
Despite $5 trillion in planned AI infrastructure spending between 2025 and 2030 and rapid model improvement against technical benchmarks, adoption of AI by the general public is plateauing. Enterprise AI usage fell from 46% to 37% between June and September 2025, and 42% of enterprise AI initiatives were discontinued in 2025, compared to only 17% in 2024. Failure to retain enterprise users has been driven largely by the lack of differentiation between products built on increasingly commoditized APIs. As foundation models become interchangeable, defensible value is shifting to specialized systems embedded in real workflows, interfacing with proprietary data, and enabled at the inference layer where general-purpose tools fall short.
Foundation Model Market
As of January 2026, the foundation model market is consolidating around a handful of players with the resources to compete at the cutting edge of state-of-the-art model development. Building and maintaining these language models requires magnitudes of capital, compute, and data that preclude competition from all but the most well-resourced organizations. This concentration is evident in both cost structures and market share. OpenAI’s GPT-4 model training required approximately $78 million in compute resources alone, while Google’s Gemini Ultra reached an estimated $191 million. As of September 2025, AI and ML training costs have increased by more than 4,300% since 2020.
Only a handful of organizations can sustain this level of investment. As of January 2025, the market for foundation models is dominated by OpenAI, Google DeepMind, Anthropic, and Meta. For enterprise LLM API usage specifically, market share data demonstrates usage clustering among the top providers, with a long tail of other providers, including DeepSeek and smaller labs, holding single-digit shares.
