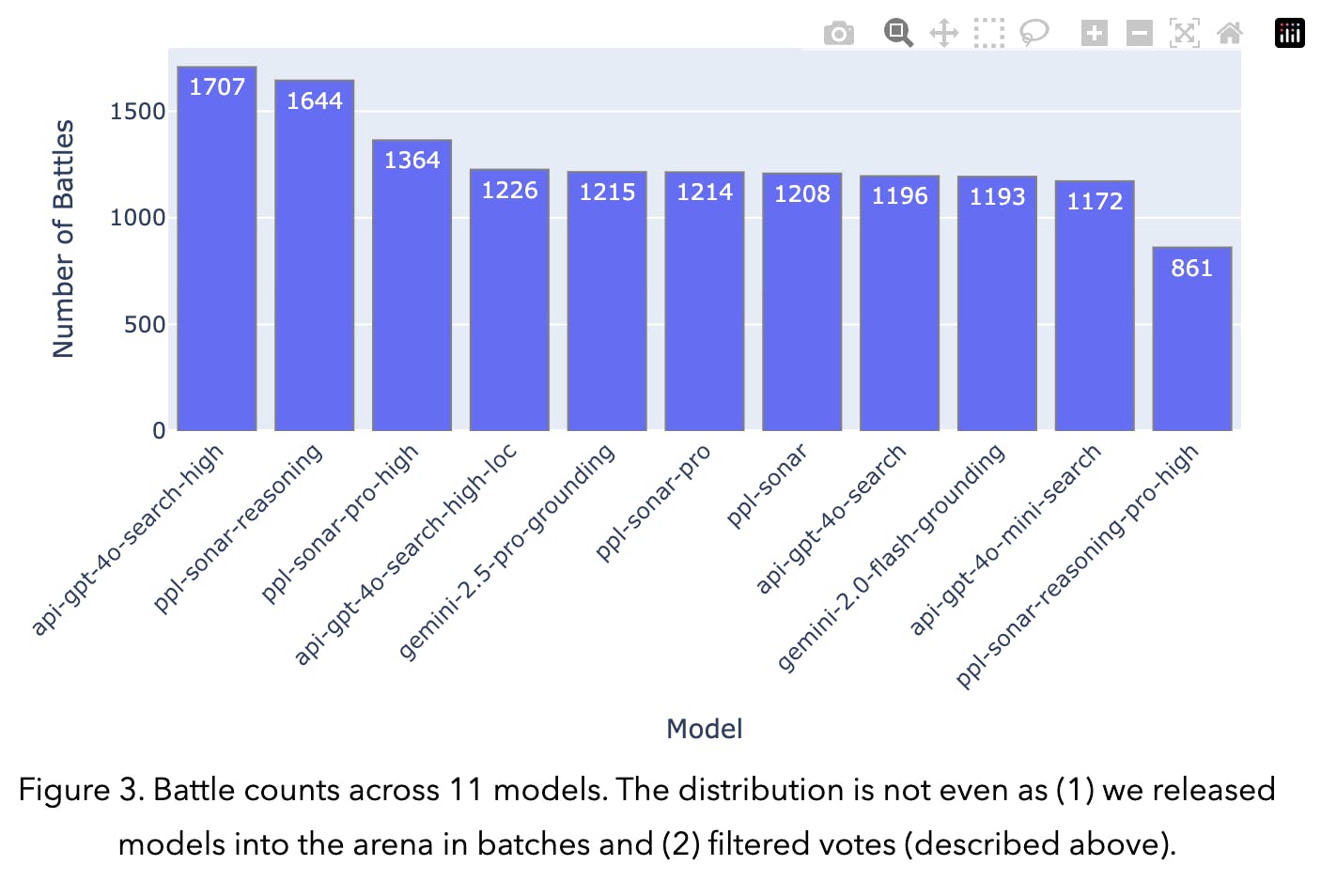
Launched in March 2025, Search Arena is LMArena’s dedicated interface for evaluating search-augmented language models through real-world, human-judged comparisons. Rather than focusing solely on static factual benchmarks like SimpleQA, Search Arena captures how retrieval-augmented models perform across diverse, open-ended tasks, including coding, research, and current events. Participants submit prompts and compare anonymized outputs from two competing models in a blind head-to-head format.
