
Thesis
The rapid acceleration of AI is the result of a powerful feedback loop where advances in algorithmic breakthroughs, improvements in hardware infrastructure, increased data availability, and funding reinforce one another. New model architectures and higher-performing GPUs don’t just enhance model training performance; they attract more investment, driving more technological R&D and fueling further breakthroughs. This virtuous cycle is the engine behind the pace of progress in AI and the advent of increasingly capable foundation models.
Symbolic AI
Before deep learning, progress in AI was driven largely by symbolic systems, or programs that manipulated explicit symbols and rules rather than learned representations. Early work in logic, search, and graph-based planning, along with expert systems in domains like medicine and chemistry, showed that carefully engineered rules and knowledge graphs could solve constrained problems remarkably well. These successes helped fuel the first big wave of optimism around AI in the 1960s–80s, even as perceptrons and early neural networks fell out of favor.
Yet symbolic AI eventually hit a ceiling. Its symbols were defined only in terms of other symbols, not in terms of perception or action in the real world. This “symbol grounding” problem meant that systems remained brittle, so slight changes in wording or environment could cause catastrophic failures because the models had no autonomous way to connect their internal representations to reality.
As tasks grew more complex, the cost of hand-coding rules and ontologies grew, progress slowed, and AI entered its first “winter.” Much of the later interest in learned world models can be read as a response to this unresolved tension. It is an attempt to learn structured representations of the world from data rather than defining them by hand. Deep learning, and later transformer-based architectures, let engineers bypass hand-engineering symbolic structures and instead learn high-dimensional representations directly from data at scale.
Algorithmic Advancements
The rapid advancement of artificial intelligence in recent years was made possible by several key algorithmic breakthroughs. These developments shaped how AI systems were trained and scaled, leading to dramatic improvements in their capabilities and costs.
Beginning in 2017, OpenAI demonstrated that reinforcement learning systems could scale far beyond prior expectations through projects like OpenAI Five, which trained using Proximal Policy Optimization across 256 GPUs and 128K CPU cores and learned the equivalent of 180 years of Dota 2 self-play per day, entirely from scratch and without human data. This work showed that long-horizon, partially observed, multi-agent environments could be mastered by existing algorithms when run at massive scale, producing coordinated strategies that surprised professional players.
The invention of transformer architectures was one of the most significant breakthroughs in modern AI. In 2017, a team of Google researchers, led by Ashish Vaswani and Noam Shazeer, released the paper Attention Is All You Need, introducing the self-attention mechanism as a replacement for recurrent and convolutional sequence models.
The core innovation was the ability of self-attention to let a model directly relate every token in a sequence to every other token, enabling it to capture long-range dependencies and globally relevant context without relying on step-by-step recurrence. This architecture avoided the local representation traps that RNNs and CNNs often fall into, where predictions become overly influenced by recent tokens or local patterns, and allowed the model to flexibly prioritize information across the entire sequence. By removing recurrence, transformers also made it possible to train on sequences in parallel, a practical benefit that later proved essential for scaling.
This ability transformed language processing because it sped up the processing time for a sequence of text and enabled a deeper understanding of context independent of the distance between words in a phrase. In June 2018, OpenAI used this architecture to build its first Generative Pre-trained Transformer (GPT) model and demonstrated how transformers could be scaled and adapted for generation.
Before GPT-1, natural language models mostly relied on supervised learning from large corpora of manually labeled data, making it prohibitively expensive and time-consuming to train large models. However, this all changed with the introduction of scaling laws. Scaling laws for language models, which describe how increases in model size, dataset size, and the computation used for model training can predictably lead to language model performance improvements, were first proposed in 2020 by an OpenAI team led by researcher Jared Kaplan.
Although previous findings from Google’s 2019 BERT paper and OpenAI’s 2019 GPT-2 paper hinted at the existence of scaling behavior, Kaplan’s 2020 paper was the first to systematically study and propose the existence of such a phenomenon for language models. The discovery of scaling laws provided evidence and formal descriptions of the relationship between LLM performance and the quantity of compute used for model training, which helped guide the development of future models like GPT-3, GPT-4, and GPT-4o.
Techniques such as reinforcement learning from human feedback (RLHF), transfer learning, and mixture of experts (MoE) contributed to the emergence and optimization of foundation models, which are machine learning models trained on vast datasets that can be applied across a broad set of use cases.
To explain each of these techniques in brief, RLHF incorporates human feedback as reward signals to train AI models to align better with human preferences. Transfer learning describes the process of pre-training a model on a large dataset for a general task before fine-tuning the model for a specific task using a smaller dataset to achieve better performance with limited data and leverage knowledge from similar domains. MoE is an architecture where a neural network is segmented into individual components specializing in different aspects of a task. A gating network decides which expert should handle inputs into the model and combines the outputs of the selected experts.
Software and Hardware Infrastructure
Algorithmic developments revolutionized AI model architectures and training approaches, but these innovations could not have been realized without concurrent progress in both software and hardware infrastructure. OpenAI’s ability to scale model training in particular has been shaped by investments in software infrastructure. In 2018, the company pushed Kubernetes beyond typical industry limits, scaling clusters to 2.5K nodes to support large training jobs and reinforcement-learning experiments. This work required fixing systems-level bottlenecks across storage, networking, and scheduling that only emerged at large scale.
OpenAI also built internal tooling, such as Rapid, a distributed RL training system that supported projects like OpenAI Five, which relied on hundreds of GPUs and tens of thousands of CPU cores to coordinate self-play at very high throughput. These early investments created a foundation where researchers could reliably run large-scale experiments without rewriting code or fighting infrastructure constraints.
By 2021, OpenAI had expanded these capabilities to 7.5K-node Kubernetes clusters, allowing a single training run to span hundreds of GPUs and supporting workloads for GPT-3, CLIP, DALL·E, and scaling-laws research. To achieve this, OpenAI reworked its networking stack, improved cluster-wide reliability, and built new systems for resource management, scheduling, and monitoring. The result was an infrastructure layer that let researchers scale experiments quickly and consistently, making software orchestration a central enabler of frontier-level model development.
The computational demands of training increasingly complex models on larger datasets required specialized hardware solutions to make large-scale AI development both technically and economically feasible. Advancements in computer chip architectures, such as Nvidia's GPUs, Google’s TPUs, and Intel’s IPUs, enabled modern AI development by providing the parallel processing capabilities required for training large machine learning neural networks. Originally intended to assist in the rendering of 3D graphics and video, these chips became more flexible and programmable over time, supporting the computational demands of machine learning training.
For instance, in November 2023, Nvidia announced the Nvidia H200 Tensor Core GPU to “handle massive amounts of data for generative AI and high-performance computing workloads.” The H200 GPU was capable of delivering memory at nearly double the capacity and 2.4x more bandwidth compared with its predecessor, the Nvidia A100, which was released three years prior in May 2020.
Similarly, in December 2024, Google released its Trillium Tensor Processing Unit (TPU). Compared to the previous generation of Google’s Cloud TPU v5p, which was released one year prior in December 2023, Trillium TPUs deliver 4x faster training for dense LLMs like Llama-2-70b and up to 2.5x better performance per dollar. Nvidia's development and deployment of networking technologies, most notably through NVLink and InfiniBand, also removed critical bottlenecks in orchestrating multi-GPU training systems.
Moreover, advancements in networking resolved bottlenecks in orchestrating multi-GPU training systems. Early deep learning models could be trained on a single machine with one or a few GPUs, but as model sizes and datasets expanded, researchers shifted towards distributing training workloads across multiple servers with multiple GPUs. This shift exposed networking as a critical component of performance, as fast interconnects were necessary to handle frequent gradient exchanges and parameter updates without slowing down training.
In addition, key technologies like Nvidia NVLink and the adoption of InfiniBand evolved networking technologies in AI from basic point-to-point connections to sophisticated high-bandwidth network fabrics. Introduced in March 2014, Nvidia NVLink is a high-bandwidth, low-latency interconnect to facilitate data exchange in multi-GPU systems. Unlike its predecessor, PCI Express (PCIe), devices using NVLinks can use mesh networking to communicate instead of a central hub, addressing data exchange demands that traditional PCIe buses could not keep up with.
For instance, in 2024, the most advanced PCIe standard offers 128 GB/s of bandwidth, while a system consisting of eight H100 GPUs connected to four NVLink switch chips can achieve GPU interconnect speeds of up to 900 GB/s. Furthermore, each new NVLink generation increased intranode bandwidth. NVLink 3.0 provided approximately 600 GB/s of bidirectional GPU bandwidth, while the latest NVLink 4.0, introduced in March 2022, provided up to 900 GB/s bandwidth per GPU.
While NVLink improved communication between GPUs on a server, the development of Infiniband improved communication between servers, allowing for low latency and efficient data transfer. Infiniband is a networking technology that enables direct communication between servers and storage systems, bypassing the overhead of CPU systems to deliver high-bandwidth and low-latency data transfer. In March 2019, Nvidia acquired Mellanox, the last independent supplier of InfiniBand products. In November 2020, Nvidia introduced its Mellanox NDR 400 InfiniBand platform, which offered communication speeds of 400 Gb/s. In March 2024, Nvidia announced the Nvidia Quantum-X800 Infiniband platform, capable of end-to-end 800 Gb/s throughput.
In 2025, the largest AI models, with hundreds of billions or trillions of parameters, are all trained on AI supercomputers, which consist of clusters of servers where networking between GPUs is often the bottleneck to scaling. Networking technologies like NVLink and Infiniband allowed for near-linear scaling of training jobs to hundreds of servers by keeping the communication overhead between servers and GPUs low. Consequently, advancements in networking and improvements in throughput and latency were instrumental in advancing the scale and efficacy of training AI models.
Data Availability and Management
Another tailwind driving the progress of AI has been the increasing availability of data. The internet’s vast repository of text, video, and image data has proven to be an invaluable resource for training large language models.
Importantly, this data has become legible to AI. Specialized datasets like Common Crawl, RefinedWeb, and The Pile enabled models to easily access diverse data and develop broad knowledge across different domains. Web scraping technologies and data processing pipelines also evolved to more efficiently collect, clean, and prepare training data at large scales. 60% of OpenAI’s GPT-3 pre-training dataset came from a filtered version of Common Crawl, with the rest coming from datasets such as WebText2, Books1, Books2, and Wikipedia.
Not only is the repository of data that LLMs have access to vast, but it is also quickly growing. In 2010, approximately 2 zettabytes of data were generated globally in total. By 2024, this figure was estimated to be around 147 zettabytes, representing a 74-fold increase in 14 years. In 2024, more than 400 million terabytes of data were created daily. In 2024, an estimated 90% of the world’s data was generated between 2022 and 2024. This illustrates how dramatically data creation is accelerating. The total amount of data created, captured, and consumed globally is projected to grow from 147 zettabytes in 2024 to 394 zettabytes in 2028, more than doubling the total amount of global data within five years.
Financial Investment
Funding is another component of the flywheel driving AI progress. Financial investment in AI globally has increased exponentially between 2014 and 2024, fueling accelerated growth in model capability as well as the aforementioned growth factors. In 2024, US investments in AI totaled $67 billion, and between 2013 and 2022, global investment in AI reached nearly $934 billion. Funding for AI startups grew from $670 million in 2011 to $36 billion in 2020.
Moreover, cloud computing providers and technology hyperscalers, such as Google, Amazon, and Microsoft, have made massive investments in AI infrastructure, creating computational resources that benefit the entire AI ecosystem - ranging from data centers to software tools, frameworks, and developer tools that make AI development more efficient.
For example, Google announced that it plans to invest $75 billion in cloud servers and data centers in 2025 alone. Amazon, meanwhile, plans to spend over $100 billion in capital expenditures in 2025, with the vast majority going towards AI infrastructure for Amazon Web Services. In January 2025, Microsoft announced a partnership with OpenAI to invest over $100 billion to build Stargate, a new AI supercomputer. A 2022 report conducted by McKinsey revealed that over 50% of respondents planned to commit at least 5% of their digital budgets to AI.
OpenAI Company Overview
Founded in December 2015, OpenAI is an artificial intelligence research and development company seeking to advance artificial general intelligence in a way that is “safe and benefits all of humanity”. OpenAI pursues cutting-edge research in AI, with a particular focus on deep learning and foundational large language models (LLMs). It builds and deploys AI products and services for both consumer and enterprise use, collaborating with various organizations, such as Microsoft and PwC, to bring AI capabilities to a broader market.
OpenAI’s work can be broadly divided into three categories: research, product development and deployment, and policy and safety.
Research: OpenAI’s research teams conduct fundamental and applied research in AI across fields like robotics, compute scaling, and simulated environments, with a focus on advancing AI system capabilities while mitigating harmful risks.
Product: OpenAI’s product development and deployment offerings are responsible for creating and implementing AI products and APIs for developers and companies to build AI-enabled applications.
Safety: OpenAI’s policy and safety teams conduct safety research, develop benchmarks to evaluate ethical AI use, and advocate for responsible AI development.
OpenAI’s product offerings can be categorized into four main areas: 1) Large Language Models, 2) Code Generation and Understanding, 3) Image and Video Generation, and 4) APIs and Services. LLMs include the GPT family of models (GPT-4o, GPT-5, etc.) as well as ChatGPT (Chatbot, API, Enterprise). Code Generation and Understanding refers to OpenAI Codex, a specialized model derived from the GPT family trained on code from public sources. OpenAI Codex is the model that powers GitHub Copilot to provide code suggestions and completions. Products under Image and Video Generation include DALL-E and Sora.
OpenAI also provides several APIs and services, such as its API platform that enables developers to access GPT models and fine-tuning capabilities through a suite of endpoints, embedding libraries to create numerical representations of text, and Playground, a web-based interface where users can experiment with different OpenAI models and tweak parameters.
While initially established as a nonprofit, OpenAI introduced a “capped-profit” for-profit subsidiary in 2019 under the oversight of the nonprofit parent to balance the capital intensity of building foundation models with its overarching mission of ensuring AI development benefits humanity. In 2024–2025, the organization began transitioning away from that capped-profit structure, and in October 2025, OpenAI announced a new governance model consisting of the OpenAI Foundation (the nonprofit parent) and OpenAI Group PBC (a public benefit corporation). As a PBC, OpenAI Group is legally required to advance its stated mission and consider the broader interests of all stakeholders, not solely shareholders.
The OpenAI Foundation continues to control OpenAI Group and now holds conventional equity, with all stockholders participating proportionally in any increase in value, with the goal of aligning long-term incentives across the organization. This updated structure is designed to preserve nonprofit mission control while enabling the capital formation necessary for frontier-scale model development. OpenAI’s organizational design appears intended to reflect a dual aim: achieving large-scale global impact through commercially successful products, and maintaining its mission at the core of its governance and operations.
Founding Story
Post-War Beginnings
“Can machines think?”
This question, contained in the first line of Alan Turing’s seminal 1950 paper, “Computing Machinery and Intelligence”, captured a radical idea that was starting to take shape in the minds of mathematicians and computer scientists alike in the mid-20th century.
In the aftermath of World War II, a small circle of mathematicians, logicians, and codebreakers began contemplating what computers might ultimately become. During the war, Turing worked on cryptanalysis to crack the German Enigma cipher and developed the Bombe machine, an early computational device that automated decryption, proving that machines could perform tasks requiring complex reasoning. In 1948, three years after WWII, Turing published his Intelligent Machinery report, regarded as the first Artificial Intelligence manifesto, proposing that machines might eventually imitate human learning and problem-solving.
At the same time, other prominent thinkers contributed theoretical elements that would go on to lay the groundwork for intelligence. In 1944, John von Neumann introduced his concept of game theory, and in 1948, Norbert Wiener described cybernetics, the science of communication between machines and living things. Computer scientists Claude Shannon and John McCarthy developed foundational research in electronic circuits, Boolean logic, and information processing that would provide the technical foundations for early breakthroughs in artificial intelligence.
In 1950, Turing proposed the Turing Test, a criterion for machine intelligence based on a human’s ability to distinguish outputs from the machine and another human. This test sparked significant public interest in artificial intelligence and public debate about whether machines could have the capacity to think.
In the 1950s, a combination of WWII computing breakthroughs, such as ENIAC and EDVAC, transitioning from military projects to research and business applications, Wiener’s cybernetics movement, growing interest in Shannon’s work in information theory, academic discussion about artificial intelligence sparked by Turing’s ideas, and post-war government funding for scientific research culminated in the 1956 Dartmouth Workshop.
This was an approximately eight-week-long event that gathered eleven mathematicians and scientists for an extended brainstorm on artificial intelligence. Organized by John McCarthy, Claude Shannon, Marvin Minsky, and Nathaniel Rochester, the Dartmouth Workshop coined the term “Artificial Intelligence” and was considered to be the founding event of artificial intelligence as a field.
Early demonstrations of AI soon followed. In the early 1950s, the first working AI programs ran on room-sized computers, capable of playing checkers and chess, indicating that machines, indeed, could execute logical strategies.
In 1958, Frank Rosenblatt invented the perceptron, the first conceptual demonstration of an artificial neural network capable of learning through repeated experimentation. Inspired by the structure of human neurons, Rosenblatt created a mathematical device that could recognize basic patterns through repeated feedback. In 1959, IBM’s Arthur Samuel coined the term “Machine Learning” in a paper describing how computers could beat humans at checkers.
Building on the foundations set in the 1950s, AI research blossomed in the 1960s with introductions in practical applications that seemed to validate bold predictions about AI’s imminent ability to surpass human intellect.
In 1965, the creation of DENDRAL at Stanford marked the introduction of the first expert system, designed to infer molecular structures from chemical data to complete work that previously required human expertise. In 1967, Joseph Weizenbaum created ELIZA, an early natural language processing program that could participate in simple conversations by finding patterns in dialogue. ELIZA rephrased users' inputs as questions, but many people became emotionally convinced that it could understand them.
Several advances in problem-solving algorithms and language understanding also occurred in the 1960s. Researchers developed programs that could solve algebra word problems or manipulate blocks with natural language. AI labs were created at universities across the United States, like MIT, Stanford, and Carnegie Mellon. In 1969, the first International Joint Conference on AI convened, marking the growth of a scientific community around AI.
The First AI Winter
While these advancements sparked great optimism about AI’s potential, AI research began to hit a wall at the turn of the 1960s. Early AI efforts were still mostly rule-based and symbolic, reflecting an assumption that human reasoning could be encoded explicitly. In 1969, Marvin Minsky and Seymour Papert published Perceptrons, a book analyzing neural networks and proving the limitations of single-layer perceptron networks, leading many to abandon neural network research for the next decade, solidifying the AI paradigm around symbolic logic.
In the 1970s, the optimism surrounding AI’s potential clashed with reality, and the field experienced its first “winter” as funding dried up and research stalled. The symbolic and expert systems developed in the 1950s and 1960s struggled with the complexities of the real world and failed to scale beyond demos and narrow puzzles. In 1974, British Mathematician Sir James Lighthill published the Lighthill report, claiming that AI had overpromised and underdelivered in areas like language translation and robotics. This report became the basis for the British government’s decision to cut AI funding for AI research in most British universities during that period.
Similar skepticism for AI arose across the world. In 1969, the US Defense Advanced Research Projects Agency (DARPA), previously a major AI sponsor, passed the Mansfield Amendment, which required the organization to find mission-oriented projects with measurable milestones instead of “basic undirected research.” Researchers were required to show that their work would produce useful military technology for funding. Stagnation in AI research and the Lighthill report suggested that most AI research was unlikely to produce useful technology, so DARPA’s funds were redirected towards other projects like autonomous tanks and battle management systems.
Expert Systems
The AI Winter forced scientists and researchers to confront hard problems and redefine their approaches. In the 1980s, researchers focused on “expert systems” instead of trying to build general intelligence. By embracing rule-based and symbolic logic systems, scientists encoded facts and rules to achieve usefulness in narrow domains. For instance, the XCON system, built in 1978 at Digital Equipment Corp., helped configure computer orders, and systems like MYCIN, built in 1972, could suggest a diagnosis from symptoms by identifying the bacteria causing illnesses.
At this moment, AI finally seemed to be delivering practical value for businesses. By the mid-1980s, nearly two-thirds of Fortune 500 companies were using expert systems in daily operations for use cases like evaluating loans or monitoring industrial equipment. Nevertheless, by the end of the decade, expert systems had largely fallen out of vogue due to a combination of their limitations to narrow use cases, and because of a failure to meet overhyped expectations.
The Machine Learning Renewal
After the rise and fall of expert systems, AI researchers began revisiting neural networks. In 1986, Geoffrey Hinton, David Rumelhart, and Ronald Williams rediscovered the backpropagation learning algorithm, which had been described by Paul Werbos a decade earlier. This breakthrough enabled them to train multi-layer neural networks efficiently, overcoming the limitations of a single-layer perceptron, and led to a small revival in neural network research in the back half of the decade.
In 1989, Yann LeCun utilized backpropagation to train a series of convolutional neural networks (CNNs), coined as LeNet, and demonstrated that they could recognize handwritten digits. This new model architecture illustrated that machine learning algorithms could solve practical computer vision problems and laid the foundations for modern deep learning later on. LeNet showed that neural networks weren’t just theoretical concepts but could solve genuine real-world problems; however, LeCun’s solution still wasn’t practically viable because limited computing power constrained network size, and large labeled datasets were scarce.
In the 1990s, AI slowly emerged from its winter as the field pivoted towards machine learning algorithms that could iteratively improve through experience. Instead of relying on human-coded rules and symbols, researchers increasingly relied on statistics to create AI systems that could learn from data.
New algorithms such as decision trees, support vector methods, and ensemble methods were utilized in AI systems for tasks like pattern recognition. Additionally, the increased availability of online datasets and the propagation of powerful personal computers made training models more accessible.
The watershed moment of this era came in 1997 when IBM’s Deep Blue defeated world chess champion Garry Kasparov. Deep Blue was a supercomputer that used brute-force search and programmed heuristics to evaluate 200 million chess moves per second. Deep Blue’s victory demonstrated that machines could surpass human intellect in certain domains and amplified public and academic interest in machine learning.
Another key development that year was the invention of Long Short-Term Memory (LSTM) by Hochreiter and Schmidhuber. LSTMs are a specialized type of recurrent neural network architecture designed to handle the difficulties of learning from sequential data, like paragraphs. The key innovation of LSTMs was that their memory cell structures allowed them to remember information for long periods and update their memory with new, relevant information to enable sequential data processing. This technology would go on to lead breakthroughs in Natural language processing, speech recognition, and machine translation.
Scale: Big Data and Deep Learning
As the internet expanded in the early 2000s, technology companies like Google and Amazon began applying machine learning to unprecedented quantities of data. Concurrently, Moore’s Law yielded faster CPUs and the rise of GPUs, providing the computing power needed to train more complex AI models. The combination of increasing amounts of data from the internet and sensors with better computing enabled deep neural networks to flourish for the first time.
The architecture that LeCun proposed with LeNet was finally feasible to exploit on a large scale. In 2006, Hinton demonstrated that multi-layer neural networks could be efficiently pre-trained, which suggested that AI could learn representations on its own. In 2009, AI researcher Fei-Fei Li created ImageNet, a labeled dataset of millions of images in more than 1K categories, which became an annual contest for AI researchers and a catalyst for computer vision advances.
In 2012, the AI field experienced a seismic shift with the invention of AlexNet by Alex Krizhevsky, Ilya Sutskever (who later co-founded OpenAI), and Geoffrey Hinton. Sutskever was a PhD student working in Hinton’s lab at the time. He built a deep convolutional neural network and won the ImageNet competition by a large margin, reducing error rates by over ten percentage points. Compared to previous models, AlexNet incorporated a deeper architecture with more layers than previous CNNs, used Rectified Linear Units (ReLu) as its activation function to address the vanishing gradient problem, and trained on two Nvidia GTX 580 GPUs to allow for training on a much larger dataset and implement dropout during training to improve generalizability.
AlexNet’s dramatic performance improvements in the 2012 ImageNet competition were the breakthrough moment that launched the modern deep learning era because it demonstrated that sufficient data, computing power, and architectural innovations could drive neural networks to outperform traditional approaches by significant margins. Almost overnight, researchers abandoned decades of work on hand-selecting features in machine learning models and rushed to implement deep neural networks that could learn generalized knowledge representations over large corpora of data.
