
Actionable Summary
As technologists attempted to make artificial intelligence a reality, machine learning and data science rose to prominence as incremental progress. As Moore’s Law progressed and the internet brought about the age of “big data”, the stage began to be set for the acceleration of AI capabilities.
In 2015, OpenAI was founded as a non-profit with a focus on building AI for everyone. As OpenAI’s research progressed, the company’s emphasis increasingly became focused on artificial general intelligence (AGI).
In March 2017, OpenAI’s leadership decided the company’s non-profit status was no longer feasible if it was going to make real strides towards AGI, and made the switch from a non-profit to a capped profit company.
In January 2020, OpenAI researcher and Johns Hopkins professor Jared Kaplan and others published "Scaling Laws for Neural Language Models.” The importance of compute and scale became front and center to the progression of OpenAI’s models.
That same appetite for compute led to OpenAI eventually raising billions from Microsoft to gain priority access to Azure.
When OpenAI published its charter in April 2018, the company touted its focus on avoiding work that would “unduly concentrate power.” However, after the move away from being non-profit and the subsequent Microsoft deal, members of the AI community expressed their issues with OpenAI’s position of becoming increasingly closed.
OpenAI’s shift in philosophy from open source to more closed off caused philosophical fractures between proponents of open source and OpenAI. That same conflict also led to groups spinning out of OpenAI in an attempt to be more open.
Most notably, Dario Amodei, former VP of Research at OpenAI, left to start his own company, Anthropic. In the process he took 14 researchers with him, including OpenAI’s former policy lead Jack Clark. While Amodei left OpenAI in December 2020, it’s been reported that “the schism followed differences over [OpenAI]’s direction after it took a landmark $1 billion investment from Microsoft in 2019.”
The other end of the philosophical spectrum from OpenAI has espoused principles of openness, with companies including Stability with Stable Diffusion, and EleutherAI. However, many of the vocal proponents of open source were far from open source purists, and instead had a habit of taking advantage of open source technology for their own gain, or hiding behind AI safety as a way to control the underlying technology.
A number of people have argued for the need to better address issues in AI including misinformation, bias, intellectual property violations, and data privacy. However, a number of companies have used these issues as a way to close off their technology, citing safety concerns as a key obstacle to remaining open.
While this happens in the name of “AI safety,” it is often due to the need for competitive differentiation. Ilya Sutskever, OpenAI’s chief scientist and co-founder, has said as much about OpenAI’s decision to close off GPT-4: “On the competitive landscape front — it’s competitive out there. GPT-4 is not easy to develop.”
But as larger players close up to protect themselves competitively, they also increase the amount of power they collect for themselves. Clement Delangue, the CEO of Hugging Face, and Amjad Masad, the CEO of Replit, had a conversation on the biggest risks facing AI. Clement described the danger this way: “Personally I think the main risk for AI today is concentration of power.”
The drawback of a concentration of power is that it leads to a single point of failure. When large organizations have the ability to effectively censor the information that both people and systems can consume, that has massive implications for determining how those people and systems will think in the future. The same is true of AI. More concentration of control over specific models makes the impact a single company can have potentially universal.
While the idea that a single AI system could have universal implications for modern language itself may feel extreme given ChatGPT only made its debut six months ago, the power of LLMs implies that they can achieve ubiquity very quickly. And while language has always had a number of influences, the world has never seen technology capable of influencing language at a fundamental level, especially not technology that is controlled by just a few companies.
If AI ends up leading to the Fourth Industrial Revolution, then it needs to be accessible to everyone regardless of cost, geography, or political affiliations. We need to remove barriers to technology and information. Not everyone has a GPU, not everyone even has the internet. But people create data that trains these models, so increasing access will align incentives between data creators and model creators to ensure those who contribute data to build a model can have their value attributed and compensated.
The Rise of OpenAI
Artificial intelligence has been in the dreams of technologists since at least the 1950s, when Alan Turing first published “Computing Machinery and Intelligence.” Since then, the progression of intelligent technology has consisted of many leaps forward followed by a few steps back. Before fundamentally intelligent systems were possible, computational power and the availability of data had to reach critical mass. Incremental progress in machine learning and data science gave rise to their gradual ascendance. As Moore’s Law kept pace, and the internet brought about the age of “big data”, the stage was set for the emergence of legitimate AI.
In 2012, a groundbreaking paper was published called "ImageNet Classification with Deep Convolutional Neural Networks.” The authors, Dr. Geoffrey Hinton and his two grad students Ilya Sutskever and Alex Krizhevsky, introduced a deep convolutional neural network (CNN) architecture called AlexNet, which represented a big leap forward in image classification tasks. One key breakthrough was that AlexNet could be trained on a GPU, allowing it to harness much more computational power than algorithms trained on CPU alone. The paper also led to a number of other influential papers being published on CNNs and GPUs in deep learning. Then, in 2015, OpenAI was founded as a non-profit with the goal of building AI for everyone. In the company’s founding announcement, OpenAI emphasized its focus on creating value over capturing it:
“As a non-profit, our aim is to build value for everyone rather than shareholders. Researchers will be strongly encouraged to publish their work, whether as papers, blog posts, or code, and our patents (if any) will be shared with the world.”
The company regarded its openness as a competitive edge in hiring, promising “the chance to explore research aimed solely at the future instead of products and quarterly earnings and to eventually share most—if not all—of this research with anyone who wants it.” The type of talent that flocked to OpenAI became a who’s-who of expertise in the field.
By 2014, the market rate for top AI researchers matched the pay for top quarterback prospects in the NFL. This kind of pay, offered by large tech companies like Google or Facebook, was viewed as a negative signal by some of the early people involved in building OpenAI. For example, Wojciech Zaremba, who had previously spent time at NVIDIA, Google Brain, and Facebook, became the co-founder of OpenAI after feeling more drawn to OpenAI’s mission than the money:
“Zaremba says those borderline crazy offers actually turned him off—despite his enormous respect for companies like Google and Facebook. He felt like the money was at least as much of an effort to prevent the creation of OpenAI as a play to win his services, and it pushed him even further towards the startup’s magnanimous mission.”
A Shift In The Narrative
As OpenAI continued to progress in its research, the company increasingly became focused on the development of artificial general intelligence (AGI). In March 2017, OpenAI’s leadership decided the company’s non-profit status was no longer feasible if it was going to make real strides towards AGI, because as a non-profit it wouldn’t be able to secure the massive quantity of computational resources it would need.
In May 2018, OpenAI published research into the history of the compute required to train large models, showing that compute had increased 300,000x, doubling every 3.4 months, since 2012.
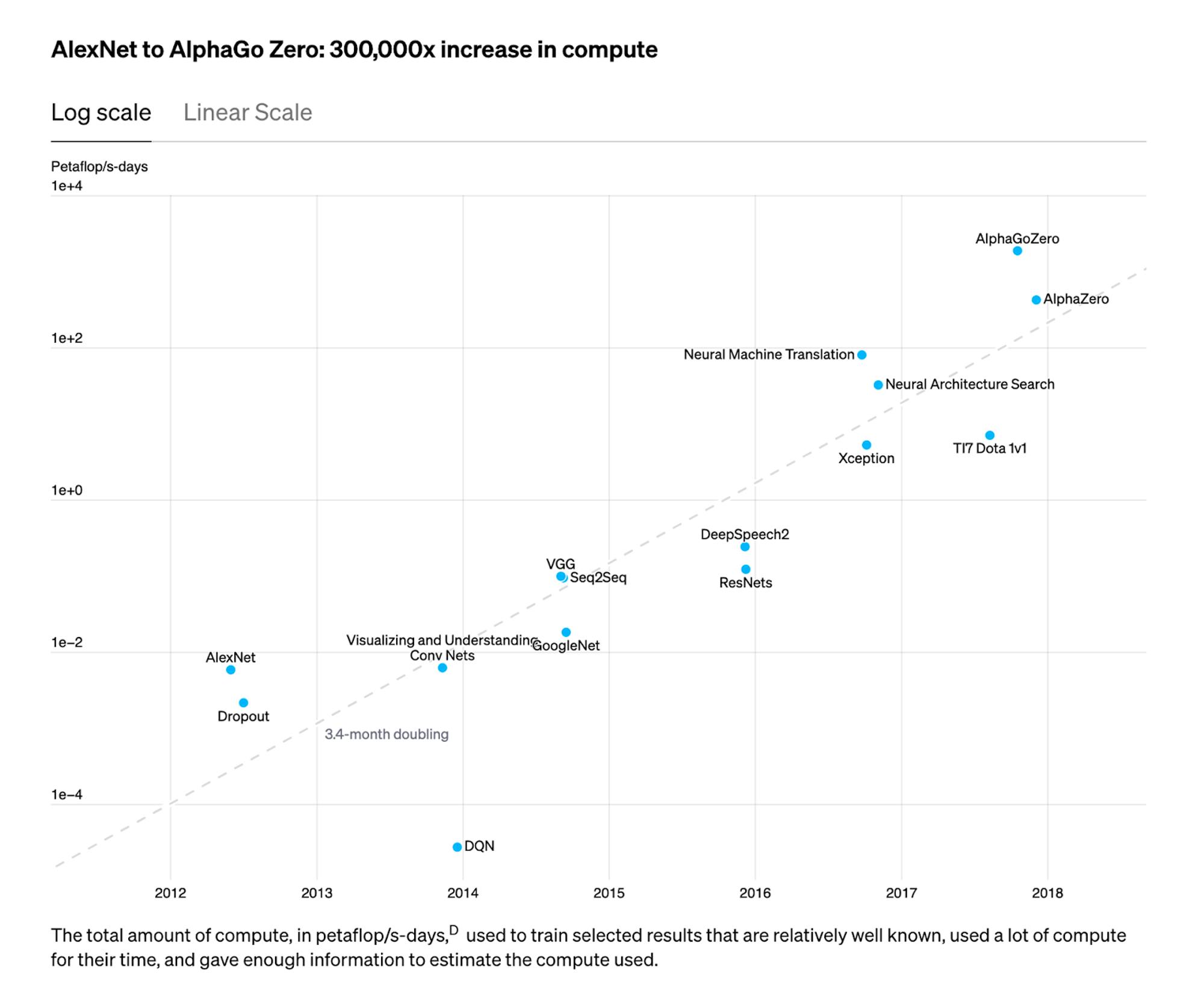
Source: OpenAI
Then, in June 2018, OpenAI published “Improving Language Understanding by Generative Pre-Training,” the first introduction of the GPT model, a transformer-based neural network architecture designed for language generation tasks. The model built on top of transformer architecture that was introduced in “Attention Is All You Need,” a foundational paper published in June 2017.
The types of models OpenAI wanted to create, like GPT and later DALL-E, were going to require significant amounts of compute. The leaders of OpenAI, like Greg Brockman, argued that in order to “stay relevant” they were going to need more resources - a lot more resources. As a first step, Sam Altman turned to Reid Hoffman and Vinod Khosla. Between that initial shift and April 2023, OpenAI would go on to raise over $11 billion in funding.
OpenAI’s new charter, published in April 2018, demonstrated the subtle changes to the business. The company still emphasized its openness and “universal mission”:
“We commit to use any influence we obtain over AGI’s deployment to ensure it is used for the benefit of all, and to avoid enabling uses of AI or AGI that harm humanity or unduly concentrate power.”
However, the charter also emphasized the company’s need to “marshal substantial resources to fulfill our mission.” Later, in March 2019, OpenAI explained how it intended to balance its fundamental mission while taking on investors with financial incentives by announcing “OpenAI LP.” The corporate structure would enable OpenAI to take on investor capital, but cap the returns its investors could potentially make, funneling any additional return to OpenAI’s non-profit arm.
Crucially, OpenAI’s new charter scaled back on the promise of openness, pointing to safety and security as the justification for this:
“We are committed to providing public goods that help society navigate the path to AGI. Today this includes publishing most of our AI research, but we expect that safety and security concerns will reduce our traditional publishing in the future, while increasing the importance of sharing safety, policy, and standards research.”
It’s important to acknowledge that, with investors who have a financial incentive tied to the size of the outcome for OpenAI, competition can become a factor. When companies are required to generate a financial return, beating your competition becomes much more important. That increased emphasis on competition often takes precedence over openness.
Building A War Chest For Scale
After the announcement of OpenAI LP, the company didn’t waste any time garnering the resources its leadership team believed it desperately needed. In July 2019, Microsoft invested $1 billion in OpenAI, half of which was later revealed to have taken the form of Azure credits that would allow OpenAI to use Microsoft’s cloud products basically for free. OpenAI’s cloud spending scaled rapidly after this deal. In 2017, OpenAI spent $7.9 million on cloud computing. This climbed to $120 million in 2019 and 2020 combined. OpenAI had previously been one of Google Cloud’s largest customers, but after Microsoft’s investment, OpenAI started working exclusively with Azure.
In 2020, Microsoft announced it had “developed an Azure-hosted supercomputer built expressly for testing OpenAI's large-scale artificial intelligence models.” That supercomputer is powered by 285K CPU cores and 10K GPUs, making it one of the fastest systems in the world. Armed with Microsoft’s computational resources, OpenAI dramatically increased the pace at which it shipped new products.
In line with OpenAI’s focus on compute resources, the company increasingly pursued an approach where scale mattered. A 2020 profile in the MIT Technology Review described OpenAI’s focus on scale as follows:
“There are two prevailing technical theories about what it will take to reach AGI. In one, all the necessary techniques already exist; it’s just a matter of figuring out how to scale and assemble them. In the other, there needs to be an entirely new paradigm; deep learning, the current dominant technique in AI, won’t be enough… OpenAI has consistently sat almost exclusively on the scale-and-assemble end of the spectrum. Most of its breakthroughs have been the product of sinking dramatically greater computational resources into technical innovations developed in other labs.”
That increased access to computational resources allowed OpenAI to continuously improve the capability of its models, eventually leading to the announcement of GPT-2 in February 2019. However, while OpenAI continued to pursue scale, the company also seemed to increasingly prefer secrecy. As part of the rollout of GPT-2, OpenAI argued that the full model was too dangerous to release all at once, and instead conducted a staged release before releasing the full model in November 2019. Britt Paris, an assistant professor at Rutgers University focused on AI disinformation, argued that “it seemed like OpenAI was trying to capitalize off of panic around AI.”
In January 2020, OpenAI researcher and Johns Hopkins professor Jared Kaplan, alongside others, published "Scaling Laws for Neural Language Models”, which stated:
“Language modeling performance improves smoothly and predictably as we appropriately scale up model size, data, and compute. We expect that larger language models will perform better and be more sample efficient than current models.”