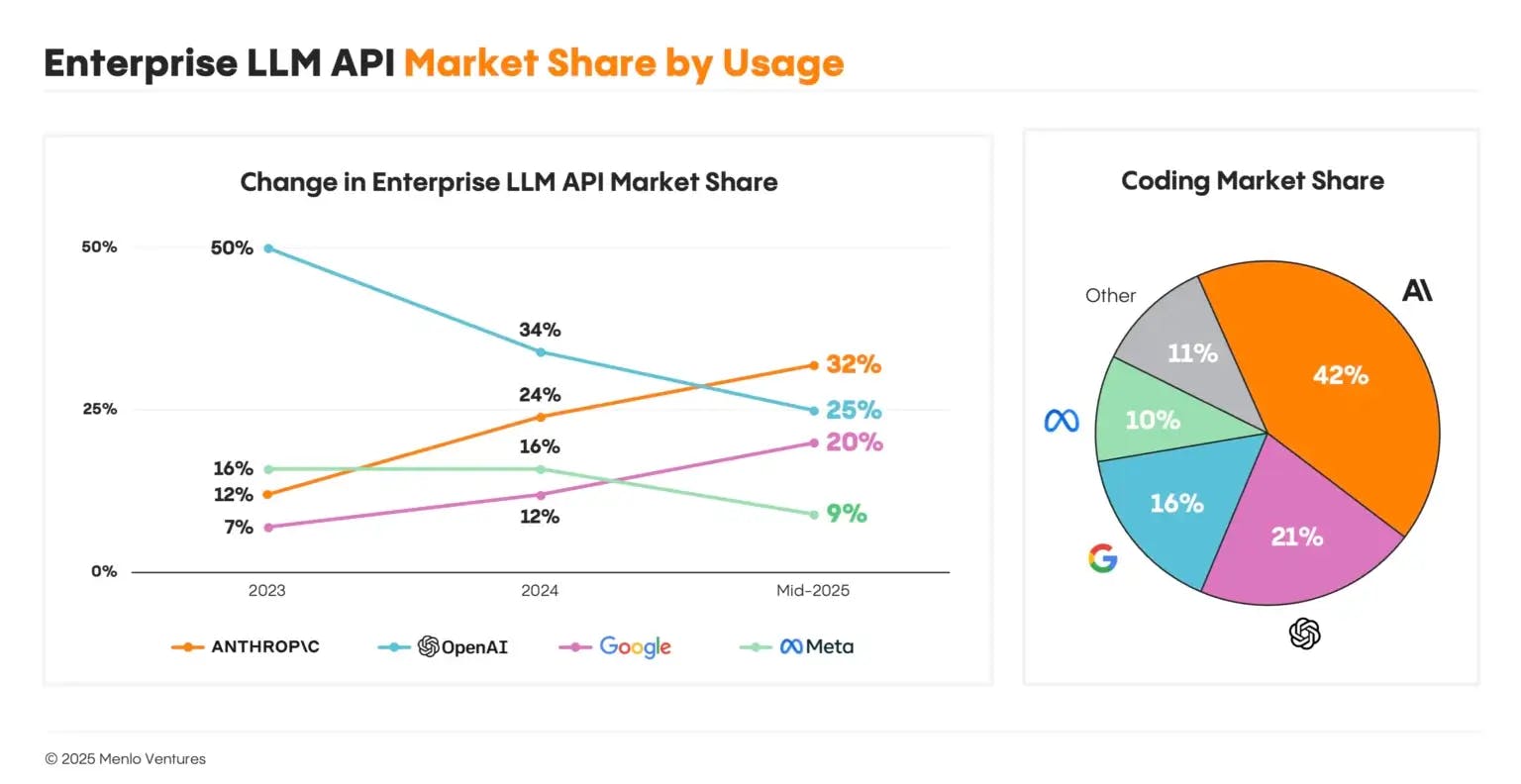
Source: Menlo Ventures
As a result, smaller players are structurally unable to compete on generality. Instead of differentiating on model capability, they are pushed toward consuming the same few APIs or open models as everyone else. The market outcome is a proliferation of undifferentiated products: the overwhelming majority of AI companies become wrappers, or thin user interfaces built on top of the APIs of OpenAI, Anthropic, and other foundational model providers with minimal proprietary modeling or data.
This convergence is visible in product design. Many converge on similar horizontal features like chat interfaces, summarization, rewriting, and generic copilots because the underlying capability is the same commodity input. In one documented example, 73 PDF chat wrapper companies launched in the same week, all offering functionally identical products. This dynamic, described as “prompt glorification,” creates the illusion that clever prompting alone constitutes a defensible business. When everyone has access to the same models, prompts, and APIs, competitive differentiation rapidly collapses, and the gap between technical capability and realized business value becomes increasingly visible.
Commoditization of LLMs