One individual AlexNet inspired in particular was Sam Altman, the future co-founder and CEO of OpenAI. In 2012, when AlexNet came out, Altman was watching its progress. In an interview with Bloomberg, Altman recalls that although he had studied AI as an undergrad, he had been distracted by it for a while, and seeing AlexNet was the moment when he realized that:
“Man, deep learning seems real. Also, it seems like it scales. That’s a big, big deal. Someone should do something.”
OpenAI’s Company History
In 2012, AlexNet demonstrated incredible performance on image recognition tasks. AlexNet dramatically lowered the top-5 error rate, from 26.2% achieved by the runner-up models down to just 15.3%, and did so on a massive scale using the ImageNet dataset, which comprised over 14 million annotated images across more than 20K categories.
The performance was impressive, but more importantly, AlexNet’s success represented the culmination of three fundamental inflection points. As discussed in the prior section, for decades, neural networks had been relegated to the backwaters of AI research. Early excitement in the 1970s and 1980s was eventually dampened by significant challenges like vanishing gradients, limited data availability, and computational constraints.
These obstacles led many researchers to favor alternative methods such as support vector machines. Considered the state of the art in the 2000s, support vector machines were more predictable and easier to train on the modest datasets available at the time. Meanwhile, neural network research was largely overshadowed, leaving deep learning as a niche interest pursued by a few researchers like Hinton.
The second factor was the breakthrough in computational power brought about by Nvidia GPUs. In the 2000s, scientists predominantly relied on CPUs for training their models. CPUs process tasks sequentially, which makes the training of large, deep neural networks prohibitively slow. The introduction of Nvidia's CUDA platform in 2007 marked a turning point by enabling widespread access to parallel processing. AlexNet itself was trained on a pair of GTX 580s, which accelerated the training process by hundreds of times compared to traditional CPU-based methods. This breakthrough in hardware made it feasible for researchers to distribute the immense computational workload of neural network training across hundreds of GPU cores
The third factor was the assembly of ImageNet as the de facto dataset for computer vision. As described briefly in the prior section, spearheaded by computer science professor Fei-Fei Li, ImageNet was built on the lessons learned from her earlier, smaller datasets like Caltech 101 (~9K images). Li envisioned a dataset that reflected the complexity of the real world, drawing inspiration from the linguistic database WordNet to define roughly 22K countable object categories comprising over 14 million labeled images.
This massive dataset provided the raw material needed to train deep neural networks effectively and served as the foundation for the ImageNet Large Scale Visual Recognition Challenge. Prior to AlexNet’s entry in the third year of the challenge, the contest was dominated by models based on support vector machines, which only delivered incremental improvements. AlexNet’s neural network submission, leveraging both Nvidia's GPU acceleration and the expansive ImageNet dataset, shattered previous accuracy records and solidified neural networks as the future of AI research in the 2010s.
AlexNet showed that neural networks, when scaled with sufficient data and computational power, could dramatically outperform existing methods in highly complex accuracy-based tasks. For Sam Altman, this was the moment when the potential of AI became undeniable. Altman believed that the scalability of deep learning offered a tangible pathway to artificial general intelligence (AGI), machine intelligence that could intellectually match and eventually surpass humans in all aspects. These early signals from the research community spurred Altman to focus his energies on AI development, setting the stage for the founding of OpenAI.
Sam Altman
Sam Altman, a tech entrepreneur and investor, has been a central figure in OpenAI’s story since its inception. Before OpenAI, Altman was president of Y Combinator, where he showed an interest in fueling research into big future technologies (including AI). Altman became an advocate of AI safety and long‑term research. He was influenced by thinkers concerned with existential risk and pushed the idea that AGI should be developed cautiously for the benefit of all. In OpenAI’s early days, Altman helped articulate the organization’s altruistic mission and co‑authored its charter and strategy, emphasizing broad distribution of AI benefits.
However, as CEO of OpenAI in later years, Altman’s approach evolved toward aggressive deployment and commercialization of AI technology. He became the public face of OpenAI’s products, frequently touting the potential of systems like ChatGPT to transform industries. Altman believed that “the best way to make an AI system safe is by iteratively and gradually releasing it into the world” to learn from real feedback. This philosophy led OpenAI to release models and prototypes at a relatively fast pace, a stance that put it at odds with more cautious voices, both internally at OpenAI and externally from public critics.
By 2023, critics and some internal team members felt Altman was prioritizing growth and profit over safety. Tensions climaxed in November 2023 when the board suddenly fired Altman, citing concerns about his candor and the company’s direction. Many interpreted this as a clash over Altman’s aggressive approach. Ilya Sutskever (Chief Scientist and fellow co-founder) reportedly felt Altman was pushing OpenAI’s software too quickly into users’ hands, writing that “[OpenAI doesn’t] have a solution for steering or controlling a potentially superintelligent AI.” The attempted ouster was short-lived; employee revolt and investor pressure forced the board to reinstate Altman as CEO within a week. By the end of the attempted board “coup” and his reinstatement, Altman had become synonymous with OpenAI’s identity and vision.
After returning, Altman has continued to lead OpenAI’s push toward AGI, but with heightened scrutiny. Overall, Altman has steered OpenAI from a cautious research lab to an AI industry leader that is willing to commercialize cutting‑edge models to fund further research, a trajectory that he deems necessary to achieve AGI, even if it means accepting greater short‑term risk. His transformation from an AI safety‑focused advocate to a pragmatic, product‑driven CEO embodies the balancing act at the center of OpenAI.
Ilya Sutskever
Ilya Sutskever is often described as the “brain” behind OpenAI’s original core research and AGI strategy. As described earlier, as a PhD and postdoctoral researcher under Geoffrey Hinton, Sutskever was instrumental in early deep learning breakthroughs. He brought this expertise to OpenAI as co-founder and Chief Scientist.
Sutskever’s contributions at OpenAI were instrumental to the company’s initial success. He helped develop the fundamental architectures and techniques that underlie foundation models. He was a key author on influential research papers and guided teams working on unsupervised learning, reinforcement learning, and super alignment (alignment of superintelligent AI). Philosophically, Sutskever had always been deeply interested in AGI. He had been one of the strongest internal voices insisting that AGI is achievable with enough scale and the right algorithms, and that OpenAI’s purpose is to lead that effort responsibly.
In the early years of OpenAI, Sutskever supported open research and collaboration, but as OpenAI shifted strategy, he agreed with limiting certain model releases for safety (for instance, the deliberate staged release of GPT‑2 in 2019 had his support, to study misuse risks). Sutskever also became increasingly focused on AI safety as models grew more powerful. In 2023, he co‑led OpenAI’s Superalignment project, a dedicated effort to solve the technical alignment problem for superintelligent AI within four years.
Despite his commitment to safety research, Sutskever found himself at odds with Sam Altman’s pace of deployment. As a board member, Sutskever was one of the chief architects of Altman’s surprise firing in November 2023, motivated by fears that OpenAI was moving too fast without fully solving how to “steer or control a potentially superintelligent AI.” He and others on the board believed a pause or leadership change was necessary to refocus on risk mitigation. However, when the ouster backfired, Sutskever reversed course within days, and he signed the open letter urging Altman’s return, publicly apologizing and acknowledging the depth of employee support for Altman.
Though Altman and Sutskever remained amicable in public, the crisis significantly decreased Sutskever’s role at the company. By May 2024, Ilya Sutskever stepped down as Chief Scientist and departed OpenAI. He went on to found a new startup called Safe Superintelligence (SSI) in September 2024, aiming to pursue safe AGI research with a smaller, more cautious team. Sutskever, once the technical heart of OpenAI, chose to start afresh rather than continue amid OpenAI’s more commercial, fast‑paced environment.
Post OpenAI, Sutskever’s influence on AGI approaches remains extensive. Sutskever championed the importance of fundamental research and alignment at OpenAI, and appears to be doubling down on safety‑driven AGI development at SSI. Sutskever’s experiences show the tension that some believe exists between ambition and caution in developing AGI: Sutskever seems to have had the view that commercialization may be necessary to secure further funding for AGI, but that AGI safety should remain a higher priority.
Elon Musk
Elon Musk played a crucial role in OpenAI’s founding and early direction, though he departed relatively early and later became one of its most prominent critics.
Musk’s interest in AI was driven by fascination and fear. Musk has repeatedly warned over the 2010s and 2020s that superintelligent AI could become an existential threat if not properly controlled. In the mid‑2010s, Musk was alarmed by the rapid progress at DeepMind (which Google acquired in 2014) and by conversations with insiders like Larry Page who, in Musk’s view, seemed too cavalier about AI surpassing human intelligence.
Musk co-founded OpenAI in 2015 as a direct response to these fears. Musk envisioned OpenAI as a non‑profit “counterweight” to big tech companies, one that would focus on safe AGI and share its research openly. As a co‑chair of OpenAI in its first years, Musk provided not just funding but also a strong philosophical grounding in existential risk minimization. He often spoke about avoiding an “AI arms race” and advocated for cooperative, careful development of AI.
Musk pushed for bold goals (he encouraged the team to announce a $1 billion fund commitment at launch to show seriousness) but also urged the organization to be very mindful of safety. However, by early 2018, Musk’s relationship with OpenAI became strained. He felt OpenAI was not progressing fast enough to “catch up” to Google and reportedly offered to take charge of the organization. When other founders did not accept his proposal for greater control, Musk decided to leave OpenAI’s board in February 2018 to pursue AGI development through his own companies.
Upon leaving, he stated that he would focus on AI development at Tesla and that OpenAI would be better off charting its own path. Musk also withdrew a large planned donation, creating a funding gap that was later filled by Reid Hoffman (founder of LinkedIn and Inflection AI). After his departure, Elon Musk grew increasingly vocal in his criticism of OpenAI’s trajectory. In 2019, when OpenAI pivoted to a capped‑profit model and partnered with Microsoft, Musk expressed disappointment, suggesting that OpenAI had deviated from its open, non‑profit ethos.
By 2023, Musk openly criticized the company, saying “OpenAI was created as an open source (which is why I named it ‘Open’ AI), non-profit company to serve as a counterweight to Google, but now it has become a closed source, maximum-profit company effectively controlled by Microsoft…Not what I intended at all.” Musk even took to calling Sam Altman “Scam Altman”, indicating a personal rift.
In 2023, Musk founded xAI, his own AI venture, stating the goal to build a truth‑seeking AI and explicitly positioning it as an “open-source” alternative to OpenAI. He also became involved in legal disputes with OpenAI; in early 2023, he threatened legal action, claiming OpenAI’s pivot to for‑profit was against the original founding agreements, and in late 2024, he led a consortium that attempted a $98 billion bid to take control of OpenAI’s parent entity. Despite his early exit, Elon Musk’s influence on OpenAI’s AGI approach remains important. In the broader AI discourse, Musk remains a prominent voice warning against unchecked AI development and AGI existential risk, even as he heads xAI, a key OpenAI competitor in the foundational model space.
Putting Together a Team to Build AGI
The Founding Dinners
The creation of OpenAI was preceded by a series of private gatherings and discussions in 2015 that brought together tech entrepreneurs and AI researchers who shared both excitement about AI’s potential and anxiety about its risks. These founding dinners, reportedly attended by Sam Altman, Elon Musk, and a small circle of confidants, were where the core vision of OpenAI began to take shape. Though AGI was the listed goal, the co-founders were less sure about how to get there. When Dario Amodei (then at Google Brain, former OpenAI researcher, and future founder of Anthropic) asked what the goal of OpenAI was in lieu of “build[ing] a friendly A.I. and then release its source code into the world,” CTO Greg Brockman responded that “[OpenAI’s] goal right now… is to do the best thing there is to do. It’s a little vague.”
Key Team Members
OpenAI’s founding team was a blend of Silicon Valley tech entrepreneurs and some of the world’s leading AI researchers, reflecting the interdisciplinary nature of the challenge. At launch, the organization named Sam Altman and Elon Musk as co-chairs of the board, signaling both a commitment to its mission and star power to draw talent and funds. Ilya Sutskever came on as OpenAI’s first Research Director, with responsibility for setting the research vision for OpenAI and attracting top research talent to OpenAI. Greg Brockman, who left his role as CTO of Stripe to join, became OpenAI’s CTO and was responsible for building out the engineering team. The early technical team featured Wojciech Zaremba and John Schulman, researchers known for contributions to deep learning and robotics, as well as Trevor Blackwell, Vicki Cheung, Andrej Karpathy, Durk Kingma, and Pamela Vagata.
This mix included experts in various subfields. Karpathy was known for work in computer vision, later became Tesla’s AI director, and founder of Eureka Labs; Kingma co-developed important generative modeling techniques (VAE); Schulman was an expert in reinforcement learning. OpenAI also assembled a notable group of advisors; luminaries like Pieter Abbeel (co-founder of Covariant, developer of AI models for robots), Yoshua Bengio (“Godfather of AI” and 2018 Turing Award laureate alongside Geoffrey Hinton and Yann LeCun), Alan Kay (2003 Turing Award Laureate), Sergey Levine (co-founder of Physical Intelligence, developer of AI models for robots), and Nick Bostrom (AGI alignment and existential risk philosopher) were listed as advisors or supporters early on. The founding team’s breadth indicated OpenAI’s intent to tackle everything from game-playing AI to robotics to language models.
On the business and funding side, in addition to Musk and Altman, Reid Hoffman (LinkedIn co-founder), Jessica Livingston (Y Combinator co-founder), Peter Thiel (Founders Fund and PayPal co-founder), Amazon Web Services, and Infosys were announced as initial funders. Many of these figures attended early meetings or were involved in shaping the strategy (Thiel, for example, had an interest in long-term tech breakthroughs, and Hoffman was interested in the societal impacts of AI). Each founding member had a defined role: Altman as the facilitator and public face, Musk as the visionary benefactor, Brockman running day-to-day engineering, and Sutskever leading research. This core team established OpenAI’s reputation from the start as a heavyweight effort uniting talent from both academia and industry.
Early AGI View
At its founding, OpenAI explicitly positioned itself as an organization focused on the path to AGI, meaning AI that can match or exceed human capabilities across a broad range of tasks. The founders conceptualized AGI as a long-term, but not infinite, project. Timelines would manifest on the order of decades, but the team remained agnostic about exactly when it might arrive, emphasizing instead that preparation and guiding principles were needed immediately.
The OpenAI team believed that AGI would most likely emerge from an extension of then-current techniques (deep learning and reinforcement learning), scaled up and combined with new ideas. They did not see a need to invent a wholly new paradigm for intelligence, but rather to incrementally whittle away at AI’s limitations, task by task. This philosophy was evident in their research agenda, which tackled a variety of domains (vision, language, robotics, games), the idea being that progress in many narrow domains would eventually yield general intelligence.
An internal concept that guided OpenAI’s thinking was something akin to an “AI Kardashev scale” or levels of AI capability. Though not public at the time, OpenAI researchers thought in terms of milestones. For example, achieving human-level performance in a video game, then achieving human-level dialogue, then human-level learning, and so on, each increasing the “general” nature of the AI. Eventually, these stages would lead to an AI that can do anything a human can, and more.
From the outset, OpenAI’s philosophy was that AGI could be an overwhelmingly positive development for humanity, ending scarcity, curing diseases, improving the quality of life globally, but only if its rollout was managed carefully. Thus, the founding team stressed cooperative principles. The OpenAI Charter later encapsulated this by stating that if any one “value-aligned, safety-conscious” lab (including OpenAI) was close to AGI, “we commit to stop competing with and start assisting this project.” OpenAI’s founding AGI philosophy was simultaneously optimistic yet cautious. The company assumed AGI is achievable and would work actively toward it, but simultaneously build in ethical guardrails and a mindset that the outcome (benefiting humanity) is far more important than just being the first to reach AGI.
Existential Risk
Given that several founders were motivated by the dangers of uncontrolled AI, OpenAI’s founding documents and discussions gave significant attention to safety measures. The team was well aware of existential risk scenarios popularized by thinkers like Nick Bostrom and Eliezer Yudkowsky, where a superintelligent AI would pursue goals misaligned with human values directly or indirectly, with catastrophic results.
To address this, OpenAI committed to a focus on AI safety research from day one. This included technical research on alignment (how to ensure AI systems do what humans intend) and policy research on how to deploy powerful AI systems responsibly. OpenAI’s initial press release noted the difficulty of predicting timelines for human-level AI and the dual-use nature of such technology (it could “benefit society” or “damage society if built or used incorrectly”). By setting up as a non-profit and pledging to collaborate and publish openly, the founders believed they were structurally mitigating some risk as the lab would not be under pressure to take reckless shortcuts for profit or hide progress.
In practice, early OpenAI sought to address long-term risk by shaping the research culture by hiring researchers interested not just in raw capability but also in ethics and safety, and they funded work on AI alignment strategies (such as inverse reinforcement learning and, later, debate and reward modeling for alignment). They also engaged with the wider community on safety. For example, OpenAI attended and supported the Beneficial AI conference at Asilomar in 2017, which discussed AI principles to avoid existential hazards.
Another way the founding team addressed risk was by instituting a board that had an unusual level of power; the board of the non-profit could even override the management of the for-profit arm if it believed an OpenAI project was leading to undue risk. This governance structure was meant as a bulwark against the scenario of a CEO unilaterally pushing to deploy a dangerous AI system; the board (bound by the non-profit mission) was supposed to keep the mission on track. Concern for existential risk was built into OpenAI, influencing everything from research priorities (with alignment work running in parallel to capability work) to institutional design.
OpenAI Name Origin
The name “OpenAI” was chosen in deliberate contrast to the state of AI research at the time. In 2015, cutting-edge AI was being developed behind closed doors in large companies (Google, Facebook) or secretive government projects. By choosing the name OpenAI, the team signaled that their organization would be “open” in two possible interpretations.
The first interpretation, as defined by Musk (who originally proposed the name OpenAI), meant that OpenAI would collaborate openly and publish its findings for the world. The founding statement promised to “publish… papers, blog posts, or code” and to share any patents with the public. This was meant to engender a spirit of transparency and trust, inviting the global scientific community to join in advancing AI rather than treating it as proprietary IP.
The second interpretation referred to the outcome. OpenAI was dedicated to ensuring the benefits of AI were open to all, not locked behind one corporation or government. As Altman argued, AI’s advantages should be broadly distributed, rather than creating a scenario where only a select few reaped the rewards.
Internally, the leadership acknowledged that “open” did not necessarily mean releasing every detail of every project immediately. Early on in the company’s development, Altman stressed that contrary to popular expectations, OpenAI would not “release all of our source code.” Sutskever also made it clear in internal emails that “open” meant that the benefits of AI would accrue to the public, but OpenAI would not build in public after a certain scale:
“As we get closer to building AI, it will make sense to start being less open. The Open in OpenAI means that everyone should benefit from the fruits of AI after it's built, but it's totally OK to not share the science (even though sharing everything is definitely the right strategy in the short and possibly medium term for recruitment purposes).”
Tensions between the first and second interpretations began to grow when OpenAI chose not to open-source the full version of GPT-2 in early 2019, citing misuse concerns. Nonetheless, the name has been a guiding ideal. The rationale was that an open approach would build trust and safety through cooperation and prevent any single actor from gaining a decisive advantage in AI.
Over the years, critics pointed out that OpenAI became less “open” (as it partnered with Microsoft and kept certain models closed), but the organization has maintained that its end goal remains the same: to openly share AGI’s benefits with humanity. At least in the beginning, the name “OpenAI” was chosen to stake a philosophical position on the journey to AGI, safety, transparency, and common good above all, even as commercial pressures began to erode some of OpenAI’s founding commitments.
OpenAI’s AGI Philosophy
The AI Kardashev Scale
As OpenAI progressed, it internally developed a framework to map the stages on the road to AGI. This was essentially an AI capability scale, analogous to the Kardashev scale used to classify civilizations. OpenAI defined a series of levels to classify AI systems, which gradually evolved as their research advanced. By mid-2024, this had crystallized into a five-level scale that OpenAI shared with its employees to benchmark progress toward AGI.
Level 1: “Chatbots”, capable of natural language conversation (ChatGPT is a prime example of this first rung).
Level 2: “Reasoners”, AI that can perform human-level problem-solving in specialized domains, essentially matching human intelligence at certain tasks.
Level 3: “Agents” are AI systems that can not only reason but also take actions in the real or digital world autonomously, handling tasks that might normally require a human with a doctoral-level education.
Level 4: “Innovators” AI that can help drive scientific or creative innovation, meaning they contribute original ideas or solutions beyond existing human knowledge.
Level 5: “Organizations”, referring to AI that can perform the work of an entire organization, a full general intelligence capable of orchestrating complex, multi-step projects and managing resources like a group of humans would.
OpenAI executives in 2024 told staff that they believed they were at Level 1 (Chatbot stage) but on the cusp of Level 2. This roadmap is OpenAI’s answer to “How close are we to AGI?”, with Level 5 corresponding to a true artificial general intelligence that can outperform humans at most tasks. OpenAI aimed to measure progress more concretely and communicate both internally and eventually externally about how advanced their AI systems are. It also reflects OpenAI’s philosophy that AGI is not a single leap, but a continuum of increasingly capable systems.
AI Safety vs “Move Fast and Break Things”
One of the core tensions throughout OpenAI’s history has been the debate between prioritizing AI safety and taking a more aggressive, Silicon Valley-style “move fast and break things” approach to development and deployment. Internally, this manifested as a split between team members (and board members) who wanted to thoroughly test and prove the safety of advanced AI systems before releasing them, and those who felt that iterative deployment to the public was the best way to learn and improve.
By late 2023, this philosophical rift came to a head. Sam Altman represented the camp that favored rapid deployment. He argued that exposing models like ChatGPT to millions of users helps uncover problems and yields valuable feedback to refine model development. Altman believed that cautious, purely in-lab development could not anticipate real-world issues as effectively, and that a gradual ramp-up of capabilities in public, alongside product commercialization to supercharge funding growth, would actually make the technology safer in the long run.
On the other side, Ilya Sutskever urged more caution. Sutskever pointed out that as AI systems approach human-level reasoning (and beyond), unpredictable behaviors could emerge, and alignment (ensuring AI goals mesh with human values) becomes critically hard to guarantee in the wild. This faction preferred intensive testing, formal verification, and even holding back certain model releases until better theoretical solutions for control were found.
The clash of these viewpoints played out in public in November 2023, when OpenAI’s board (led by Sutskever and several safety-conscious members) abruptly fired Altman. Implicitly, the firing was due to concerns that he was driving OpenAI to take unacceptable risks as a result of its rapid product commercialization.
In an OpenAI blog post just months before Altman’s firing, Sutskever had written, “We don’t have a solution for…controlling a potentially superintelligent AI” yet, making his concern that the technology was outpacing internal safeguards public. Meanwhile, Altman countered that delaying releases could let competitors get ahead or could slow down the very learning process needed to make AI safe. After Altman’s brief ouster and dramatic return, it became clear that the “move fast” side had won out; employee sentiment and investor backing favored continuing OpenAI’s rapid progress.
Even as OpenAI promised better internal communication and more transparency with its board on safety issues, factions within OpenAI, or “tribes”, as Altman called them, were dismantled systematically. Several OpenAI co-founders, including Sutskever and Mira Murati (then OpenAI's CTO), alongside other key OpenAI employees, would leave over the next year, and the entire board was reconstituted.
OpenAI’s challenge since then has been to not appear reckless while still pushing forward. The company often states that it believes in deploying AI carefully and has improved its models’ safety. Nonetheless, critics remain who see OpenAI as having shifted toward a “break things” mentality by releasing powerful models (GPT-4, etc.) without fully solving known problems like bias, misinformation, or the theoretical alignment problem.
Commercialization
OpenAI’s structure and strategy underwent a significant evolution from pure research to commercialization, especially from 2019 onward. Initially established as a non-profit, OpenAI had no pressure to generate revenue and was funded by donations. However, as the scale of experiments (and the corresponding costs) grew, OpenAI embraced commercialization as a means to sustain its mission. The first major step was the 2019 restructuring into a capped-profit model, which allowed it to accept venture investments.