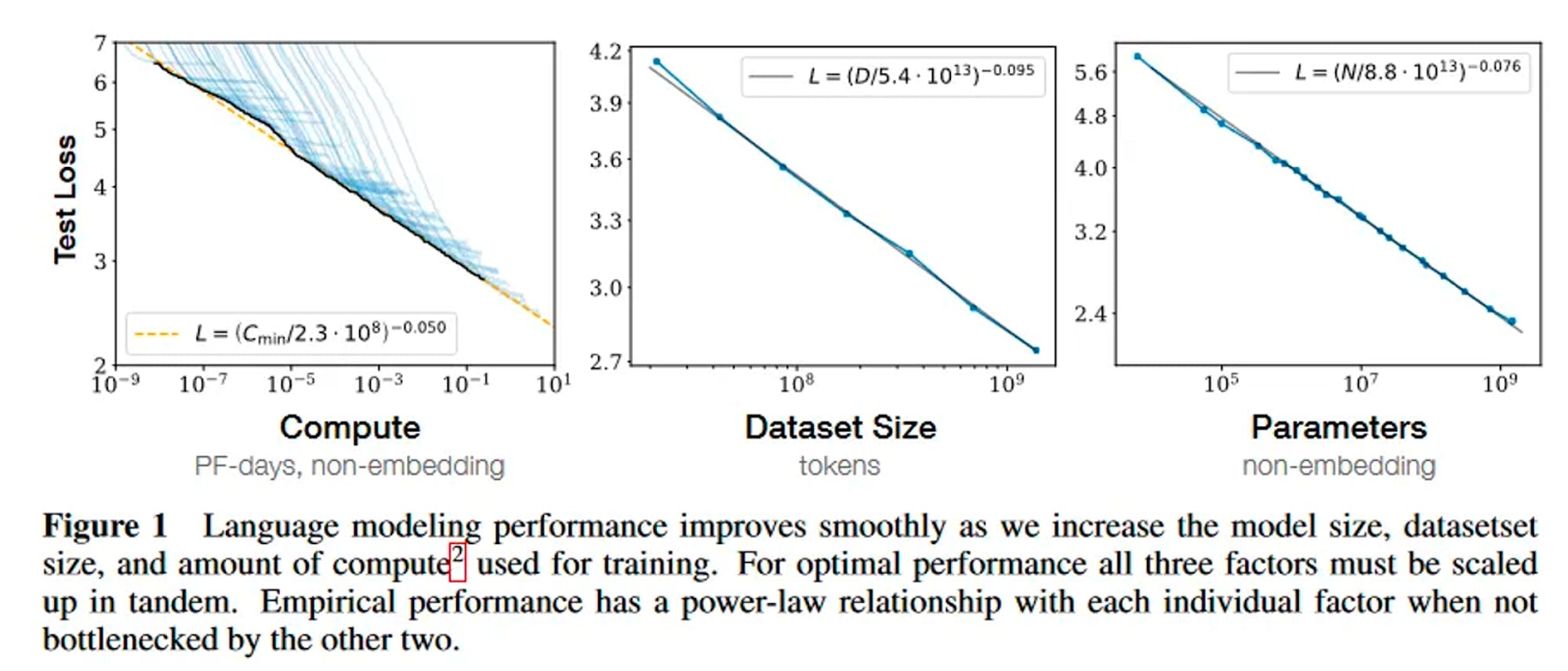
Source: OpenAI
Again, the importance of compute and scale became front and center to the progression of OpenAI’s models. The focus on scale was reinforced in May 2020 when OpenAI published a paper on GPT-3, "Language Models are Few-Shot Learners”, that demonstrated smooth scaling of performance with increased compute.
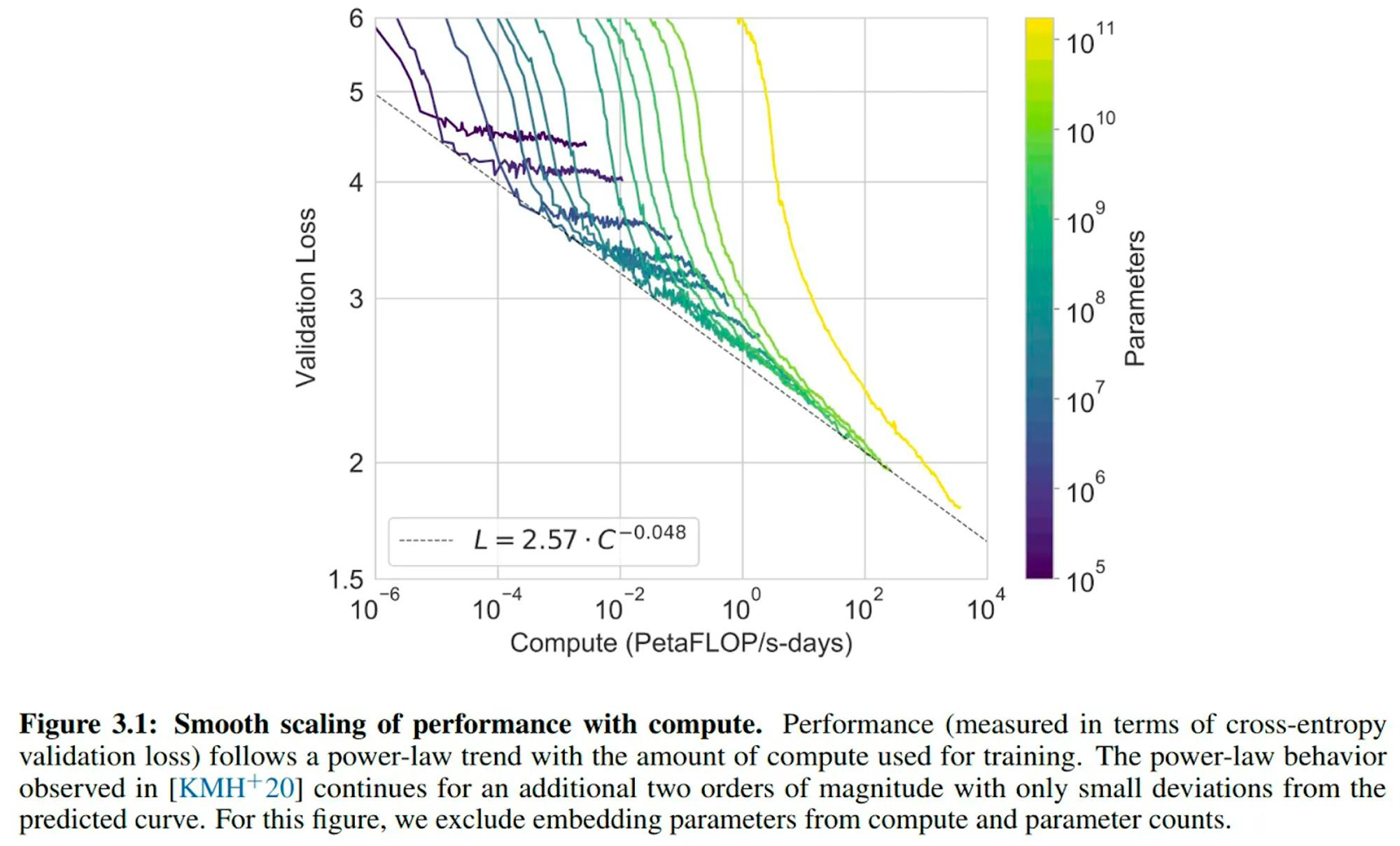
Source: OpenAI
Furthermore, OpenAI found that increasing scale also improves generalizability, arguing “scaling up large-language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches.” Gwern Branwen, a freelance researcher, coined The Scaling Hypothesis in a blog post, and stated:
“GPT-3, announced by OpenAI in May 2020, is the largest neural network ever trained, by over an order of magnitude… To the surprise of most (including myself), this vast increase in size did not run into diminishing or negative returns, as many expected, but the benefits of scale continued to happen as forecasted by OpenAI."
The success of OpenAI’s research did not stay confined to academics or AI-interested circles. It burst onto the public scene with the launch of ChatGPT on November 30th, 2022, which reached 1 million users after five days. Two months after the launch of ChatGPT, in January 2023, it had become the fastest-growing consumer product ever with 100 million MAUs. That same month, Microsoft doubled down on OpenAI with a new $10 billion investment. Many also began to believe that ChatGPT represented the first legitimate potential threat to Google’s dominance in search in decades.
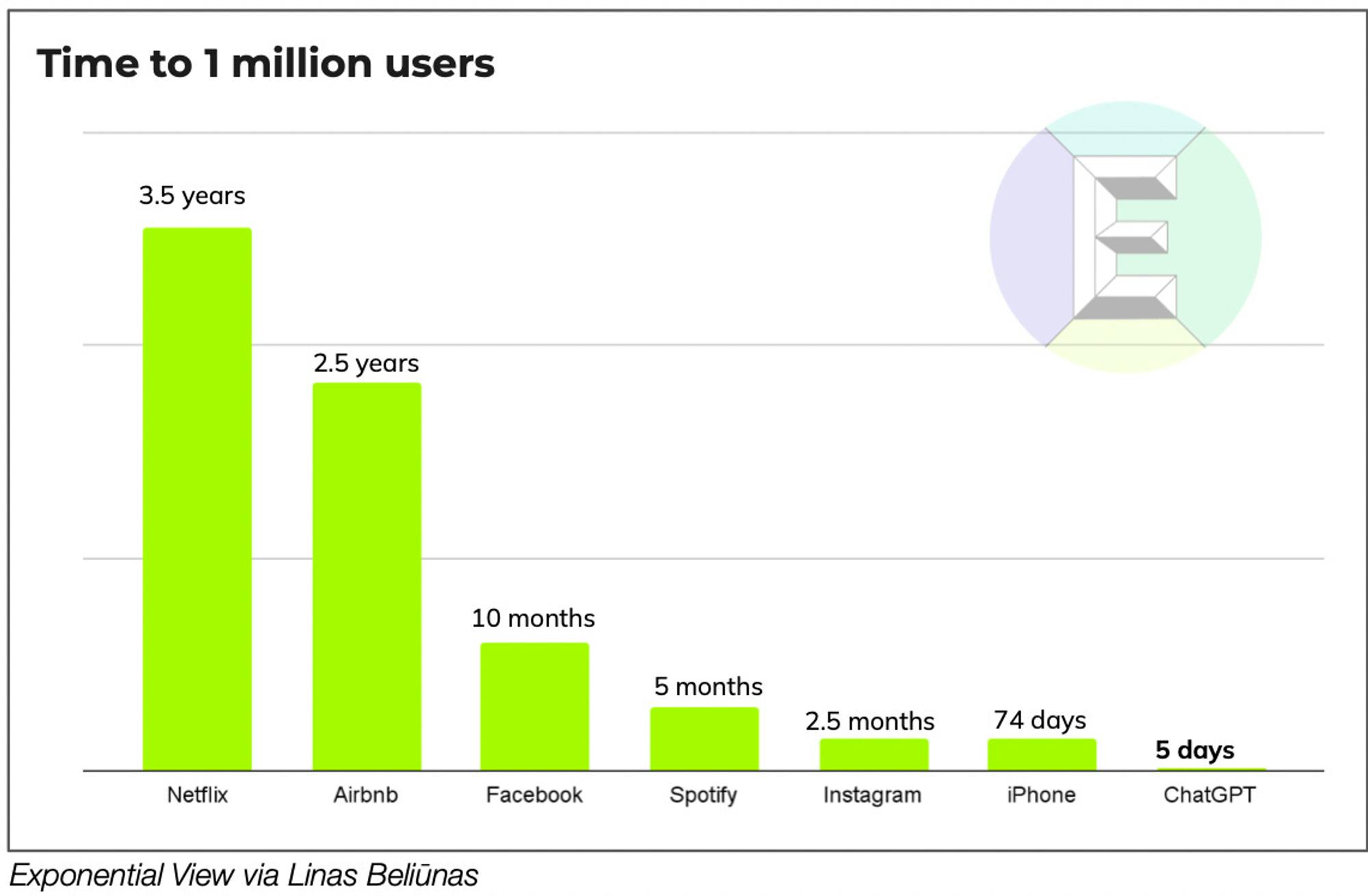
Source: Exponential View
Internally, OpenAI projected $200 million of revenue in 2023 and $1 billion by 2024. But despite their positive external reception and expected financial success, OpenAI’s products came with a cost. One report estimated that OpenAI’s losses in 2022 doubled to $540 million, with Sam Altman expecting to raise as much as $100 billion in the subsequent years to fund its continued efforts to reach scale. This would make it “the most capital-intensive startup in Silicon Valley history.” ChatGPT alone had costs that Sam Altman himself described as “eye watering,” estimated to cost $700K per day to keep the service running.
While the success of ChatGPT and the seemingly endless resources from Microsoft made OpenAI a leading player in the world of AI, the approach the company had taken didn’t sit right with everyone. Several people involved in the early vision of the company saw OpenAI’s evolutionary process as moving it further and further from the openness implied in the company’s name.
From OpenAI To ClosedAI
OpenAI’s shift from non-profit to for-profit took place over the course of 2017 and early 2018, before being announced in April 2018. The cracks between the original ethos and the current philosophy started showing even before this announcement. In June 2017, Elon Musk, one of the original founders of OpenAI, had already poached OpenAI researcher Andrej Karpathy, a deep learning expert, from the company to become head of Tesla’s autonomous driving division in an early sign of internal conflict at OpenAI.
In February 2018, OpenAI announced that Elon Musk would be stepping down from the company’s board. After his departure, Elon Musk failed to contribute the full $1 billion in funding he had promised the company, after having only contributed $100 million before leaving. While both Musk and OpenAI claimed the departure was due to increasing conflict of interest, that story has become more nuanced. In March 2023, it was revealed that Musk “believed the venture had fallen fatally behind Google… Musk proposed a possible solution: He would take control of OpenAI and run it himself.” The company refused, and Musk parted ways.
Later, after the success of ChatGPT and Microsoft’s $10 billion investment into OpenAI, Elon Musk became more vocal about his criticism and existential disagreements with the company.