Source: LMArena
As of April 2025, the platform has collected over 7K votes across 11 models, including entries from OpenAI, Google Gemini, and the Perplexity Sonar series. To ensure unbiased comparisons, the platform standardizes and randomizes citation formats, thus neutralizing model-specific quirks that could reveal identity. Search Arena also supports longer prompts, extended completions, multi-turn interactions, and multilingual inputs, providing a more flexible and realistic testbed than traditional search model benchmarks. All evaluations are conducted using the providers’ default API configurations, staying faithful to real deployment conditions.
Copilot Arena
Copilot Arena is LMArena’s evaluation platform for AI coding assistants, designed to benchmark LLMs on real-world code completion and editing tasks. Users compare paired outputs from two anonymized models, selecting the completion they find more helpful or correct. To ensure fair comparisons, model positions are randomized, completions are rendered simultaneously, and speed is deliberately controlled to prevent early responses from biasing user choice.
Since its launch, Copilot Arena has been downloaded over 2.5K times via VSCode and has facilitated more than 100K code completions as of November 2024. The platform captures much richer context than existing static benchmarks, with an average prompt length of 1,002 tokens, far exceeding typical coding evaluation datasets, which used median prompt lengths of as low as ~100 tokens as of November 2024.
In addition to long-context tasks, Copilot Arena also targets known weaknesses in LLM code generation, such as “fill-in-the-middle” (FiM) tasks. Instead of forcing models into unnatural FiM formats, the platform allows them to generate full snippets and post-processes the outputs to simulate FiM, preserving model behavior while testing relevant capabilities. Ongoing work focuses on refining UI elements to reduce position bias, ensuring that user votes reflect true preference rather than interface ordering. Together, these design decisions allow Copilot Arena to serve as a scalable framework for assessing the quality and reliability of AI coding assistants.
RepoChat Arena
RepoChat Arena is a live benchmarking environment tailored for AI software engineers working with real-world codebases. Users submit a GitHub repository URL along with a natural-language query, such as a request to review a pull request, resolve an issue, or implement a new feature, and two large language models compete to generate the most helpful response.
Unlike static code benchmarks, RepoChat Arena tests end-to-end performance on practical tasks without requiring users to manually extract context. A retriever model automatically scans the repo’s file structure to identify and select the most relevant files, which are then paired with the user’s question and passed to the answer model.
Released in November 2024, the arena has already seen over 12K multi-turn conversation battles, with more than 4.8K user votes. Of those, 2.5K unique repositories were directly involved in head-to-head voting sessions as of February 2025. By evaluating models on tasks that mirror how developers actually use LLMs, from code navigation to system design, RepoChat Arena provides a unique glance into model performance in more complex, real-world software engineering workflows.
Market
Customer
LMArena serves a growing ecosystem of model developers and users navigating the increasingly complex landscape of large language models. Its primary customers are AI model providers, including leading labs such as OpenAI, Google DeepMind, Anthropic, and Meta. These organizations use LMArena for public benchmarking, competitive positioning, and confidential pre-release testing. The platform allows them to evaluate private, unreleased model variants under anonymous labels, providing real-world human feedback before public launch. This process helps labs select top-performing candidates from dozens of internal options, reducing the risk of costly release missteps.
In addition to proprietary model labs, LMArena provides a critical validation layer for open-source developers such as Mistral, Alibaba, and smaller academic research groups. For these teams, the platform offers a valuable opportunity to gain visibility and measure performance against well-funded proprietary models on equal footing.