The direct catalyst was the high cost of training state-of-the-art models; compute and talent were expensive, and OpenAI’s leadership openly acknowledged that without new capital, they’d hit a wall. Once the for-profit OpenAI LP was created, OpenAI quickly entered into a partnership with Microsoft. Microsoft’s $1 billion investment in 2019 provided not just funds but also access to a massive cloud computing infrastructure (Azure) tailored for OpenAI’s needs. In return, Microsoft gained a preferred position to commercially utilize OpenAI’s technologies (for example, the exclusive license to GPT-3 for integration into its products and Azure services).
This partnership marked the beginning of OpenAI’s monetization of its research. By 2020, OpenAI had launched a cloud API offering, allowing developers to pay to use GPT-3 and other models, a significant shift from earlier years when code and models were released openly. The revenue from the API and later consumer-facing products (like the ChatGPT Plus subscription launched in 2023) began to fund further research. OpenAI’s commercialization accelerated with the unprecedented success of ChatGPT.
ChatGPT, which launched in November 2022, reached 100 million monthly active users within just two months, a record at the time. Suddenly, OpenAI was a household name, and enterprises were lining up to collaborate or invest. In early 2023, Microsoft invested an additional $10 billion into OpenAI, in a deal that further deepened commercial ties (integrating OpenAI models into Microsoft’s Office, Bing, and Azure offerings). OpenAI also started forming partnerships across various industries, for instance, working with GitHub on Copilot (an AI coding assistant based on OpenAI’s Codex model) and with companies like Stripe and Khan Academy to pilot its GPT-4 model.
While these moves provided much-needed capital and data (from real-world usage) to OpenAI, they also meant that OpenAI had effectively become a business with customers and product deadlines. Some critics argue that this created a conflict of interest. The more OpenAI chased revenue, the more incentive it had to release powerful AI quickly, possibly at odds with safety concerns. The leadership tried to counter this by framing commercialization as a means to an end.
Sam Altman frequently said that OpenAI’s profits (capped for investors) would all go into funding the expensive mission of building AGI, and that they would not sacrifice safety for profit, though skeptics remained unconvinced. By 2024, OpenAI’s commercialization reached another inflection point. After the board saga, OpenAI held discussions about removing the profit cap and transitioning into a traditional for-profit corporation. In October 2024, OpenAI raised $6 billion in a new funding round at a valuation of $157 billion, with the condition that it would convert into a for-profit company within two years, indicating that even more traditional venture capital dynamics are coming into play. In March 2025, OpenAI raised an additional $40 billion in an investment round led by SoftBank, bringing the company to a $300 billion valuation. Seven months later, it reached a $500 billion valuation after a $6.6 billion share sale.
Under research, competitive, and internal/external pressure, OpenAI evolved from a grant-funded AI safety lab to a global startup with significant revenue streams and products used by millions. This commercial pivot not only provided the resources to train frontier models, but it also fundamentally changed the organization’s structure and external image. By 2025, OpenAI was often mentioned in the same breath as the largest public tech companies, and its decisions are scrutinized not only for scientific merit but also for business implications, even as OpenAI tries to maintain alignment with its founding mission.
Board Drama, Key Departures, and Corporate Restructuring
Sam Altman’s Ousting and Reinstatement
The events of November 2023 at OpenAI marked one of the most dramatic corporate leadership crises in recent tech history. As described briefly earlier, in a surprise announcement on November 17, 2023, OpenAI’s board of directors fired CEO Sam Altman, citing that he had not been “consistently candid” with the board. Along with Altman, President and co-founder Greg Brockman also departed (he resigned in protest after Altman’s firing). This move was shocking because OpenAI had been enjoying a string of successes (ChatGPT, GPT-4) and Altman was widely seen as the driving force behind the company. The fallout revealed a schism at the board level, primarily over issues of trust and the pace of AI development.
The board (which at the time included Ilya Sutskever, Quora CEO Adam D’Angelo, tech entrepreneur Tasha McCauley, and academic Helen Toner) was more concerned about long-term safety and felt Altman was pushing too fast without adequate governance. In the immediate aftermath, OpenAI’s CTO Mira Murati was appointed interim CEO, and the board began searching for a permanent replacement, even as Altman’s ouster sparked public controversy.
Over that weekend, nearly the entire OpenAI staff of researchers and engineers revolted. Altman and Brockman were courted by Microsoft, which offered them positions to continue their work; over 700 OpenAI employees (out of 770) signed an open letter saying they would follow Altman to Microsoft unless the board reversed its decision. This unprecedented show of employee support, alongside pressure from investors, forced a rapid reconsideration.
By November 21, 2023, OpenAI announced a deal to reinstate Sam Altman as CEO and replace the board with a new slate of directors. The new interim board consisted of more industry‑friendly figures (including former Salesforce co‑CEO Bret Taylor and former U.S. Treasury Secretary Larry Summers), with the old board members (except Sutskever) departing. Ilya Sutskever, who had been part of the decision to fire Altman, publicly apologized for the turmoil and was retained as Chief Scientist initially, but was removed from the board. In the end, Altman returned to OpenAI’s helm just days after being ousted, and Greg Brockman also returned to the company (though not to the board).
Unsealed court documents, which were released in 2025, have since added much more texture to why the board moved so abruptly. In a deposition taken as part of Elon Musk’s lawsuit against OpenAI, co-founder and former chief scientist Ilya Sutskever testified that he believed Altman “lied habitually” and described a “consistent pattern” of pitting senior leaders against one another, including then-CTO Mira Murati and executive Daniela Amodei (who later left to co-found Anthropic).
Sutskever said he had spent more than a year quietly documenting concerns about Altman’s conduct and ultimately prepared a 52-page memo at the request of directors Adam D’Angelo, Helen Toner, and Tasha McCauley that catalogued instances where, in his view, Altman misled the board, obscured internal safety processes, and manipulated internal dynamics. Other reporting on the deposition indicates that former board members also weighed accounts that Altman had failed to inform them in advance about major product launches (such as ChatGPT) and had not clearly disclosed his control of OpenAI’s startup fund, deepening their sense that they could not rely on him to be transparent with a mission-driven nonprofit board.
The court filings also reveal that, in the chaotic days after Altman’s firing, OpenAI briefly explored a potential merger with rival Anthropic as a contingency plan if the company could not be stabilized under new leadership. According to Sutskever’s testimony and other accounts, some directors saw a merger or even an orderly wind-down of OpenAI as consistent with their duty to minimize the risks of misaligned AGI, rather than allow the organization to continue under a CEO they no longer trusted. These details reinforce that the crisis was not simply a clash over “moving too fast” on AI, but the culmination of a prolonged breakdown in trust between Altman and key members of the nonprofit board, one that only reversed when employee and investor pressure made his removal untenable in practice.
This governance crisis made three things clear to public observers. First, it highlighted the immense value placed on Altman’s leadership by the OpenAI team and tech giant partners; essentially, the board could not execute OpenAI’s mission without the support of its employees and Microsoft. Second, it exposed how OpenAI’s unusual governance (a non‑profit board controlling a for‑profit) led to instability, as board directors focused on long‑term risks might clash with management’s near‑term plans. Finally, it brought to light communications issues; the phrase “breakdown of communications” was cited around the firing, indicating Altman and the board had not been on the same page about OpenAI’s trajectory.
After his reinstatement, Altman affirmed his commitment to OpenAI and moved quickly to stabilize the organization. The board was expanded in early 2024 to include new members with technical expertise and credibility to avoid such insular decision-making in the future.
The Altman firing incident has since become a case study in AI company governance. For OpenAI, the immediate impact was an even stronger alignment between Altman and OpenAI’s employees and investors, effectively green‑lighting Altman’s “move fast” strategy going forward, but with an acute awareness that AI safety concerns had fallen to the wayside.
2024 Exodus of Founding Team and Talent
In the aftermath of the late‑2023 leadership saga, OpenAI saw a notable exodus of some founding members and other key talent during 2024. The most high‑profile departure was Ilya Sutskever, co-founder and Chief Scientist. As mentioned, after Altman’s return, Sutskever’s role was diminished; he was removed from the board and, in May 2024, left OpenAI entirely. Sutskever’s exit was symbolic: one of the original architects of OpenAI’s research was leaving the organization he helped build. His departure was coupled with the dismantling of the Superalignment team he had led.
Several other researchers (including Superalignment co-lead Jan Leike) who were focused on long‑term safety and alignment left around this time as well, either to join Sutskever’s new venture or other labs. Sutskever co‑founded Safe Superintelligence Inc. (SSI) in mid‑2024, a new research startup dedicated to building safe AGI with no other product development, taking with him at least one former OpenAI researcher (Daniel Levy) as a co‑founder. SSI managed to raise $1 billion in its first months, indicating strong investor faith in the ex-OpenAI team.
Mira Murati also left OpenAI to start her own AI venture. On September 25, 2024, Murati announced that she was stepping away from the company to “create the time and space to do my own exploration.” This announcement was followed hours later by resignations of OpenAI’s chief research officer, Bob McGrew, and a vice president of research, Barret Zoph. Murati later announced the founding of Thinking Machines Lab in February 2025. McGrew became a senior advisor to the lab, and Zoph became CTO of Thinking Machines.
Furthermore, a number of OpenAI’s safety and policy team members quit in early 2024, apparently out of disillusionment with the board episode and the direction of the company. For example, OpenAI’s former head of policy/regulatory affairs, Miles Brundage, resigned, and several alignment researchers publicly expressed pessimism about OpenAI’s commitment to safety after seeing how the board was treated. This brain drain in 2024 had both practical and cultural impacts.
Practically, OpenAI had to hire aggressively to fill the void. By 2024, the organization was recruiting top researchers and engineers from tech giants (helped by the allure of OpenAI’s high valuation and resources). Culturally, the departure of mission‑driven talent like Sutskever signaled a shift in OpenAI’s internal balance. The center of gravity moved more toward those focused on scaling, engineering, and product delivery. It also meant the loss of some historical memory and context from the founding era. On the other hand, many of the newer employees (who joined during the GPT‑3/ChatGPT boom) were very aligned with Altman’s vision, so OpenAI’s day‑to‑day operations continued relatively unabated.
The 2024 exodus served as an inflection point for the company; OpenAI transitioned from the founders‑run research lab to a next‑generation company less dependent on its original team. By 2025, apart from Sam Altman himself, most of the daily leadership did not include the early founder team. The emergence of competitor labs (Anthropic, which was founded in 2021 by Dario Amodei after leaving OpenAI, SSI by Sutskever in 2024, and Thinking Machines by Murati in 2024) means some of the talent that pioneered OpenAI’s breakthroughs is now working elsewhere on similar goals, potentially in ways more aligned with the original OpenAI mission than OpenAI’s later commercial incarnation. OpenAI has undoubtedly been strengthened in deployment engineering and scale by new talent and funding, but the loss of “the idealists” has permanently affected the company’s trajectory and AI safety attitude towards AGI.
Structure Changes
OpenAI’s organizational structure has undergone several transformations: from a non‑profit to a capped‑profit hybrid, and now toward an even more commercially driven model. Originally, OpenAI was a 501(c)(3) non‑profit entity. The rationale was to free the company from profit incentives so it could focus purely on the societal good. Early governance was straightforward — a board of directors (composed of scientists and donors) oversaw the institute, and day‑to‑day decisions were made by the research leadership. By 2019, after recognizing the funding imperative, OpenAI created the for‑profit subsidiary OpenAI LP with the unique capped‑profit model.
The non‑profit (OpenAI Inc.) remained as the controlling shareholder of the LP, and its board had ultimate control to ensure mission adherence. Investors and employees could hold equity in the LP, but with a capped return. This structure was novel, an attempt to marry the need for billions in capital with a mission‑driven backbone. In practice, it meant that by 2020–2021, OpenAI was operating much like a startup (with venture capital expectations) but still had an unusual oversight mechanism. This duality showed during the 2023 Altman ousting. The non‑profit board (with no equity, focused on mission) could fire the CEO of the company, a scenario that wouldn’t happen in a normal startup or public company. Many saw this governance experiment as problematic when the crisis hit, because the board didn’t include representatives of major stakeholders like Microsoft or the employees, creating a disconnect.
In early 2024, after Altman’s reinstatement, OpenAI immediately took steps to adjust its governance. It added board members with more industry experience. More radically, OpenAI started exploring abandoning the non‑profit control entirely. By late 2024, it became public that OpenAI had agreed (as part of a new funding round) to transition into a traditional for‑profit structure within two years. This likely means dissolving or minimizing the role of the non‑profit OpenAI Inc., and having a normal corporate board for OpenAI Global (potentially a public‑benefit corporation or even a standard C‑corp).
Sam Altman himself noted that raising capital as a nonprofit was impossible, and even the capped‑profit model, while well‑intentioned, was cumbersome when OpenAI needed to move quickly. Another structural shift was internal. OpenAI started to split into more product‑focused teams (for ChatGPT, for the API, for enterprise services), akin to a mature tech firm. The non‑profit still technically exists and engages in some activities (like funding AI safety research outside OpenAI and computing educational initiatives), but its direct control over the technology will diminish. In essence, OpenAI’s structure is converging with the tech industry norm with heavy investor influence, profit‑driven metrics, and conventional corporate governance, a far cry from the niche research lab in 2015.
This evolution has been controversial. OpenAI itself contends that its core mission is unchanged, and it still prioritizes safety alongside an organizational form that best accelerates its work. The coming years (2025 and beyond) will likely see OpenAI as a fully commercial entity, possibly even considering an IPO at up to a $1 trillion valuation according to an October 2025 report, yet one that is tasked (perhaps by its charter or internal policies) with keeping long‑term AGI safety as a priority. It’s an open question how well the mission can be preserved under a more profit‑oriented structure.
Product Evolution
Early AGI Experiments
In its quest for AGI, OpenAI carried out a number of early experiments and projects that were designed to test the waters of general intelligence and advance the state of the art. One of the first initiatives released was OpenAI Gym in 2016, a toolkit for reinforcement learning researchers. Gym provided a common set of environments (like games and tasks) where algorithms could be evaluated, fostering progress in RL. Gym’s creation stemmed from OpenAI’s philosophy of measuring progress, as the team wanted to easily track how a single algorithm might perform across many tasks as a proxy for generality.
In the same year as Gym, OpenAI released Universe, a platform aimed at training an AI agent across a wide range of games and websites by controlling a VNC interface. Universe was arguably an early attempt at a general-purpose agent. The goal was to have one AI learn to navigate many different virtual environments (from playing Flash games to completing web tasks) to move toward general intelligence.
In practice, Universe proved very challenging; the agents of that time (based on deep reinforcement learning) struggled to transfer skills between tasks, and the project did not yield a breakthrough result. It was eventually deprioritized as research focus shifted. OpenAI recognized that unsupervised pre-training (as would be done later with large language models) or more powerful model architectures might be needed for an agent to truly generalize.
OpenAI Five
Another important early project was OpenAI Five, the Dota 2 game-playing AI. OpenAI Five was a team of neural network agents trained via reinforcement learning to play the complex strategy game Dota 2 at a high level. In contrast to solving games such as Chess or Go, OpenAI Five aimed to test AI agents in a virtual environment that would simulate the “messiness and continuous nature of the real world.”
This project, which ran through 2017–2019, was a significant benchmark for multi-agent cooperation and long-horizon planning in AI. In June 2018, OpenAI Five managed to beat semi-professional teams, and by April 2019, it defeated the reigning world champion team in two exhibition matches. As Dota 2 is an open-ended game with a very large action space and imperfect information (fog of war), achieving superhuman performance indicated how far scaling and self-play in RL could go.
OpenAI Five was trained on tens of thousands of years’ worth of game play via parallel simulations and self-play reinforcement learning, where the AI improves by competing against past versions of itself. This victory showed that, at least in games, AI could achieve very general strategies and teamwork. However, such mastery was still narrow. OpenAI Five knew Dota 2 deeply, but could do nothing else. It didn’t directly get OpenAI closer to generalized AI, but OpenAI Five served as proof that with massive compute and reinforcement learning, neural networks could scale to superhuman capabilities.
Robotics
OpenAI also ventured into robotics as an early path to AGI, with the logic that an embodied agent learning in the physical world could be one way to achieve general understanding. OpenAI hosted its first OpenAI Robotics Symposium on April 27, 2019, where the company posited that reinforcement learning in simulation, using techniques such as domain randomization and memory‐augmented architectures, could enable robust “sim2real” transfer and direct physical training.
One of OpenAI’s technical goals (Goal 2) in June 2016 was to build a household robot that could perform basic chores. While a full robot butler wasn’t feasible at the time, OpenAI did significant work on robotic manipulation. Notably, in October 2019, OpenAI developed a human-like robot hand that could solve a Rubik’s Cube puzzle. This involved training neural networks in simulation (pairing the same reinforcement learning code from OpenAI Five with a technique called domain randomization to generalize to the real world) and then deploying them on a physical robotic hand.
The robot hand could manipulate the cube and solve it, a feat requiring dexterity and feedback, one of the most impressive robotic manipulation results at the time. However, the robot hand showed the same problems as OpenAI Five. Not only was the use case of the hand specialized and narrow, but robotics progress and feedback cycles were notoriously slow and hardware-constrained. It also foreshadowed a theme. Though many believed that reinforcement learning plus scale could eventually handle real-world tasks, in practice, OpenAI found language to be a more tractable domain for generality than pure gameplay or robotics.
Product
The Rise of Transformer Architectures
Supervised Natural Language Processing
Natural Language Processing (NLP) is a subfield of artificial intelligence centered around enabling computers to understand, interpret, generate, and respond to human languages.
Up until 2017, NLP methods relied on supervised learning, which is a type of machine learning where a model is trained on labeled data to accurately map inputs to the correct outputs. Supervised methods require extensive manual annotation of large datasets to create enough labeled examples to guide the neural network training for specific tasks such as text classification, sentiment analysis, and entity recognition.
While effective, supervised learning encountered significant limitations. For one, model performance was heavily dependent on extensively labeled data. Supervised NLP models required large, high-quality annotated datasets, limiting applicability to only domains or languages where such annotations were feasible. For instance, in 2016, Google released its Neural Machine Translation (GNMT) model, which consisted of 100 million bilingual sentence translations between pairs of languages. To train GNMT, Google had to collect data from translated news articles, government documents, and publicly available bilingual texts.
Supervised NLP models also typically performed well only within their narrowly defined training task. They struggled to generalize across multiple tasks or datasets. In 2013, Stanford’s Sentiment Treebank (SST) model achieved nearly 85% accuracy in classifying sentences from movie reviews into positive or negative sentiment. However, when researchers applied SST to other sentiment tasks, such as classifying sentiment from Twitter posts or product reviews, it experienced substantial reductions in accuracy. Moreover, the SST model lacked the general linguistic understanding for broader NLP tasks such as named entity recognition or question answering.
Finally, annotating data at scale was prohibitively expensive and time-consuming. For instance, annotation rates for labeling road signs cost up to $1.00 per pounding box, while medical image annotation can cost up to $5.00. This created significant cost and scalability problems that hindered the development of broader and more versatile NLP models.
Recurrent Neural Networks
Recurrent Neural Networks (RNNs), including their variants such as LSTMs and GRUs, were another prominent approach towards NLP modeling. RNNs are a class of neural networks designed specifically for sequential data, such as language, time series, and audio signals. RNNs maintain an internal state or “memory” to keep track of previous inputs, which allows them to identify dependencies and context within sequences and predict things like the next probable word in a sentence.
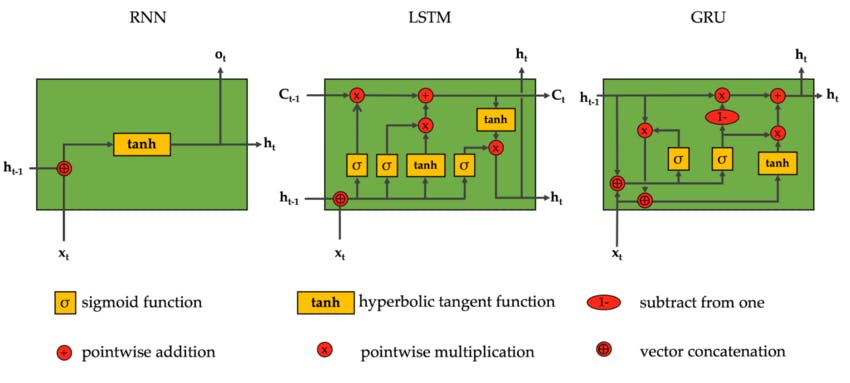
Source: Hassaan Idrees
Although RNNs became a standard tool for NLP tasks due to their sequential modeling capabilities, they also faced significant drawbacks. RNNs experienced vanishing and exploding gradients, where an RNN’s memory would forget context placed earlier in a sequence, like the start of a paragraph, as it processed longer sequences. In a 2016 paper quantifying the effects of vanishing gradients in RNNs, researchers Phong Le and Willem Zuidema discovered that for sequences longer than 10 tokens, their RNN’s accuracy dropped to levels comparable with random guessing.
Vanishing and exploding gradients made training difficult over long sequences and restricted model performance on complex language tasks. Moreover, the RNN’s sequential nature limited the ability to parallelize RNN training workflows, which reduced its computational efficiency and scalability.
In 2014, Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio attempted to solve the vanishing gradient problem in their paper, “Neural Machine Translation by Jointly Learning to Align and Translate.” Bahdanau et. al introduced the attention mechanism, which is a technique that allows models to selectively focus on parts of input data when producing a predictive output. Attention mechanisms assign different weights, signaling importance, to input elements, allowing models to dynamically emphasize critical information and ignore less important details in a sequence.
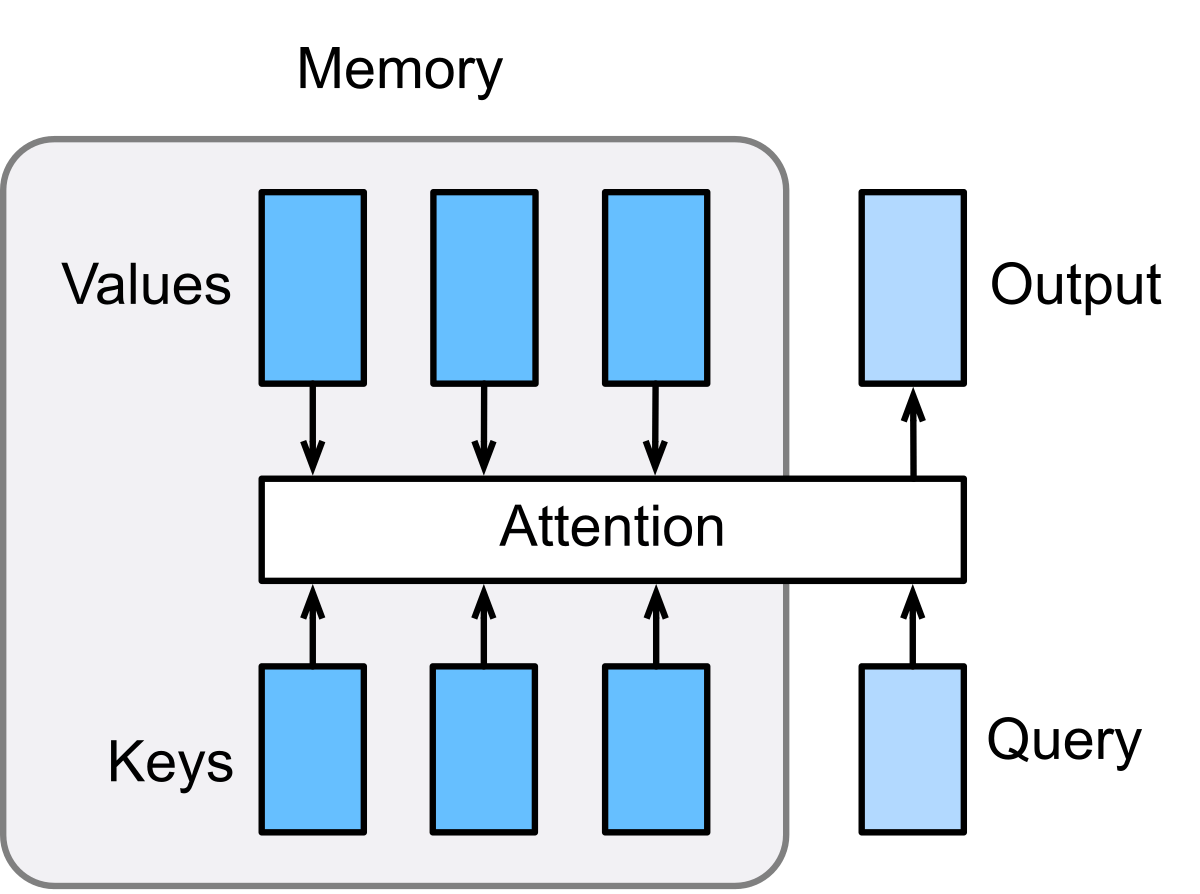
Source: Wikipedia
In 2017, Vaswani et. al introduced the transformer architecture in the paper “Attention is All You Need,” which replaced recurrence entirely with attention mechanisms. Unlike RNNs, which process sequences step-by-step, transformers analyze all words in a sequence simultaneously, allowing them to capture content across lengthy statements. Transformers eventually replaced RNNs because their parallel approach allowed for faster training through parallelization, better context retention, and more accurate language understanding.