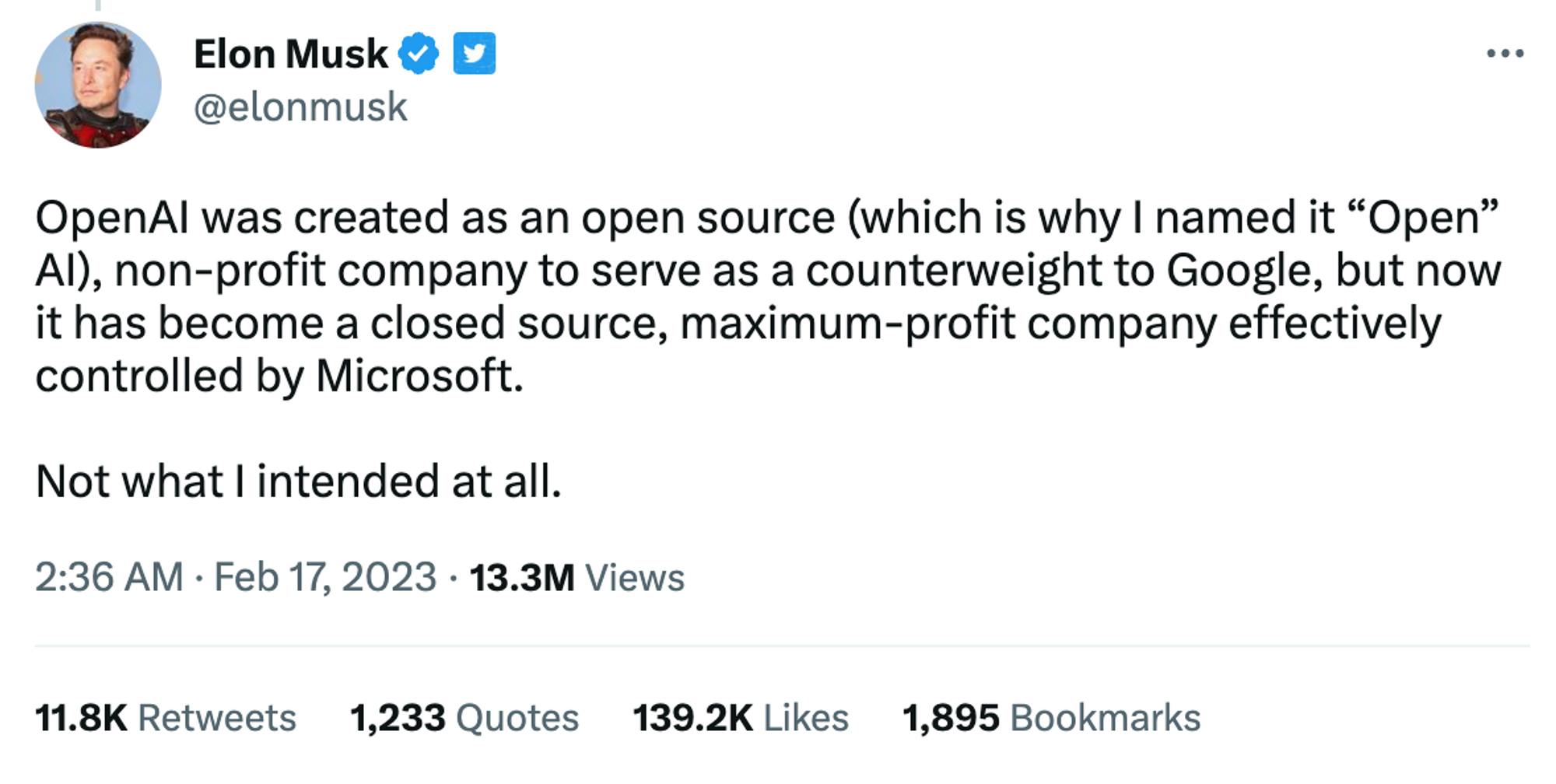
Source: Twitter
Elon Musk wasn’t alone in those criticisms. When OpenAI published its new charter, and announced OpenAI LP, the company touted its focus on avoiding work that would “unduly concentrate power.” In March 2019, people expressed their issues with OpenAI’s position. The idea that capping investor returns at 100x was, in any way, a deterrent for typical financially-driven incentives, drew criticism. In one Hacker News post, a commenter made this point:
“Early investors in Google have received a roughly 20x return on their capital. Google is currently valued at $750 billion. Your bet is that you'll have a corporate structure which returns orders of magnitude more than Google on a percent-wise basis (and therefore has at least an order of magnitude higher valuation), but you don't want to "unduly concentrate power"? How will this work? What exactly is power, if not the concentration of resources?”
In tandem with the success of ChatGPT, OpenAI became increasingly closed off from its initial vision of sharing its research. In March 2023, OpenAI announced GPT-4, the company’s first effectively closed model. In announcing GPT-4, the company argued that concerns over competition and safety prevented the model from a more open release:
“Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.”
In an interview around the same time, Ilya Sutskever, OpenAI’s chief scientist and co-founder, explained why OpenAI had changed its approach to sharing research:
“We were wrong. Flat out, we were wrong. If you believe, as we do, that at some point, AI — AGI — is going to be extremely, unbelievably potent, then it just does not make sense to open source. It is a bad idea... I fully expect that in a few years it’s going to be completely obvious to everyone that open-sourcing AI is just not wise.”
Members of the AI community have since criticized this decision. Ben Schmidt, the VP of Information Design at Nomic*, explained that “not being able to see what data GPT-4 was trained on made it hard to know where the system could be safely used and come up with fixes.“ These comments came after a Twitter thread explaining the inherent limitations of such a closed approach.

Source: Twitter
One of the biggest limitations that users are left with when OpenAI closes off context for its models is an understanding of the potential weightings or biases inherent in the model. For example, one review of ChatGPT indicated that it demonstrates political bias with a “pro-environmental, left-libertarian orientation.” Beyond specific instances of bias, Ben Schmidt further explained that “to make informed decisions about where a model should not be used, we need to know what kinds of biases are built in.” Sasha Luccioni, Research Scientist at Hugging Face, explained the limitations that OpenAI’s approach creates for scientists:
“After reading the almost 100-page report and system card about GPT-4, I have more questions than answers. And as a scientist, it's hard for me to rely upon results that I can't verify or replicate.”
Beyond case-specific instances of replicability, or bias, there were other critics whose focus was more on the implications for AI research as a whole. A discipline that has borrowed heavily from academia was now facing a much more top-down corporate level of control in the form of OpenAI’s alignment with Microsoft. William Falcon, CEO of Lightning AI and creator of PyTorch Lightning, explained this critique in a March 2023 interview:
“It’s going to set a bad precedent… I’m an AI researcher. So our values are rooted in open source and academia. I came from Yann LeCun’s lab at Facebook,…. Now, because [OpenAI has] this pressure to monetize, I think literally today is the day where they became really closed-source.”
As Sam Altman’s priorities for OpenAI continued to evolve starting in 2020 up to the launch of GPT-4, the changes didn’t just cause public debates on profit vs. non-profit or closed vs. open, nor did they just spark a conflict between Altman and Musk.
Instead, OpenAI’s approach “forces it to make decisions that seem to land farther and farther away from its original intention. It leans into hype in its rush to attract funding and talent, guards its research in the hopes of keeping the upper hand, and chases a computationally heavy strategy—not because it’s seen as the only way to AGI, but because it seems like the fastest.” That approach has caused real breaking points for several people working at OpenAI.
Most notably, Dario Amodei, former VP of Research at OpenAI, left to found rival AI startup Anthropic. In doing so he took 14 researchers with him, including OpenAI’s former policy lead Jack Clark. While Amodei left in December 2020, it’s been reported that “the schism followed differences over the group’s direction after it took a landmark [$1 billion] investment from Microsoft in 2019.” OpenAI would produce several alumni that would go on to start other AI companies, like Adept or Perplexity AI. But increasingly, OpenAI’s positioning would put a number of different AI experts both inside and outside the company on different ends of the spectrum between open and closed.
Cracks In The AI Family Tree
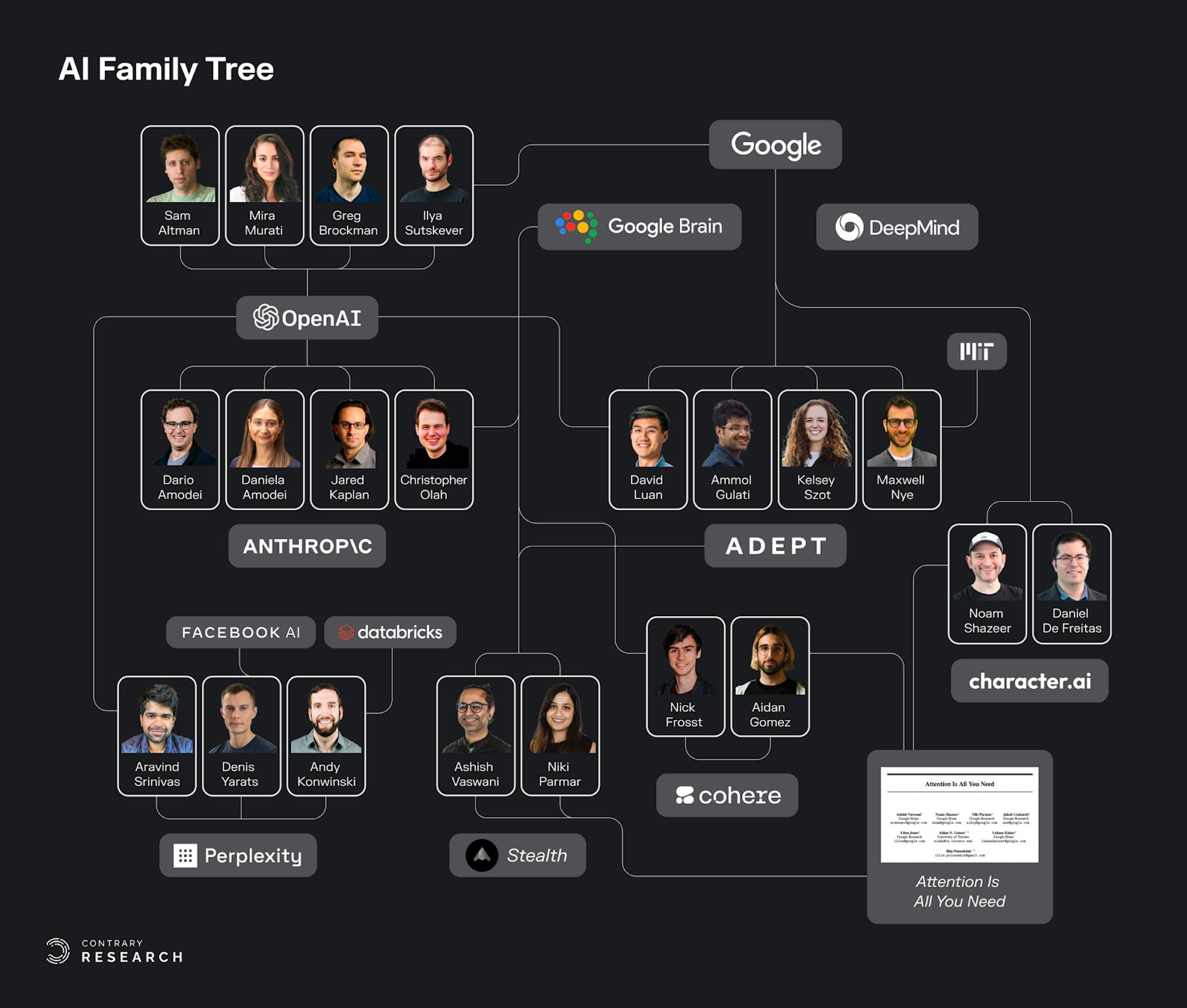
Source: Contrary Research
Unpacking the newest players in the AI landscape unveils an interwoven family tree of experts, institutions, and ideas. “Attention Is All You Need,” the pivotal paper that introduced transformer architecture, now a key building block of large language models, was written primarily by people affiliated with Google. When Google acquired DeepMind in 2014, it was with the promise that DeepMind “would be shielded from pressure to make money in order to focus on a single goal: creating computer software that equals or surpasses human intelligence.”
The culture of collaborative academia has been a significant part of the AI landscape in the past. Even as recently as January 2023, this point about the equalizing power of collaboration was made in The Economist:
“AI knowledge diffuses quickly… Since the best AI brains are scientists at heart, they often made their defection to the private sector conditional on a continued ability to publish their research and present results at conferences. That is partly why Google made public big advances including the “transformer”, a key building block in ai models, giving its rivals a leg-up. (The “t” in Chatgpt stands for transformer.) As a result of all this, reckons Yann LeCun, Meta’s top AI boffin, ‘Nobody is ahead of anybody else by more than two to six months.’”
The collaborative nature of AI research is also one key driver behind the overlapping threads in the AI family tree. Many AI luminaries have spent time at Google Brain, Meta AI, NVIDIA, and now OpenAI among several other stops. But OpenAI’s closing off, and the subsequent success of ChatGPT has pushed the industry into an AI arms race, marked by responses like Google’s “Code Red.”
Increased competition and technological breakthroughs have forced most players in AI to make philosophical stances in terms of how they’ll build their respective companies. While some at Google assert open source will make it harder for companies like OpenAI to establish a moat, others are more focused on leveraging open source for their own benefit, or focusing on safety implications within AI.
Stability AI & Stable Diffusion
Perhaps one of the loudest proponents of open source has been Stability AI. Founded in early 2019, the company’s core product is DreamStudio, a text-to-image interface powered by Stable Diffusion. Whereas other text-to-image models like DALL-E or Midjourney had only been accessible via cloud services, Stable Diffusion was released open source.
Source: GitHub, as of July 5th 2023
Emad Mostaque, the CEO and co-founder of Stability AI, has positioned the company as a champion of open source. In May 2023, he said that he intended to, “be the leader of open even as everyone else does closed.” He went on to lay out the importance of open models for leveraging private data as follows:
"Open models will be essential for private data… Most of the valuable data in the world is private data, regulated data. There is no way that you can use black-box models for your health chatbots, or your education, or in financial services, whereas, an open model, with an open-source base, but with licensed variant data, and then the company's private data, is really important."
The biggest piece of evidence demonstrating Stability AI’s commitment to open source is the company’s involvement with Stable Diffusion. However, Stability AI has been known to inflate the level of its involvement in the development of Stable Diffusion. In October 2022, Stability AI raised a $101 million Series A. In April 2023, the deck the company used to raise that round was leaked. In it, Stability AI claimed to be a “co-creator” of Stable Diffusion, in addition to being a meaningful contributor to other projects like Midjourney and EleutherAI.
In reality, Stability AI’s contributions were clarified to be contributing compute grants including $75 million for AWS compute resources. The actual development of Stable Diffusion was the result of years of research and work by researchers at LMU Munich (called CompVis) and Runway, a New York-based generative AI startup. Mostaque has since more clearly stated the model’s origins, but that hasn’t stopped most sources from pointing incorrectly to Stability AI as the primary developer of Stable Diffusion.
“Stability, as far as I know, did not even know about this thing when we created it,” Björn Ommer, the head of the LMU research group that originally developed Stable Diffusion, told Forbes. “They jumped on this wagon only later on.” Ommer also opined on the muddied ownership claims for Stable Diffusion. “Once [Mostaque] had this money [from his Series A] he became a bit clearer who actually developed Stable Diffusion and that his company did not own the IP.”
Just as OpenAI has had shifting priorities in the face of taking on investor capital, you see a similar conflict play out for Stability between commitment to open source and the need to demonstrate ownership to garner capital and competitive advantage. Stability’s exaggerated claims around ownership over Stable Diffusion has been a hit to the open-source AI community, but the company’s problems haven’t stopped there.
Stability AI has tried to expand beyond Stable Diffusion’s success in image generation by pushing into developing language models. In April 2023, Stability AI launched StableLM, intended to be the company’s response to ChatGPT. The model is available on GitHub in 3 billion and 7 billion parameter model sizes, with 15 billion and 65 billion parameter models to follow. Stability AI is maintaining its commitment to open source, promising to release a full technical report on the model. However, informal testing from AI developers and journalists have found performance to be significantly worse than ChatGPT, which runs GPT-3.5, and other open-source models from EleutherAI and Nomic*.
Throughout the first half of 2023, Stability AI was trying to raise a round of funding at a $4 billion valuation before opting instead to raise a small convertible note. In June 2023, Forbes released a piece noting multiple discrepancies in the way Stability talks about itself. These included listing AWS as a “strategic partner”, even though a VP at AWS told Forbes that Stability is “accessing AWS infrastructure no different than what our other customers do.”
Stability has also claimed to have partnerships with UNESCO, OECD, WHO and World Bank, but all four agencies denied the existence of such partnerships. The Forbes article noted other issues for Stability as well, such as overdue taxes, missed payroll, and executive departures including the Head of Research and COO at Stability.
Anthropic & Constitutional AI
One of the most notable companies that was born from OpenAI’s lineage is Anthropic. In January 2020, Johns Hopkins physicist Jared Kaplan and several OpenAI researchers published “Scaling Laws For Neural Language Models.” This was the same research that reflected OpenAI’s philosophical shift towards needing more compute, more capital, and therefore a different corporate vision.