When a small number of vendors compete at the capability frontier, they also compete on pricing primitives, access patterns, and integration workflows. This reduces costs and the amount of time necessary to ship AI-enabled products to consumers, lowering barriers to entry for startups building off of these products, and encouraging fast follower behavior among those startups. Put differently, concentration at the frontier can accelerate commoditization everywhere else.
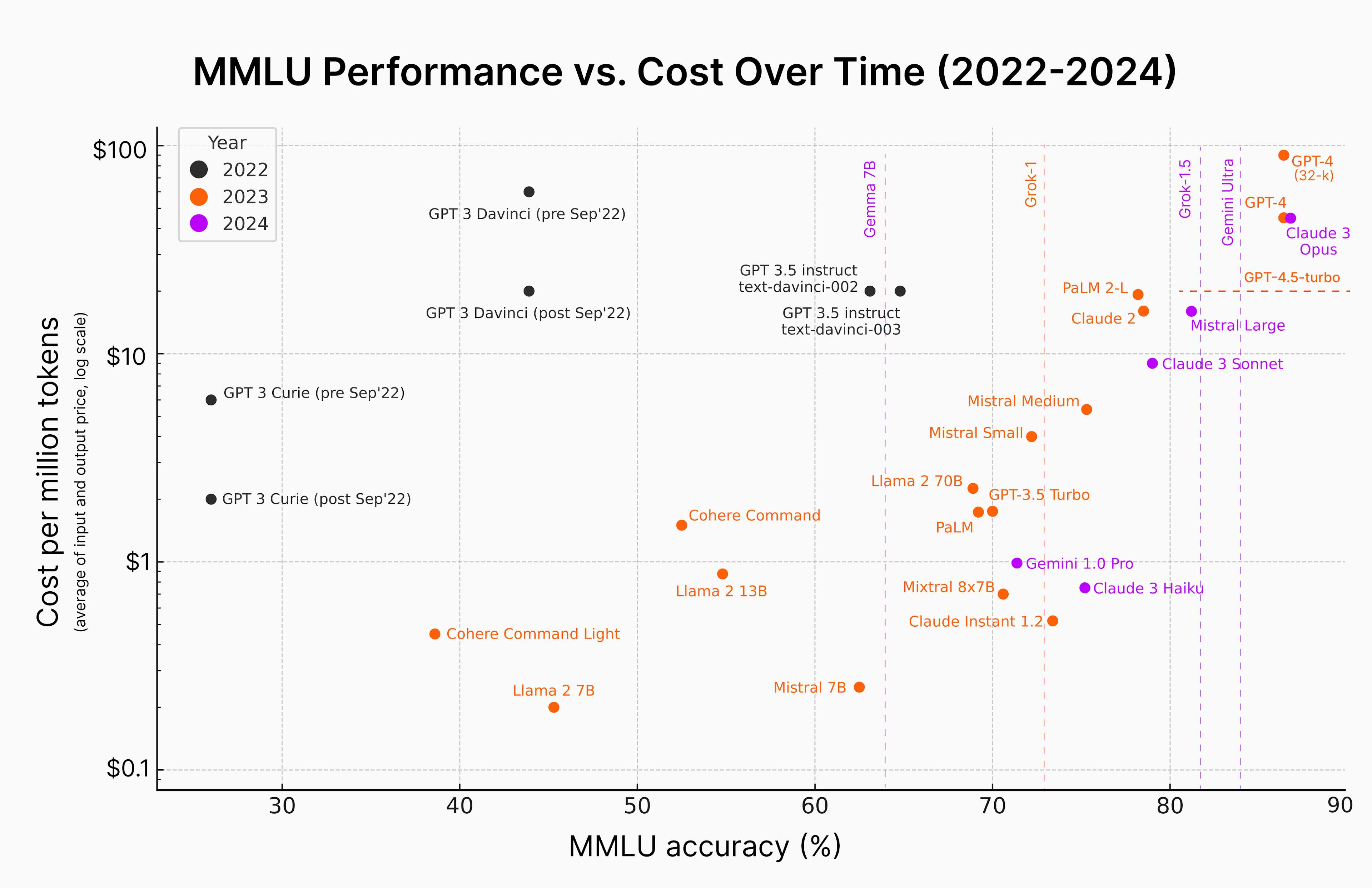
Source: semaphore
Low-cost tokenized APIs illustrate this effect, making frontier intelligence a metered input cost and enabling small teams to create credible products without training models themselves. OpenAI's API pricing structure illustrates how platform economics significantly reduce barriers to entry. For instance, the GPT-4.1 nano model costs only $0.10 per 1 million input tokens, with a minimal $5 credit purchase requirement.
Leading open-source models further reinforce this dynamic. As of January 2025, the top 10 foundation models (both open and proprietary) cluster within five percentage points on common benchmarks such as MMLU, GPQA, and HumanEval. As open-source models improve and collectively converge on quality, teams can switch between providers, self-host models as required by costs or privacy, and replicate baseline capabilities of state-of-the-art proprietary models. In effect, “general LLM capability” starts to behave like a commodity. Early commoditization is already visible at the application layer, where products are cheap to build and copy.
General AI Adoption Plateaus
Despite aggressive investment and rapid technical progress, adoption of general-purpose AI tools has begun to plateau, particularly in enterprise settings. In September 2025, 37% of Americans used generative AI at work, down from 46% in June 2025.