Transformers
The transformer architecture is central to the development of large language models. Introduced in the seminal paper "Attention Is All You Need" by Vaswani et al. in June 2017, transformers replaced traditional recurrent neural networks (RNNs) and convolutional neural networks (CNNs) as the dominant paradigm for NLP tasks.
Transformers underpin powerful language models such as OpenAI’s GPTs, enabling them to achieve unprecedented performance in language understanding and generation.
The central innovation of transformers is the self-attention mechanism, which allows a language model to relate words within a sentence regardless of their distance from each other. For instance, when humans read, their understanding of each word is informed by the context of the surrounding words. Similarly, self-attention helps each word contextualize other words, dynamically assigning importance to different parts of the input text.
Leveraging self-attention, a transformer takes a sentence or text sequence and processes it as a whole, rather than word-by-word. Previous approaches, like recurrent neural networks (RNNs), read sentences sequentially, leading to slower performance and difficulty capturing long-range context. In contrast, transformers analyze the entire sequence simultaneously, resulting in both improved efficiency and a deeper understanding of contextual relationships within language.
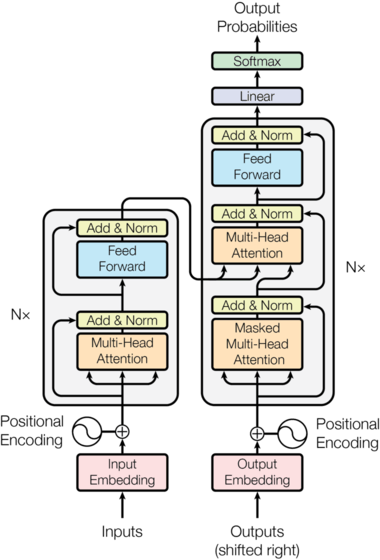
Source: Transformers Are All You Need
The transformer model has two core parts: the encoder and the decoder. The encoder processes input text and builds vector representations to encode its meaning. The decoder generates text output, which could be a translation, summary, or response. The encoder and decoder are both composed of multiple layers that each contain specialized components such as embedding layers, positional encoding, self-attention mechanisms, and feed-forward neural networks.
The first step in transformer processing involves converting words into numerical representations called embeddings. Embeddings translate words into multidimensional numeric vectors, placing words with similar meanings near each other within this numeric space. To preserve the order of words, which is crucial because transformers process text simultaneously rather than sequentially, a positional encoding is added to each word embedding. Positional encoding tags each word with information about its position, ensuring the transformer maintains awareness of the order and structure of sentences.
The core of the transformer is the self-attention mechanism. Self-attention allows the model to weigh the importance of each word in relation to every other word within the sentence. To accomplish this, each word’s numeric embedding is transformed into three different sets of numbers called query, key, and value. The query represents the focus of the embedding, the key indicates what information or context it has, and the value represents the actual information the sequence possesses. These help the transformer determine the importance of connections between words, establishing which words should "pay attention" to each other to capture meaning precisely.
After self-attention refines the contextual relationships between words, the model uses feed-forward neural networks to further process and clarify the meaning of each word individually. Feed-forward neural networks take each word’s context-enriched representation independently and refine its meaning by applying learned transformations to it.
The decoder in the transformer model generates its output. It first uses self-attention to maintain coherence among previously generated words, then employs a special form of attention, encoder-decoder attention, to connect each new output word to the most relevant input words provided by the encoder.
Together, these components—embedding layers, positional encoding, self-attention mechanisms, feed-forward networks, and encoder-decoder attention—allow transformers to understand and generate language with high degrees of accuracy.
Generative Pre-trained Transformers (GPTs), developed by OpenAI, rely entirely on the transformer architecture. GPT models differ from the original encoder-decoder transformer architecture used by machine translation tasks by exclusively utilizing decoder blocks.
Transformers are a key enabler for GPTs because their attention mechanisms enable them to overcome the long-range dependency limitations of traditional RNNs. Because transformers process sequences all at once instead of word by word, transformers enable the training of these models to be highly parallelized.
GPT Models
GPT-1: Transformers and Generative Pre-Training
Following Google’s invention of transformers in 2017, OpenAI released its Generative Pre-trained Transformer (GPT-1) model in June 2018. OpenAI introduced the model in the paper “Improving Language Understanding by Generative Pre-Training.” In the paper, OpenAI outlined the use of a transformer architecture, rather than RNNs, to improve the models' ability to capture long-range dependencies, addressing the limitations found in earlier sequential models.
Architecturally, GPT-1 was a 12-layer, 12-headed transformer decoder-only network that utilized masked self-attention. The model generated text by processing long-form text sequentially. Each token input only attended to preceding tokens, making the model’s approach unidirectional and autoregressive. Each of GPT-1’s model heads had 64-dimensional head states, and the model had 117 million parameters in total, which was a substantial size at the time. GPT-1’s decoder-only architecture simplified the pre-training phase, emphasizing next-word prediction tasks, making it especially well-suited for text generation.
GPT-1’s training involved two phases. It started with unsupervised generative pre-training on the BookCorpus dataset. The BookCorpus dataset was a 4.5 GB dataset consisting of approximately 7K unpublished fiction books. OpenAI chose to train on this large unlabeled dataset to allow GPT-1 to internalize general language patterns as it learned to predict subsequent words in a sequence. The training process demanded 1 petaFLOP of computation per day, ran over eight Nvidia P600 GPUs, and ran for 30 days.
After the pre-training phase, GPT-1 underwent a discriminative fine-tuning process. It was fine-tuned specifically for supervised tasks, such as question answering, semantic similarity assessments, and textual entailment challenges. The fine-tuning was targeted at adapting the language model parameters to perform effectively on specific NLP benchmarks.
GPT-1 achieved state-of-the-art (SOTA) or near-SOTA performance across many NLP evaluations. For instance, GPT-1 achieved a GLUE benchmark score of 72.8, beating the previous best score of 68.9. GPT-1 also beat existing benchmark records in question answering and commonsense reasoning capabilities by 5 to 8%.
GPT-1’s success was groundbreaking in NLP approaches. Before GPT-1, NLP typically involved training separate, task-specific models. GPT-1 demonstrated the potential for a single, general-purpose generative model to be fine-tuned across various specialized tasks. This approach laid critical groundwork for future, more advanced GPT iterations.
GPT-1’s approach of fine-tuning a generatively pre-trained model trained from a large unlabeled dataset emphasized the potential of large-scale unsupervised pre-training instead of supervised NLP training. The language model underscored the viability of transfer learning, indicating that comprehensive general-language understanding gained through unsupervised learning could effectively transfer across diverse language tasks with minimal architectural changes.
Nevertheless, GPT-1 still had limitations. GPT-1 did not strongly demonstrate zero-shot generalization capabilities. Its relatively small size necessitated fine-tuning for robust downstream task performance.
Despite these constraints, GPT-1's architectural and training principles — decoder-only transformers, next-word prediction objectives, and the two-step training method — provided foundational elements that propelled later advancements in OpenAI’s GPT product series.
The success of GPT-1 was a watershed moment internally. OpenAI realized that the transformer architecture, combined with unsupervised pre-training on large text corpora, was a powerful approach that could be scaled up to yield even more intelligence. GPT-1’s performance on downstream tasks (like question answering or text classification after fine-tuning) outstripped what earlier recurrent models could do with similar data. It also demonstrated an ability to generalize knowledge, GPT-1, despite its small size by later standards, learned a wide range of facts and language patterns from books. This sparked the insight that feeding more data and compute could make these models qualitatively better.
Researchers like Ilya Sutskever and Dario Amodei began to discuss scaling laws, the notion that as model parameters, training data, and compute increase, the performance on diverse tasks follows predictable improvements (this was later formalized in a 2020 paper by OpenAI on scaling laws).
Consequently, OpenAI’s strategy shifted to a scaling maximalist approach. The company fast-tracked the development of GPT-2 (released in Feb 2019), which had 1.5 billion parameters, more than 10x GPT-1’s size, and was trained on a far larger dataset of 8 million web pages (WebText). GPT-2 showed emergent capabilities: it could generate entire paragraphs of coherent text on prompts and exhibit rudimentary reasoning or world knowledge that no model before it had. This seemed to serve as an early vindication of the scaling hypothesis.
The training for both GPT-1 models also indicated the need for massive compute resources. Training GPT-2 and later GPT-3 required far more GPUs and a well-engineered infrastructure. This practical constraint (cloud computing and GPUs) was the main reason behind OpenAI’s 2019 partnership with Microsoft.
From GPT-1 onward, OpenAI staked its bet on scaling being the primary driver of AGI. Altman and others publicly stated that they believed future more-general AI systems would be giant neural networks trained on nearly all available data. Thus, securing funding for compute, researching more efficient training techniques (to maximize what they could do with given hardware), and gathering or generating large datasets became OpenAI’s main priorities.
GPT-2: Scaling Unsupervised Training
In 2019, OpenAI introduced GPT-2, succeeding GPT-1 and scaling up the model’s complexity and quantity of training data. GPT-2 had 1.5 billion model parameters and was trained on 40 GB of internet text, a more than 10x increase compared to GPT-1’s 117 million parameter count and 4.5 GB training set. GPT-2’s training corpus was a dataset called WebText, which contained approximately 8 million web pages scraped from Reddit links with high karma scores.
Architecturally, GPT-2 featured a 48-layer transformer decoder, quadrupling GPT-1’s 12-layer depth. Its hidden size expanded to 1.6K dimensions, and vocabulary increased to 50.3K token types through byte-pair encoding (BPE), allowing GPT-2 to represent text more flexibly.
GPT-2 also introduced several new ML engineering techniques, such as applying layer normalization at the input of each sub-block and an additional layer normalization after the final self-attention block, enabling stable training of deeper networks. GPT-2 implemented residual connection weight initialization to scale contributions down proportionally to the number of layers, avoiding divergence during deep model training. Another notable advancement was doubling GPT-2’s context window length to over 1K tokens, significantly enhancing its capability to manage long-range dependencies and generate coherent long-form text.
GPT-2 demonstrated unsupervised multitask learning capabilities. Even without fine-tuning, GPT-2 displayed proficiency in tasks like reading comprehension, translation, summarization, and question-answering through simple prompting techniques. For instance, prompting GPT-2 with question-answer formats often yielded plausible, coherent answers, revealing that the model implicitly acquired task-specific knowledge through general language modeling. GPT-2 set state-of-the-art records on seven of eight language modeling benchmarks of its time, emphasizing the improvements increased scale could yield in language models.
GPT-2’s release also sparked significant ethical discussions. OpenAI initially withheld the full 1.5 billion parameter model, citing concerns about potential misuse for automated disinformation or spam. It instead adopted a staged release strategy, progressively releasing smaller models (124 million, 355 million, and 774 million) while collaborating with researchers to understand potential risks. By November 2019, reassured by the absence of widespread abuse and observing independent replications, OpenAI eventually made the full GPT-2 publicly available.
This staged release underscored a critical ethical challenge in AI: balancing openness in research with responsible deployment of powerful technologies. GPT-2 was pivotal, highlighting both the enormous promise of large-scale language models and the pressing need for ethical governance.
GPT-2 demonstrated that increasing model scale and training data qualitatively enhances model capabilities, laying the critical groundwork for future innovations such as GPT-3, where OpenAI further expanded model size by two orders of magnitude, continuing to explore and expand the boundaries of artificial intelligence. Concurrently, it highlighted the challenges OpenAI faced in balancing AI product development with safety and ethics concerns.
GPT-3: Massive Scale, Few-Shot Learning, and RLHF
In June 2020, OpenAI introduced GPT-3, dramatically extending the capabilities established by its predecessors, GPT-1 and GPT-2, by scaling model size and training data. GPT-2 had 175 billion model parameters, a more than 100x increase compared to GPT-2’s 1.5 billion parameters. This model size increase was facilitated by increased computational resource demand, notably underscored by OpenAI’s partnership with Microsoft, leveraging a supercomputer with 10K GPUs interconnected through high-speed networking.
GPT-3's architecture was fundamentally similar to GPT-2 as a transformer decoder but larger in scale. It incorporated 96 transformer blocks (attention layers), each with 96 attention heads, and a model dimension of 12.2K. The advancements behind GPT weren’t as driven by new architectural innovations as they were by distributed training techniques to scale existing transformer architectures.
To feed this model, OpenAI assembled a vast training dataset totaling nearly 500 billion tokens. Approximately 60% of the training data originated from a filtered Common Crawl web dataset, complemented by several high-quality sources such as WebText2 (19 billion tokens), internet book collections Books1 and Books2 (combined 67 billion tokens), and English Wikipedia (3 billion tokens).
A significant feature of GPT-3 was its increased context window, extended to 2048 tokens, twice GPT-2's length, allowing GPT-3 to handle and generate substantially longer and more contextually coherent passages. The computational cost was substantial, estimated at roughly $4.6 million.
GPT-3 notably introduced groundbreaking advancements in few-shot and zero-shot learning. Without requiring any gradient updates or explicit task-specific training, GPT-3 demonstrated robust capabilities across diverse tasks merely by utilizing carefully structured prompts. Tasks like language translation, arithmetic reasoning, SAT analogies, and even basic code generation became possible with minimal contextual guidance. This generalization capability underscored the paradigm shift in NLP, showing how immense pre-trained models could implicitly learn various tasks through exposure to vast data alone.
GPT-3’s text generation capabilities reached near-human levels of quality, with outputs such as news articles indistinguishable from human-written texts by evaluators. However, despite its impressive proficiency, GPT-3 revealed notable limitations and challenges. It often "hallucinates," generating plausible-sounding but factually incorrect content. It also inadvertently perpetuated biases and offensive language from its training data, raising significant ethical concerns.
Addressing these issues, OpenAI did not publicly release GPT-3’s weights but instead provided access through an API, governed by usage guidelines and safety filters. To improve GPT-3's alignment with human values and reduce problematic outputs, OpenAI developed a new technique for refining large language models - reinforcement learning from human feedback (RLHF) in January 2022, leading to the creation of InstructGPT.
InstructGPT: RLHF and AI Safety
In January 2022, OpenAI introduced InstructGPT. InstructGPT is a series of models that uses RLHF to improve the alignment of AI outputs with human intentions. InstructGPT was trained with humans in the loop to improve the model’s ability to explicitly follow instructions provided by users, resulting in outputs that were more accurate and less toxic compared to GPT-3.
InstructGPT was trained through three stages. First, human annotators created high-quality responses to a set of prompts, providing a supervised learning baseline that was fed into supervised fine-tuning for GPT-3.5. Then, human evaluators ranked the outputs from the model and created a reward model to predict human-preferred responses. Finally, the GPT-3.5 models were iteratively fine-tuned with the reward models to maximize the predicted human preference, which improved the alignment of the model’s generated content with human intentions.
OpenAI's evaluations demonstrated InstructGPT's significant improvements over GPT-3 across metrics such as truthfulness, toxicity, and appropriateness. Remarkably, even smaller InstructGPT models (e.g., 1.3 billion parameters) were preferred over larger GPT-3 models (175 billion parameters), underscoring the effectiveness of human alignment techniques.
GPT-3.5
In December 2022, OpenAI quietly released GPT-3.5. Built upon the foundations of InstructGPT, GPT-3.5 was designed to generate results that were less problematic and aligned closer to a user’s intent.
OpenAI's GPT-3.5 and InstructGPT represented significant milestones in the ongoing evolution of LLMs. Emerging as substantial refinements of the original GPT-3, these models played a critical role in bridging the gap between foundational capabilities and practical usability. Notably, their development paved the way for subsequent advancements, including the creation and success of GPT-4.
GPT-4: Multimodal GPTs
In March 2023, OpenAI announced GPT-4. Unlike its predecessors, GPT-2 and GPT-3, GPT-4 was described as a "large multimodal model," accepting both image and text inputs and outputting text outputs. Notably, OpenAI opted not to disclose the exact architectural details or parameter counts of GPT-4, citing competitive and safety concerns, a departure from the transparency of earlier model releases. External sources, such as Semafor, speculate that GPT-4 could have approximately one trillion parameters, potentially achieved using techniques like Mixture-of-Experts (MoE).
GPT-4’s architecture retained the fundamental transformer design but introduced significant advancements, most notably multimodal capabilities. For the first time, GPTs could accept and interpret image inputs alongside text. This feature, initially demonstrated in partnership with services like Be My Eyes, allowed GPT-4 to describe images, interpret visual humor, or analyze diagrams effectively.
Another critical enhancement in GPT-4 is the extended context window. GPT-4 had two variants: one with an 8.2K-token context window, and another specialized version with 32.8K tokens - eight times greater than GPT-3’s 4.1K-token limit. This extended context significantly enhances GPT-4's ability to handle lengthy inputs, facilitating the analysis of extended documents, sustained dialogues, or complex tasks like interpreting legal documents or technical reports.
GPT-4 also demonstrated superior reasoning capabilities compared to earlier models. Its performance on benchmarks highlights dramatic improvements: on the Uniform Bar Exam, GPT-4 scored around the top 10% of human test-takers, whereas GPT-3.5 scored near the bottom 10%. Similarly, GPT-4 significantly outperformed its predecessors on the Massive Multitask Language Understanding (MMLU) benchmark, achieving strong performance even in languages beyond English.
The advancements in GPT-4’s reasoning and safety features were further supported by extensive fine-tuning through RLHF. OpenAI reported that GPT-4 exhibits significantly fewer hallucinations and harmful outputs compared to GPT-3.5, refusing prohibited requests 82% more often and reducing factual inaccuracies by approximately 60%. This improved alignment stems from an extensive safety evaluation and adversarial testing process, combined with new features such as the system message, allowing developers to guide the AI’s behavior explicitly at the start of interactions.
GPT-4o: Expanding Multimodal Capabilities
In May 2024, OpenAI introduced GPT-4o, which combined multimodal capabilities in text, image, and voice. This model could process and generate these modalities, creating an interactive, intuitive AI capable of engaging in real-time conversations, translating speech seamlessly, and generating photorealistic images directly from text prompts.
GPT-4o was designed for global use, demonstrating mastery over 50 languages and significantly improving multilingual interactions. Additionally, it offered a massive 128K-token context window, enabling the model to handle extensive inputs such as complete documents or lengthy conversations without loss of context.
Safety and ethical challenges escalated with GPT-4o’s advanced capabilities, notably around image generation and voice synthesis, prompting OpenAI to implement stringent content moderation protocols and ethical guidelines. These measures were vital in preventing misuse, such as deepfake generation or voice cloning.
GPT-4.5: Scaling Unsupervised Training
In February 2025, OpenAI released GPT-4.5, designed to further enhance GPT-4’s capabilities. With a heavy focus on reliability, GPT-4.5 aimed to substantially reduce hallucinations and factual inaccuracies.
One notable aspect of GPT-4.5 was its enhanced conversational style. Trained specifically to be more emotionally intelligent and engaging, GPT-4.5 provided responses that were warmer and more personable, significantly improving interactions and user satisfaction.
At this point, OpenAI identified two paradigms for advancing capabilities: scaling unsupervised learning and scaling reasoning. Unsupervised learning involves scaling up the amount of data and computing to improve model performance. GPT-3.5, GPT-4, and GPT-4.5 follow this paradigm. The alternative paradigm is scaling reasoning, which teaches models to think and produce a chain of thought before they respond, allowing them to handle more complicated logic problems. GPT-4.5 is an example of using additional computing and data, along with architecture innovations, to scale unsupervised learning.
However, the scale and computational demands of GPT-4.5 meant limited initial accessibility, restricted primarily to premium and research subscribers. The model also sparked discussions around diminishing returns, with some critics arguing that GPT-4.5 offered incremental improvements at substantial computational costs.
GPT 5: One Unified System
In August 2025, OpenAI announced GPT-5. Compared to the GPT-4 family of models, GPT-5 is a unified system, meaning the model unifies multiple paradigms — such as reasoning, agents, and multimodal capabilities — into a single system. The model became the default for ChatGPT users, replacing GPT-4o, OpenAI o3, and GPT-4.5.
GPT-5's most notable innovation was its integrated reasoning capability. Rather than requiring users to select between different models for different tasks, GPT-5 incorporated a real-time router that could automatically determine when to engage in deeper reasoning before responding. This resolved a major user pain point that caused confusion and complications when deciding what model to choose from.
The reasoning model, GPT-5-thinking, is more efficient and smarter than its predecessor, o3. When reasoning, GPT-5 used 50-80% fewer output tokens compared to OpenAI o3 while achieving better performance across capabilities, including visual reasoning, agentic coding, and graduate-level scientific problem solving. The model demonstrated improvements across benchmarks, particularly in domains requiring technical expertise. GPT-5 achieved 94.6% on AIME 2025 without tools, 74.9% on SWE-bench Verified for real-world coding, 84.2% on MMMU for multimodal understanding, and 46.2% on HealthBench Hard.
A critical focus for GPT-5 was reliability and honesty. With web search enabled, GPT-5's responses were approximately 45% less likely to contain factual errors than GPT-4o, and when thinking, approximately 80% less likely to contain factual errors than OpenAI o3. OpenAI particularly invested in making the model recognize its limitations. GPT-5 was trained to recognize when tasks couldn't be completed, avoid speculation, and explain its limitations more clearly. In tests where images were removed from multimodal prompts, GPT-5 gave confident answers about non-existent images only 9% of the time, compared to 86.7% for OpenAI o3.
OpenAI also released GPT-5 Pro for its power users. This variant used scaled but efficient parallel test-time compute to think for longer periods, achieving state-of-the-art performance on challenging benchmarks like GPQA. In evaluations on over 1K economically valuable, real-world reasoning prompts, external experts preferred GPT-5 Pro over standard GPT-5 67.8% of the time, with GPT-5 Pro making 22% fewer major errors and excelling particularly in health, science, mathematics, and coding.
GPT-5.1
In November 2025, OpenAI released two new models, GPT-5.1 Instant and GPT-5.1 Thinking. The two new models iterated on the GPT-5 model by making ChatGPT both more intelligent and more conversational. Specifically, GPT-5.1 Instant introduces adaptive reasoning capabilities for the first time, being warmer by default and more playful while remaining clear and useful. GPT-5.1 Thinking can adapt its thinking time more precisely to each question.
In practice, on a representative distribution of ChatGPT tasks, GPT-5.1 Thinking is roughly twice as fast on the fastest tasks and twice as slow on the slowest tasks, demonstrating dynamic resource allocation based on problem complexity. The release of these two new models represented a shift in how OpenAI’s models allocate computational resources.