Source: AGIWear; Jared Kaplan
Oren Etzioni, who leads the AI institute established by Paul Allen, the co-founder of Microsoft, emphasized the directional shift OpenAI had taken:
“They started out as a non-profit, meant to democratize AI. Obviously when you get [$1 billion] you have to generate a return. I think their trajectory has become more corporate.”
Led by Dario Amodei (Anthropic CEO), Kaplan joined 14 other OpenAI researchers, including Chris Olah, to found Anthropic in 2021. The company’s approach took alternative methods to ensure its ability to balance commercialization with social responsibility. One report on Anthropic’s founding explained its goals this way:
“To insulate itself against commercial interference, Anthropic has registered as a public benefit corporation with special governance arrangements to protect its mission to ‘responsibly develop and maintain advanced AI for the benefit of humanity’. These include creating a long-term benefit committee made up of people who have no connection to the company or its backers, and who will have the final say on matters including the composition of its board.”
Anthropic’s efforts to remain more “socially conscious” have been primarily governance decisions, like becoming a public benefit corporation. However, the technological focus of what the company is building has been more centered around ensuring safety in the output of its models. The approach Anthropic takes is referred to as “Constitutional AI.”
Traditionally, LLMs like ChatGPT are trained with a method known as reinforcement learning from human feedback (RLHF). While Anthropic popularized the term in 2022, the practice has been around since 2017. Explicitly optimizing against human feedback certainly makes models more palatable to their users, but comes with the risk of baking the feedback-providers’ biases into the model. To combat this, Anthropic’s approach instead provides a “constitution” of desired parameters. The company describes the approach this way:
“In the supervised phase we sample from an initial model, then generate self-critiques and revisions, and then finetune the original model on revised responses. In the [RLHF] phase, we sample from the finetuned model, use a model to evaluate which of the two samples is better, and then train a preference model from this dataset of AI preferences.”
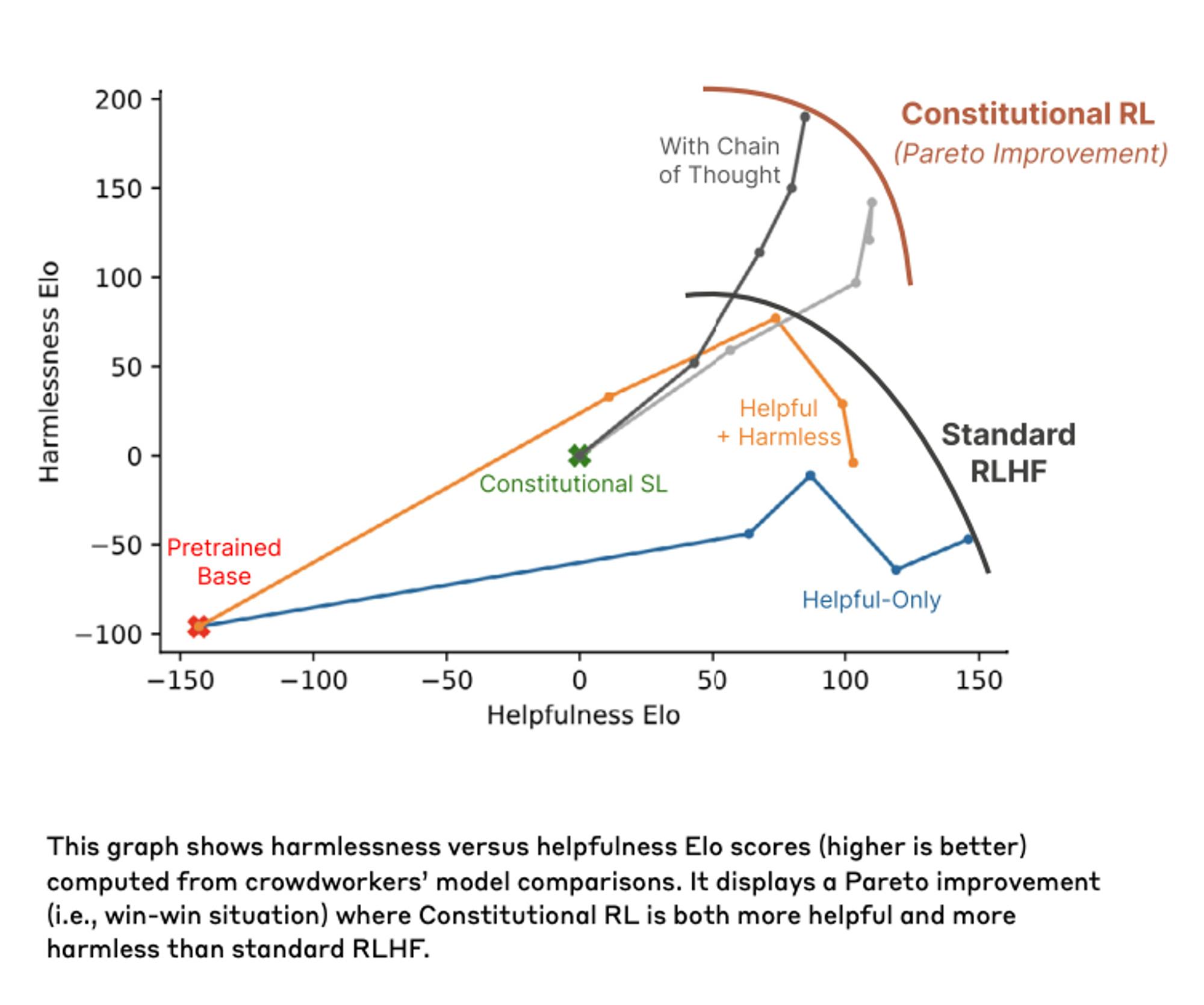
Source: Anthropic
Jared Kaplan explained this approach to reinforcement learning this way:
“The model trains itself by basically reinforcing the behaviors that are more in accord with the constitution, and discourages behaviors that are problematic.”
While Anthropic’s focus on AI safety seems more in line with principles of open source than OpenAI’s increasingly corporate priorities, there are elements of the AI safety approach that could be seen as “open in name only.” In particular, Anthropic’s emphasis on safe AI deployment has led it to become incredibly secretive. A recent evaluation of AI companies’ compliance with draft EU AI regulation ranks Anthropic as second to last overall, in large part due to its secrecy around training data, capabilities, and evaluations.

Source: Stanford University
Some of Anthropic’s secrecy can be traced back through its cultural roots in the effective altruist (EA) ideology of some of its founders and largest backers. In particular, Jann Tallinn and Sam Bankman-Fried (SBF), the leads of Anthropic’s Series A and B rounds, are both strongly tied to the EA movement. One of the most salient EA ideas influencing Anthropic is the concept of infohazards. Infohazards, coined in 2011 by EA philosopher Nick Bostrom, are ideas that must be kept secret on the basis that their distribution could cause significant harm. A classic example of an infohazard is information that could help someone build a nuclear weapon. A more modern example is information that could help someone build a capable AI system. Functionally, labeling trade secrets as infohazardous endow employees with a moral responsibility not to share them, therefore promoting a secretive culture.
Anthropic likely has good intentions in emphasizing AI safety, even if many in the open source community may disagree with their approach. Often, when companies use the argument of “AI safety” it is typically targeted at the mission of striving towards benevolent AGI. But that long-term end could be used to justify potentially harmful means. In multiple cases, for example, the competition for compute, adoption, and progress has compelled AI companies to remove the few safety parameters they have.
As much as companies, including OpenAI, point to safety as a justification for being more closed off, the elephant in the room remains the less high-minded incentive of competition for market share. Safety is better marketing, but competition may be the more immediate and powerful incentive. Fear of competition can be one reason why companies turn away from open source. Ilya Sutskever, OpenAI’s chief scientist and co-founder, says as much about OpenAI’s decision to close off GPT-4:
“On the competitive landscape front — it’s competitive out there. GPT-4 is not easy to develop. It took pretty much all of OpenAI working together for a very long time to produce this thing. And there are many many companies who want to do the same thing, so from a competitive side, you can see this as a maturation of the field. On the safety side, I would say that the safety side is not yet as salient a reason as the competitive side. But it’s going to change.”
So while Anthropic may have good intentions, the company’s approach to AI safety is indicative of a broader problem with the world of AI right now. The more financial incentives to beat the competition pervades a landscape of companies that are not committed to open collaboration, the more you reinforce the potential for mutually assured destruction in the AI arms race rather than a cooperative effort building towards the best possible outcome for humanity as a whole.
EleutherAI & “Unironically Giving OpenAI A Run For Their Money”
Stability AI didn’t just claim to have been the co-creator of Stable Diffusion. It also claimed to be critically involved in the creation of another important project: EleutherAI. EleutherAI was arguably one of the earliest open-source AI research groups, started by Connor Leahy, Sid Black, and Leo Gao on Discord.
Source: IEEE
The group first started as a Discord server in July 2020 to replicate GPT-3. In December 2020, EleutherAI released “The Pile,” a diverse text data set for training language models. In March 2021, the group released GPT-Neo, and later released GPT-J, a 6 billion parameter model, before releasing GPT-NeoX in February 2022. All three of these models were the largest open source language models at the time of their respective release.
EleutherAI’s models have been highly praised, with one Google Brain research scientist saying “our research would not have been possible without EleutherAI’s complete public release of The Pile data set and their GPT-Neo family of models.” EleutherAI’s “The Pile” has been used by Microsoft and Meta to train AI models. EleutherAI has now been established as a non-profit and has received funding from Stability AI and Hugging Face, and has received grants from TPU Research Cloud, a Google Cloud program for research, and CoreWeave, a cloud GPU provider.
However, one article reports that when EleutherAI was asked about what official affiliation existed between Stability AI and EleutherAI, the response was: “None.” Further confusing the relationship, Eleuther AI’s website recently began listing Stability AI CEO Emad Mostique as a member of its board. Current EleutherAI CEO Stella Bidderman clarified the situation on Discord, stating that “Stability is one of our funders and Emad is on our board.”

Source: EleutherAI Discord Server
While EleutherAI has received grants and funding, the company has avoided raising venture capital. Instead, one of the original creators of EleutherAI, Connor Leahy, has gone on to found Conjecture, with funding from people like Nat Friedman, Daniel Gross, Patrick and John Collison, Arthur Breitman, Andrej Karpathy, and Sam Bankman-Fried. Connor still sits on the board of EleutherAI as of July 2023.
Projects like EleutherAI have demonstrated that high quality open-source AI models are possible. But the bigger question is whether the forces at work within the AI landscape will prove too hostile for any large-scale successful open-source project in the midst of the AI arms race.
The State of AI Today
The biggest swings in AI right now are coming from OpenAI and, in particular, the responses from big tech. In April 2023, Google merged its Google Brain and DeepMind teams. The previously independently-operated DeepMind will, according to the Financial Times, cede its “cherished independence in return for greater power and influence over the future of AI.” Google Brain, on the other hand, has always been more directly commercialized, integrating its work into search, ads, and translation contributing “significantly to Google’s bottom line.”
In February 2023, Jeff Dean, SVP of Google Research and AI, instituted a new policy where “Google would take advantage of its own AI discoveries, sharing papers only after the lab work had been turned into products.” In a world of well-funded players focused on owning as much of the AI world as possible, the center of gravity is trending towards concentrated walled gardens, not collaboration.
Centralization is an especially dangerous outcome in AI given the history of monolithic tech giants demonstrating their inability to effectively handle constructive criticism. In March 2021, Timnit Gebru, and other Google Brain researchers, published the paper “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” The paper discusses the downside of large language models, including the potential for bias in broad training data sets.
Google said Gebru’s paper “painted too bleak a picture of the new technology.” After aggressively defending the paper, Gebru was promptly fired from Google. Several people have argued for the need to better address a number of issues in the world of AI, such as:
Misinformation: Microsoft Chief Economist Michael Schwarz argued that “I am confident AI will be used by bad actors… It can do a lot of damage in the hands of spammers with elections.” Geoffrey Hinton, sometimes referred to as “The Godfather of A.I.”, is worried that false photos, videos, and text would mean the average person would “not be able to know what is true anymore.”
Bias: Research from Penn State showed that NLP models tend to associate more negative words to people with disabilities. The Washington Post, with researchers at the Allen Institute of AI, investigated Google’s C4 data set, which contains 15 million websites used to train industry large language models including Google’s T5 and Meta’s LLaMA. The results saw a number of instances of anti-Muslim bias, hundreds of examples of pornographic websites, and more than 72K instances of “swastikas.”
Intellectual Property Violations: GitHub, owned by Microsoft, and OpenAI are being sued in a class action lawsuit that alleges the AI coding assistant GitHub Copilot is “software piracy on an unprecedented scale.” Copilot was trained on public code with licenses requiring credit for the creators, but Copilot does not provide any credit or copyright in its suggestions. Similarly, Stability AI is being sued by Getty Images for using their images in training its image models.
Data Privacy: Facing regulatory challenges, OpenAI updated its privacy policy on March 14, 2023 to allow users to remove their personal information. However, there are debates if it's even technically possible to enforce GDPR’s “right to be forgotten,” given how complicated it can be to separate specific data once it's embedded in LLMs. OpenAI maintains broad rights on data usage. This has led companies like Samsung and JPMorgan to outright ban employees from using tools like ChatGPT, given concerns over sensitive data.
The power of the technology is obvious, but so are the inherent issues that need to be tackled like the concentration of power, censorship, and data ownership. Having closed monolithic central failure points only increases the likelihood that these problems get worse before they get better.
Sometimes regulation can become an effective counterbalance to the centralization of power. In a meeting with the Biden administration on May 4, 2023, major industry players Google, Microsoft, OpenAI, Stability AI, NVIDIA, Hugging Face, and Anthropic agreed to open their AI systems for public evaluation to “explore how the models align with the principles and practices outlined in the Biden-Harris Administration’s Blueprint for an AI Bill of Rights and AI Risk Management Framework.”
The US government also issued a nationwide request from the NTIA (National Telecommunications and Information Administration), which received 1.4K responses, including from the aforementioned participants. Anthropic released recommendations titled “Charting a Path to AI Accountability” calling for actions such as establishing pre-registration for large AI training runs, risk assessments, and mandating external red teaming before model release. OpenAI’s response detailed suggestions such as red teaming, quantitative model evaluations, assessing dangerous capabilities, and registration and licensing for “highly capable” foundation models.
OpenAI has even gone further in its proposed solutions than national regulation, suggesting an international governing body to regulate the risks around AI. In a post titled “Governance of superintelligence”, Sam Altman, Greg Brockman, and Ilya Sutskever suggest:
“...We are likely to eventually need something like an IAEA for superintelligence efforts; any effort above a certain capability (or resources like compute) threshold will need to be subject to an international authority that can inspect systems, require audits, test for compliance with safety standards, place restrictions on degrees of deployment and levels of security, etc.”
However, as much as regulation could help maintain the balance of power in AI, it has often also been used as a barrier to protect existing incumbents and make success more difficult for new entrants. OpenAI, along with a number of other companies, universities, and trade associations, spent a collective $94 million on lobbying efforts in the first quarter of 2023 alone. OpenAI engaged in a massive multi-country tour, especially in the EU, to push for their AI regulation to be more “watered down,” especially as it relates to OpenAI. As Marietje Schaake, an international policy fellow at Stanford's Institute for Human-Centered Artificial Intelligence, has described it, "Any and all suggestions that are coming from key stakeholders, like [OpenAI], should be seen through the lens of: What will it mean for their profits?"