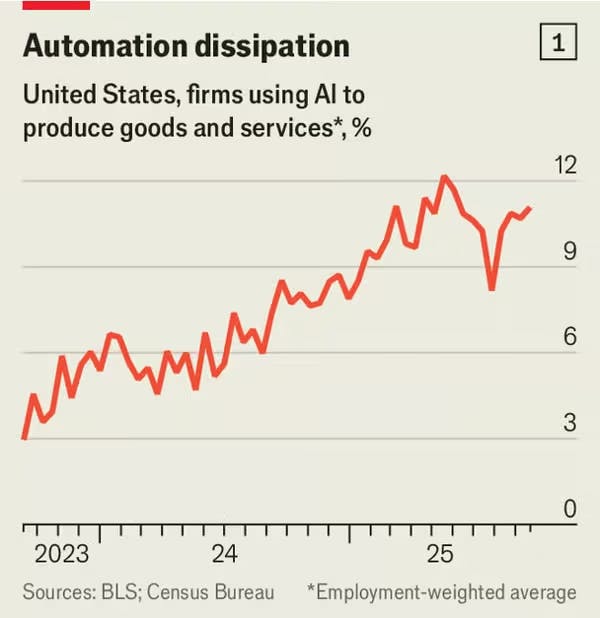
Source: The Economist
Adoption has fallen most dramatically at large businesses, where pressure from shareholders to adopt AI made early adoption most popular. These same companies have higher integration costs and more complex workflows, poorly suited to generic tools. Only 11% of major enterprises have deployed GenAI at scale across business units.
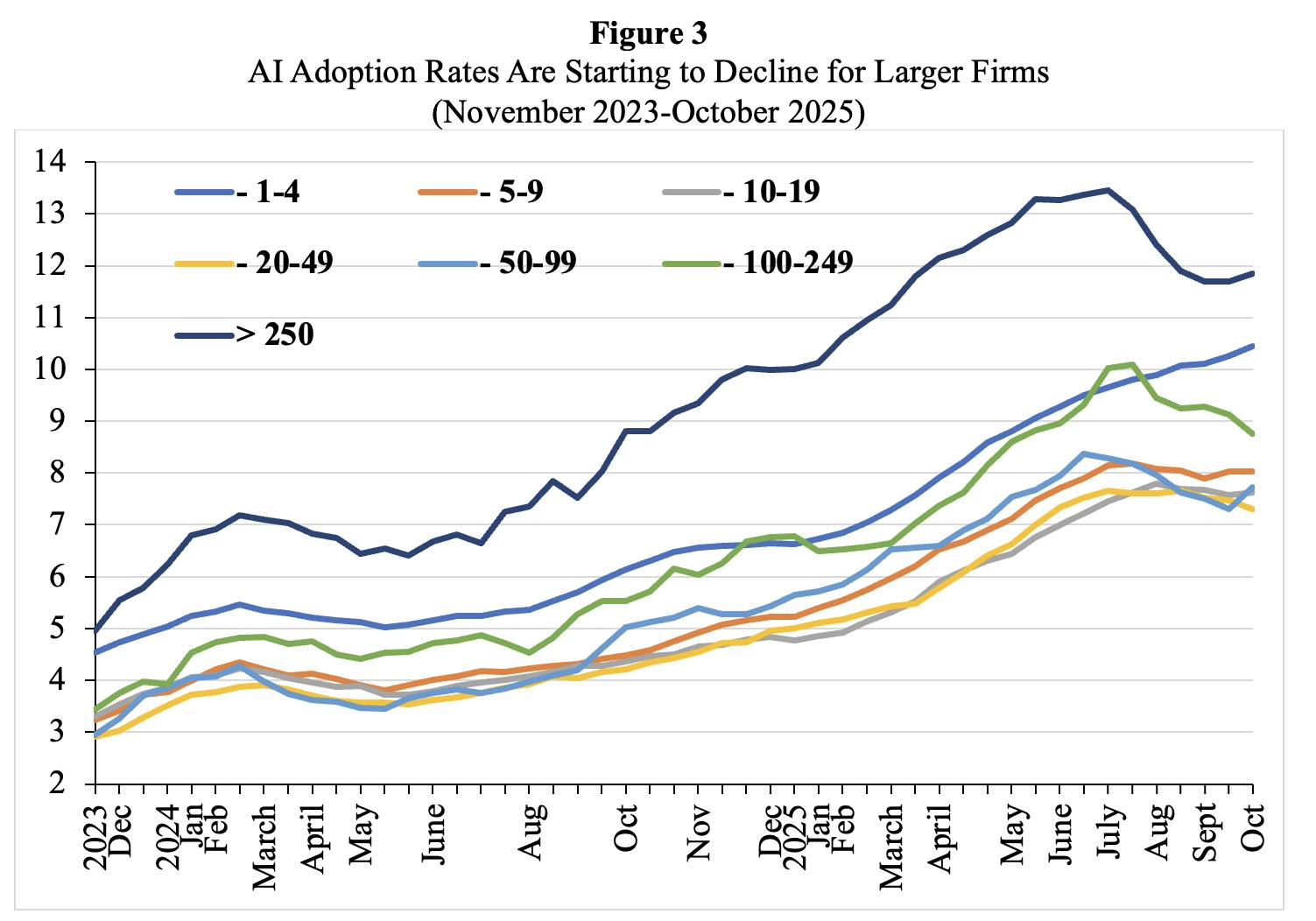
Source: INET Economics
AI optimists point to the absence of AI systems tightly embedded into real operational workflows as the driver of this gap, rather than insufficient model capabilities. However, there are counter indicators: for example, Amazon employees have described outputs from internal AI tools as “slop.” Studies of AI-generated and AI-assisted code have shown that AI contributions increase software bugs and instability. This pattern is consistent with tools that are easy to demo but hard to build into workflows. Across the board, there is a general gap between the hype and realized productivity for these types of tools: 45% of enterprise executives reported returns below expectations, while only 10% reported exceeding them.
Capital in the AI investment cycle has been overwhelmingly concentrated at the extremes of the stack: massive investment at the foundation model layer, and a proliferation of lightweight application “wrappers” built on top. Between 2026 and 2030, hyperscalers and frontier AI labs plan to spend $5 trillion on infrastructure to enable AI services. Justifying this level of investment will require some $650 billion a year in AI revenues, an increase from (loss-making) AI revenues of $50 billion a year today. This dynamic has been compared to the dot-com era, when capital flooded into telecom infrastructure ahead of real demand, triggering a wave of bankruptcies when adoption lagged. The failure was not the internet itself, but the timing and allocation of capital relative to value creation.
Lessons from Cloud Infrastructure
The cloud market sets one precedent for how platform markets can evolve. As the market shifts from innovation to consolidation to commoditization, value migrates to specialized layers sitting on top of the infrastructure layer.