ChatGPT
ChatGPT is an interactive chatbot that uses large language models to respond to user input. ChatGPT understands text, images, and audio received from users and engages in dialogue, answers questions, and follows instructions to generate text or images. ChatGPT can retain memory and remember context from previous messages, adjusting its responses throughout multiple conversation threads. Its conversational design allows users to ask follow-up questions, request clarifications, and provide corrections to prompt ChatGPT to adapt its answers. ChatGPT is available on both web browsers and through its mobile application.
ChatGPT is built on OpenAI’s GPT family of models. While users were previously required to choose which language model they wanted to interact with, the release of GPT-5 removed this need and combined multimodal capabilities, reasoning, agents, and advanced mathematical capabilities into a single system. As of October 2025, users could choose between “Auto, Instant, Thinking, and Thinking-mini” modes for GPT-5 via ChatGPT.
Released in September 2025, Pulse in ChatGPT is a proactive research feature that delivers personalized daily updates based on chat history, feedback, and connected apps like a calendar. Available to Pro users on mobile as of October 2025, it conducts asynchronous research overnight and presents information as visual cards you can quickly scan. Rather than waiting for the user to ask questions, Pulse anticipates what they need and brings relevant updates to them each morning.
Also released in the same month, Instant Checkout allows US ChatGPT users to buy products directly within conversations, starting with Etsy sellers and expanding to over a million Shopify merchants. It's powered by the Agentic Commerce Protocol, an open standard co-developed with Stripe. For instance, when a user asks shopping questions like "best running shoes under $100," ChatGPT shows relevant products, and for items with Instant Checkout enabled, they can complete purchases using Apple Pay, Google Pay, Link, or credit cards. Essentially, ChatGPT acts as an intermediary while merchants handle the payment processing, fulfillment, and customer relationships using their existing systems.
In October 2025, OpenAI also launched Apps in ChatGPT — interactive third-party applications that users can chat directly with inside the ChatGPT interface. It lets users summon apps by name or have ChatGPT suggest them when relevant to the conversation. Initial partner apps included Spotify, Zillow, Booking.com, Expedia, Canva, Coursera, and Figma, with more coming later in 2025. Apps built with OpenAI’s Apps SDK can trigger actions and display an interactive interface directly in chat responses. For example, users can ask "Spotify, make a playlist for my party this Friday" and the music app appears right in the conversation, or type "Zillow, show me homes for sale in Pittsburgh" to browse an interactive map with listings, all without leaving ChatGPT.
ChatGPT users can further personalize their experience by creating custom GPTs that allow them to configure special instructions, extra domain knowledge, and model abilities to create versions of ChatGPT tailored specifically for a certain purpose. Users can either create GPTs on their own or find one through the GPT store. Additionally, connectors are integrations that let ChatGPT securely connect to third-party applications like Gmail, Google Calendar, Google Drive, Dropbox, and Microsoft SharePoint. Once connected, ChatGPT can search files, pull data, and reference content directly in conversations.
In November 2022, OpenAI launched ChatGPT as a research preview after fine-tuning GPT-3.5 with RLHF to create an interactive assistant that could follow instructions while filtering for harmful and untruthful content. Through the process of adjusting model behavior based on feedback from human reviewers, ChatGPT was trained to more accurately follow human instructions, refuse certain types of inappropriate requests, and moderate its tone in response.
GPT Reasoning

Source: OpenAI
OpenAI’s o-series is a line of LLMs focused on complex reasoning tasks like science and programming by spending time “thinking” before answering prompts. Unlike the GPT series of models that respond quickly with fluent answers, the o-series models internally deliberate using a hidden chain-of-thought to process questions step by step. OpenAI’s reasoning models include o1, o1-mini, o1-pro, o3, o3-mini, and o4-mini. GPT-5, which was released in August 2025, was a unified system that included reasoning capabilities.
All of the o-series models share the same architectural philosophy: they “think” and step through problems internally before producing a final answer. Each model generates a multi-step chain of thought abstracted away from the users. The o-series models are trained to refine their thinking process, recognize mistakes, break down complex tasks, and alternate between new strategies when stuck.
OpenAI’s o-series models could also use external tools to solve problems. For instance, o3 was trained to determine if it needed to search the web or execute python code during a session and autonomously facilitates the action if so. This made the models more agentic than their GPT predecessors because they’re not only capable of producing text but also actively retrieving data and initiating actions outside of the OpenAI platform.
OpenAI’s reasoning models were built on top of the transformer architecture, and they were trained to focus on reasoning through RLHF. After the base model is pre-trained on text, OpenAI trains the model to reason through problems by fine-tuning the model’s process of reaching an answer and not just the answer itself. Through repeated iterations of training and feedback, the o-series models learned to produce useful intermediate steps that lead to more correct solutions. Just as scaling up unsupervised pre-training improved performance for GPT models, OpenAI found that scaling up train-time computation to increase the number of RLHF training iterations improved reasoning model performance.
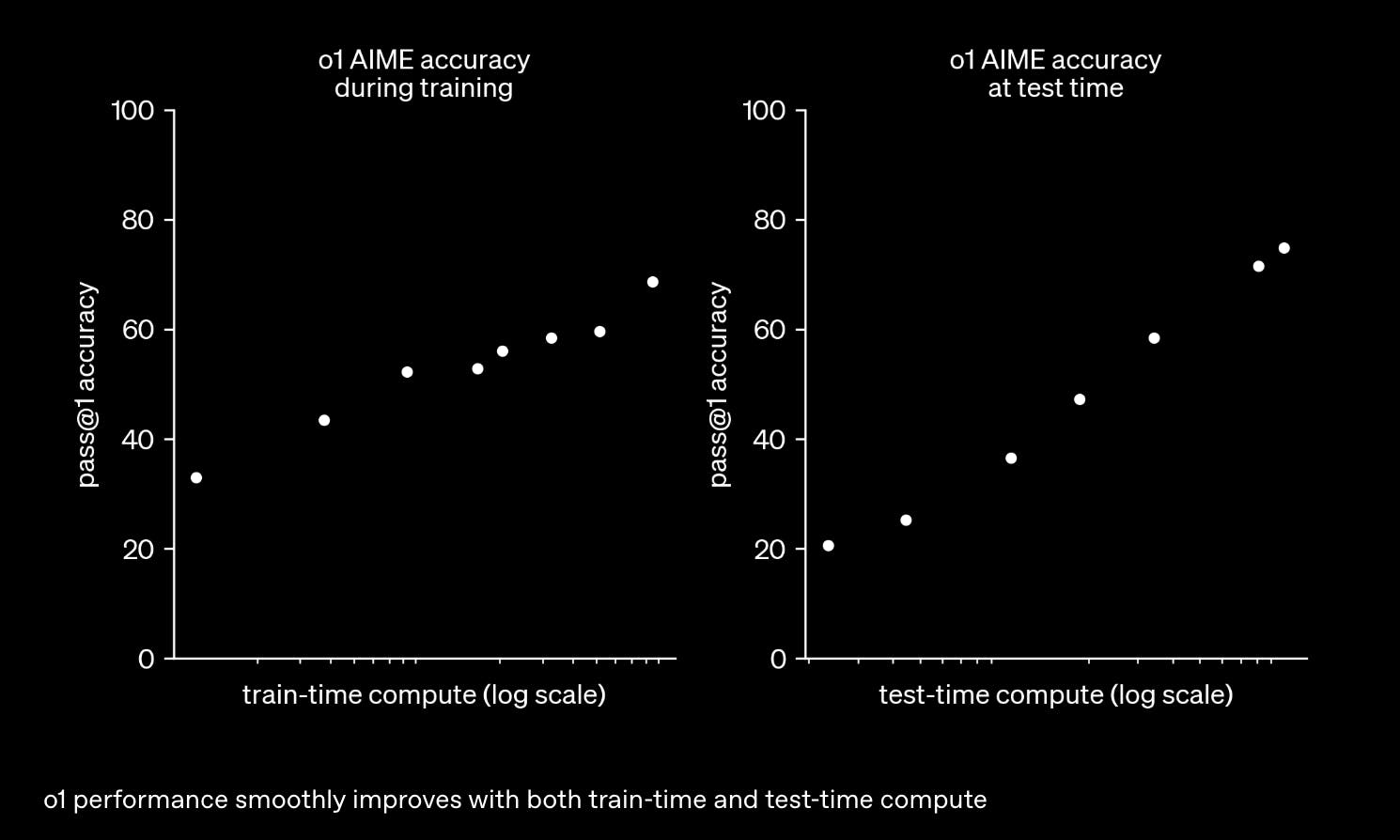
Source: OpenAI
In comparison to earlier models, the o-series’ algorithmic novelty stemmed from their RLHF-driven chain-of-thought and decision-making process. Previous GPT models largely relied on prompting strategies to coax multi-step reasoning, but didn’t have an internal mechanism to reliably plan multiple steps on their own.
In September 2024, OpenAI introduced OpenAI o1 as a research preview alongside o1-mini. At the time of its release, OpenAI o1 ranked in the 89th percentile on competitive programming questions, performed as well as a top 500 student in the USA Math Olympiad qualifier, and surpassed PhD-level accuracy in physics, biology, and chemistry problems on the GPQA benchmark. O1-mini is a smaller, faster, and more cost-effective variant of o1. It delivers similar reasoning performance at close to 80% lower cost than o1-preview.
In January 2025, OpenAI introduced OpenAI o3-mini as an alternative to o1 for technical domains where use cases required precision and speed. In February 2025, OpenAI released ChatGPT Deep Research, a special agent for intensive knowledge work. Deep Research uses a version of the o3 model to manage long-running research queries that involve browsing multiple sources and analyzing data. Deep Research allows users to submit a research question and upload optional file attachments, collects sources across the web, and aggregates research material into a detailed, citation-rich report within 5-30 minutes.
In April 2025, OpenAI introduced OpenAI o3 and o4-mini as the successors to OpenAI o1. Upon release, OpenAI o3 set new state-of-the-art results on benchmarks like Codeforces programming challenges (91.6% accuracy), SWE-Bench (69.1% accuracy), and GPQA PhD-level science questions (83.4% accuracy). o3 made 20% fewer significant errors than OpenAI o1 on real-world tasks in domains such as programming, consulting, and ideation, and was 3x more accurate than o1 on certain logical reasoning tests. OpenAI o3 was also trained for tool use and deployed with the full ChatGPT plugin integration, allowing it to initiate agentic actions like web browsing or code execution.
In August 2025, GPT-5 Thinking was released not as a standalone reasoning model, but as GPT-5 with a reasoning component built into the GPT-5 unified system. According to OpenAI, GPT-5 with thinking performed better than o3 while using 50-80% fewer output tokens across capabilities, including visual reasoning, agentic coding, and graduate-level scientific problem solving. On real-world coding tasks (SWE-bench Verified), GPT-5 used 22% fewer output tokens and made 45% fewer tool calls than o3.
More significantly, when using web search on production traffic, GPT-5 with thinking was approximately 80% less likely to contain factual errors than o3, and produced about six times fewer hallucinations on complex, open-ended questions. The model also demonstrated improved honesty, with deception rates dropping from 4.8% for o3 to just 2.1% for GPT-5 reasoning responses.
GPT Image (formerly known as DALL-E)
Source: OpenAI
DALL-E is a family of text-to-image models (DALL-E, DALL-E 2, and DALL-E 3) that generate digital images from natural language prompts. DALL-E can generate new images or manipulate and rearrange objects in input images. The models are incorporated into ChatGPT, the OpenAI API, and Microsoft’s Bing/Copilot products. DALL-E includes guardrails such as automatic content filtering and C2PA provenance watermarks to reduce misuse.
DALL-E is offered across several versions and OpenAI products based on user needs. OpenAI hosts a web app that allows users to interact with DALL-E through a simple UI for image generation and editing. For integration into applications, OpenAI offers an API that allows developers to send text prompts and receive generated images. OpenAI also allows ChatGPT Plus and Enterprise subscribers to generate images using DALL-E 3 within the ChatGPT chat dialogue. Moreover, DALL-E is also offered through partnerships with consumer-facing products. For instance, Bing Image Creator is powered by DALL-E, and Microsoft’s Copilot uses DALL-E to generate images to fulfill user requests.
OpenAI released the first version of DALL-E in January 2021 as a research preview. DALL-E is a 12-billion-parameter version of GPT-3 trained on a dataset of text-image pairs to generate images from text captions. Similar to GPT-3, DALL-E’s architecture is built upon an autoregressive decoder-only transformer and employs a discrete variational autoencoder (VAE), which can convert an image to a sequence of tokens and a sequence of tokens back to an image. The discrete VAE enables DALL-E to leverage GPT-3’s text-based architecture to generate images.
In April 2022, OpenAI released DALL-E 2, which leverages a diffusion model architecture instead of an autoregressive transformer. DALL-E 2 is composed of a two-stage “unCLIP” system where a diffusion decoder paints pixels from a CLIP-based image embedding. The first stage is converting a text caption into a CLIP image embedding, and the second stage is using a diffusion model to generate an image conditioned on the embedding.
CLIP is an OpenAI-developed neural network that can learn visual conceptions from natural language supervision. CLIP aligns images and natural-language text in a shared embedding space to create a universal multi-modal encoder that can identify which text matches an image best. DALL-E 2 uses CLIP to filter a larger list of images generated by the network and select the images most closely resembling a user prompt. DALL-E 2 generates more realistic and accurate images than DALL-E with 4x greater resolution. In October 2023, OpenAI announced DALL-E 3. DALL-E 3’s architectural details are not fully disclosed.
GPT Image
GPT Image 1 is OpenAI's advanced multimodal AI model specifically designed for image generation and manipulation, which replaced DALL-E 3 as the default image generator in ChatGPT in March 2025 and was made available via API in April 2025. The model achieved significant early adoption, with over 130 million users creating more than 700 million images in just the first week after launch.
The key architectural difference between the GPT Image and its predecessor, DALL-E, lies in their differing generation methodologies. While DALL-E uses a diffusion model conditioned on CLIP image embeddings, GPT Image 1 uses an autoregressive generation approach that works pixel-by-pixel, giving it greater precision and flexibility. These results are achieved largely because GPT Image 1 was trained on the joint distribution of online images and text, learning not just how images relate to language, but how they relate to each other.
Combined with aggressive post-training, the resulting model demonstrates visual fluency, capable of generating images that are useful, consistent, and context-aware. GPT‑4o’s image generation can follow detailed prompts with attention to detail. GPT‑4o can handle up to 10-20 different objects. The tighter binding of objects to their traits and relations allows for better control.
Sora
Source: Business Insider
Sora is a text-to-video model that can generate video clips or extend short videos based on a user prompt. Sora can take in text prompts, image inputs, or video clips and produce a short video clip that matches the task description. In February 2024, OpenAI released Sora in a research preview. On release, Sora could generate up to one minute of 1920 x 1080 video. Sora can remix user-supplied video, extend clips forward or backward, and keep identities and lighting consistent across multiple shots.
Sora’s video editing platform includes a suite of video editing tools. Sora’s storyboard tool allows users to break a video into segments and provide different prompts or images in each segment to offer precise control over a timeline of multiple scenes. Sora’s remix feature lets users replace or modify specific objects within a generated video. Sora’s platform also enables users to re-cut and extend friends, create seamlessly looping videos, blend multiple clips, and set style presets to apply artistic styles over videos.
Sora is a diffusion transformer and an adaptation of the technology behind DALL-E-3. At its core, a diffusion model predicts progressively cleaner latent video patches with a GPT-style transformer operating over the patches so that the network inherits LLM-like compute scaling laws.

Source: Deven Joshi
Sora’s architecture can be viewed as a combination of language-model scale transformers with diffusion-based image and video generation techniques. Sora’s architecture includes a video latent encoder and decoder that compress raw video frames into a lower-dimensional latent representation. The compressed video can then be divided into small units called spacetime patches, which serve as tokens for the Transformer architecture. Conceptually, each patch might represent a small pixel region of a frame across a few consecutive frames. After a generation, these frames are pushed through a decoder network that converts the patches into a full-resolution video in pixel space. Within Sora, the Transformer takes in a set of noisy latent patches and learns to predict sequentially less-noisy versions of those patches, which results in video generation.
Sora builds upon DALL-E 3’s recaptioning strategy to improve prompt adherence, where an auxiliary video-to-text model generates descriptive captions for videos in the training set to help Sora learn a tighter correspondence between textual descriptions and visual content. Consequently, when users prompt Sora, the model is better at following complex instructions and rendering details described in the prompt. For additional safety, Sora-generated videos include watermarks and C2PA metadata to indicate that the video is AI-generated.
Sora 2
Source: Sora
In September 2025, OpenAI released Sora 2, the second generation of its text-to-video model. Alongside the model release, OpenAI launched a dedicated iOS application with social media features, marking a transition from research preview to consumer product.
At the time of release, OpenAI characterized Sora 2 as potentially the “GPT-3.5 moment for video”, capable of generating Olympic gymnastics routines, backflips on paddleboards that accurately model buoyancy and rigidity dynamics, and triple axels while maintaining realistic physics. Prior video models tend to be overoptimistic, morphing objects and deforming reality to execute text prompts.
For example, if a basketball player misses a shot, earlier models may spontaneously teleport the ball to the hoop. With Sora 2, if a basketball player misses a shot, it will rebound off the backboard. Sora 2 introduced capabilities that have been difficult for prior video models to achieve, including more accurate physics, sharper realism, syncnhronized audio, enhanced steerability, and an expanded stylistic range.
In terms of video quality, even with the original Sora model, users could generate videos up to 1080p resolution, up to 20 seconds long, and in widescreen, vertical, or square aspect ratios. OpenAI introduced new duration options for longer videos with Sora 2, with all users able to generate 15-second videos and Pro users able to generate 25-second videos on the web with a storyboard.
The standalone iOS Sora App is an AI-generated short-form content social media app. The app is designed for low-friction, collaborative creation. Users can make videos from text or a photo, remix content, and share with friends. The app lets users make cameos, which are characters of themselves or friends that they can generate in Sora videos. Setting up a cameo is opt-in and includes video and audio verification so Sora can represent users accurately and prevent misuse. Every video generated with Sora includes both visible and invisible provenance signals. At launch, all outputs carry a visible watermark.
Sora 2 was made available via sora.com, in a new standalone iOS Sora app, and in the future will be available via OpenAI's API. Access started with invite-only iOS users beginning September 30, 2025, with plans to expand.
Market
Some outside commentators have observed that OpenAI seems to be building the everything platform for AI, the foundational layer upon which all AI applications, services, and interactions are built. This platform roadmap may stem from the company’s belief that artificial general intelligence will be a transformative, universal utility.
In practice, OpenAI is positioning its technology to converge all AI consumer and enterprise use-cases on one platform, a scope that is unparalleled outside of the tech hyperscalers. OpenAI’s unprecedented first-mover advantage, ChatGPT’s name recognition, and massive consumer base give the company a powerful distribution moat. However, fulfilling an “AI for everything” mandate will demand maintaining technical leadership and broad utility in the face of intensifying competition and technical complexity.
Structurally, OpenAI’s platform relies heavily on partnerships that could become single points of failure. In particular, Microsoft underpins OpenAI’s infrastructure (Azure cloud computing) and acts as a primary distribution channel (integrating OpenAI models into the Microsoft Suite). This dependence is a double-edged sword. Microsoft’s investment and cloud resources accelerated OpenAI’s rise, but this dependence also creates a strategic weakness. Any misalignment or deterioration in the OpenAI-Microsoft relationship due to pricing disputes, competitive overlap, or regulatory intervention would leave OpenAI vulnerable, potentially cutting off enterprise access and critical compute supply.
More broadly, OpenAI’s rapid growth has invited systemic risks. Regulators are closely scrutinizing AI for privacy, security, and antitrust issues. OpenAI itself faces a growing slate of legal challenges around intellectual property and data usage. Critics argue that OpenAI’s growing influence, buttressed by Microsoft’s market power, concentrates AI capabilities in a few hands, raising concerns about accountability and public oversight. Reputationally, OpenAI must also manage public expectations and trust. Incidents of biased or incorrect AI outputs have sparked debate over the responsible deployment of its technology, and any high-profile failures could curtail the company’s “platform” aspirations.
OpenAI’s market positioning is tested by fierce competition from both tech giants and the open-source ecosystem. If OpenAI succeeds as the primary AI platform, it could prove disruptive to Google’s search dominance, Microsoft’s own software franchises, and Meta’s social platforms.
As a potential threat to tech incumbents, OpenAI is both competing and partnering with some of its most formidable competitors. Google has marshaled its AI divisions (Google Brain and DeepMind) to develop Gemini, a next-generation model to compete directly with ChatGPT. Google enjoys unrivaled advantages in proprietary data (from Gmail, Search, etc) and raw computing power. Meta, another hyperscaler, open-sourced its LLaMA models, seeding an open-source movement to erode the moat around proprietary models. Meanwhile, fellow AI-native startups like Anthropic, Mistral, and Elon Musk’s xAI are all vying for leadership in the foundational model space.
OpenAI is aiming to build an AI-centric ecosystem while surrounded by well-resourced rivals and an increasingly vibrant open-source community. This raises the stakes for OpenAI to execute flawlessly on multiple fronts (technical, distribution, and reputational) to achieve its most ambitious goals.
Customer
Consumer vs. Enterprise
OpenAI’s user adoption has been dominated by individual consumers, raising questions about the depth of its enterprise penetration. By August 2025, ChatGPT had over 700 million weekly active users globally, a user base more akin to a consumer internet platform than a typical enterprise software product. The company’s flagship offering, the ChatGPT app (and Plus subscription at $20/month), remains the primary revenue engine, accounting for the majority of OpenAI’s sales. As of August 2025, OpenAI had 20 million paying subscribers to ChatGPT Plus.
In contrast, its business-oriented plans are just beginning to scale as of 2025. About 3 million paid “business” users (seats under ChatGPT Team, Enterprise, or educational plans) were on OpenAI’s platform by June 2025. This suggests that enterprises are experimenting with AI pilots. OpenAI has noted that “80% of Fortune 500 companies” have tried its products in some form, but most heavy usage so far comes from individuals and small teams, not large enterprise-wide deployments.
OpenAI’s API services (which enable companies to integrate its AI models into their apps) contribute only about 15-20% of revenue in 2025, according to an unverified third-party estimate. In other words, four-fifths of OpenAI’s revenue is derived from end-users interacting directly with OpenAI’s apps and models, rather than enterprise software licensing.
This consumer-driven adoption is unusual for a company trying to sell cutting-edge tech into businesses, and it underscores OpenAI’s unique market entry via a viral consumer product (ChatGPT). The implication is that OpenAI’s brand and product have huge mindshare, but its enterprise business (with steadier, higher-value contracts) is not yet fully realized. This is primarily due to organizational caution around data privacy, compliance, or the immature state of generative AI for mission-critical tasks.
Ecosystem Channel Conflict
OpenAI’s go-to-market strategy creates a paradox. The company is providing a platform for developers while simultaneously competing with those very developers for end-users. On one hand, OpenAI encourages third-party companies and startups to build products on its API. On the other hand, OpenAI’s own consumer-facing solutions (like ChatGPT and its plugins) often overlap with those third-party offerings. This dynamic has already produced contradictions. For example, numerous AI writing startups (e.g., Jasper and Copy.ai) built services on GPT-3, effectively “reselling” OpenAI’s language model outputs with custom interfaces.
But the launch of ChatGPT as a free (or $20/month) general-purpose co-pilot in late 2022 undermined these startups as users could suddenly get similar functionality straight from OpenAI. As industry research notes, “OpenAI’s hit consumer product ChatGPT…works at cross purposes to their ability to sell access to their APIs into businesses”. In effect, any developer building an AI-based consumer app must now consider that OpenAI might integrate the same feature into ChatGPT itself, which is a broadly available, well-funded product. Even OpenAI’s partnership with Microsoft plays into this issue, where ChatGPT positions itself as the enterprise AI of choice even as OpenAI models are sold as a service to enterprises through Azure.
OpenAI’s competitors have taken note and adapted their positioning. Anthropic, for instance, has made a strategic choice to focus on being an enterprise AI partner. Though Anthropic provides a consumer product, the company’s main product is to provide Claude via API to embed in others’ products. This means Anthropic isn’t “co-opting” the user interface or relationship. Likewise, startups like Cohere and AI21 Labs market themselves as enterprise AI vendors that deliver models without an agenda to own the end-user interaction.