Concentration of Power
Make no mistake: the tech industry was concentrated long before the current AI boom. At the end of 2021, big tech stocks like Apple, Amazon, Microsoft, and Meta made up 39% of the Russell 1000 Growth Index, which tracks large cap stocks in the US. Looking at OpenAI as just another massive startup success story akin to Stripe or Airbnb is a mistake. OpenAI’s financial relationship with Microsoft makes the company’s position unique. The billions that Microsoft has invested in OpenAI caused a rift in the OpenAI team, not just because it was a lot of capital, but specifically because it came from a large monopoly player in tech.
As OpenAI becomes more protective of its competitive position, the company will push to control more of the ecosystem. For example, in April 2023 OpenAI opened an attempt to patent the term “GPT” to protect the brand recognition associated with its products, like ChatGPT. But beyond simple concentration of mindshare, there are actual negative ramifications to technical output if so much of the ecosystem is centralized through one player. Martin Laprise, the chief scientist and co-founder of Hectiq.ai explained the danger of relying on concentrated models this way:
“It’s already slightly disturbing to think about the long-term consequence of people delegating a part of their thought process to “something”, now imagine that they are delegating this process to a centralized model heavily aligned by a really small group of curators.”
Laprise’s concerns stem from the need for diverse RLHF, the process of using human feedback to reinforce a model’s learning. If you rely on an external model to do the training, you’re continuing to limit any potential output as the result of the same small subset of biased curators providing human feedback. In a Wall Street Journal opinion piece, Peggy Noonan made this point about the would-be owners of the AI ecosystem:
“Everyone in the sector admits that not only are there no controls on AI development, there is no plan for such controls. The creators of Silicon Valley are in charge. What of the moral gravity with which they are approaching their work? Eliezer Yudkowsky, who leads research at the Machine Intelligence Research Institute, noted in Time magazine that in February the CEO of Microsoft, Satya Nadella, publicly gloated that his new Bing AI would make Google “come out and show that they can dance. I want people to know that we made them dance.” Mr. Yudkowsky: “That is not how the CEO of Microsoft talks in a sane world.”
Centralization doesn’t just cause concern for ideological libertarians. The implications of a single point of failure are concerning for a number of reasons. Any single company runs the risk of accidentally exposing confidential corporate information, or having individual user data exposed by bugs. The larger their user base, the more harmful such breaches become.

Source: Twitter
On the other end of the spectrum from these large centralized AI players are the biggest proponents of open-source AI, such as Hugging Face CEO Clement Delangue, who testified before congress. In an overview of his testimony, Delangue said:
“Open science and open source AI distribute economic gains by enabling hundreds of thousands of small companies and startups to build with AI. It fosters innovation, and fair competition between all. Thanks to ethical openness, it creates a safer path for development of artificial intelligence by giving civil society, non-profits, academia, and policy makers the capabilities they need to counterbalance the power of big private companies. Open science and open source AI prevent blackbox systems, make companies more accountable, and help solving today’s challenges like mitigating biases, reducing misinformation, promoting copyright, & rewarding all stake-holders including artists & content creators in the value creation process.”
Prior to his testimony before Congress, Delangue and Amjad Masad, the CEO of Replit*, had a conversation in one conference on the biggest risks facing AI. Delangue described the disconnect between reality and narrative this way:
“Personally I think the main risk for AI today is concentration of power. These technologies are powerful and what we need for them to be sustainably deployed in our society is for more people to understand how they work, understand what they’ve been trained on, and understand how to limit and mitigate them. Our mission has been to bring more transparency to [AI], because otherwise these technologies are built behind closed doors. And it creates this narrative completely disconnected from reality. They’re kind of like glorified auto-completes, and at the same time in the public sphere… you see people describing them as these things that are going to take over and destroy the world. And in my opinion, it’s created because of lack of transparency and education about how these technologies are built.”
Masad went on to explain some of the key concerns people have about AI, and how those concerns are being stoked by these large centralized players:
“A lot of the safety concerns come from hype. These big companies are beneficiaries of hype. In a sense, they are the beneficiaries of the anxiety. For example, Microsoft Research got an early version of GPT-4 and wrote a paper calling it ‘first contact with artificial general intelligence.’ Then they [changed] it to ‘sparks of AGI.’ They’re using… research as a marketing opportunity. They’re marketing the system as artificial general intelligence, and then they’re feeding all the fears of the people that have been talking about the problems of AGI. And it’s creating a very toxic environment where for them it’s marketing, but for a lot of people it’s life or death.”
Finally, Delangue made the point that this undue focus on a bigger, scarier threat of AGI, also impacts how the world sees this technological progress. Rather than through a lens of understanding, it's a lens of concern:
“By focusing on this [threat of AGI], we focus the public narrative on something that hasn’t happened, and might never happen. And we don’t focus on the real challenges of today like bias, misinformation, lack of transparency, or control of power.”
The spectrum of responses to the threat of AI is as broad as the spectrum of approaches to open-source vs. closed. On Twitter, Nirit Weiss-Blatt, author of The Techlash, and Sasha Luccioni, an AI researcher at Hugging Face, collaborated on a visualization of the AI safety spectrum, sharing their perspectives on where some prominent contributors to AI stand.
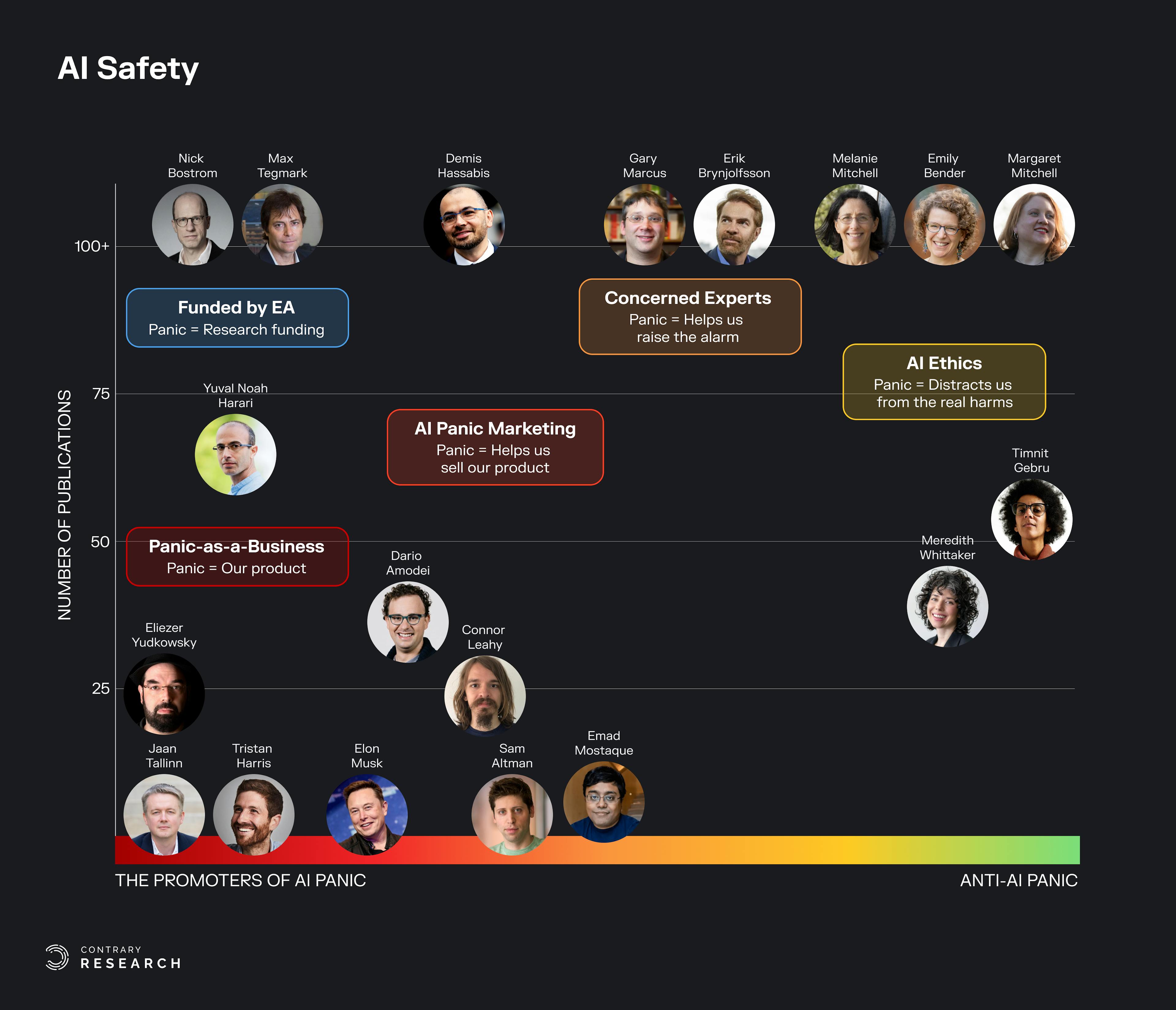
Source: Twitter; Contrary Research
Weiss-Blatt referred to the spectrum as "A Taxonomy of AI Panic Facilitators.” She further explained the categories this way:
Panic-as-a-Business: "We're telling you will all die from a Godlike AI… so you must listen to us."
AI Panic Marketing: "We're building Godlike AI that could be a monster… unless you invest in us to tame that monster."
Concerned Experts: "We don't believe X-risk as strongly but want to raise the alarm about all the potential harms.”
AI Ethics: "The X-risk panic distracts us from the real/current harms that have nothing to do with human extinction (e.g., bias, misinformation)"
Proponents of open-source AI often point to the fact that more openness would more effectively enable a response to AI issues. The discussion between Amjad Masad and Clement Delangue extended to how to balance the desire for large companies to be more open, while avoiding the proliferation of large language models among bad actors. In one paper, Irene Solaiman, who was previously at OpenAI and is now at Hugging Face, made this argument:
“The biases found in Internet-scale language models like GPT-2 are representative of the data on which the model was trained… We expect that internet-scale generative models will require increasingly complex and large-scale bias evaluations.”
Yann LeCun, the Chief AI Scientist at Meta, discussed this same topic on Twitter debating the merits of larger players pushing their own agenda by being closed, compared to the rapid increase of progress when technology is open.
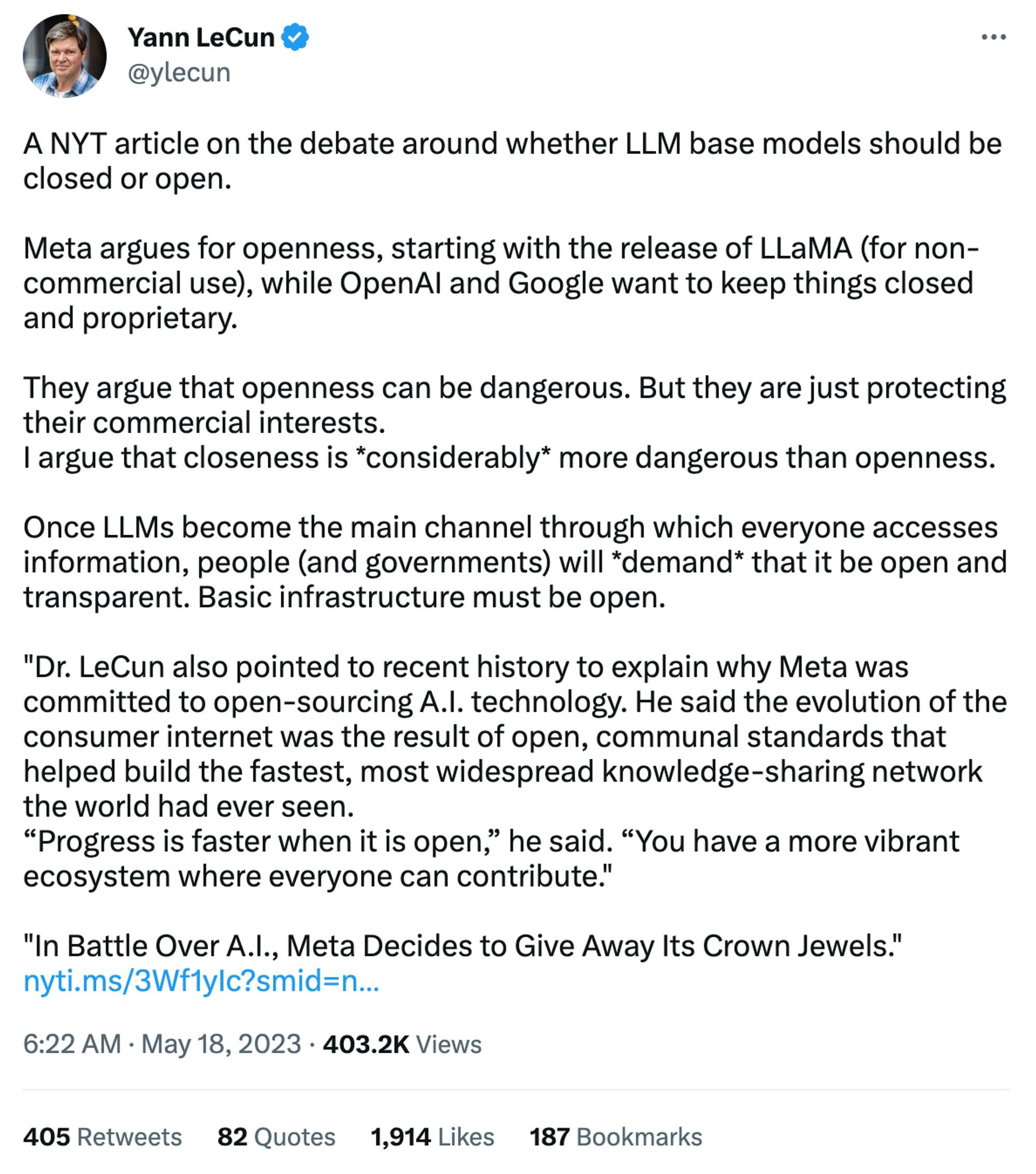
Source: Twitter
The more open these models are, the more they are also exposed to scrutiny around the bias they demonstrate. The more closed the training data is, the less understandable those biases become. Those same limitations of a closed ecosystem create an opportunity for bad actors to take advantage. Openness provides a counterbalance to make sure that good players of all sizes are more capable.
Censorship
Concentration of power also leads to the prospect of easier censorship. When large organizations have the ability to effectively censor the information that both people and systems can consume, that has massive implications for determining how those people and systems will think in the future. The principle of linguistic relativity, also known as whorfianism, presents the hypothesis that the structure of a language influences or even determines the way individuals perceive and think about the world.
As AI systems become inclusive of the majority of our data, the output of those same systems will start to shape people’s framing for reality. Several prominent philosophers have remarked on this intimate relationship between language, understanding, and power. French theorists Gilles Deleuze and Felix Guattari wrote in their book, A Thousand Plateaus that “there is no mother tongue, only a power takeover by a dominant language within a political multiplicity.” German philosopher Ludwig Wittgenstein put it more bluntly, saying “the limits of your language are the limits of your world.”
While the idea that AI systems could have implications for modern language and behavior itself may feel extreme given ChatGPT only made its debut relatively recently, the power of AI models implies that they can achieve ubiquity very quickly. And while language has always had a number of influences, the world has never previously seen technology capable of influencing language at a fundamental level, especially not technology that is controlled by just a few companies.