Similar to the high cost of building frontier-scale LLMs, cloud infrastructure demands significant capital expenditures for data centers, networking, and specialized hardware, creating structural barriers that lock out most competitors. For the most part, smaller providers tend to survive by specializing in certain regions (e.g., Alibaba in China) or narrow customer segments (e.g., DigitalOcean for developers).
Today’s cloud infrastructure market is highly concentrated. As of Q2 2025, AWS controls about 30% of the global cloud infrastructure market, Microsoft Azure holds 20%, and Google Cloud accounts for 13%. Together, the “Big Three” control roughly 63% of a nearly $100 billion quarterly market, while no other provider has more than 4% individually. While dozens of other credible infrastructure providers exist, such as Alibaba, IBM, Oracle, Rackspace, DigitalOcean, OVH, and Tencent, true global scale has been achieved by only a small number of hyperscalers.
Crucially, the primary enduring value in cloud computing did not remain at the infrastructure layer. While AWS, Azure, and Google Cloud became foundational utilities, the largest and most defensible businesses emerged higher in the stack. Companies like Snowflake, Databricks, and Stripe captured value by building specialized data, analytics, and payments platforms that embedded deeply into customer workflows and specific use cases. Furthermore, both Snowflake and Databricks benefit from high switching costs and network effects once organizations centralize their data and processing on these platforms, which makes displacement difficult.
Source: Public Comps
The AI market is beginning to mirror this same structural pattern. As the foundation model layer concentrates among a small number of hyperscale providers, general-purpose LLMs increasingly function as infrastructure rather than differentiated products. This shift creates the conditions for value to move upward, but it also exposes a critical mismatch in how capital has been deployed. The central question becomes where value can be captured as general-purpose AI fails to meaningfully reshape real workflows.