It has been noted that flagship models from top providers account for a disproportionate share of LMArena’s interaction data. While this ensures that leading models are well-represented, it has also prompted external scrutiny, including allegations of bias in random model selection. Maintaining trust in the leaderboard’s neutrality is therefore both a strategic imperative and an ongoing challenge.
LMArena also supports a diverse and highly active user base, including researchers, students, software developers, and ML engineers. Approximately 75% of submitted prompts are novel each day as of December 2024, ensuring that evaluations reflect fresh, evolving use cases rather than static test sets. This helps LMArena maintain an adaptive snapshot of how real users interact with language models, rather than a static benchmark.
Market Size
LMArena operates in several rapidly growing markets, each reinforcing the demand for better evaluation tools for AI systems. Its core market, AI-enabled testing, focuses on applying machine learning and automation to software testing workflows. As of 2024, the AI-enabled testing market is valued between $800 million and $900 million as of August 2025, with projections reaching $3.8 billion by 2032, growing at a CAGR of 20.9%. North America led the space with a 35% market share as of August 2025.
Adjacent to this is the broader machine learning operations (MLOps) market, which includes tools for managing the lifecycle of ML models, from training and deployment to monitoring and governance. As of September 2025, the MLOps market is projected to grow from $3.4 billion in 2024 to $29.4 billion by 2032, at a CAGR of 31.1%. LMArena fits squarely within the monitoring, validation, and governance layers of the overall stack.
These categories are themselves fueled by the expansion of the generative AI market, valued at $16.9 billion in 2024 and expected to exceed $109.4 billion by 2030. As of 2024, the global AI market was projected to grow from $279.2 billion in 2024 to $1.8 trillion by 2030, at a CAGR of 35.9%. LMArena’s role in this landscape is not limited by the current size of AI testing budgets, but rather tied to the R&D and marketing spend across the entire AI industry.
Training a single frontier model can cost upwards of $100 million, making post-training evaluation a critical investment. LMArena’s leaderboard provides strategic intelligence that de-risks these efforts, enabling model developers to fine-tune, benchmark, and validate models before public deployment. By offering reliable human preference signals, LMArena helps labs avoid costly missteps and informs go-to-market strategy. In this context, LMArena is not merely a testing platform, but rather a tool for market validation, model selection, and competitive positioning.
Competition
Competitive Landscape
LMArena sits at a unique crossroads in the AI ecosystem, providing what has become a critical layer of public infrastructure for model evaluation. While competitors increasingly integrate evaluation tooling into broader platform offerings, LMArena has carved out a distinct position through its community-driven approach. Its leaderboard, fueled by millions of human preference votes, is now a widely cited reference point across research labs, enterprises, and open-source endeavors. This has created a powerful data and trust moat; LMArena’s perceived neutrality and scientific rigor make it a fair decision-maker in a field where evaluation bias can significantly shape public perception and deployment decisions.
The broader LLM evaluation space is fragmenting into several sub-markets. In public benchmarking, LMArena competes most directly with Hugging Face’s Open LLM Leaderboard, which relies on automated testing against academic datasets. While quantitative benchmarks like those used by Hugging Face offer scalability and objectivity, they often suffer from dataset contamination and fail to capture subjective traits like helpfulness or conversational quality.
Other emerging segments include consumer-facing model aggregation, where platforms like Quora’s Poe offer side-by-side model access and voting interfaces geared toward casual users. For enterprise-grade MLOps and observability, companies like Weights & Biases (acquired by CoreWeave), Arize AI, and Arthur AI provide internal monitoring tools for deployed AI systems. While these players offer powerful infrastructure, their evaluation pipelines often remain opaque or narrowly scoped to enterprise needs.
LMArena’s greatest long-term challenge will come not from methodological rivals, but from large, integrated AI platforms with the resources to build their own proprietary human-feedback systems. These entities, ranging from model labs to infrastructure providers, may eventually internalize LMArena’s functions.