OpenAI’s dual role as a platform and consumer app provider is a difficult balance. It may be the case that OpenAI’s strongest traction will continue to be on the consumer side (individual knowledge workers, students, creatives using ChatGPT), at least until trust and customization features satisfy larger corporate requirements. The company is trying to bridge this gap with offerings like ChatGPT Enterprise and the promise of data privacy and dedicated capacity for businesses. However, OpenAI remains a top-down tech supplier and a bottom-up consumer app company. This unusual strategy carries the risk of alienating would-be partners or developers, something its rivals are exploiting by positioning themselves as neutral enablers rather than competing for the limelight.
Market Size
The artificial intelligence market is expected to be worth $1.3 trillion by 2032, growing at a 42% CAGR. In July 2024, J.P. Morgan estimated that “half of the vulnerable jobs in the United States will be automated away over the next 20 years” with a total productivity gain of “about 17.5% or $7 trillion beyond the current Congressional Budget Office projection for GDP.”
The growth projections for OpenAI’s business are extraordinary, and arguably unprecedented by historical standards. According to one third-party report from May 2025, OpenAI told investors it expects to reach $125 billion in revenue by 2029 and $174 billion by 2030, up from an estimated ~$3.7 billion in revenue in 2024. These forecasts imply that in under a decade, OpenAI could rival the annual revenues of today’s largest tech companies. For perspective, hitting $125 billion would mean roughly 35x growth in five years, a trajectory no traditional software or hardware firm of similar scale has previously achieved.
Even the rapid adoption of cloud computing and mobile platforms in the 2010s saw a more gradual monetization curve. Generative AI is scaling faster in terms of users than those technologies. ChatGPT set records as the fastest-growing consumer app in history (reaching 100 million users in 2 months), and reached 1 billion users within two years of launch. This uptake fuels the belief that a multi-trillion-dollar AI market is emerging this decade. Some analyses project the broader AI market (software and infrastructure) will exceed $1-2 trillion by the late 2020s, with annual growth rates of 40-50%. OpenAI, as a leading player, is expected to capture a significant slice of this new market.
However, historical analogs suggest that early hype often overestimates short-term commercialization. For example, during the cloud computing boom, even dominant providers took years to translate usage growth into large revenues, and enterprise SaaS companies typically scale with high-paying customers over a decade or more. OpenAI’s current financial profile reveals constraints that may temper its growth vs. pure software peers.
Notably, it has been reported that OpenAI operated at roughly 48% gross margin as of early 2025, far below the ~75% average gross margin for cloud software (SaaS) companies. This margin gap reflects the heavy computational expense of running AI models reflected in dollar spend per data center GPU infrastructure. Though the company does expect margins to improve (projecting ~70% gross margins by 2029 through efficiency gains), this hinges on significant advances in model optimization and custom hardware.
In terms of total addressable market, OpenAI’s roughly $170 billion revenue target by 2030 assumes not only achieving billions of users but also a high average revenue per user or per API client. Monetization on that scale will require entwining AI with countless industries (from finance to education to retail), creating new revenue streams beyond the current scope of chatbot subscriptions or API calls. Optimistic scenarios cite emerging use cases such as AI-driven drug discovery becoming a $35 billion market, or AI augmenting/replacing large parts of knowledge work to justify immense spending on AI. Yet it remains to be seen how much of this value OpenAI can capture itself, versus ceding to integrators and competitors.
In testing these assumptions, no precedent exists for a software platform achieving over $100 billion in annual sales primarily on AI services within such a short span. Even the largest cloud platforms (AWS, Azure) took nearly 15 years to approach the $50-$100 billion range in revenue, and those are backed by the broad IT spending shift to cloud. OpenAI bets that AI will permeate virtually every industry and that OpenAI’s models will sit at the center of this value chain. Though the total AI pie is large, OpenAI’s share could be constrained by competition, pricing pressure, and the degree enterprises choose multi-vendor or open-source approaches.
The margin structure also indicates that OpenAI’s revenue is “harder earned” for every dollar of sales, more is spent on compute, which could limit the bottom-line gains relative to a pure-play software company. While the projected market size for AI and OpenAI’s own revenue is enormous (multi-billion users and multi-trillion TAM by 2030), these figures may be more aspirational than realistic. OpenAI will need to dramatically expand its business model (hardware, commerce, etc) and defy the typical adoption-to-monetization lag that has characterized past technology waves to approach those numbers
Competition
Competitive Landscape
In the AI competitive landscape, OpenAI is squeezed between low-cost open-source offerings from below and giants with scale from above. Google, Microsoft, and Meta can match OpenAI on research talent and vastly outspend it on infrastructure; they also control channels to billions of users (Android, Windows, Facebook, Instagram, etc) for distribution. Meanwhile, the open-source community and smaller companies ensure that if OpenAI falters or overprices, alternatives are available. The competitive moat for OpenAI thus likely depends on a combination of first-mover advantage (ChatGPT brand name), continued model excellence, and building an ecosystem around its platform that adds value beyond the raw models. But the window to cement dominance is narrow, and any loss of technical edge would make it harder for OpenAI to justify its platform status, even given its consumer lock-in. Given high investor expectations, OpenAI must navigate this competitive gauntlet carefully to maintain its lead.
Tech Giants / Hyperscalers
Google has been focused on AI research and infrastructure since 2016, positioning artificial intelligence as central to its organizational strategy. The company implemented AI enhancements in Google Search algorithms, YouTube's recommendation systems, Gmail's smart features, and the computational photography capabilities in Pixel smartphone cameras. Through Google Cloud, the company provided AI tools and services to external businesses and developers. The company also directed AI research toward societal applications, specifically targeting healthcare solutions and climate change modeling, though the post does not detail specific outcomes in these areas.
The company's AI research originated from two distinct organizations with different histories and specializations: Google Research's Brain team and DeepMind, a London-based AI company acquired by Google in 2014. These two organizations operated as separate entities while producing foundational AI technologies. Their collective achievements included AlphaGo (the first AI system to defeat a world champion Go player), transformer architecture (the foundation for modern large language models), word2vec (word embedding methodology), WaveNet (audio synthesis model), AlphaFold (protein structure prediction system), sequence-to-sequence models (enabling improved machine translation), knowledge distillation techniques (for model compression), and deep reinforcement learning algorithms.
Brain and DeepMind also developed critical infrastructure, including TensorFlow and JAX frameworks, which became widely adopted tools for expressing, training, and deploying large-scale machine learning models across the industry. In April 2023, Google restructured these operations by merging the Brain team with DeepMind to form a unified division called Google DeepMind.
As of 2020, DeepMind had published over 1K papers, including 13 papers accepted by Nature or Science, and at the 2024 International Conference on Machine Learning alone, teams from Google DeepMind presented more than 80 research papers. The combined Google AI divisions continue to produce foundational research, with 2024 breakthroughs including AlphaQubit published in Nature, the FACTS Grounding Leaderboard developed with Kaggle, and collaborative work on models like AMIE for medical diagnostics and LearnLM for education. This substantial publication output and conference presence demonstrate that Google/DeepMind remains a major source of cutting-edge AI research papers.
Google's investment in custom tensor processing units represents one of the most significant strategic advantages in the AI infrastructure landscape. Google began using TPUs internally in 2015 and made them available for third-party use in 2018. The latest generation, TPU v4 and v5e, were used to train Google’s models, and in 2023, Google unveiled a new Cloud TPU v5p supercomputer for its next-gen systems.
Google launched its flagship model Gemini initially in December 2023 as a direct answer to OpenAI’s GPT-4. Developed by Google DeepMind, Gemini is a multimodal AI chatbot. Early benchmarks showed that Gemini Ultra, its most capable model, outperformed GPT-4 on many academic tests. In fact, Gemini became the first model to exceed human expert-level on the MMLU exam benchmark (90% score).
Google introduced Gemini 2.5 in March 2025. All Gemini 2.5 models are thinking models, capable of reasoning through their thoughts before responding. The models include 2.5 Pro, which scored 84.0% on MMMU multimodal reasoning tests and led on LiveCodeBench for competition-level coding and 2025 USAMO math benchmarks as of May 2025; and 2.5 Flash, an efficiency-focused model that showed improved performance across key benchmarks while using 20-30% fewer tokens.
Google’s latest model release as of November 2025 is Gemini 3. Gemini 3 was designed to integrate multimodal capabilities with advanced reasoning. The release features Gemini 3 Pro and a preview of a more advanced reasoning variant called Gemini 3 Deep Think. In terms of benchmark performance, Gemini 3 Pro achieved a record 1501 Elo on the LMArena Leaderboard and secured top scores on benchmarks such as GPQA Diamond with 91.9% and MathArena Apex with 23.4%. This is compared with OpenAI’s GPT 5.1’s 88.1% and 1.0% scores on the same benchmarks, respectively.
The Deep Think variant further improves performance on complex tasks, scoring 45.1% on ARC-AGI-2 and 93.8% on GPQA Diamond, compared to GPT-5.1’s 17.6% and 88.1% scores on the same benchmarks. The model features a 1 million-token context window and powers a new agentic development platform called Google Antigravity. Since launching in 2023, the Gemini ecosystem has seen substantial user engagement. As of November 2025, AI Overviews serve 2 billion users every month, while the Gemini app has surpassed 650 million monthly users. Over 70% of Google Cloud customers utilize the company’s AI tools, and 13 million developers are building with its generative models.
The economic benefits of Google's vertically integrated approach are substantial. For instance, Google's Gemini 2.5 Pro costs $10 per 1 million output tokens versus OpenAI o3's $40 per 1 million output tokens, while Gemini 2.5 Flash costs just 60 cents per 1 million output tokens versus o4 mini's $4.40. This reflects what analysts call an “80% cost edge” from bypassing the “Nvidia Tax,” referring to the models OpenAI trained with Nvidia chips.
Google’s TPU design philosophy prioritizes lower power consumption and total cost of ownership over peak performance. TPUs consume significantly less power than Nvidia's H100, which runs at 2x the power consumption of a TPUv5 and approximately 5x that of TPUv5e. In a real-world use case, Midjourney reduced inference costs by 65% after migrating from GPUs, while Cohere achieved 3x throughput improvements. Google's newest Trillium (TPU v6), released in December 2024, delivers up to 2.5x improvement in training performance per dollar and up to 1.4x improvement in inference performance per dollar over the prior generation, with up to 4x faster training for dense LLMs like Llama-2-70b compared to TPU v5e.
In addition to developing in-house chips and talent, Google invested $300 million for a 10% stake in Anthropic in February 2023. The investment valued Anthropic at around $5 billion and came just weeks after Microsoft announced its $10 billion investment in OpenAI in January 2023. As part of the partnership, Anthropic chose Google Cloud as its preferred cloud provider, with Google building out large-scale TPU and GPU clusters for Anthropic to train and deploy its AI models. Google later committed to invest an additional $2 billion in Anthropic in October 2023, further deepening its stake in the company.
Microsoft
Microsoft is both OpenAI’s closest partner and a competitor in its own right. From 2019 through 2023, Microsoft was OpenAI’s primary investor, allocating more than $13 billion into the startup. Then, OpenAI funneled most of those billions back into Microsoft in the form of buying cloud computing power needed to fuel the development of new AI technologies in a partnership that gave Microsoft exclusive cloud provider status (Azure) for OpenAI, as well as early access to OpenAI’s models. By March 2023, Microsoft had integrated GPT-4 into Bing (as the Bing Chat copilot) and, by September 2023, launched Microsoft 365 Copilot to bring AI assistance into Office apps, directly leveraging OpenAI’s technology.
Microsoft maintains substantial independent AI research capabilities through Microsoft Research, which has contributed significant breakthroughs to the field. In 2020, Microsoft introduced Turing Natural Language Generation (T-NLG), a 17-billion-parameter model that was the largest published at the time, demonstrating the company's early expertise in large-scale language models. This was followed by the Megatron-Turing NLG 530B model in 2021, a collaboration with Nvidia that created a 530 billion parameter model, then the world's largest and most powerful monolithic transformer language model.
Microsoft has also been developing its own AI infrastructure. In May 2025, the company built one of the world's top five supercomputers for OpenAI, featuring more than 285K CPU cores, 10K GPUs, and 400 gigabits per second of network connectivity for each GPU server. In October 2025, Microsoft unveiled the world's first production-scale Nvidia GB300 NVL72 cluster with over 4.6K Nvidia Blackwell Ultra GPUs, purpose-built for OpenAI's most demanding AI inference workloads, with plans to scale to hundreds of thousands of Nvidia Blackwell Ultra GPUs.
In terms of custom silicon development, Microsoft has made significant strides to reduce dependence on third-party hardware. At the 2023 Ignite conference, Microsoft introduced the Azure Maia AI Accelerator (codenamed Athena), a 5-nanometer TSMC chip with 105 billion transistors designed specifically for AI tasks and generative AI, alongside the Azure Cobalt CPU, a 128-core Arm-based processor. Microsoft's CTO, Kevin Scott, indicated in October 2025 that the company wants to mainly use its own data center chips for AI in the longer term, though it uses a mix of Nvidia, AMD, and its own custom silicon as of October 2025.
This vertically integrated approach mirrors Google's strategy with TPUs and positions Microsoft to achieve similar cost and performance advantages in training large models. The collaboration between Microsoft and Nvidia has enabled the use of Azure's infrastructure for training models like ChatGPT, with thousands of Nvidia AI-optimized GPUs linked together in a high-throughput, low-latency network based on Nvidia Quantum InfiniBand. Since OpenAI's models are trained on Azure clusters funded by Microsoft's capital, Microsoft effectively possesses comparable compute resources to OpenAI itself, creating a symbiotic relationship where both organizations benefit from shared infrastructure investments.
Meta
In contrast to OpenAI and Google, Meta has adopted an open research and open-source approach to AI. In February 2023, Meta released the LLaMA series of LLMs openly to researchers. The primary technical characteristic highlighted was its range of sizes, including 7 billion, 13 billion, 33 billion, and 65 billion parameters, which were specifically chosen to make advanced LLMs accessible to researchers lacking vast computing resources.
This focus on smaller, yet competitively performant models was a strategic move aimed at democratizing the field, as these models require significantly less computational power for experimentation, validation, and fine-tuning compared to models like GPT-3. In fact, external benchmarks showed LLaMA 2 on par with GPT-3.5 on many tasks, and subsequent community tweaks further bridged the gap to GPT-4. LLaMA’s popularity is evidenced by the 10x increase in monthly usage (token volume) from January to August 2024.
To build on the momentum established by LLaMA 2, LLaMA 3 was released in April 2024, which significantly closed the performance gap with proprietary models like OpenAI’s GPT-4. LLaMA 3 launched with models up to 70 billion parameters and introduced an instruction-tuned model. Notably, Meta is actively working on larger, potentially 400-billion-parameter LLaMA 3 models for future release, which are specifically targeted to surpass existing models in complex reasoning tasks.
Internally, Meta leverages its GPU data centers, built from years of running AI at scale for content ranking and moderation across billions of Facebook and Instagram users. While the company still relies heavily on Nvidia H100 GPUs, Meta continues to invest heavily in developing custom AI hardware, such as its MTIA chips, which were reported in March 2025, to enhance efficiency. In March 2024, Meta announced plans to build two data‑center–scale clusters, each with roughly 24K Nvidia H100 GPUs, used for training Llama 3 and other GenAI workloads. They also stated a 2024 goal to operate infrastructure equivalent to around 600K H100s.
Beyond open-sourcing frontier models like LLaMA, Meta actively supports the wider AI community by offering foundational tools such as PyTorch, demonstrating a commitment to preventing vendor lock-in and accelerating ecosystem growth. PyTorch, an open-source machine learning library, was first released in May 2018. PyTorch has since become the dominant framework for AI research (used in over 70% of AI research implementations as of 2024), a success so widespread it led to the creation of the vendor-neutral PyTorch Foundation in 2022. Meta’s commitment to open-sourcing AI technologies aligns directly with Mark Zuckerberg's vision. By offering powerful, widely adopted tools freely, Meta seeks to prevent industry-wide vendor lock-in to competitors' proprietary systems, fosters accelerated ecosystem growth, and positions itself as a key architect of the industry's enduring open-source standard.
Meta’s aggressive AI push stems from its position playing catch-up against rivals like OpenAI and Google, a situation made clear by the initially underwhelming performance of its flagship model projects. Specifically, the highly anticipated, 288-billion-parameter Llama 4 "Behemoth" model was repeatedly delayed from its initial April 2025 launch date. Internal concerns surfaced over the model's underwhelming performance gains in areas like logical reasoning and mathematics, and its inference inefficiency, prompting Meta to restructure the Llama 4 development team and even consider adopting a Mixture of Experts (MoE) architecture due to competitive pressure. This lack of an immediately superior, flagship model left the company without a readily monetizable, high-end commercial offering to rival the established APIs of GPT-4 and Gemini.
To rapidly close this capability gap, Meta launched a hiring spree, forming its Superintelligence Labs (MSL) in June 2025 and projecting massive capital expenditures between $66 billion and $72 billion for 2025, an effort personally led by CEO Mark Zuckerberg. This campaign involved poaching top researchers from competitors, including dozens from OpenAI, with reported compensation packages for lead engineers ranging from $100 million to $300 million over four years for top-tier talent.
Meta recruited four key executives to lead its Superintelligence Labs: Ruoming Pang, Apple's former head of foundation models who developed Apple Intelligence, reportedly secured a package exceeding $200 million; Nat Friedman, ex-GitHub CEO, came aboard to co-lead the labs alongside Wang; and Daniel Gross, who had been CEO of Safe Superintelligence and co-ran the NFDG venture fund with Friedman backing AI startups like Perplexity. The effort was further cemented by a key $14.3 billion investment in Scale AI for a 49% stake, effectively securing the data expertise and the startup's CEO, Alexandr Wang, to lead the new Superintelligence unit.
Together, these hires represent Meta's aggressive strategy to acquire proven AI leadership from across the industry, combining deep technical expertise (Pang), data infrastructure mastery (Wang), product development experience (Friedman), and AI investment acumen (Gross), to accelerate its pursuit of artificial general intelligence. The massive financial commitment, including nine-figure compensation packages and substantial infrastructure investments, highlights the tension between Meta's open-source philosophy and the escalating costs of competing at the frontier of AI development.
Amazon
Amazon, the world’s largest cloud provider (AWS), is positioning itself as the platform of choice for generative AI, rather than betting on a single in-house model. In September 2023, Amazon announced a strategic partnership with Anthropic, initially investing $4 billion for a minority stake and later increasing to a total of $8 billion committed in November 2024. This made AWS the primary cloud for Anthropic’s training and gave Amazon access to Anthropic’s Claude models to enhance its own offerings.
The Amazon–Anthropic partnership can be seen as a parallel counterpart to Microsoft–OpenAI, aligning a major cloud vendor with a leading AI startup. Aside from Anthropic, Amazon’s Bedrock service (launched in September 2023) brought a selection of top models to AWS customers, including models from AI21 Labs (Jurassic), Cohere, Stability AI (Stable Diffusion), Meta’s Llama 2, and Amazon’s own baseline models. This multi-model marketplace approach reflects Amazon's strategic positioning: instead of competing to build the best individual model, AWS aims to win as the essential infrastructure provider hosting all leading models. By leveraging its cloud computing dominance and offering customers maximum flexibility, including access to OpenAI's models through third-party APIs, Amazon is attempting to sidestep the model development race while capturing the underlying value.
That said, Amazon is also developing its own foundation models, known as Amazon Titan Text models (and others like CodeWhisperer for code generation). These models have been less high-profile, partly because Amazon has kept them behind APIs for AWS users and focused on enterprise applications. Amazon’s internal AI talent has been more fragmented. It has AI teams for Alexa voice assistant, for recommendation algorithms, etc., but historically, Amazon AI research lagged behind its counterparts at Google or Meta. However, Amazon has made key hires and acquisitions like Zoox, and with the influx of Anthropic’s expertise (Anthropic’s researchers will collaborate with AWS engineers), Amazon’s talent pool is strengthening. Notably, Anthropic’s team includes several ex-OpenAI researchers with safety and model expertise.
In terms of compute resources, Amazon’s AWS arguably has the largest on-demand compute capacity of any cloud, and it has innovated in AI chips. Its compute capacity leadership is evidenced by AWS's consistent market leadership, holding the largest market share (number one in the IaaS market as of 2024) and making massive infrastructure investments ($83 billion in capital expenditures in 2024 and projected $125 billion in 2025). While competitors like Microsoft Azure and Google Cloud are growing quickly, AWS maintains the largest absolute scale and market position due to its early leader advantage and substantial, sustained capital investment. In terms of AI chips, Amazon’s Inferentia (for inference) and Trainium (for training) chips are custom-designed to lower the cost of running AI models on AWS. By 2024, Amazon began persuading partners to use these chips, such as Anthropic, which agreed to train future Claude models on AWS Trainium hardware instead of only Nvidia GPUs.
Overall, Amazon’s competitive edge lies in ubiquity and choice. It may not (yet) have a ChatGPT-equivalent consumer product, but it enables others to build chatbots and genAI apps on AWS. Enterprises wary of sending data to OpenAI or Google can opt for an AWS-first approach. For instance, they can use a Claude model via Bedrock, fine-tuned privately on AWS, with all data staying in their AWS environment. This value proposition of data control and integration with AWS’s cloud tools (security, databases, etc.) is compelling for many companies. In the long run, Amazon’s success will be measured by how much of the generative AI workload market it captures on AWS versus Azure and Google Cloud.
Open-Source/Chinese Competitors
A flourishing open-source AI movement is providing low-cost (or free) alternatives to OpenAI’s models, which could erode OpenAI’s market power. Since 2023, over 250 foundation models have been released, with one-third of those introduced after August 2023 alone, a testament to the rapid pace at which new players and research labs are launching models. Many of these are open-source or at least openly available to developers. For example, when Meta’s LLaMA weights leaked and were later officially released, developers around the world optimized the model to run on inexpensive hardware and even on smartphones. Projects like BLOOM (from Hugging Face), Mistral, and numerous others are iterating quickly. According to multiple industry assessments, some smaller open models now “compete head-to-head or even outperform established firms’ models on well-known benchmarks.”
DeepSeek’s release of its R1 and V3 models in January 2025 epitomized the strength of not only the open-source ecosystem in the US and more broadly in China. Founded in 2023 by Liang Wenfeng, a computer science engineer and the founder of the quantitative hedge fund High-Flyer Quant, DeepSeek’s origins are distinct in that it is self-funded and independent, allowing it to bypass the immediate commercial pressures faced by venture-backed startups.
This financial autonomy enabled the team to focus on architectural efficiency, specifically "Mixture-of-Experts" (MoE) architectures, which became crucial to their strategy of overcoming hardware limitations imposed by US export controls on high-end Nvidia chips. The industry received both technical and economic shocks in late January 2025 following the release of the DeepSeek-R1 and DeepSeek-V3 models.
More specifically, DeepSeek revealed that R1, a reasoning model comparable in performance to OpenAI’s o1, was trained for approximately $5.6 million. In stark contrast, U.S. counterparts often cite training costs in the hundreds of millions (e.g., OpenAI's GPT-4 was estimated to cost around $100 million). This revelation triggered a massive sell-off in the US stock market as investors feared that DeepSeek’s efficiency breakthroughs would break the "scaling laws" that justified substantial spending on hardware infrastructure.
DeepSeek is not an isolated anomaly but the spearhead of a broader, robust Chinese open-source ecosystem that includes heavyweights like Alibaba’s Qwen and 01.AI’s Yi model series. This ecosystem has adopted a "release early, release often" strategy that contrasts with the guarded approach of Google and OpenAI. For instance, Alibaba’s Qwen has seen massive adoption (over 600 million downloads as of September 2025) and is integrated into widely used platforms, effectively becoming the open-source alternative of the AI world to OpenAI’s closed-source model. The Chinese government supports this ecosystem through initiatives like the National Integrated Computing Power Network (NICPN), which aims to pool resources and reduce costs for domestic developers.