In the broader context of disinformation, a new term has emerged. Malinformation, a combination of “malware” and “disinformation.” One definition of the term: “‘malinformation is classified as both intentional and harmful to others’—while being truthful.” In a piece in Discourse Magazine, it discusses the public debate on COVID, vaccines, and the way government, media, and large tech companies like Twitter attempted to control the spread of misinformation:
“Describing true information as ‘malicious’ already falls into a gray area of regulating public speech. This assumes that the public is gullible and susceptible to harm from words, which necessitates authoritative oversight and filtering of intentionally harmful facts... It does not include intent or harm in the definition of malinformation at all. Rather, ‘malicious’ is truthful information that is simply undesired and “misleading” from the point of view of those who lead the public somewhere. In other words, malinformation is the wrong truth.”
The idea of “undesired” truth starts to feel eerily similar to the idea of Newspeak and thoughtcrimes explored in George Orwell’s Nineteen Eighty-Four. For an AI system to have universal implications for society’s conception of reality is likely a ways off. But large companies like Microsoft have already demonstrated their advantage when it comes to bundling and distributing products.
As a result, the opportunity for large centralized organizations to leverage the distribution of their AI systems in order to more effectively control public discourse is not that outlandish. The ability to combat censorship depends on a capable and distributed counterbalance. That counterbalance is unlikely to come from a formidable and equally centralized player. Instead, it is more likely to come from the empowered long tail of concerned parties.
As Clement Delangue at Hugging Face described in reference to his congressional testimony, “open source AI… [gives] civil society, non-profits, academia, and policy makers the capabilities they need to counterbalance the power of big private companies.” The more empowered long-tail organizations and individuals are, the less dominant single-perspective centralized organizations will be.
Ownership Of Data
Finally, the reality is that language and image models represent the greatest remixing of human language and culture ever. Each model is trained on existing language and images. With more data, you get better results. Data continues to be the “new oil” that powers the AI revolution. But because of that dependency, it calls into question how these systems will manage and attribute the ownership and credit for the underlying data.
Midjourney and Stability AI, for example, are being sued for scraping artist’s images from the internet without their consent and using them to train their image models. Midjourney’s CEO, David Holz, didn’t have a great response when asked about the issue, saying “the art community already has issues with plagiarism. I don’t want to be involved in that.” Similarly, Getty Images is suing Stability AI for using its stock photos to train models. Microsoft and OpenAI are also under fire for their coding Copilot product that was trained using millions of GitHub repos without consent.
Other companies, like Reddit, haven’t yet taken legal action. But they are actively pushing for companies building LLMs trained on data from these websites to pay for that access. The pushback from some of the internet’s most valuable data sources to internet scraping, such as Reddit and Twitter, has led to The Verge to call it the “end of a social era on the web.” Reddit CEO, Steve Huffman, stated:
“The Reddit corpus of data is really valuable. But we don't need to give all of that value to some of the largest companies in the world for free.”
Reddit's attempt to recoup costs through increasing prices on third-party API access led to a massive user revolt, with more than 7K subreddits going dark and Google’s search results noticeably deteriorating. In a parallel move at Twitter, Elon Musk introduced new login and rate-limits “to address extreme levels of data scraping & system manipulation.” This led to major outages and errors on Twitter the first weekend of July 2023, and record sign-ups to Twitter competitors such as Bluesky.
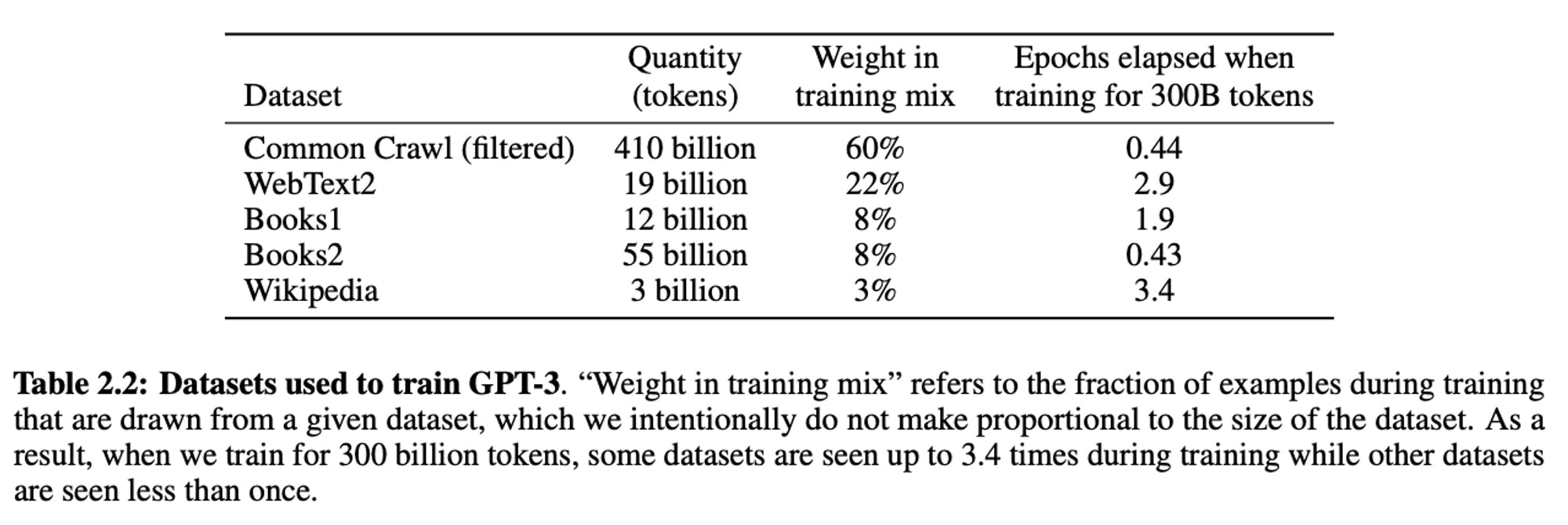
It’s clear from previous versions of GPT that open internet sites represent a significant majority of training data for LLMs. For example, the training data sources for GPT-3 include Common Crawl and Webtext2, much of which came from scraping hyperlinks from Reddit.
More companies that provide user-generated content (UGC), like Reddit, will be forced to make attempts at monetizing access to their content. Prashanth Chandrasekar, the CEO of Stack Overflow, a popular Q&A site for developers, said as much:
“Community platforms that fuel LLMs absolutely should be compensated for their contributions so that companies like us can reinvest back into our communities to continue to make them thrive.”
LLMs trained on UGC will damage content flywheels for a number of businesses, which could lead to less human-generated content on the internet for future LLMs to be trained on. The issue of data ownership and utilization will become increasingly complex. The less transparent AI companies are with what data is being used to train their models, the less this type of attribution can be understood and effectively managed.
To make matters worse, leading AI companies like OpenAI and Anthropic are already turning around to limit how much their own output can be used to train other LLMs. As these kinds of complex issues push AI to become more and more closed, what does actual open-source AI look like?
Building Open-Source AI
The AI Political Compass
As progress in the space increases more and more rapidly, every company is forced to position itself along emerging philosophical lines. Since Jared Kaplan and the team at OpenAI released “Scaling Laws For Neural Language Models,” it has kicked off the age of “scale is all you need.” As different companies make decisions about how they’ll access adequate compute, they’ve had to align themselves in different ways based on the financial resources they think they’ll need.
How open a company is, how focused they are on the opportunities vs. the risks of AI, are all specifics that are up for debate. Alexander Doria, the Head of Research at OpSci, laid out his perspective on where different platforms fall.

Source: Twitter
While this landscape is just one person’s opinion on where every company is positioned, the broader concept of an ideological spectrum actually exists as companies increasingly make different choices about how they’ll be aligned. However, one still rapidly evolving dynamic that may impact each of these companies is the way that focus on scale and performance is continuing to change.
While models produced by closed platforms like OpenAI and Anthropic still typically rank at the top of most performance benchmarks, there are impressive demonstrations from open-source providers as well. Open-source models like Guanco, or Vicuna, an open-source chatbot built on top of LLaMA, are competitive with closed models from the current leaders, OpenAI’s GPT series and Anthropic’s Claude series.
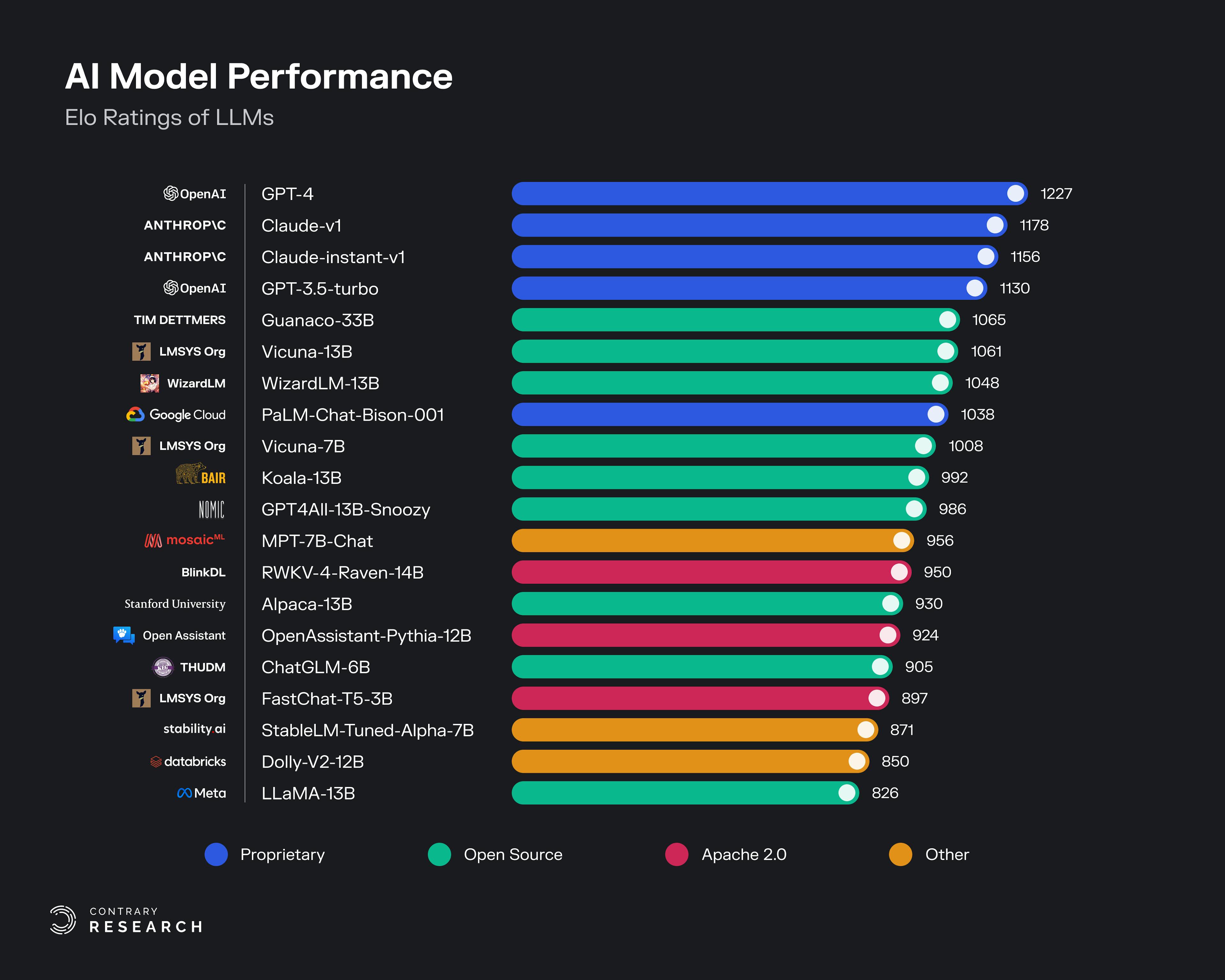
Source: LMSys Leaderboard; Contrary Research
Vicuna comes out of the Large Model Systems Organization, a research collaboration between students and faculty from Berkeley, UCSD, and CMU. LYMSYS trained Vicuna-13B for $300 on 70K user-shared ChatGPT conversations, demonstrating the viability of training models on outputs from other models.
Other open-source projects, such as AutoGPT, are combining foundation models with different methods to create new functionality. AutoGPT chains together GPT-4 “thoughts” to autonomously achieve whatever goal the user sets it, acting as a sort of AI agent. AutoGPT went viral on April 1st, 2023 and as of June 2023 it has 132K+ GitHub stars, making it the 29th highest ranked open-source project of all time. The project has been able to achieve functionality like recursive debugging and even self-improvement.
Researchers are also building open-source data and infrastructure to ensure fully open-source AI that’s competitive with industry models. A leader in this space is RedPajama, a collaboration between Together, a startup launched in June 2022 by AI researchers, with Ontocord.ai, ETH DS3Lab, Stanford CRFM, Hazy Research, and MILA Québec AI Institute. One of their first steps was to release the RedPajama base dataset in April 2023, which aims to replicate Meta’s LLaMA dataset. As of June 2023, the 5 terabyte dataset has been “downloaded thousands of times and used to train over 100 models.”
Large enterprises are already taking note of the power of open source LLMs and tooling. In June 2023, Databricks acquired MosaicML for $1.3 billion. MosaicML had previously built a popular open-source LLM called MPT-7B that was downloaded 3.3 million times. While Databricks is primarily known as a data analytics and management platform, the acquisition of MosaicML was a step towards openness in AI. In announcing the acquisition, Ali Ghodsi, the Co-Founder and CEO of Databricks described the company’s motivation this way:
“Every organization should be able to benefit from the AI revolution with more control over how their data is used. Databricks and MosaicML have an incredible opportunity to democratize AI… Databricks and MosaicML’s shared vision, rooted in transparency and a history of open source contributions, will deliver value to our customers as they navigate the biggest computing revolution of our time.”
The majority of large companies are less focused on democratizing AI, and instead focused on their strategy for controlling it. Companies like Databricks have always had an open source ethos, but it's not the only large company focused on making sure the current revolution remains as open as possible.
A Champion of Open Source
When it comes to large companies currently playing in AI, most of them were uniquely positioned to take advantage of the current AI boom because they were selling the picks-and-shovels of LLMs: cloud compute. Microsoft, OpenAI’s biggest investor, has Azure, a $34 billion business. Similarly, Google has its Google Cloud Platform, a $26 billion business. While Microsoft has invested billions in OpenAI, not to mention Inflection AI or Adept AI, Google has also invested in companies like Runway and Anthropic. But for these hyperscale cloud giants, much of that investment could come back as revenue for their cloud computing businesses.
Meta is unique in not providing cloud computing services. Instead, the company has a “strategic partnership” with AWS and a $20 billion investment in 40 million square feet of its own data centers. Meta is also unique in that it decided to open source LLaMA, its foundational 65-billion-parameter large language model. Going beyond just releasing the model, Meta has also released the weights for the model. One New York Times article described the benefit of that:
“[Analyzing] all that data typically requires hundreds of specialized computer chips and tens of millions of dollars, resources most companies do not have. Those who have the weights can deploy the software quickly, easily and cheaply, spending a fraction of what it would otherwise cost to create such powerful software.”