Scale AI: Founded in 2016, Scale AI began as a data-labeling company and has since evolved into a full-stack AI infrastructure provider. As of September 2025, Scale offers fine-tuning services, generative AI tooling, and a sophisticated evaluation platform through its SEAL (Safety, Evaluations, and Alignment Lab) Leaderboard. SEAL operates as a high-trust, expert-driven evaluation service geared toward government and enterprise clients, focusing on adversarial robustness, safety, and national security, domains that require rigorous performance guarantees.
With Meta investing $14.8 billion for a 49% stake in June 2025 and a $1 billion Series F round in May 2024, Scale is valued at $29 billion as of September 2025, having raised a total of $1.6 billion in venture capital funding outside Meta’s investment as of June 2025. Unlike LMArena, which offers open and community-driven evaluation, SEAL provides evaluation as a private service. Both platforms aim to become the authority on model quality, but they target different audiences.
Hugging Face: Hugging Face, founded in 2016, has become the central open-source platform for the machine learning world. Its ecosystem includes a vast model hub, collaborative development environment, and the Open LLM Leaderboard, which benchmarks models using automated academic datasets like MMLU, HellaSwag, and ARC. The leaderboard runs on standardized hardware, offering reproducibility, but lacks the subjective, real-world preference data that powers LMArena. Hugging Face’s strength lies in integration, offering model access, training tools, evaluation methods, and community infrastructure all under one roof.
The company has raised $400 million from investors including Salesforce, Google, Amazon, NVIDIA, and Sequoia. Hugging Face posted a $4.5 billion valuation in August 2023, following its $235 million Series D funding round led by Salesforce. Hugging Face’s automated leaderboard provides valuable quantitative signals, while LMArena complements this by providing insight into human-powered comparisons, reflecting two different evaluation paradigms.
Poe: Originally launched as a social Q&A platform in 2009, Quora entered the AI space with the release of Poe (Platform for Open Exploration) in December 2022. Poe acts as a consumer-facing model aggregator, enabling users to chat with and compare outputs from models developed by OpenAI, Anthropic, Google, and Meta. Poe serves as a platform for public model exploration, positioning itself as a potential competitor to LMArena, though it doesn’t aggregate model performance metrics as of September 2025.
Quora raised a $75 million Series D funding round in January 2024, led by a16z. As of September 2025, its last publicly disclosed valuation was $2 billion in May 2019. With over 400 million monthly users and $301 million in total funding from investors including a16z, Y Combinator, and Benchmark, Poe could theoretically replicate parts of LMArena’s leaderboard and take advantage of its massive distribution. However, unlike LMArena, Poe currently lacks methodological rigor and a formal leaderboard structure. Poe’s strength lies in aggregation and interface design, while LMArena’s lies in scientifically grounded evaluation.
Business Model
LMArena began as a research project sustained by a mix of volunteer contributions, academic funding, and strategic sponsorships from a broad network of stakeholders in the AI ecosystem. These included academic institutions like UC Berkeley’s Sky Computing Lab, venture firms such as a16z and Lightspeed, and infrastructure providers.
With its incorporation and $100 million seed round in May 2025, LMArena began transitioning from an academic project to a scalable business. Its model is a variation on the freemium structure, with the core platform remaining open and accessible to the public, allowing for the generation of data from millions of anonymous, head-to-head model comparisons. Community-driven growth serves as both a data engine and marketing tool. LMArena’s revenue-generating services are focused on model providers and enterprise clients, who pay for access to more customizable and private evaluation infrastructure.
Emerging revenue streams include private arenas, which allow model developers to evaluate proprietary systems using internal or sensitive data without exposing results publicly. LMArena also plans to commercialize evaluation tooling and analytics, offering dashboards and diagnostic reports tailored to model performance across domains. Additionally, the company is rolling out API and SDK access for teams that want to programmatically integrate LMArena’s evaluation pipelines into their training, release, or monitoring workflows. Premium support for custom assessments is another potential area of growth, offering tailored testing environments.