The open-source models often have the benefit of being highly customizable and free of usage restrictions, attracting power users and enterprises with specialized needs or tighter budgets. Cost is a key differentiator as open models can be run locally or on cheaper cloud instances, undercutting OpenAI’s API pricing. These open-source alternatives may force a scenario where OpenAI’s core technology becomes commoditized and lead to lowered switching costs (alongside eroding margins). To combat this, OpenAI would need to stay far ahead in model capability or offer proprietary advantages (like superior tooling, security, or integration) that open models lack. Nonetheless, the barrier to entry in AI model development has lowered as abundant open-source code, model checkpoints, and research mean no single company can monopolize innovation.
AI Startups (Horizontal / Vertical)
Beyond incumbents and open communities, numerous startups have entered the fray, either building general-purpose AI models (horizontal players) or applying AI to specific industries and tasks (vertical players). These startups often consist of top researchers spun out of big tech or OpenAI, and many have secured massive funding.
Anthropic
Arguably OpenAI’s most direct startup competitor, Anthropic was founded in 2021 by former OpenAI researchers, including Dario Amodei, after disagreements over OpenAI’s direction. Anthropic’s mission focuses on AI safety and alignment, and it developed the Claude series of large language models.
Claude debuted in 2022 and by 2023 was a strong competitor to ChatGPT, known for its exceptionally long context window (100K tokens in Claude 2) and better, more moral conversational style. Anthropic pioneered “constitutional AI”, an alignment method where the model is guided by a set of written principles to self-correct harmful outputs. This allows training a helpful-but-harmless AI with far fewer human interventions, an innovative alternative to OpenAI’s RLHF.
In terms of talent, Anthropic has attracted defectors from OpenAI. For instance, in 2023 and 2024, OpenAI’s vice president of alignment, Jan Leike, and renowned researcher John Schulman (architect of ChatGPT) both left to join Anthropic. Several other OpenAI scientists also moved to Anthropic, reflecting Anthropic’s position as a refuge for those prioritizing a more measured approach to AI development. This talent influx gives Anthropic one of the strongest research teams outside OpenAI or Google.
With strong financial backing and strategic partnerships with tech incumbents, Anthropic developed models and capabilities on par with OpenAI. Anthropic started with an initial $124 million from investors in May 2021 and later received $300 million from Google for a 10% stake in February 2023. By the end of 2024, Amazon had invested $8 billion and formed a strategic partnership that allowed Anthropic to train frontier models approaching OpenAI’s magnitude, whose partnership with Microsoft has continuously granted it valuable compute resources.
Anthropic has rapidly advanced its large language models, starting with the Claude Instant series in 2023, which quickly expanded its context window to 100K tokens for enhanced analysis. The critical shift came with the Claude 3 family (Haiku, Sonnet, and Opus) released in March 2024, where all three models, led by the high-performing Opus, were reported to outperform OpenAI's GPT-4 on key benchmarks, including math, reasoning, and document Q&A. This competitive lead was further solidified in July 2024 with the release of Claude 3.5 Sonnet, which set new industry benchmarks and was stated to outperform both Claude 3 Opus and GPT-4o on several graduate-level reasoning and coding tasks, firmly positioning Claude as a current performance leader in the frontier AI race.
Anthropic has also established competitive advantages against competitors like OpenAI through strategic product development and the creation of essential industry standards. In the high-value software development segment, Claude Code, released in May 2025, serves as a comprehensive tool allowing developers to write, edit, debug, and ship code end-to-end. It supports integrations with popular environments such as VS Code and JetBrains extensions, and includes GitHub integration for automated PR responses, leading to its adoption by major developer tools like GitHub Copilot, Cursor, and Replit*. Claude Code’s capability has helped Anthropic capture a significant share of the enterprise developer market.
Furthermore, Anthropic has exerted influence at the platform level by introducing the Model Context Protocol (MCP) in November 2024. This open standard was designed to address the "N×M problem" by providing a universal protocol for connecting any AI application with any data source through standardized interfaces. The protocol's adoption has been rapid and widespread. OpenAI officially integrated MCP across its own products, including ChatGPT and its Agents SDK, in March 2025. Additionally, Microsoft partnered with Anthropic to develop an official SDK in C# and added native MCP support to Copilot Studio, positioning the protocol to become an "open standard for the AI agentic era," according to Google DeepMind CEO Demis Hassabis.
As of November 2025, Anthropic has a reported valuation of $350 billion following a $15 billion investment round from Microsoft and Nvidia in the same month. This milestone follows a period of explosive growth, including a September 2025 Series F round led by ICONIQ that valued the company at $183 billion. As of November 2025, Anthropic has raised over $27 billion in total funding. Amazon remains its largest backer with approximately $8 billion in total commitments, alongside Google, which has invested over $3 billion. Other key investors include Salesforce Ventures, Lightspeed Venture Partners, Menlo Ventures, and Spark Capital.
xAI
A relatively new entrant to the AI race, xAI was founded by Elon Musk in July 2023. Musk, who was a co-founder of OpenAI back in 2015 but later departed, has been vocally critical of OpenAI (for example, disagreeing with its for-profit pivot). With xAI, Musk assembled a small elite team (including former DeepMind researchers like Igor Babuschkin and Tony Wu from Google) to develop a “good AGI” that is truth-seeking and maximal in curiosity.
xAI has made waves with its pursuit of extreme compute. In 2023, Musk reportedly acquired around 10K high-end GPUs to kickstart xAI’s training cluster. By July 2024, Musk announced that xAI’s upcoming model (Grok version 3) would be trained on 100K Nvidia H100 GPUs. This claim, if realized, implies a compute budget on the order of $3–4 billion just in chips, putting xAI’s effort in the same league as the largest projects at OpenAI or Google. Musk’s vision is to reach even larger scales, tweeting that xAI aims for “50 million GPU-equivalents” over five years in August 2025.
In November 2023, xAI first released the Grok chatbot, which has undergone rapid iterations to boost its reasoning, speed, and features. It began with Grok-1 (released November 2023), designed to be a witty, "rebellious" chatbot with real-time knowledge from X, but which initially courted controversy due to its unfiltered and occasionally inaccurate nature. This was quickly followed by Grok-1.5 (March 2024), which delivered significant improvements in reasoning and massively expanded its context window to 128K tokens, narrowing the performance gap with rivals like GPT-4.
The next major leap came with Grok-2 and Grok-2 Mini (August 2024), bringing versatility, better accuracy, and multilingual support, while also being made available to developers via an API. By December 2024, the model was rolled out to all X users for free and upgraded to include live web searches, source citations, and multimodal image generation (Aurora). The latest iteration, Grok 3 Beta (February 2025), trained on xAI's "Colossus" compute cluster, demonstrated improved performance across top academic benchmarks, with new features like DeepSearch for complex research and a "Think" advanced reasoning mode.
As an answer to ChatGPT’s image generation capability, Grok Imagine, xAI’s image generator native to Grok, was released in August 2025. Finally, Grok launched as an in-car conversational assistant for Tesla vehicles in July 2025. Upon launch, Grok acted as a chat-style companion to answer questions, provide summaries, and offer entertaining responses, but it did not control vehicle functions such as climate or navigation.
As of November 2025, xAI has a reported valuation of $200 billion following a reported September 2025 funding round of $10 billion, although Elon Musk disputed the reports and claimed the company was not raising. xAI has raised over $25 billion in total funding across eight separate funding rounds. The Qatar Investment Authority and Kingdom Holding remain key backers with substantial commitments, alongside Valor Equity Partners, which has participated across multiple funding rounds. Other key investors include Sequoia Capital, Andreessen Horowitz (a16z), Fidelity Management & Research Company, Vy Capital, BlackRock, Lightspeed, Morgan Stanley, MGX, and technology partners Nvidia and AMD.
The future competitive relationship between xAI and OpenAI will be fundamentally shaped by contrasting strategic approaches and a fierce technical race for model capability. xAI leverages a core advantage through its tight integration with the X platform, which was acquired by xAI in March 2025 for $33 billion. X provides Grok with proprietary, real-time data for training and a massive, built-in user base that is inaccessible to OpenAI. Philosophically, xAI differentiates itself with an open-source approach and an unfiltered, rebellious persona, standing in opposition to the typically closed and more strictly moderated models of OpenAI. Crucially, xAI has also demonstrated its ability to compete directly on performance, indicating a sustained, high-stakes battle for technical leadership.
Cohere
Cohere was founded in 2019 by Aidan Gomez (CEO), Nick Frosst, and Ivan Zhang, all of whom had studied at the University of Toronto. Gomez and Frosst further honed their expertise as AI researchers at Google Brain in Toronto. Crucially, Cohere’s DNA is linked directly to the foundation of modern AI. Aidan Gomez co-authored the 2017 paper "Attention Is All You Need," which introduced the transformer model architecture that underlies all top large language models, including Cohere’s and OpenAI’s GPT series.
The company's founding thesis centered on the belief that LLMs were the next valuable technology, but they were constrained by research labs. Cohere’s objective was to bring this technology to industry and facilitate widespread adoption, specifically aiming to serve as an independent AI platform not tied to any hyperscaler. Their core focus is to provide businesses with API access to their general-purpose language models, thereby solving the expensive cost (often over $10 million) of training large models in-house and the lack of specialized engineering talent required to manage them.
Cohere’s product evolution is defined by its API-first approach, offering models optimized for three primary use cases. For retrieving text, the company offers endpoints like Embed for multilingual text analysis, Semantic Search for meaning-based results, and Rerank to improve existing search systems. For generating text, it provides a Summarize endpoint, a general Generate endpoint for content creation, and a flagship Command Model, which is built to follow user instructions for business applications and can be custom-trained on customer data. Lastly, the Classifying Text endpoint allows customers to extract meaning for tasks such as content moderation and sentiment analysis. This suite of services is delivered through a tiered, usage-based pricing model to enterprises like Oracle, Notion, and Spotify.
As of September 2025, Cohere had a reported valuation of $7 billion following a $100 million extension to its Series D round in the same month. This milestone follows a period of strong growth, including an oversubscribed August 2025 Series D round that raised $500 million and valued the company at $6.8 billion. As of November 2025, Cohere has raised approximately $1.5 billion in total funding across seven separate rounds. PSP Investments and Cisco led key rounds, with Nvidia and AMD Ventures serving as significant backers across multiple funding rounds. Other key investors include Inovia Capital, Salesforce Ventures, Index Ventures, Oracle, Tiger Global Management, Sequoia Capital, and more.
Industry-Focused Vertical AI Startups
A wave of vertical AI startups is applying large AI models to specific domains. These companies might not train giant models from scratch (often they fine-tune existing ones), but they represent competitive pressure in terms of capturing customers and innovating on applications. A few examples:
Healthcare and Science AI: Companies like DeepMind’s Isomorphic Labs or startups like Insilico Medicine use AI for drug discovery and biological research. While not direct competitors to ChatGPT, they vie in the sense of attracting top AI talent and pushing AI frontiers in areas OpenAI hasn’t prioritized. For instance, DeepMind’s AlphaFold solved a 50-year-old biology problem (protein folding), which is an innovation edge that showcases its lead in scientific discovery. If OpenAI aims for AGI, these domain breakthroughs are steps on that path that others are achieving first.
Legal AI and Finance AI: Startups such as Harvey (legal AI co-pilot for lawyers) or BloombergGPT (a finance-trained LLM developed by Bloomberg) demonstrate verticalization. While Harvey uses OpenAI under the hood, BloombergGPT was an independent effort, using a 50-billion-parameter model trained on financial data, arguably competing with OpenAI for finance clients by being more specialized. However, an October 2025 report claims that OpenAI is reportedly working with real bankers to develop solutions to automate junior bankers’ workload using AI, a sign that OpenAI is moving fast to capitalize on industry-specific solutions.
AI Agents and Automation: Some startups focus on AI agents and automations that speed up traditional workflows (e.g., Anysphere’s Cursor). They may use base models from OpenAI or others, but they add proprietary layers and could switch providers – meaning OpenAI risks being replaced by another model. The existence of open-agent frameworks and protocols (like LangChain and initiatives like the MCP) for tools means startups can mix-and-match model providers. This again intensifies competition on quality and pricing among model providers.
Business Model
Corporate Structure
In 2015, OpenAI was set up as a 501(c)(3) research lab. OpenAI was a nonprofit organization with the mission to “ensure that artificial general intelligence (AGI) benefits all of humanity”. Between 2015 and 2018, OpenAI focused on producing open research, publishing papers, and releasing tools like the OpenAI Gym toolkit for reinforcement learning.
As its AI research progressed, OpenAI encountered significant computational and financial costs involved with training increasingly large models. In 2019, the organization recognized that achieving its goals to build AGI would require more resources than what philanthropic donations could provide.
Subsequently, in March 2019, OpenAI created a for-profit subsidiary called OpenAI LP under the original nonprofit. OpenAI LP is a capped-profit company that allows OpenAI to attract private investments while maintaining its nonprofit’s mission. Through the subsidiary, investors and employees could receive equity in OpenAI LP, but their returns were capped at a predetermined limit. Returns for the first round of OpenAI investors were capped at 100x their initial investment. Any profit beyond that cap would revert to the OpenAI nonprofit.
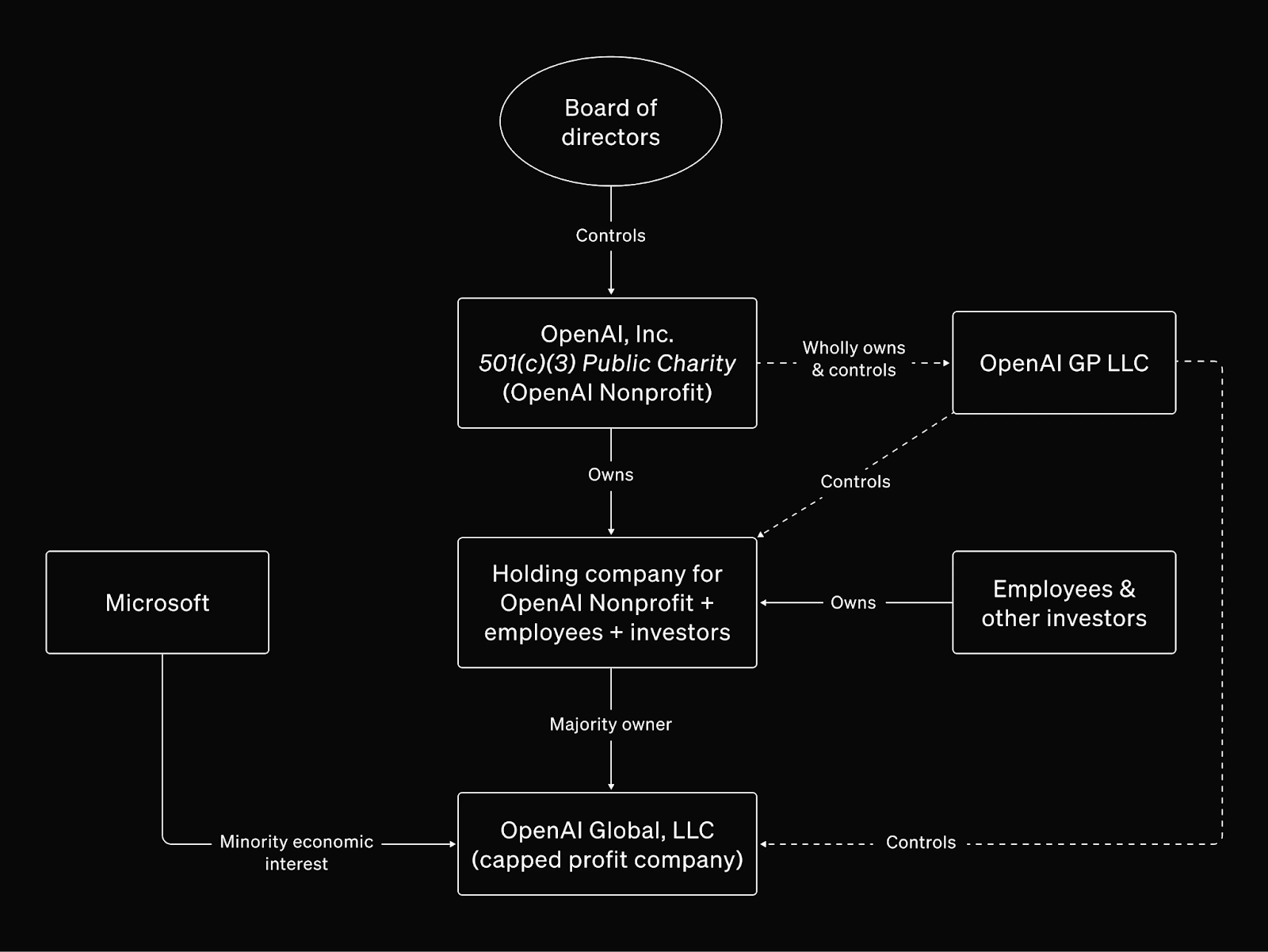
Source: OpenAI
Structurally, the nonprofit parent (OpenAI, Inc.) controls the general partner (OpenAI GP LLC), which governs the for-profit OpenAI LP (OpenAI Global, LLC), which issues equity capped in returns to employees and investors.
In October 2025, OpenAI completed a major corporate recapitalization that officially transitioned its main business into the OpenAI Group Public Benefit Corporation (PBC), removing the previous capped-profit limit and allowing all equity holders to own conventional stock that participates proportionally in the company’s success. The original nonprofit entity was officially named the OpenAI Foundation, and its core mission of ensuring AGI benefits all of humanity was explicitly embedded into the PBC's charter.
Crucially, the Foundation retains ultimate governance control through special voting rights, allowing it to appoint and replace all directors of the for-profit Group at any time. Furthermore, the Foundation secured a substantial financial stake, holding a 26% equity stake in the OpenAI Group (valued at approximately $130 billion) as of October 2025, and a warrant for significant additional shares if a long-term valuation milestone is reached, positioning the nonprofit as the single largest long-term beneficiary of the company's growth and providing a direct funding mechanism for its philanthropic focus areas, such as health and AI resilience.
Monetization
OpenAI’s business model generates revenues through several channels: consumer-facing products, enterprise-facing products, a developer API platform, and occasional licensing deals.
Consumer Plans
OpenAI’s primary consumer-facing product is ChatGPT. In February 2023, OpenAI introduced ChatGPT Plus, a $20-per-month subscription that offers users priority access, faster response times, and access to more advanced models. For power users, OpenAI provides a Pro tier that includes everything in ChatGPT Plus as well as unlimited access to all reasoning models, voice models, video generation, Operator, and Codex agent.
OpenAI also offers a free tier of ChatGPT limited to older models and subject to slower service during peak times. This subscription model allows OpenAI to monetize their user base while maintaining a free tier for broader accessibility. Launched in October 2025, ChatGPT Go is a low-cost subscription plan that provides expanded access to ChatGPT’s existing free features, including extended access to file uploads and advanced data analysis. It initially launched in developing countries, including Southeast Asia and Africa.
Enterprise and Team Plans
In August 2023, OpenAI released ChatGPT Enterprise, a plan focused on providing an enterprise-grade AI offering for organizations. ChatGPT Enterprise offers higher performance with models, enhanced data privacy, and administrative tools for managing corporate accounts. ChatGPT Enterprise pricing is set through custom contracts, dependent on the number of seats and usage.
Teams can also purchase ChatGPT Team. ChatGPT Team is priced based on the number of seats and provides an experience similar to ChatGPT Plus for teams and growing organizations. For smaller organizations, OpenAI first introduced ChatGPT Team, which was renamed ChatGPT Business in August 2025. This plan is priced at $25 per user/month and includes a shared workspace, team-based admin controls, and higher message limits for advanced models than the individual Plus plan, serving as a collaborative layer for teams and growing organizations without the extensive security and customization features of the full Enterprise plan.
Developer API Platform
OpenAI provides API access to its models for developers and businesses. The OpenAI API allows customers to integrate AI capabilities into their own applications without needing to run the underlying models on their own hardware. OpenAI hosts the models in the cloud and charges users per request. Pricing is usage-based and calculated based on the number of tokens used in a request. Developers using OpenAI’s API platform pay a fixed amount per 1 million tokens based on the model and task at hand. Different APIs, such as the Realtime API, Image Generation API, Responses API, Chat Completions API, and Assistants API, all have different price schemes based on usage.
In addition to usage fees, OpenAI’s API business includes volume licensing and enterprise deals. For instance, some companies negotiate an annual contract or purchase a set amount of capacity for a fixed price.
Enterprise and Licensing Partnerships
Beyond self-service API access and subscriptions, OpenAI engages in enterprise and licensing partnerships. One example of this is OpenAI’s partnership with consulting firms, such as Bain & Company, to integrate AI solutions for large corporations. OpenAI also works directly with certain enterprise customers, helping customers deploy AI across their organizations, build custom GPTs, and optimize models based on customers’ proprietary data.
OpenAI also licenses its technology for exclusive use in partner products. In 2020, Microsoft obtained an exclusive license to GPT-3’s underlying model weights, which facilitated Microsoft’s integration of AI into Microsoft Word, Outlook, and Power Platform. When OpenAI develops new models, Microsoft often gets early access or integration rights. For instance, Bing was the first search engine to utilize GPT-4 for search.
Traction
Product
In June 2022, OpenAI released DALL-E for image generation for over 1 million beta users. In September 2022, it removed the waitlist and grew the user base to over 1.5 million users, who created more than 2 million images per day.
In November 2022, OpenAI launched ChatGPT. ChatGPT reached 1 million users in its first five days. Within two months after launch, ChatGPT reached 100 million active users, setting the record for the fastest-growing consumer application in history. In February 2023, OpenAI introduced a new subscription plan, ChatGPT Plus, for twenty dollars per month. By July 2024, ChatGPT Plus had more than 7.7 million paying subscribers.
In August 2023, OpenAI released ChatGPT Enterprise. By September 2024, OpenAI reported more than 1 million paying business users. In February 2023, OpenAI announced a partnership with management consulting firm Bain & Company to support Bain’s enterprise clients with AI solution implementation through OpenAI’s technology. Nine months after launch, OpenAI reported that in August 2023, 80% of Fortune 500 companies adopted ChatGPT. Early users of ChatGPT Enterprise included Block, Canva, Carlyle, The Estée Lauder Companies, PwC, and Zapier.
OpenAI reported $1.6 billion in revenue in 2023. In February 2025, OpenAI saw more than 400 million weekly active users and 2 million paying enterprise users across all of its products. In March 2025, OpenAI was projected to triple its revenue to $12.7 billion from the prior year. According to Ramp’s* AI Index in May 2025, 32.4% of US businesses were paying for subscriptions to OpenAI’s AI model platforms.
In November 2025, OpenAI announced that it was serving more than 1 million businesses worldwide, making it the fastest-growing business platform in history, serving customers including Morgan Stanley, T-Mobile, Target, and more. This included all organizations that actively paid OpenAI for business use, either through ChatGPT for Work or through OpenAI’s developer platform.
OpenAI claimed that its enterprise momentum was fueled in part by consumer adoption. With more than 800 million weekly users already familiar with ChatGPT as of November 2025, adoption and ROI within businesses is enabled by broad consumer awareness and adoption, which causes pilots to be shorter and rollouts to face less friction. ChatGPT for Work, for instance, had more than 7 million total seats in November 2025 (up 40% in just two months). ChatGPT Enterprise seats specifically have grown 9x year-over-year from November 2024 to November 2025.
Strategic Partnerships
In July 2019, after announcing the creation of OpenAI LP, a new “capped-profit” company that allowed OpenAI to raise substantial investment capital, OpenAI announced a partnership with Microsoft. This partnership provided OpenAI with a $1 billion investment from Microsoft and access to Microsoft Azure’s supercomputing capabilities. Microsoft became OpenAI’s exclusive cloud provider, positioning Azure to power all of OpenAI’s training and services. The partnership also includes joint research on supercomputing and a shared safety board for AI safety governance.