That same article quoted Yann LeCun, Meta’s chief AI scientist, explaining Meta’s approach to openness when it comes to AI as follows:
“The platform that will win will be the open one… Progress is faster when it is open. You have a more vibrant ecosystem where everyone can contribute.”
Mark Zuckerberg went on to explain this approach further in a June 2023 interview where his comments on Meta’s approach sound very similar to OpenAI’s original entreaty to AI talent who were more interested in contributing to more open projects:
“Meta has taken the approach of being quite open and academic in our development of AI. Part of this is we want to have the best people in the world researching this and a lot of the best people want to know that they're going to be able to share their work.”
Zuckerberg went on to describe his contrarian view that open source is ultimately the way to build the most secure and safe future for AI:
“I don't think that the world will be best served by any small number of organizations having this without it being something that is more broadly available. And I think if you look through history, it's when there are these… power imbalances that they're going to be kind of weird situations. So this is one of the reasons why I think open source is generally the right approach. One of the best ways to ensure that the system is as secure and safe as possible [is open source] because it's not just about a lot of people having access to it. It's the scrutiny that kind of comes with building an open source system.”
Meta’s decision to open source its LLM started with just a research license, which means developers can’t commercialize the model into paying use cases. The company is considering releasing the model commercially, but is forced to consider the liability implications of, for example, potential copyright material included in the model’s training data set. Far from limiting Meta’s competitiveness, however, Zuckerberg believes that all of Meta’s product could have an “AI agent” and that “LLaMA… is basically going to be the engine that powers that.”
In positioning itself as a champion of open source, Meta is taking a fundamentally different approach than Google and Microsoft. But this isn’t the first time Meta has gone up against Google in the world of machine learning.
In November 2015, the Google Brain team released a machine learning framework called TensorFlow. Shortly after, in October 2016, Facebook’s AI Research team released a similar framework called PyTorch. While TensorFlow was initially much more commonly used, PyTorch has risen to own the machine learning landscape, including being a central pillar in OpenAI’s infrastructure. In June 2022, one article outlined Google’s quite moves to launch a new framework called Jax, effectively ceding the machine learning landscape to Meta for the time being:
“The chorus is the same in interviews with developers, hardware experts, cloud providers, and people close to Google's machine learning efforts. TensorFlow has lost the war for the hearts and minds of developers. A few of those people even used the exact phrase unprompted: ‘PyTorch has eaten TensorFlow's lunch.’”
As powerful as Meta’s support for building open-source AI is, one significant obstacle in building AI models up to this point has been about scale. If the largest companies with the most data and access to compute are closed silos, it can make it difficult to compete. But the reality is that, increasingly, success in building AI won’t only come from scale.
Scale Is NOT All That Matters
When the “Scaling Laws For Neural Language Models” paper was published in January 2020, it focused on the idea that foundation models tend to get better as they get larger. For example, Stanford’s Center for Research on Foundation Models publishes a benchmark, HELM (Holistic Evaluation of Large Models), that finds the best models for in-context learning are larger.
Large models also demonstrate breakthrough emergent capabilities on different tasks. Emergence can be thought of as the phenomenon of incremental quantitative changes leading to marked changes in qualitative behavior – the common analogy being water crossing the freezing point and becoming ice. The paper “Emergent Abilities of Large Language Models” shows how models such as GPT-3 from OpenAI and LaMDa from Google demonstrate breakthrough performance on a wide variety of tasks around the 10^22 parameter mark.
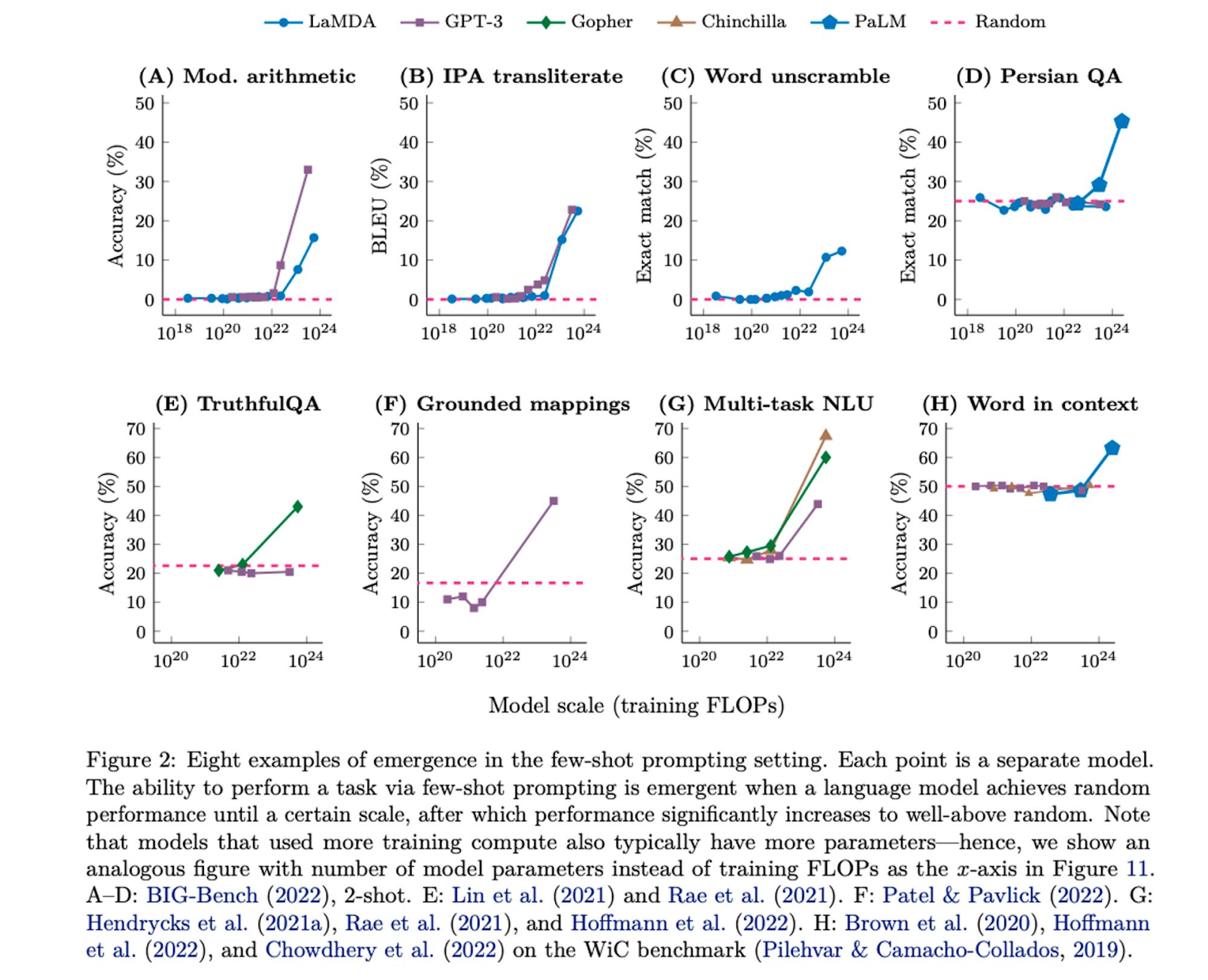
Source: Google
However, larger models require more data to train, with the landmark Chinchilla paper from DeepMind suggesting a new set of scaling laws, which require much more data than the original “Scaling Laws for Neural Language Models” paper predicted. A recent code-completion model from Replit* was released in April 2023 and goes even further. The model was trained on 2.7 billion parameters, and provides 40% better performance than comparable models.
These new insights on LLM scaling suggest one reason why Sam Altman says “I think we’re at the end of the era where it’s gonna be these giant models, and we’ll make them better in other ways.” Rumors were floated by Cerebras Systems, a startup that built the world’s largest computer chip, that OpenAI’s GPT-4 would be 100 trillion parameters. This led to a viral twitter chart which Sam Altman denied as “complete bullshit.”
We can see why – applying the latest scaling laws, a 100 trillion parameter model would require 4,000x times more data than GPT-3, a monumental undertaking that hits fundamental limits of publicly available data on the internet. Researchers in a paper “Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning'' found that we may exhaust publicly available data around the year 2024. High quality datasets right now are around a few terabytes in scale, whereas a 100 trillion parameter model would need an estimated 180 petabytes of data, according to Chinchilla scaling laws.
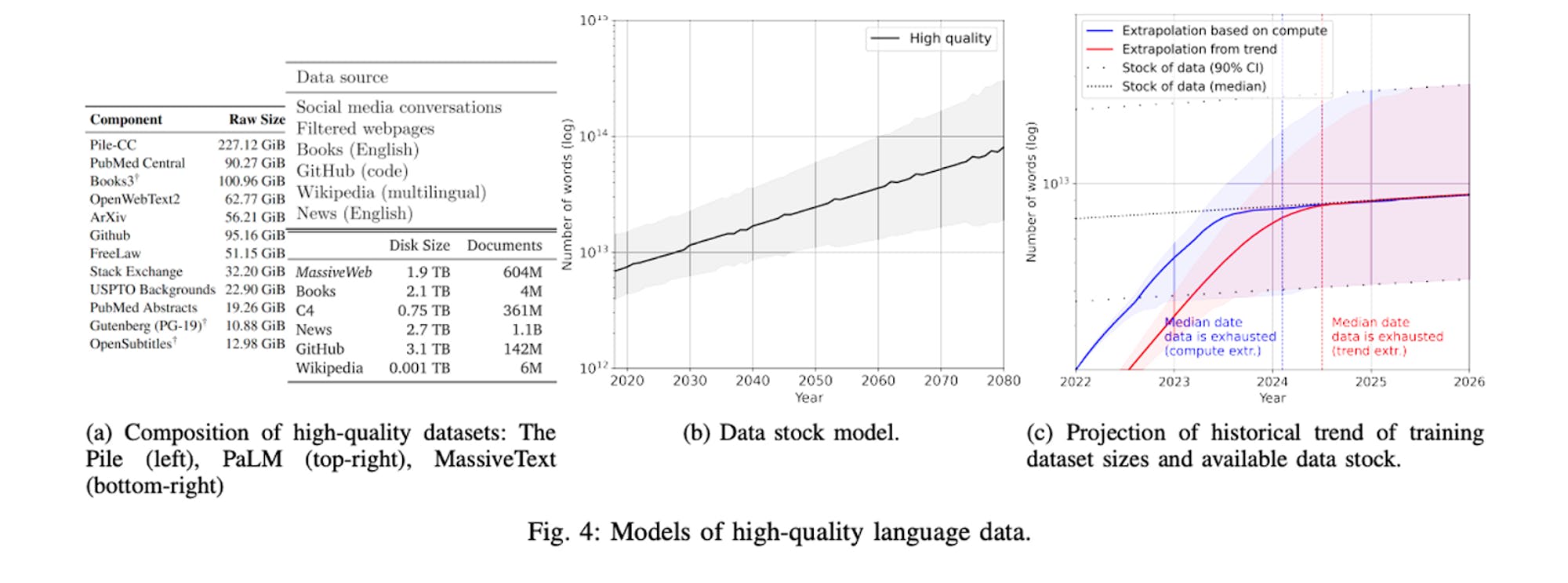
Source: EpochAI
In the meantime, smaller open-source AI has been on a tear. A memo from a Google senior engineer, titled “We Have No Moat, and Neither Does OpenAI”, leaked on May 4th, 2023 and “made the rounds” in Silicon Valley. The memo argues:
“The uncomfortable truth is, we aren’t positioned to win this arms race and neither is OpenAI. While we’ve been squabbling, a third faction has been quietly eating our lunch. I’m talking, of course, about open source.”
The author argues that “people will not pay for a restricted model when free, unrestricted alternatives are comparable in quality,” with a chart that open-source models are being developed at a rapid pace of one to two weeks apart.
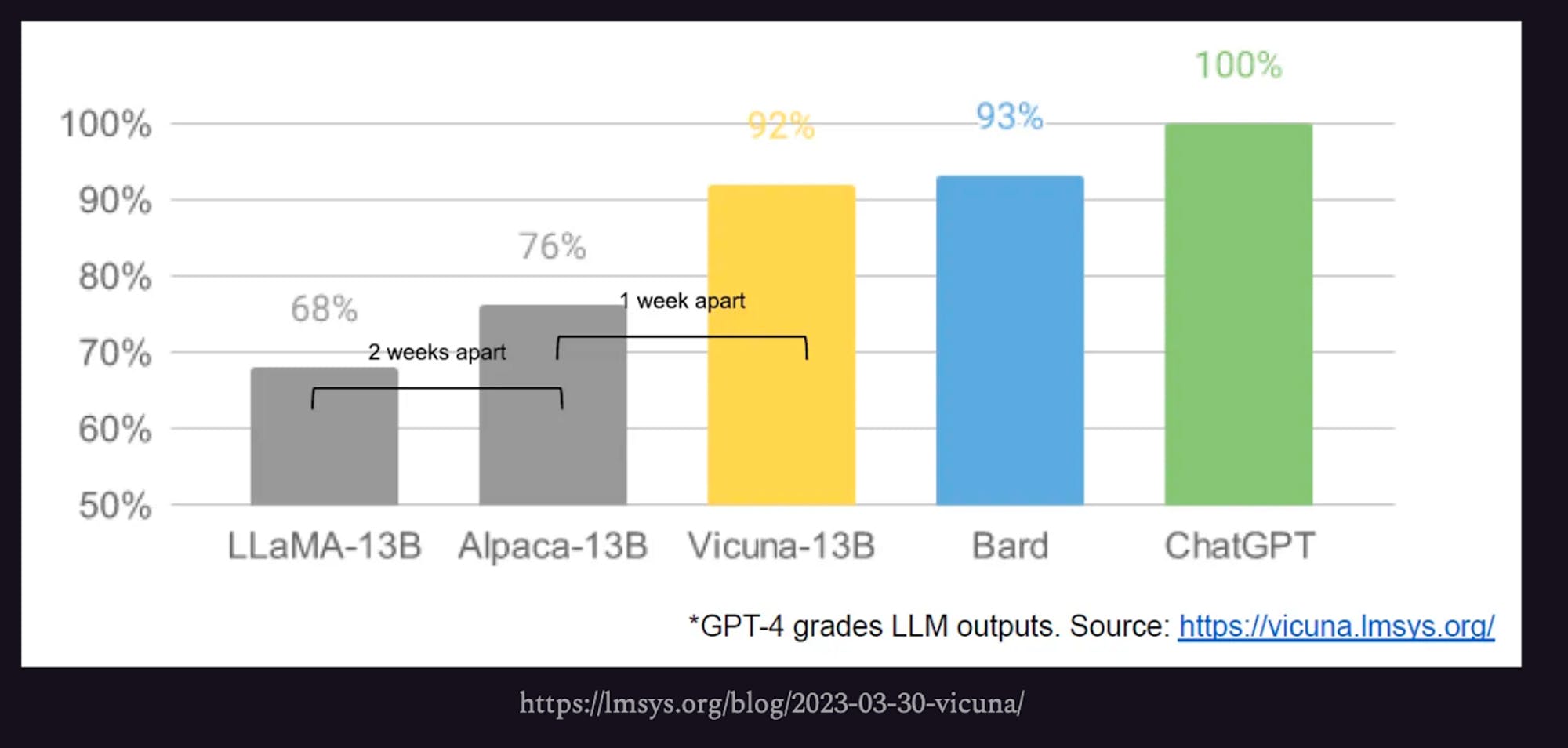
Source: SemiAnalysis
However, this position has been criticized by AI researchers. Various researchers have pointed out that the above chart graded open-source models using GPT-4. Jesse Mu, a Stanford PhD at Anthropic, tweeted a response:
“The cited LM evals are misleading: they don’t measure frontier capabilities but a very narrow task distr. Claims that closed LMs have no moat must evaluate OSS models on actual knowledge work, not stuff like ‘name a restaurant.’”