While the company is asset-light, owning no physical infrastructure, its operating costs scale with platform usage. Every user interaction triggers API calls to external model providers like OpenAI, Google, and Anthropic, creating a linear cost structure tied to engagement volume. As LMArena grows, these API fees represent a core challenge to maintaining long-term margins. Additional expenses include cloud hosting, backend services, personnel, and R&D, particularly for designing new evaluation methodologies and publishing research to uphold its credibility. LMArena does not monetize its entire dataset; it commits to publicly releasing up to 20% of preference data to support open research, while retaining the remaining 80% as a strategic asset for commercial products.
Traction
Since its public launch, LMArena has emerged as a core benchmarking infrastructure for the generative AI ecosystem, with growth metrics that underscore its momentum and credibility. The platform now receives over one million unique visitors per month as of April 2025, and has collected more than 3.5 million human preference votes as of September 2025. The company’s reach spans both industry and academia, with users including AI labs, open-source communities, and independent researchers.
As of April 2025, LMArena has evaluated over 400 public models and run more than 300 private, pre-release tests, providing real-world performance feedback before public launches. The company has released over 1.5 million user-submitted prompts and 200K anonymized pairwise vote records for open research, helping teams study human preferences at scale. LMArena differentiates itself from existing benchmarks as of September 2025, as less than 1% of LMArena prompts overlap with any existing static benchmark. Topic modeling of LMAerna prompts reveals more than 600 distinct task clusters, ranging from SQL generation to trip planning to legal reasoning. The largest single cluster accounts for just 1% of all prompts, demonstrating the breadth of LMArena’s data.
Model providers often publicly cite high LMArena rankings in press releases as third-party validation of model quality. LMArena’s leaderboards, datasets, and model cards are also hosted on Hugging Face, increasing visibility within the open-source and developer community. LMArena continues to solidify itself as a key player in model evaluation, with companies including OpenAI (GPT series, o1), Google (Gemini, Gemma), Anthropic (Claude), Meta (Llama), and xAI (Grok) using LMArena either for public validation or confidential iteration ahead of release.
Valuation
LMArena raised a $100 million seed round in May 2025 at a $600 million valuation. The round was co-led by Andreessen Horowitz (a16z) and UC Investments, with participation from Lightspeed Venture Partners, Laude Ventures, Felicis, Kleiner Perkins, and The House Fund. This was the company’s first institutional raise, and brings its total funding raised to $100 million as of September 2025.
Key Opportunities
Private Arenas
One of LMArena’s immediate commercial opportunities is offering private arenas for enterprises and model labs. These single-tenant, secure instances of the public platform allow organizations to evaluate LLMs on proprietary datasets and internal use cases without exposing sensitive information. For many enterprise customers, evaluating models on a public platform is not viable due to confidentiality and compliance requirements. Private arenas solve this by enabling teams to use their own domain experts as evaluators, with support for versioned prompts, reproducible experiments, and granular control over test environments. This unlocks complex, customized evaluations for tasks such as internal tool assessment, and model fine-tuning for enterprise clients.
Agent and Multimodal Evaluation
As LLMs increasingly function as autonomous agents, existing benchmarks that judge single-turn outputs in isolation are no longer sufficient. In response, LMArena could grow via developing goal-oriented frameworks to evaluate entire agent trajectories, including plan formulation, tool usage, API interactions, and final task completion. For instance, users could compare replayable sessions of agents attempting the same multistep task, and vote based on overall performance, rather than just a final answer. Similar methods could be explored for evaluating multimodal agents that incorporate vision, speech, or sensor inputs.
Custom Analytics
Human preference data collected through LMArena can be cleaned, labeled, and packaged for downstream use in training reward models, an essential input for techniques like RLHF. LMArena could offer curated datasets that are balanced across prompt types, domains, and difficulty levels. Beyond training, there is also an opportunity for LMArena to build an analytics product that provides subscribers with structured insights on model performance and emerging usage patterns. The platform could reveal trends such as rising prompt categories, regional or linguistic biases, or early signs of model regressions. LMArena could also work on developing and selling domain-specific, synthetic test sets based on LMArena’s actual collection of user prompts, giving clients realistic evaluation tools without requiring them to disclose proprietary data.