Where Specialization Begins
As the model layer converges and commoditizes, the opportunity for value creation moves up to the inference layer, where models are constrained, structured, and embedded into domain-specific workflows.
Hugging Face co-founder and CEO Clem Delangue argues LLMs are not the right solution for everything, and more specialized systems will see increasing adoption. This view reflects a broader structural reality: general-purpose LLMs are optimized for breadth, while most enterprise use cases demand depth. As a result, specialization increasingly begins at the inference layer, where general models are adapted into narrow, high-confidence systems aligned with real operational constraints.
Specialization in inference is achieved by constraining how models are trained and how they generate results, with structured inputs, constrained prompts, and verified outputs enforced by techniques such as constrained decoding. By limiting output generation to tokens that conform to predefined schemas, constrained decoding transforms probabilistic text generation into a predictable system component. These constraints improve output stability and trustworthiness while increasing inference efficiency. More importantly, it allows logic, schemas, and domain rules to be encoded directly into system architecture, producing reliable behavior through narrow, domain-aligned inference.
This approach addresses the fundamental discrepancy with model application, as most enterprise tasks are not open-ended language problems and require precision, repeatability, and trust. In healthcare, for example, models must accurately interpret clinical terminology, diagnostic codes, and complex medical relationships to be clinically useful. Across fields including healthcare, finance, legal, and software engineering, specialized models consistently outperform general-purpose LLMs on domain-specific benchmarks. These performance improvements originate from fine-tuning on proprietary data and aligning inference-time behavior with the reasoning patterns, technical terminology, and constraints of professional workflows.
Source: Lightspeed
Real-world deployments illustrate this pattern:
Legal: Harvey AI built the first custom-trained case law models in collaboration with OpenAI. Harvey uses between 30 and 1.5K model calls per query, decomposing legal tasks into structured subtasks including retrieval, citation grounding, and jurisdiction-specific reasoning. This ensures complete context, starting with case law from Delaware, and then expanding to include all of US case law. Lawyers preferred Harvey’s outputs to those of GPT-4 97% of the time in surveys with major law firms. The Harvey Assistant, Harvey’s user interface for law tasks, achieved the highest scores in five of six benchmarked tasks, including a 94.8% accuracy rate for document question answering.
Medical: Med-PaLM 2 achieved 86.5% accuracy on MedQA (USMLE) benchmark using ensemble refinement, making it the First AI system to surpass the pass mark (60%) on US Medical Licensing Examination style questions. Med-PaLM 2 uses a specialized prompting strategy where the model conditions on multiple possible reasoning paths it generates, then refines and improves its answer, leading to significantly lower rates of possible harm from incorrect or irrelevant information compared to general models. Specialized medical models retain advantages in deployment scenarios requiring on-premise hosting, HIPAA compliance, lower inference costs for high-volume use cases, and embedded medical safety guardrails.
Where Defensibility Emerges
Domain Moats
Real moats form at the workflow level through integration depth, embedded domain heuristics, and trust and safety mechanisms built into the user experience. In practice, workflow redesign means restructuring how work is executed end-to-end, such as automating handoffs, embedding decision logic, and shifting AI from an assistive tool to a system that directly orchestrates tasks.
Among 25 AI success factors, workflow redesign correlates most strongly with EBIT impact. While only 21% of organizations have significantly redesigned workflows for AI, high performers (6% of orgs with 5%+ EBIT from AI) are three times more likely to fundamentally redesign workflows rather than overlaying AI. Agentic AI may have the potential to accelerate business processes by 30% to 50%, but these benefits can be realized only when AI-first execution is embedded directly into operations. Companies that solve this integration challenge build defensible positions that thin wrappers cannot replicate.
Workflow depth compounds with user experience to form a second layer of moat. Here, UX operationalizes domain judgment by constraining choices and guiding users toward correct actions. Vendors with deep domain expertise can translate that judgment into interfaces, defaults, and decision flows that function as expert systems rather than generic tools.