In May 2024, OpenAI announced partnerships with major media outlets like The Atlantic, Vox Media, and The Associated Press to license content for model training and enhance ChatGPT with reliable information. In June 2024, OpenAI and Apple announced a partnership to integrate ChatGPT into iOS, macOS, and Siri at no cost to OpenAI. In June 2024, OpenAI and Oracle announced a partnership as an extension of their Azure partnership. Oracle Cloud Infrastructure became an extension of Microsoft’s Azure AI platform to provide additional cloud capacity through extra GPU clusters for OpenAI’s model training and deployment. In 2024, OpenAI generated $3.7 billion in revenue.
In January 2025, OpenAI announced The Stargate Project, a new initiative in collaboration with SoftBank, Oracle, and MGX to invest $500 billion over the next four years in building new AI infrastructure for OpenAI in the United States.
In October 2025, OpenAI and Salesforce announced an expanded strategic collaboration. According to the announcement, Salesforce’s platform (Agentforce 360) will integrate OpenAI’s frontier models (including GPT-5) and allow users to access Salesforce CRM data, build Tableau visualizations, and deploy AI agents directly via ChatGPT. The commerce component (Agentforce Commerce) will also allow merchants to sell to ChatGPT users while maintaining control of data and fulfillment.
Also in October 2025, PayPal and OpenAI announced that PayPal’s digital wallet would be embedded into ChatGPT’s Instant Checkout feature starting in 2026. Users will be able to pay for goods discovered via ChatGPT using PayPal; merchants in PayPal’s network will become discoverable to ChatGPT users. PayPal will also handle multiple funding options (bank, balance, cards), buyer/seller protections, and post-purchase services via the delegated payments API.
Lastly, Walmart also announced a partnership with OpenAI in October 2025 to enable “AI-first shopping experiences” where customers and Sam’s Club members would soon be able to shop directly through ChatGPT using Instant Checkout. The user would simply chat and buy, whether for groceries, household essentials, or new product discovery. Walmart also earlier committed to giving US associates access to OpenAI’s certification program, starting in 2026.
These three October 2025 partnerships collectively demonstrate that OpenAI is making a push into commerce, enterprise workflows, and platform-embedding beyond its core model training and infrastructure deals. With Salesforce, the emphasis is on embedding OpenAI’s models into the enterprise software stack — making AI agents part of business workflows, data analysis, and CRM rather than just a standalone chatbot. With PayPal, the focus shifts to enabling “agentic commerce” — purchases initiated within ChatGPT, payments handled seamlessly via PayPal’s wallet, and merchant networks integrated into the chat interface. With Walmart, the user-facing angle is highlighted: the largest US retailer enabling its massive customer base to shop via ChatGPT and linking everyday commerce into the conversational AI space.
Compute Deals
OpenAI has leveraged an aggressive and unconventional deal-making strategy in an attempt to secure its position in the AI arms race. From June to November 2025, OpenAI signed a cluster of large chip and compute arrangements that lock in multi-year supply and capital:
On September 22nd, 2025, OpenAI and Nvidia announced a systems partnership with Nvidia that targets at least 10 gigawatts of Nvidia-powered data centers and includes Nvidia's intent to invest up to $100 billion into OpenAI as capacity comes online. The first gigawatt is slated for the second half of 2026 on Nvidia's Vera Rubin platform. The structure is staged, with investment tranches tied to actual gigawatt deployment.
Two weeks later, on October 6th, 2025, OpenAI and AMD unveiled a supply partnership centered on six gigawatts of compute using future Instinct parts, with deployment beginning in late 2026. To align incentives, AMD granted OpenAI warrants for up to 160 million AMD shares that vest against compute milestones starting at the first gigawatt. Public filings and coverage emphasize both the capacity goals and the equity-like upside OpenAI can capture if it executes.
On October 13, 2025, OpenAI announced a collaboration with Broadcom to co-develop and deploy 10 gigawatts of custom AI accelerators. Reporting indicates roll-out would begin in the second half of 2026 and will use Broadcom networking inside OpenAI’s custom racks. The Broadcom tie-up sits alongside, rather than replaces, the Nvidia and AMD paths and signals an internal push on custom silicon and systems.
OpenAI also expanded its compute base through very large cloud commitments. In September 2025, the Wall Street Journal reported a roughly $300 billion, multi-year Oracle agreement that Oracle linked to a surge in remaining performance obligations. Days later, OpenAI, Oracle, and SoftBank publicized 5 additional Stargate sites intended to keep a 10-gigawatt buildout on schedule and to support the $500 billion Stargate project. In early November, Reuters reported a seven-year, $38 billion cloud services deal with AWS, OpenAI’s first significant move beyond Azure for primary hosting.
Taken together, these deals give OpenAI an enormous resource moat. The company is locking up future access to tens of gigawatts of AI compute capacity across multiple vendors, at a time when high-end GPUs and data center power are scarce and heavily contested.
Valuation
OpenAI’s valuation has surged to levels that defy traditional comparisons, reflecting extreme optimism about its growth and significant FOMO (fear of missing out) among investors. In October 2025, OpenAI completed an employee secondary, with current and former staff selling about $6.6 billion of stock to investors, including Thrive Capital, SoftBank, Dragoneer, MGX, and T. Rowe Price, at a $500 billion valuation — up from $300 billion post-money in March 2025 following the $40 billion Series F led by SoftBank.
The company appears to be on track to exceed its 2025 ARR projection of $12.7 billion, implying a revenue multiple of almost 40x. For context, this implied multiple is orders of magnitude above established tech peers. Even at the height of the 2023-24 AI frenzy, Nvidia (the leading AI hardware firm) traded around ~24x forward sales, and Meta, a mature tech giant with several key AI plays, was at ~5x sales. Other big-cap tech companies typically trade below ~10x revenue. These figures suggest that investors are valuing OpenAI less like a software company and more like a once-in-a-generation asset that could dominate a future trillion-dollar industry. At a $500 billion valuation, OpenAI shares carry a premium that assumes exponential growth will continue.
The disconnect between OpenAI’s multiples and those of more established companies indicates a speculative fervor. Analysts note that such pricing implies investors are “prepared to invest regardless of how steep the valuation is to avoid the risk of missing out” on AI’s transformative upside. The company has raised enormous sums ($64 billion in primary funding as of August 2025), giving it a large war chest to pursue its ambitions, but new investors are buying in at very high prices. Historical precedents for companies valued on feverish growth expectations often ended with sharp corrections.
More recently, certain high-growth SaaS companies and “unicorns” that reached extreme multiples in 2021 had their values fall dramatically by 2022-23 as interest rates rose and hype cycles normalized. While OpenAI’s case is unique, it is not immune to market physics. If OpenAI fails to meet the aggressive revenue targets baked into its valuation or if competition eats into its market share, a re-rating could occur. A compression from 50x ARR to 20x (still a rich multiple) would, at minimum, halve OpenAI’s implied value.
A large portion of OpenAI’s funding has come from strategic backers like Microsoft (which views it as both an AI supplier and investment) and institutional investors known for aggressive bets (SoftBank, Tiger Global, etc). These players might tolerate higher valuations due to strategic synergies or AI momentum plays. Nvidia's stock surge in 2023-2024 (driven by AI demand) demonstrated how markets can bid up anything AI-related to lofty heights. OpenAI’s valuation ride is a parallel in the private domain.
Still, unlike Nvidia, which sells tangible products with healthy profits at high growth rates, OpenAI is not yet profitable and requires ongoing capital infusion to cover its huge R&D and cloud bills. This reliance on external funding makes OpenAI’s valuation more fragile, as it must keep convincing the market of exceptional future earnings to raise the private capital round or go public successfully.
Any significant stumble, whether a competitor leapfrogging its technology, an unexpected regulatory clampdown, or even a plateau in user growth, could trigger a crisis of confidence and a rapid deflation of OpenAI’s half-trillion-dollar valuation. That valuation reflects lofty expectations of world-changing growth and a premium for being the current category leader, but it stands on tenuous ground. Investors are betting that OpenAI will pull off something historically unprecedented in both adoption and monetization. The upside is immense, but the risks are equally stark, as even a modest shortfall from investor expectations could trigger significant downside.
Key Opportunities
Monetizing the Consumer User Base
OpenAI can further monetize its enormous user base (hundreds of millions of free users) through new revenue streams beyond the standard $20/month subscriptions. The company itself projects that by 2029, about $25 billion/year of its revenue could come from monetizing free users in novel ways.
OpenAI’s strategic partnerships with PayPal and Walmart position it to monetize its consumer user base more directly through economic activity rather than solely through subscriptions. By embedding commerce functionality into ChatGPT via Instant Checkout and connections to large merchant networks, OpenAI can participate in transaction flows where it historically captured only attention or intent. In a mature state, this could support revenue from referral or affiliate fees, revenue sharing on completed transactions, and potentially per-transaction platform fees, especially when users move from simple queries such as “find a product” to full task delegation such as “plan and purchase everything for a week of meals.”
Additionally, OpenAI could introduce premium services for consumers, higher tiers of ChatGPT with specialized skills or exclusive plugins at higher price points (the company already has a $20 tier and a $200 “Pro” tier for power users). There is also discussion of platform fees or an app store model if third-party developers sell ChatGPT plugins or extensions. As OpenAI’s users comprise one of the largest engaged audiences in tech, even small ARPU (average revenue per user) increases would yield billions in new revenue.
However, if users begin to feel that ChatGPT is steering answers for profit or cluttering the experience with product pitches, the tool could lose trust and appeal. OpenAI will need to implement monetization in a way that doesn’t undermine the user-centric value, as history has shown that once-neutral platforms can alienate users when aggressively commercialized.
Hardware and Proprietary AI Chips
OpenAI could benefit its underlying economics by developing its own AI hardware and vertically integrating. Currently, OpenAI’s products rely on third-party chips (predominantly Nvidia GPUs) and cloud infrastructure (Microsoft’s Azure). This dependency is costly and potentially limiting, as GPU shortages or price hikes can bottleneck OpenAI’s growth.
In 2025, OpenAI proposed the idea of making AI chips in-house, and reports indicate the company is investing in customer AI chips. If OpenAI can design specialized AI accelerators optimized for its models, it could both reduce inference costs (improving margins) and gain more control over its tech stack. This strategy would be similar to how Google developed TPUs for its own AI needs. In addition to chips, OpenAI is exploring consumer hardware devices through collaboration with former Apple designer Jony Ive on an AI gadget. Such a device might be a consumer product that seamlessly delivers OpenAI’s AI assistant capabilities in daily life.
OpenAI’s long-term vision also includes robotics. CEO Sam Altman has hinted at robotics as a field where physical AI could be deployed, and OpenAI has done research on robotic hand manipulation in the past. While not a core business yet, future offerings where OpenAI’s AI controls physical robots or automation systems (for example, in warehouses or home use) could grow into substantial businesses if successful.
The opportunities in hardware overall are significant. Custom chips could both cut costs and be sold to others as a new revenue line. An AI consumer device could create a new product category (much like the iPhone did for mobile computing), and robotics integration could open markets in manufacturing and services.
However, the risks are equally high. Building consumer hardware is capital-intensive and out of OpenAI’s traditional software expertise. Chip design and consumer electronics have even longer development cycles and high failure rates. OpenAI will also face extremely high competition with entrenched chipmakers like Nvidia or device giants like Apple. Moreover, any hardware venture would likely require even more funding, testing investor patience. While hardware could be a game-changer that solidifies OpenAI’s physical infrastructure independence, it could also become an expensive distraction if not executed well.
Compute Tie-up as Defensible Moat
For OpenAI, tying up compute and interlocking supply arrangements before its competitors do could create operating leverage that creates a defensible position in the market. Compute is increasingly a zero-sum input. High-end accelerators and power are constrained, so every incremental block of capacity OpenAI secures reduces what rivals can access in the same time window. That concentration changes competitive dynamics and amplifies industry-level risk if OpenAI fails to convert capacity into durable model leadership and profitable usage.
Tying up supply with Nvidia, hyperscalers, and other chip partners increases the probability that OpenAI can sustain the largest training runs, iterate faster, and hold a visible performance gap. If scarcity worsens, the advantage compounds, because quality gains from larger, better-scheduled training runs often outpace what smaller or delayed cohorts can achieve. Additionally, preferential access increases training cadence, reduces scheduling friction, and raises the ceiling on model size and context length, which can translate into higher win rates in enterprise evaluations and better retention for consumer products. It also improves bargaining power with distribution partners, because OpenAI can credibly commit to road maps that require sustained access to next-generation hardware.
Finally, the tie-up strategy also has a capital markets angle. When suppliers co-invest or provide capacity against take-or-pay and other structured contracts, OpenAI’s effective cost of capital can drop, and its optionality can rise. That can support larger model bets without proportional equity dilution and can accelerate ecosystem lock-in around OpenAI tooling. For example, the Wall Street Journal’s framing of counterparties “tethered” to OpenAI captures why this reduces supply risk in the base case and why it lengthens the company’s planning horizon for product launches, enterprise migrations, and commerce integrations.
On balance, the current environment creates asymmetric potential for OpenAI. Scarcity makes supply capture unusually valuable and, if maintained, it can translate into measurable lead indicators such as higher inference share, faster enterprise conversion, and stronger downstream economics. The same scarcity raises the stakes, which is why credible evidence of sustained demand, clear monetization paths, and disciplined capital deployment will be the key signals to watch as these large commitments roll into service through 2026 and beyond.
Key Risks
Industry Risks
Regulatory Uncertainty and Compliance Pressure
OpenAI faces a rapidly evolving regulatory landscape as governments worldwide react to the rapid development of AI. New regulations, such as the European Union’s AI Act, which was enacted in May 2024, combined with national regulatory frameworks, could impose stringent requirements on model transparency, data usage, privacy, and safety. Regulatory pressure is mounting giving the growing public concern about AI’s potential misuse, high-profile incidents of harmful AI outputs, and global regulatory fragmentation - with different legislative jurisdictions in countries like the United States, Europe, China, crafting distinct AI legislation.
In February 2025, OpenAI CEO Sam Altman warned that overly restrictive regulations could limit or slow AI development. Indeed, this situation has already played out in certain countries. In April 2023, Italy temporarily banned ChatGPT over a suspected breach of privacy rules. In December 2024, Italy fined OpenAI €15 million for violating GDPR.
Regulatory risk could lead to costly compliance burdens, potential fines, and market access restrictions if OpenAI is unable to meet local requirements. Even if OpenAI can meet new safety checks and audit data sources to meet compliance standards, regulatory pressure could also lead to slower rollout of new features or models due to the need for legal review and safety testing before release.
Geopolitical Dynamics
Geopolitical risk encompasses both competitive threats from outside the United States and potential government actions at home in response to geopolitical tensions. The development of AI is a strategic priority for global world powers, and OpenAI is caught in the middle of this geopolitical competition. US-China tensions are particularly impactful to OpenAI as they have led to export controls on advanced chips, as Contrary Research has covered in depth, and restrictions on research collaboration.
Some analysts argue that OpenAI is already “losing ground” to rivals, like DeepSeek, backed with significant state support, who could overtake OpenAI in global markets where US companies face access barriers. Geopolitical splits might force OpenAI to operate separate, siloed services in different regions, limiting its global scale. Geopolitical conflict could also disrupt OpenAI’s supply chain and curb the availability of AI hardware. Reduced access to international talent due to visa/trade restrictions could also hamper OpenAI’s ability to recruit top researchers to advance model performance.
Data Center Lifetime and Write-Down Cycle
Advanced AI accelerators are wearing out and becoming obsolete much faster than traditional data-center gear. Analysts estimate the useful life of cutting-edge AI chips is shrinking to five years or less, forcing companies to write down hardware faster and replace it sooner to stay competitive. Each new generation chip — H100 to H200 to GB200 and beyond — delivers such large performance and efficiency gains that three-year-old chips can be economically uncompetitive even if they still function. In practice, that means a GPU cluster behaves more like a short-duration financial asset since companies only get a few years of SOTA performance before being forced to accept structurally worse unit economics or incur another round of capex and write-downs. If those few years are not spent running high-value, high-margin workloads at high utilization, the return on that hardware can fall below what investors expect.
That dynamic is particularly acute for OpenAI because of the sheer scale and pace of its build-out. In 2025, the company has committed to more than $1 trillion of compute and cloud deals with partners such as Nvidia, AMD, Oracle, CoreWeave, and AWS, securing around 30 gigawatts of capacity over the next decade, far in excess of its current revenue base of $13 billion (projected for 2025). One September 2025 report, looking at the sector as a whole, estimated that AI providers will need roughly $2 trillion of annual revenue by 2030 to sustain data-center capex and energy costs for around 100 gigawatts of AI power, implying a large industry-wide revenue gap even before factoring in OpenAI’s particularly aggressive plans. Altogether, this means every cohort of hardware OpenAI brings online has to be filled quickly with paying, economically attractive workloads to earn back its cost before the next generation makes it obsolete.
Company Risks
Governance Model and Mission Alignment
OpenAI’s internal structure and governance present a risk to its stability. Managing OpenAI’s hybrid model between its roots as a non-profit and its capped-return for-profit arm introduces tensions between its initial altruistic mission to ensure AI benefits humanity and its commercial pressures to attract capital to scale model development. If OpenAI doesn’t convert entirely to a for-profit entity by December 2025, it could lose $10 billion of pledged funding from Softbank. If it doesn’t convert to a for-profit entity by October 2026, previous investors could claw back up to $6.6 billion of investments with interest.
OpenAI’s governance structure is not just a legal challenge, but also a cultural one. OpenAI was founded with the mission of ensuring AI is developed with long-term safety and the prioritization of humanity in mind. While converting to an entirely for-profit structure would sate investors and potentially draw in more capital, it could alienate early and influential employees who joined for the mission. Indeed, influential figures, such as Ilya Sutskever and Jan Leike, in OpenAI’s founding history have already left the company, citing concerns about the deprioritization of AI safety versus rapid product development.
Infrastructure Scaling and Cost Challenges
OpenAI faces an immediate risk from the difficulty of scaling its infrastructure and finances to meet demand. The success of consumer and enterprise products like ChatGPT and OpenAI’s API platform has led to explosive user growth. In February 2025, OpenAI had 400 million active users across all products, with 2 million paying enterprise users. Supporting hundreds of millions of users requires an ever-expanding fleet of expensive hardware running at all hours of the day. In 2024, OpenAI spent $9 billion on operations, leading to a $5 billion loss that year. Negative cash flow on that magnitude is difficult to sustain long-term without continuous capital injections.
Furthermore, there are physical constraints to OpenAI’s pace of growth. There is limited space for data centers, limited electricity, cooling, and availability of cutting-edge hardware. In February 2025, CEO Sam Altman announced that OpenAI had to stagger the release of GPT 4.5 due to GPU shortages. If user demand continues to outpace infrastructure growth, OpenAI could hit a wall where it must throttle usage or see performance suffer. Furthermore, as models get more complex, the computational cost per request might increase, exacerbating the problem. The dual challenges of scaling up infrastructure and covering the massive costs to operationalize its models may pose a substantial risk to OpenAI if managed improperly.
Scale and Circularity of Deals
OpenAI’s mega deals with AMD, Nvidia, Broadcom, and others give it an enormous resource moat. Aligning with Nvidia, AMD, and Broadcom secures a pipeline of cutting-edge chips; aligning with Oracle, CoreWeave, and AWS ensures those chips are integrated into large-scale, purpose-built infrastructure. By negotiating equity options and cross-investments, OpenAI also tightly couples its success to that of its suppliers, which gives those suppliers strong incentives to prioritize OpenAI over rival customers. From a strategic perspective, this cluster of agreements reduces supply risk, strengthens OpenAI’s bargaining power with any single vendor, and supports the narrative that OpenAI is planning not millions but trillions of dollars of AI infrastructure over the next decade.
However, this setup also comes with risks. First, the scale is unprecedented: the company’s cloud commitments and multi-gigawatt chip deals are worth $1 trillion altogether, much of which does not begin delivering hardware until 2026 or later, and OpenAI's revenues at the time of the commitments were far smaller. Analysts, therefore, worry about execution risk. OpenAI must grow its user base and enterprise adoption fast enough to keep these data centers full and profitable.
Second, some of the financing is circular in nature. Nvidia has committed up to $100 billion to OpenAI, which plans to spend that money on Nvidia systems; Oracle’s cloud growth is driven disproportionately by a single $300 billion contract; CoreWeave’s orders are intertwined with Nvidia financing and take-or-pay chip purchases. This raises questions about how much of the demand is organic versus engineered, and whether revenues and valuations in the ecosystem are being propped up by interdependent contracts.
Third, OpenAI is concentrating a lot of its commitments into a small set of suppliers and in a very specific technological trajectory. If AI model architectures change in ways that reduce GPU intensity, if regulatory constraints slow large-scale deployment, or if power and grid planning do not keep up with 20-plus gigawatts of new load, these long-dated commitments could become a drag rather than a moat.
Summary
OpenAI is a San Francisco–based AI lab and platform company founded in 2015, best known for ChatGPT, the GPT model family, DALL·E, and, more recently, Sora. OpenAI reached roughly $13 billion in annualized revenue by July 2025, up from about $4 billion in 2024, with weekly active users growing to around 800 million and paying business users surpassing 5 million. This makes OpenAI one of the fastest-scaling software businesses in history, but also a highly unusual one. It began as a nonprofit, then adopted a capped-profit structure, and is in the middle of a complex recapitalization into a public benefit corporation while its controlling nonprofit remains under scrutiny from the California attorney general and other stakeholders.
The core of the business is ChatGPT and adjacent subscriptions. Consumer and business subscriptions (ChatGPT Plus, Pro, Team, Enterprise) account for the majority of revenue, with API and licensing contributing perhaps 15–20%. In October 2025, it was reported that 70% of OpenAI’s $13 billion in annual revenue was coming from users paying $20/month, although only 5% of ChatGPT’s 800 million regular users were paying subscribers. This revenue is complemented by a growing enterprise base and deep integrations into other products, from Microsoft and Apple at the platform layer to Salesforce and various SaaS tools in the enterprise stack.
Under the hood, OpenAI is increasingly an infrastructure company. Through the Stargate initiative and a web of contracts with Oracle, CoreWeave, AWS, NVIDIA, AMD and Broadcom, OpenAI has committed to tens of gigawatts of AI data-center capacity and more than a trillion dollars of implied long-term compute and chip spend, including a $500 billion, four-year plan to build 10 GW in the US alone and a $300 billion cloud contract with Oracle that begins in 2027. Those deals create a powerful moat in a world where GPUs and power are scarce: they secure preferential access to the inputs needed to train and serve frontier models and tie key suppliers’ fortunes to OpenAI’s success. They also raise the stakes. AI accelerators now have short economic lifetimes, and OpenAI expects compute and technical talent to consume roughly 75% of its revenue through 2030, which means utilization, pricing, and product-market fit must keep up with an aggressive capex and refresh cycle.
Governance is another defining feature of the company. In November 2023, OpenAI’s nonprofit board abruptly ousted CEO Sam Altman for not being “consistently candid,” triggering a near-total employee revolt and intervention from Microsoft; Altman was reinstated within days, and the board was reconstituted with more industry-friendly members. Since then, OpenAI has faced lawsuits from co-founder Elon Musk and formal inquiries from California’s attorney general over whether its shift toward a more conventional for-profit structure is compatible with its original charitable mission and nonprofit tax status. The recapitalization into a PBC controlled by a nonprofit is an attempt to square that circle, namely, to preserve mission language and oversight while enabling the scale of capital required for trillion-dollar infrastructure bets.
Taken together, OpenAI is best understood as a high-growth, high-burn AI platform making a very large, very leveraged bet on being the default interface and infrastructure layer for intelligent software. OpenAI has achieved genuine product-market fit at a global scale but is operating at the edge of what today’s capital markets and governance models can comfortably support. Its upside depends on sustaining subscription and enterprise growth, monetizing new surfaces such as agents and commerce, and turning its locked-up compute into a durable advantage. Its downside risk sits in the same place: if model economics, regulation, or competition undercut that growth, the very scale of its infrastructure and financial commitments could turn into a drag rather than a moat.
*Contrary is an investor in Ramp and Replit through one or more affiliates.