Key Risks
Leaderboard Manipulation
Because LMArena uses head-to-head human voting to determine model quality, the integrity of the leaderboard depends on both the trustworthiness of individual votes and the robustness of the ranking algorithm. Recent research has raised concerns over the leaderboards’ susceptibility to gaming. If API providers can detect Arena-originated traffic patterns, they may be able to script votes in favor of their models, a consequential outcome since just a few hundred votes can meaningfully alter Elo rankings.
LMArena’s use of Elo, originally designed for dynamic, evolving systems like chess, has also introduced technical limitations when applied to largely static entities like language models. Elo’s sensitivity to match order makes the leaderboards susceptible to path dependency. The rankings’ sensitivity to hyperparameter choice can lead to ranking instability, especially when comparing models of similar performance. Lastly, Elo’s core mathematical assumption of transitivity does not consistently hold when applied to the ranking method employed by LMArena. These statistical artifacts are vulnerabilities of the company’s leaderboards that may be taken advantage of.
In addition, due to the average human preference problem, and because LMArena’s leaderboards are an influential target, model providers may be incentivized to optimize their models specifically to win these preference battles. This may result in developers fine-tuning for the stylistic quirks preferred by LMArena’s user base, rather than making true improvements to a model's core reasoning.
Conflicts of Interest
LMArena faces pressure to monetize following its $600 million valuation and recent seed funding round. The company’s easiest path to long-term profitability involves selling evaluation tools, data access, and premium leaderboard services to the same labs whose models it ranks. This introduces a conflict of interest that threatens the neutrality of the platform. Public trust in LMArena depends on it acting as an impartial referee in model evaluation, yet the incentives of monetization may push the company to favor large customers. As more value concentrates in the top positions on the leaderboard, any perceived or real bias, as well as suspicion towards LMArena’s incentives to monetize, could lead to reputational damage.
Data Access Disparities
A joint study led by researchers at MIT, Stanford, and Cohere accused LMArena of favoring large, proprietary model providers through data asymmetries. According to the study, leading providers like OpenAI and Google received 20.4% and 19.2% of all data from the arena, respectively, while 83 open-source models collectively received only 29.7% of all data. The authors also note that LMArena enables private testing, where large providers are given privileges to test unreleased variants privately, collect user feedback, and then only publicize their best-performing version. This process creates an impression of consistent superiority that smaller models, which submit once and must compete in real time, cannot replicate. In addition, it was found that Meta’s publicly released Llama 4 model differed from the model that was topping LMArena’s leaderboard. LMArena may face a credibility crisis if it cannot enforce leaderboard submission transparency, regulate private testing, and provide fair access to Arena data.
Summary
As the number of foundation models from labs like OpenAI, Google, and Anthropic grows, developing an objective framework for evaluating models’ reasoning abilities has become a prominent issue. Static academic benchmarks, while historically useful, fail to reflect how models perform in the wild, where user preferences, task specificity, and prompt diversity shape perceived quality. Enterprises and developers now face a blind spot without a reliable, real-time signal for model performance across use cases.
LMArena addresses this gap through a public evaluation platform that pits models against one another in blind, head-to-head comparisons. Real users help generate human preference data at scale. These votes power an influential live leaderboard, used by model providers for both public benchmarking and private pre-release testing. Originally spun out of a UC Berkeley research project, the company has raised $100 million at a $600 million valuation and is emerging as the default provider for evaluating model performance.
The central question is whether LMArena can remain trusted and fair as it commercializes. The platform’s long-term credibility depends on preventing vote manipulation, ensuring equitable access to user-generated data, and avoiding preferential treatment of dominant players, especially as performing well on LMArena’s leaderboard becomes a target in itself for enterprises and developers.