This is why successful vertical AI products resemble purpose-built systems, such as an electronic medical record that automatically drafts visit notes, rather than a standalone chat interface. Vertical systems also benefit from natural customizability: because they are designed for a single industry, they require minimal configuration to deliver value, while horizontal tools often demand extensive integration and adaptation. Over time, these workflow and UX choices create higher switching costs and position vendors as strategic partners rather than interchangeable software providers.
Proprietary Data Advantages
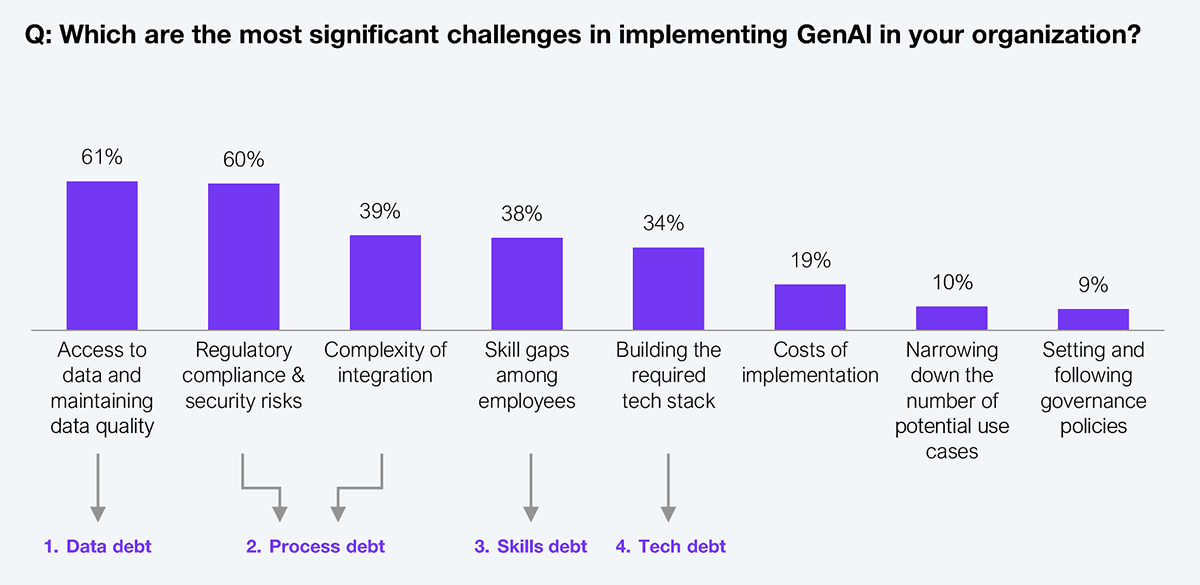
Proprietary data represents the most durable long-term moat in AI. Proprietary data has been described as “the new gold” for AI companies because domain-specific, non-public data enables models that consistently outperform generic systems trained only on web-scale text. In healthcare, providers fine-tune models on internal patient records and claims data, achieving faster and more accurate diagnoses than general-purpose systems. A survey of 550 executives found “access to data and maintaining data quality” as the most common challenge in implementing generative AI.
Source: HFS Research
Some players extend this advantage by building data ecosystems that connect consumers, partners, and institutions, allowing behavioral and transactional data to compound over time. For example, financial technology companies such as MoneyLion have focused on this ecosystem business, where their data can be used to train powerful AI models for financial applications. Security and compliance requirements further reinforce this dynamic in regulated industries such as healthcare, finance, and defense, pushing enterprises toward vertical AI providers that can guarantee data isolation, auditability, and policy enforcement.
Over time, this advantage compounds. Once a company owns domain-specific data and schemas, it encodes them into retrieval systems, structured outputs, and business-logic constraints. Each additional interaction enriches the underlying data, improving model performance and reinforcing switching costs. As a result, every inference call is grounded in proprietary context, making even commoditized foundation models behave like specialized systems that competitors cannot replicate.
Looking forward, specialization is not the only path for AI, but it is the defensible one. As models continue to improve and commoditize, competitive advantage will not come from access to intelligence, but from how precisely it is shaped, constrained, and embedded into real-world systems. In this regime, progress favors depth over breadth, and value accrues to those willing to build where scale alone cannot reach.