Instead of an endless race towards more parameters for general purpose models, the focus is, instead, shifting towards finding efficient improvements in these models through means other than increased scale. For example, Stephen Bach, a Snorkel AI researcher, published a paper called “Multitask Prompted Training Enables Zero-Shot Task Generalization.” The idea of “zero-shot learning” is a method of prompt engineering that enables a model to learn tasks for which it has had no training data for.
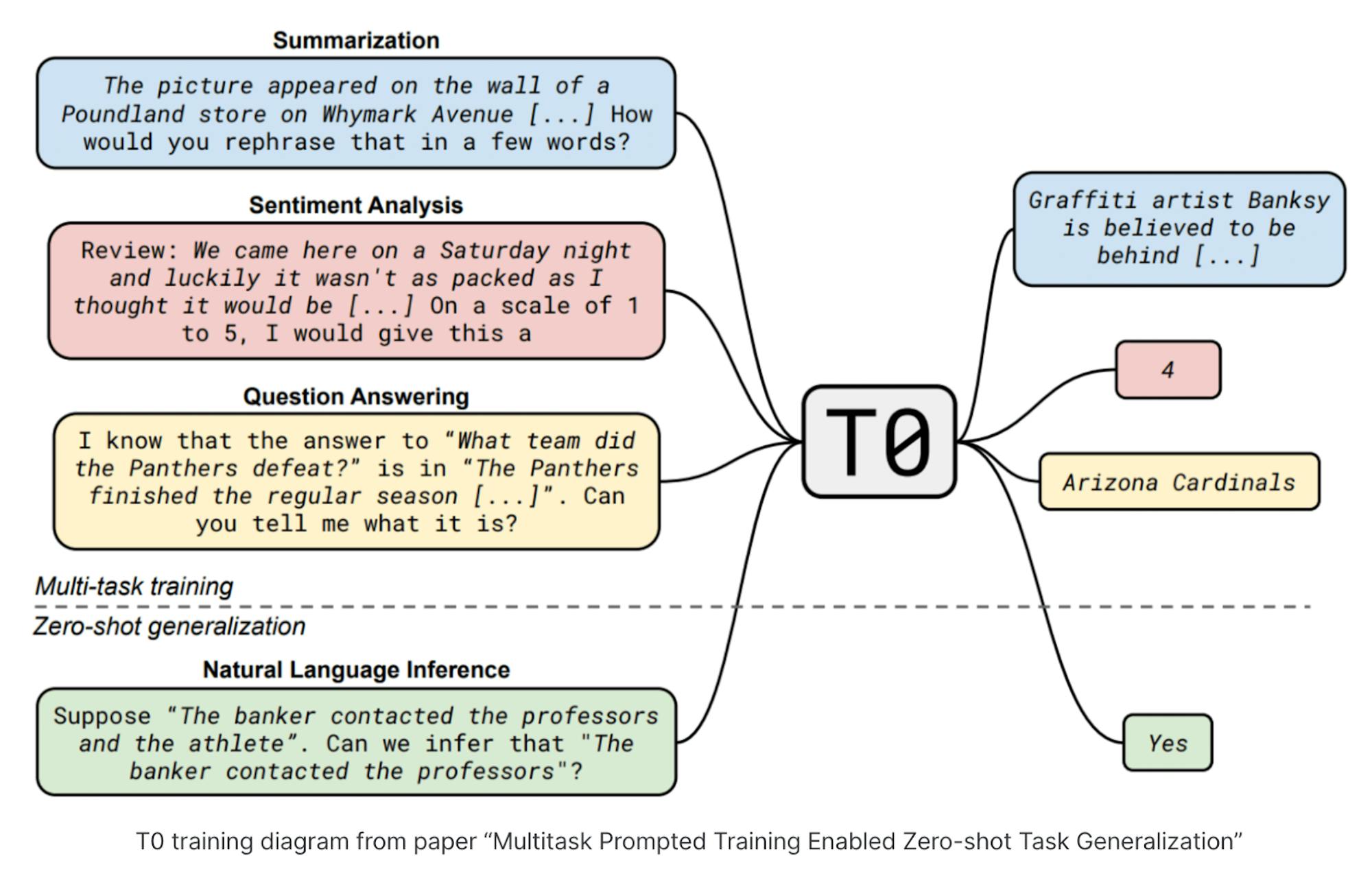
Source: Snorkel AI
Alex Ratner, the CEO of Snorkel AI, summarized the work that Bach and his team had done in being “able to get a model that was 16 times smaller than GPT-3 that outperformed it on a bunch of benchmark tasks by curating a multitask training data set.”
Another method of achieving similar performance at a fraction of the compute is through task-specific training and model compression. For example, GPT4All is a compressed language model that can run on edge devices with only 4GB of RAM and a CPU. Using a fine-tuned version of GPT4All can reduce the cost of applying a language model to a specific task.
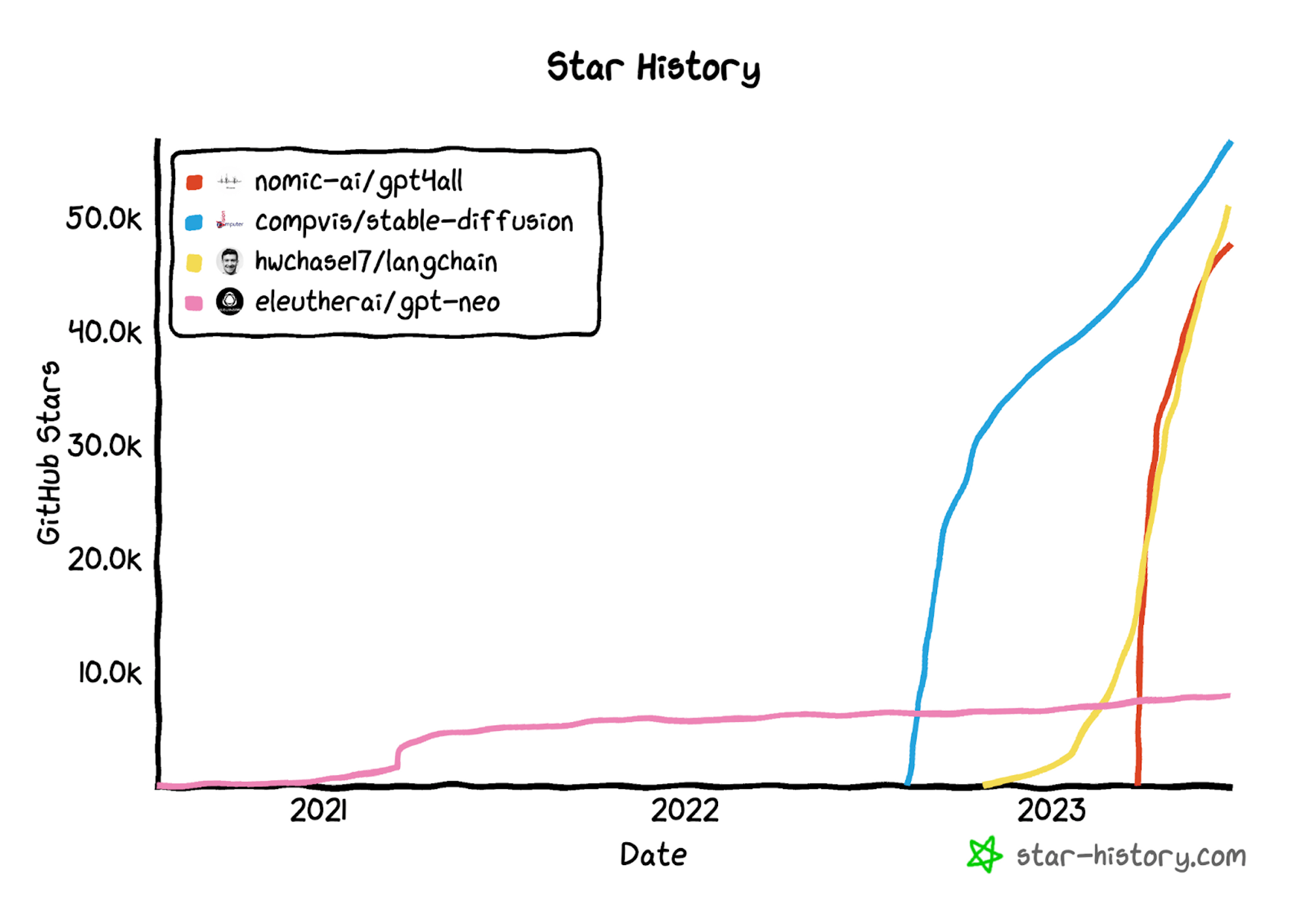
Source: GitHub, as of June 28th, 2023
Beyond the improved unit economics of compute per dollar, open models like GPT4All provide transparency and access to AI technology. Since their code and data is public, anyone can audit the process used to create the models. Further, since they can run on low resource systems, they allow people without access to the scarce supply of GPU hardware to benefit from the technology.
AI’s Linux Moment
The explosion of excitement and activity with open-source models has led Chris Ré, professor at Stanford’s AI Lab, to announce “AI is having its Linux moment.” As Chris Ré notes in his analogy to Linux:
“A bunch of open-source hackers came together and built a freely available operating system…. The big player Microsoft continued to have a large install base with Windows and made amazing products that people want, but open source has had a huge role in computing. Open source embraced permissive licensing and allowed a broader set of people to be represented in the creation of important computing tools; it also brought down barriers so that more people could use technology in myriad ways. Can we do the same (or even better) for AI? We might need to break new ground in how we think about open-source software, and reimagine what this movement means in the context of AI systems.”
Open-source communities made major contributions to open-source datasets. For example, LAION-5B, a dataset of over 5 billion images used to train image models, was reported on with the title “The Future of AI Relies on a High School Teacher’s Free Database.” EleutherAI released The Pile, a high quality dataset used to train many of the leading open-source models. The strong culture of open source in the AI community led to platforms like Hugging Face, with its hub and library, hosting open-source models and the open-source data sets used to train them.
As the leaked Google memo notes, open-source AI has seen an explosion in activity this year following the release of LLaMA on February 24, 2023 by Meta, which was subsequently leaked on March 3, 2023, leading to widespread experimentation. On March 13, 2023, Stanford released Alpaca, which introduced a library, alpaca-lora, using a fine-tuning method called low rank fine tuning that allowed individuals to fine-tune models on consumer hardware. By March 18, 2023, it was possible to run LLaMA on a Macbook CPU. All of that in less than a month.
Large companies also have an incentive to promote open-source models. Databricks introduced Dolly 2.0 in April 2023, a fully open-source LLM Databricks claimed was trained for less than $30. MosaicML, the model training platform that Databricks acquired, open sourced MPT-7B in May 2023, a series of commercially usable LLMs trained on 1T tokens and meets the quality of LLaMA-7B, Meta’s leaked model which is not licensed for commercial use.
As Mark Zuckerberg noted on a Meta earnings call in Q1 2023:
“The reason why I think [we] do this is that unlike some of the other companies in the space, we’re not selling a cloud computing service where we try to keep the different software infrastructure that we’re building proprietary. For us, it’s way better if the industry standardizes on the basic tools that we’re using and therefore we can benefit from the improvements that others make and others’ use of those tools can, in some cases like Open Compute, drive down the costs of those things which make our business more efficient too. So I think to some degree we’re just playing a different game on the infrastructure than companies like Google or Microsoft or Amazon, and that creates different incentives for us.”
That perspective from Zuckerberg led Ben Thompson of Stratechery to make this argument:
“What is compelling about this reality, and the reason I latched onto Zuckerberg’s comments in that call, is that Meta is uniquely positioned to overcome all of the limitations of open source, from training to verification to RLHF to data quality, precisely because the company’s business model doesn’t depend on having the best models, but simply on the world having a lot of them.”
The proliferation of a wide variety of open-source models leads to a lot of benefits, but it’s not enough to have functionality. You also have to have broad usage. The core opportunity is to make rapid improvements that make open-source AI more usable – a rising tide lifts all ships. But beyond that, the implications for safety and counterbalances of power and influence come with open source. Alex Ratner, the CEO of Snorkel AI and a machine learning professor at the University of Washington, made this argument:
“[We’re moving] from GPT-X to GPT-You. Personalization to specific domains is already occurring, such as PubMedGPT for doctors, Pile of Law for lawyers, and BloombergGPT [or FinGPT] for finance. The advent of libraries like alpaca-lora has democratized access to personalization, allowing users of consumer hardware to personalize their own models. Users will be able to imbue models with their own values and behaviors.”
Model and data ownership is also a concern. Enterprises often do not want to hand over their private, proprietary data to companies like OpenAI. Instead, organizations are attempting to customize pre-trained models to their own use cases. Co-founder and Chief Scientist of Numbers Station Ines Chami notes that they create and deploy smaller, specialized models for enterprises:
“It’s really important to personalize and adapt the model specifically to the organization… The idea is to generate answers that are specific to the organization, so we use fine-tuning techniques and also feedback.”
Large models are also costly to use. Numbers Station notes in a blog post that cutting edge models “usually have billions of parameters and cost millions to serve. In a best case scenario, running inference over 1M rows of shorter context user data could cost $3.7K.” They claim to produce a model 800x smaller and 2275x cheaper, all while maintaining the same quality.
The work by Brown University professor Stephen Bach in his collaboration with Snorkel AI led to a fine-tuned GPT-3 legal-classification model. They claim to have produced a model with the same quality as GPT-3 while being 1400x smaller and costing 0.1% of GPT-3 to run in production. GPT4All provides similar opportunities for high quality performance at a fraction of the compute resources.
If AI is truly the Fourth Industrial Revolution, then it needs to be accessible to everyone regardless of cost, geography, or political affiliations. We need to remove barriers to technology and information. Not everyone has a GPU, not everyone even has the internet! There needs to be an aligned incentive between data creators and model creators to ensure those who contribute data to build a model can have their value attributed and compensated.
An ideal solution would break down a lot of the barriers that exist for rapid and universal adoption:
Removing information barriers: Open source both data and code. This requires tools for observing, discussing, and curating data to train a model. Not a black box, but an understood and attributable model. Models should also be able to run “air gapped” so sensitive data never leaves a user’s system.
Removing ideological barriers: There needs to be a democratic process around deciding what a model can and cannot say. If we’re going to censor universal systems then there needs to be a universal compromise on what those controls should be, rather than a single set of rules passed down from the most powerful monolithic tech company. Different constituencies deserve different models.
Removing technological barriers: Models should not, and cannot, continue to require massive infrastructure to operate. The capability to run these models locally, powered by low-powered machines is the only way that the technology becomes universal.
Removing geographical barriers: Stewards of a given model need to find ways to allow people from all around the world to access their models. There has to be a way for models to spread, even without internet access.
*Contrary is an investor in Nomic and Replit through one or more affiliates.
Appendix
An Overview of The Truly Open AI Landscape

Source: Contrary Research
A Brief History of AI

Source: Contrary Research








